Ansys Mechanical™ is an industry-leading finite element analysis (FEA) solver with structural, thermal, acoustics, transient, and nonlinear capabilities. Implicit FEA applications like Mechanical software often place large demands on memory and disk I/O subsystems, and engineers have tended to avoid the cloud for resourcing these workloads. However, companies are looking to utilize high-performance computing (HPC) workloads like Mechanical applications in the cloud for various reasons, whether augmenting their existing HPC on-premises resources or fully transitioning to the cloud.
This blog post discusses the performance of Mechanical software using Oracle Cloud Infrastructure (OCI). The goal was to determine the best overall configurations to carry out production simulation workloads in a cloud environment providing comparable performance to dedicated on-premises hardware.
Benchmarks
We created various compute clusters using the HPC Terraform template available on the Oracle Cloud Marketplace. We give a brief description of the shapes that we tested in Table 1, and you can find a more comprehensive description in the OCI documentation.
| Table 1: Computer Shapes Tested |
||||
| Server shape |
Processers |
Cores/node |
Memory(GB) |
Storage |
| BM.Optimized3.36 |
Intel Xeon 6354 |
36 |
512 |
NVMe |
| BM.Standard3.64 |
Intel Xeon 8358 |
64 |
1024 |
Network |
| BM.Standard.E5.192 |
AMD EPYC 9J14 |
192 |
2304 |
Network |
| BM.HPC.E5.144 |
AMD EPYC 9J14 |
144 |
768 |
NVMe |
| VM.Standard.E5.flex |
AMD EPYC 9J14 |
64 |
512 |
Network |
The first four systems listed are based on CPU bare metal shapes, often preferred over virtual machine (VM) shapes for HPC. The fifth system we tested was a flexible VM shape, where we could specify the number of cores and memory.
All benchmarks were run using all the CPU cores on dedicated systems one job at a time using Mechanical software version 2024R1. Results were reported in terms of overall job performance based on the Ansys solver core rating, where higher is better. For our first set of benchmarks, we used the latest cluster benchmark datasets provided by Ansys described in Table 2.
| Table 2 V24Benchmark-Cluster Description |
||
| DATASET |
SOLVER |
SIZE |
| V24direct-4 |
Sparse solver, nonsymmetric, transient, nonlinear, thermos-electric coupled field |
4 MDOFS |
| V24direct-5 |
Sparse solver, transient, nonlinear |
15 MDOFS |
| V24direct-6 |
Sparse solver, transient, linear regression, 1 frequency |
11MDOFS |
| V24iter-4 |
JCP solver, static, linear |
30MDOFS |
| V24iter-5 |
PCG solver, static, linear |
63 MDOFS |
| V24iter-6 |
PCG solver, static, linear |
125 MDOFS |
The Mechanical software offers shared-memory parallel (SMP), distributed-memory parallel (DMP), and hybrid parallel methods. For each dataset we tested, we found either the DMP or hybrid-parallel method to be optimal, typically with 32–64 cores per MPI domain. We ran each benchmark in a scratch directory, which was on the direct-attached NVMe storage if available, or an NVMe network attached OCI NVMe block Storage volume. Chart 1 shows the results of these benchmarks on the various systems.
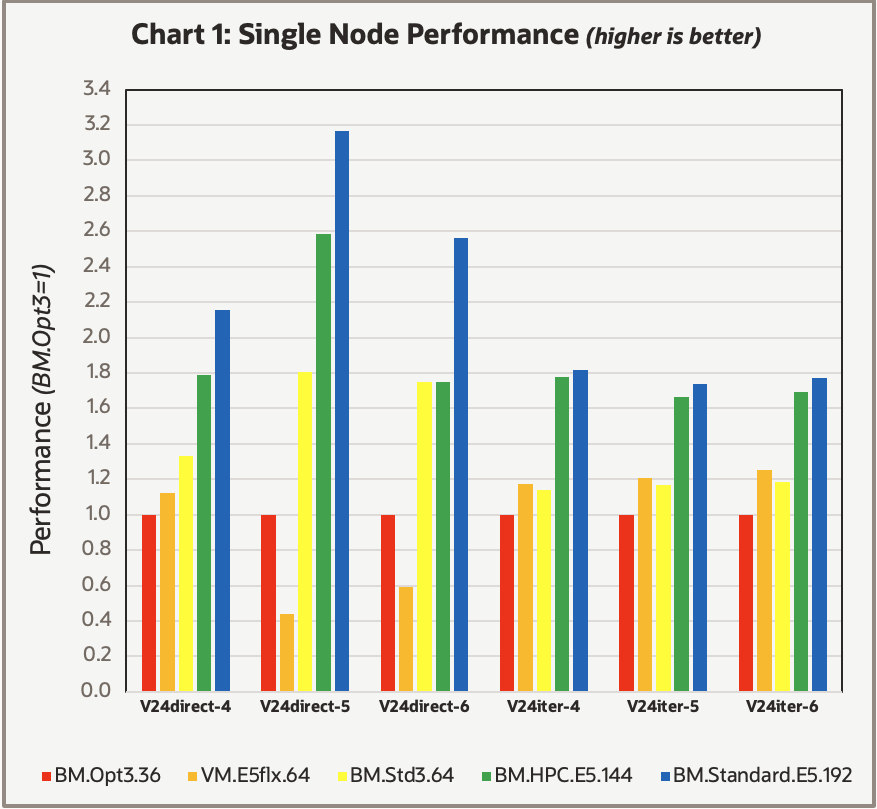
These results tend to be more useful when viewed as a trend, not as individual results, because customer workloads vary. The order of the results is sorted with the reference system, the BM.Optimized3.36 shape first with the other shapes listed in terms of generally increasing overall performance. The major overall trend showed that shapes with more CPU cores tended to perform better, particularly when using the hybrid-parallel mode to limit the number of cores per MPI domain to 32–64. Also notable was that the 64-core based VM.Standard.E5.Flex shape was comparable in performance to the 64-core BM.Standard.3.64 for the iterative-solver cases but lagged in performance noticeably for the direct-solver cases.
HPC in the cloud tends to offer an advantage over on-premises HPC because advancements in available hardware occur much more rapidly. However, this setup presents challenges in keeping performance blog posts relevant over a longer period. As we noted earlier, whenever Compute shapes contained internal NVMe storage, we utilized it to reduce I/O wait times, but limiting use of implicit FEA to only shapes with imbedded NVMes might not be necessary.
We carried out benchmarks on the three direct-solver cases listed in Table 2 along with two customer examples of I/O-intensive iterative-solver cases. Benchmarks were carried out on the BM.HPC.E5.144 system using the internal NVMe storage as the reference along with a local file system created from network attached block storage, and various network attached shared file systems. Chart 2 uses the following terms and acronyms:
- bk120 refers to an XFS filesystem mounted on the Compute server, which was created from an OCI network attached NVMe-based block volume with the variable performance parameter unit (VPU) set to 120 with 230K IOPS at 1,800 MB/s.
- NFS-nvme used network file system (NFS) storage from an NFS server utilizing its internal NVMe storage as the export file mount.
- Lustre used a Lustre client based on a Lustre File system created from four VM.DenseIO2.8 servers—two for meta data servers, two for for object ddata servers.
- NFS-bk120 used a network-attached NFS storage from an NFS server, exporting an XFS file system created from an OCI block volume with a VPU of 120.
- FSS used the network-attached the OCI File Storage service with the mount target performance set to 400K IOPs.
- NFS-bk10 was similar to the NFS-bk120 except the VPU was set to 10 with 25K IOPS at 480 MB/s.
Chart 2 displays the effect of various I/O subsystems on the overall job performance of these five jobs.
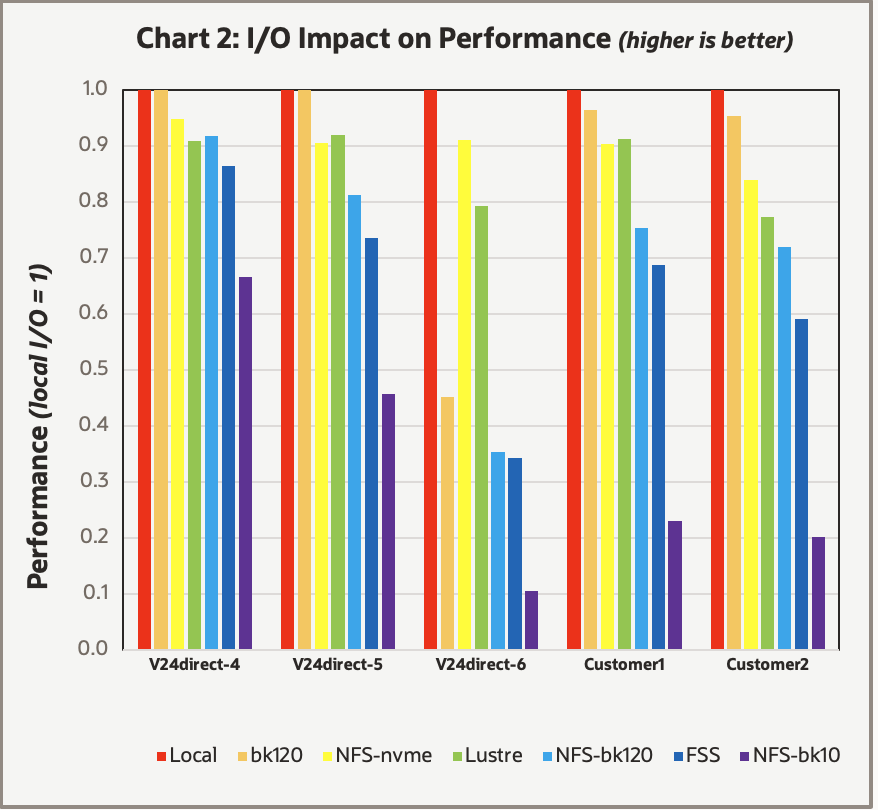
Apart from V24direct-6, the results were consistent across the various test cases. V24direct-6 is the only case that went out-of-core on the BM.HPC.E5.144 shape used, which might explain the anomalies. In Chart 1, while both BM.Standard3.64 and BM.Standard.E5.192 used network attach block volumes for storage, they had sufficient memory to stay in-core, diminishing the impact of I/O on the overall performance. In general, we recommend choosing shapes with sufficient memory to keep the solver in-core over shapes with internal NVMes with insufficient memory to run in-core.
Overall use of the network attached block volume offered similar performance to the internal NVMe, with the host OS able to effectively buffer much of the I/O traffic within the available memory. Use of a shared file system (Lustre, NFS, or OCI File Storage) typically dropped performance 10–30%, case with the exception being the NFS storage, NFS-bk10, which was ill suited for these jobs. While the shared file systems performed reasonably well with a single job, they likely falter more when simultaneous jobs are running, likely causing significant performance penalties. In contrast, the local NVMe or block volume storage options don’t suffer any degradation with an increased number of simultaneous jobs
Conclusion
We found that OCI offers several options for achieving excellent performance with Mechanical software. Performance generally scaled well with the number of cores available in each Compute shape. While using Compute shapes with internal NVMe drives can be beneficial, they’re typically only necessary for large out-of-core workloads or a large number of simultaneous jobs.
We encourage Ansys users to test their Mechanical application workloads at Oracle Cloud Infrastructure with a 30-day free trial.
For more information, see the following resources:
