Oracle and AMD recently announced a major expansion of their long-standing relationship with the GA of the MI355x few months back.
This blog details more hardware details, performance characteristics of LLM model serving on the BM.GPU.MI355X.8 shape with Oracle Cloud Infrastructure(OCI).
The AMD Instinct MI355X GPU is a state-of-the-art accelerator engineered to meet the rigorous demands of modern artificial intelligence (AI) and machine learning (ML) workloads. Its advanced architecture and robust performance capabilities make it exceptionally well-suited for both training complex models and executing inference tasks efficiently. A powerful hardware combined with matured ROCm software version 7.0 puts tis as a good option for demanding workloads. We announced General Availability (GA) in October 2025, since then we have been busy with real-world performance validations and hardware + ROCm characteristics at scale. This blog shares few insights on the performance, and details on how to get started with AMD MI355X on OCI.
Key Strengths of the AMD Instinct MI355X GPU
High Memory Capacity and Bandwidth: Each MI355X GPU is equipped with 288 GB of HBM3E memory, delivering a peak bandwidth of 8 TB/s. This substantial memory capacity and bandwidth are crucial for handling large datasets and complex models without bottlenecks.
Advanced Compute Architecture: Built on AMD’s CDNA 4 architecture, the MI355X features 256 Compute Units (CUs) and supports a wide range of precision formats, including FP64, FP16, FP8, FP6, and FP4, catering to diverse computational needs.
Enhanced AI Performance: The MI355X delivers impressive performance metrics across various precision levels, including:
• FP64 (Double Precision): 78.6 TFLOPS
• FP16 (Half Precision): 5 PFLOPS
• FP8: 10.1 PFLOPS
• FP6 and FP4: 20.1 PFLOPS each
These capabilities ensure that the MI355X can handle both the rigorous demands of training complex models and the efficiency requirements of inference tasks.
Performance Details
The MI355X’s architecture and performance metrics position it as a versatile solution for AI inference workloads. The support for lower precision formats like FP8, FP6, and FP4 enables faster inference processing with reduced computational overhead, making the MI355X ideal for real-time AI applications. We ran different target AI inference workloads profiles from low input & output tokens to very large summarization use case and consistency saw liner scanning and amazing performance for large content lengths.
Performance Details
The MI355X’s architecture and performance metrics position it as a versatile solution for AI inference workloads. The support for lower precision formats like FP8, FP6, and FP4 enables faster inference processing with reduced computational overhead, making the MI355X ideal for real-time AI applications. We ran different target AI inference workloads profiles from low input & output tokens to very large summarization use case and consistency saw liner scanning and amazing performance for large content lengths.
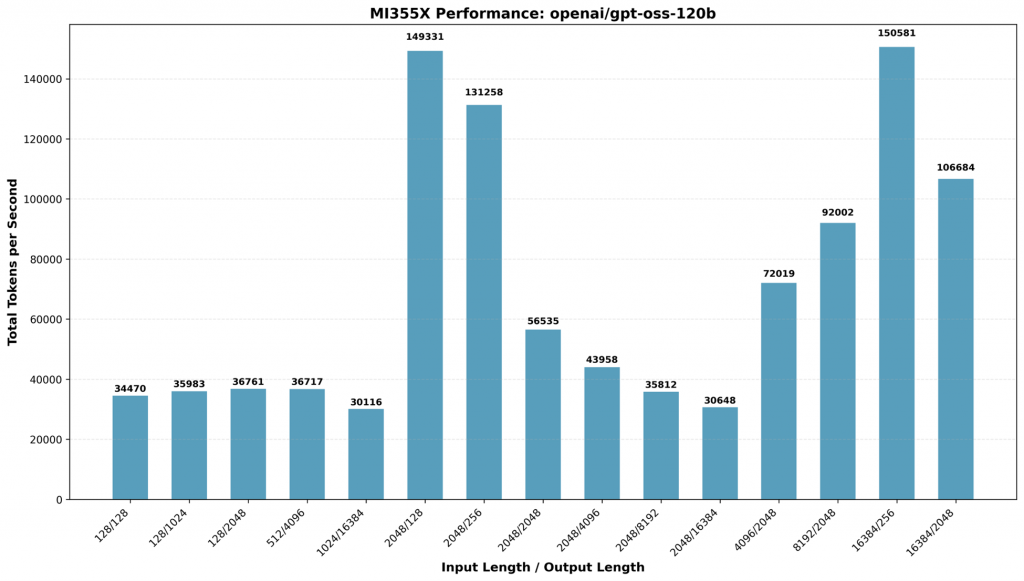
LLM Inference Runs
The below graph shows the total throughput in Token Per Second (TPS) on OCI BareMetal AMD MI355X GPUs. Meta llama 3.3 70B AMD quantized FP8 precision LLM Model was used during the run, as well as Open AI GPT 120B OSS Model. The results show very high throughput with offline inference throughput scenarios and the hardware consistently performed well when input/output sizes of the content were expanded. More technical details on configs and container here.
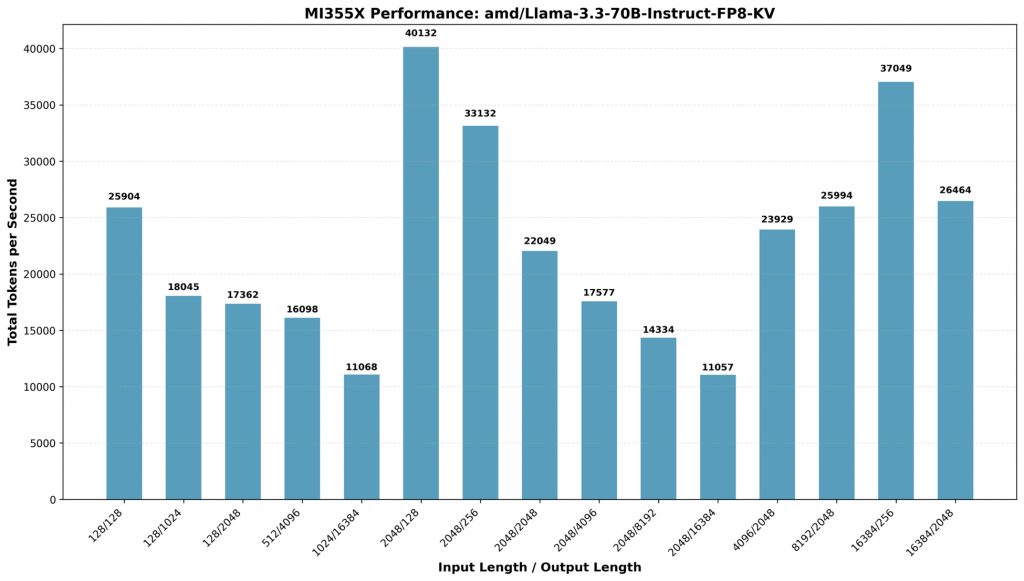
On Open AI GPT OSS LLM model MI355X continues to do better as token sizes become large e.g., 16K Input size underscoring the large HBM memory size and bandwidth boost MI355X have compared to MI300X. This highlights its efficiency in handling large-scale inference tasks make it a great choice for use cases like code generation and summarization use cases. More technical details here. When comparing all our AMD MI300X performance benchmarking, notable big leap performance update was achieved with ROCm 7.0 and vLLM compared to ROCm 6.0 versions. This highlights the PyTorch, vLLM and flash attention libraries optimizations made in last one year.
Hardware Specifications On OCI
The MI355X’s hardware specifications underscore its suitability for demanding AI workloads:
Oracle Cloud Infrastructure (OCI) offers bare-metal GPU instances featuring the MI355X with varying networking configurations to cater to different performance and scalability needs:
BM.GPU.MI355x:
• GPU Model: AMD MI355X
• GPUs per Node: 8
• GPU Memory: 288 GB per GPU
• Total GPU Memory: 2.3 TB
• CPU: 2 x AMD EPYC 9004/9005-series, CPU Cores: 128
• System Memory: 3 TB DDR
• Local Storage: 8 x NVMe 7.68 TB per disk (61.44 TB total)
• Host NIC: NVIDIA CX-7 2 x 200 Gbps (400 Gbps total)
• RDMA NICs Option 1: AMD Pensando™ Pollara 400 AI NIC, 8 x 400 Gb/s Ethernet (3.2 Tb/s total bandwidth, RoCE + RDMA)
• RDMA NICs Option 2: Mellanox Technologies MT2910 Family [ConnectX-7], 8 x 400 Gb/s NVIDIA CX-7 Ethernet (3.2 Tb/s total bandwidth, RoCE + RDMA)
These configurations provide flexibility for various workloads, ensuring optimal performance and scalability in OCI environments.
Getting Started with OCI AMD MI355X
If you are interested in learning more and getting hands on with this GPU offering, please get in touch with OCI GPU Sales at https://www.oracle.com/corporate/contact/
