Author
Irshad Buchh, AI/ML Engineering, Oracle
Raj Sharma, Field CTO, Hammerspace
Abstract
Organizations are increasingly leveraging Oracle Cloud Infrastructure (OCI) to run both modern cloud-native AI/ML pipelines and traditional High Performance Computing (HPC) workloads. While OCI provides the high-performance compute, low-latency RDMA networking, and scalable infrastructure required for these workloads, the data architecture requirements differ significantly between Slurm-based HPC environments and Kubernetes-native platforms.
This two-part blog series examines how Hammerspace can be integrated into two distinct OCI reference architectures:
- Part 1 (this post): OCI HPC/GPU Stack with Hammerspace for high-throughput, distributed data access across GPU and CPU clusters.
- Part 2: OCI HPC OKE Stack with Hammerspace, enabling scalable, Kubernetes-native AI/ML and containerized workloads.
In this first post, we explore how Hammerspace enhances the OCI HPC/GPU stack by providing a global data environment that delivers performance, namespace unification, and simplified data mobility across large-scale compute clusters.
The OCI HPC/GPU Stack is Oracle’s purpose-built high-performance computing platform on Oracle Cloud Infrastructure, designed to run traditional supercomputing workloads in the cloud without sacrificing performance, scalability, or architectural control. It brings together bare metal compute, GPU-accelerated instances, flexible VM shapes, and ultra-low-latency RDMA cluster networking into a tightly integrated environment that feels native to HPC engineers while delivering the elasticity and operational simplicity of cloud infrastructure.
Built around Slurm as the workload manager, the stack enables rapid provisioning of large-scale clusters that would traditionally require months of procurement and on-premises deployment. On OCI, these clusters can be deployed in minutes, scaled dynamically, and decommissioned when no longer required thus enabling true on-demand supercomputing. The OCI HPC/GPU Stack supports a wide range of performance-intensive workloads, including: AI/ML training, Computational fluid dynamics simulations for automotive and aerospace modeling, Crash simulation and structural analysis, Financial modeling and large-scale risk analysis, Biomedical simulations and genomics pipelines, Seismic processing and reservoir modeling, Trajectory analysis and mission design for space exploration workloads.
A key differentiator of the OCI is performance consistency at scale. Oracle’s flat, non-oversubscribed network fabric enables efficient scaling across thousands of CPU cores or large GPU fleets with minimal latency jitter. This deterministic performance profile is critical for tightly coupled MPI workloads and distributed AI training jobs, where network variability directly impacts application efficiency. When paired with a high-throughput parallel file system such as Hammerspace, the platform becomes an end-to-end architecture optimized for data-intensive HPC and AI environments.
Introducing Hammerspace: A Global Data Platform for AI
Hammerspace is a high-performance data platform designed to unify, manage, and optimize storage across public clouds, private clouds, and on-premises environments through a single global namespace. Rather than requiring data migration or forklift upgrades, it assimilates existing storage systems in place and makes them accessible through a unified, policy-driven architecture.
Built on open standards such as NFS v4.2 with pNFS, Hammerspace leverages metadata-driven automation to control data placement, performance tiers, and movement. Administrators can define policies that determine where data should reside based on performance requirements, cost considerations, or compliance constraints. This approach enables organizations to treat distributed storage resources as a single logical system while maintaining control over locality and efficiency.
The Linux-Native Architecture: Performance Without Agents
Hammerspace is architected natively within the Linux ecosystem, integrating directly with the Linux kernel and standard NFS protocols. No proprietary agents or client-side software installations are required on compute nodes. Using familiar NFS protocols such as v3, v4, and pNFS, it delivers high-performance, scalable file access in a way that feels natural to Linux administrators and HPC engineers.
This Linux-native design is particularly important in an OCI HPC/GPU environment:
- POSIX-Compliant Access Without Code Changes
Applications retain standard POSIX file semantics. No modifications to HPC applications or AI pipelines are required, and no client agents need to be deployed across compute nodes. From the perspective of the OCI HPC/GPU Stack, Hammerspace is simply mounted as another NFS file system. - No Job Re-Staging Requirements
Because access is delivered through NFS, all compute nodes in the Slurm cluster can access the same datasets regardless of where the underlying storage physically resides. This eliminates the need for manual data staging or duplication before job execution. - Seamless Integration with OCI HPC/GPU
Native NFS mounts can be configured easily within the OCI HPC/GPU Stack. Once mounted, data is immediately available to Slurm-managed jobs, reducing preparation time and simplifying workflow automation.
For HPC teams under pressure to scale capacity, support collaboration across environments, and modernize infrastructure, Hammerspace introduces cloud-like agility without disrupting existing operational models. Researchers can access shared datasets across clusters or geographic regions, pipelines become easier to automate, and infrastructure teams can control performance and cost through policy-driven data management rather than manual processes. The result is improved compute utilization and faster time to insight.
Integrating Hammerspace NFS Export with OCI HPC/GPU
You can deploy and configure a Hammerspace cluster on Oracle Cloud Infrastructure by following the official documentation. Step-by-step deployment guidance is available in the Hammerspace OCI installation guide: https://hammerspace.com/oci/
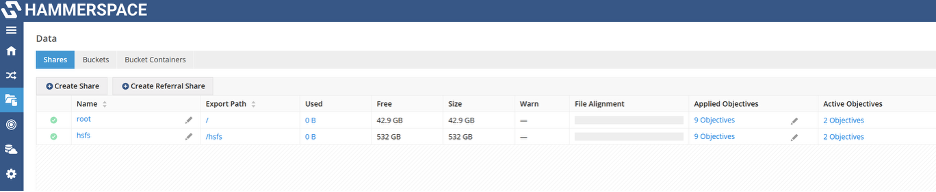
As part of the Hammerspace configuration, we created an NFS export named /hsfs. This export serves as the shared filesystem that will be integrated with the OCI HPC/GPU Stack. In the following steps, we will configure the Slurm-based HPC environment to mount and use this Hammerspace NFS export, enabling high-performance, scalable, and globally accessible storage for HPC workloads.
Deploying the OCI HPC/GPU Stack with Hammerspace Integration
To deploy the HPC Slurm environment, navigate to the OCI Console and follow:
Marketplace → All Applications → HPC and GPU Cluster → Launch Stack
Enter the required stack information and proceed to configure the variables. As you move through the configuration steps, you will see the storage options after the sections for Cluster Monitoring, Autoscaling, and API Authentication.
To integrate Hammerspace:
- Enable the Additional File System option.
- Add a new NFS file system.
- Provide the NFS export path created earlier,
/hsfs. - Specify the NFS server IP address, which is the internal cluster IP of the Hammerspace deployment on OCI.
- Set the NFS server path to
/hsfs.
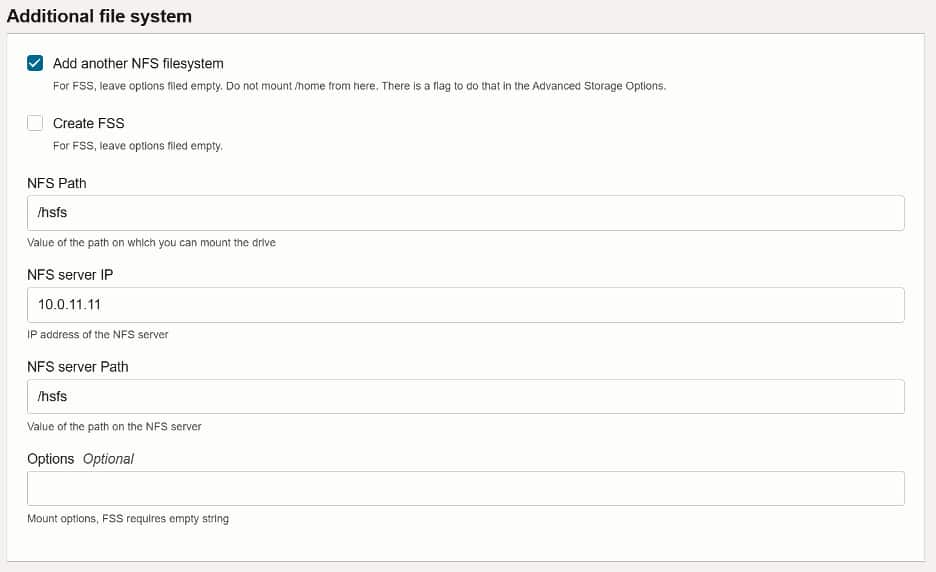
Once all parameters are configured, click Create to deploy the stack. The provisioning process will begin and may take several minutes to complete.
After deployment, review the Stack Job details to obtain the IP addresses of the Controller node, Login node, and Monitoring node. These endpoints will be used to access and manage the Slurm-based HPC environment.
Validation of Hammerspace Integration
With the Hammerspace filesystem provisioned and the OCI HPC/GPU Stack successfully deployed, the next step is to validate the integration.
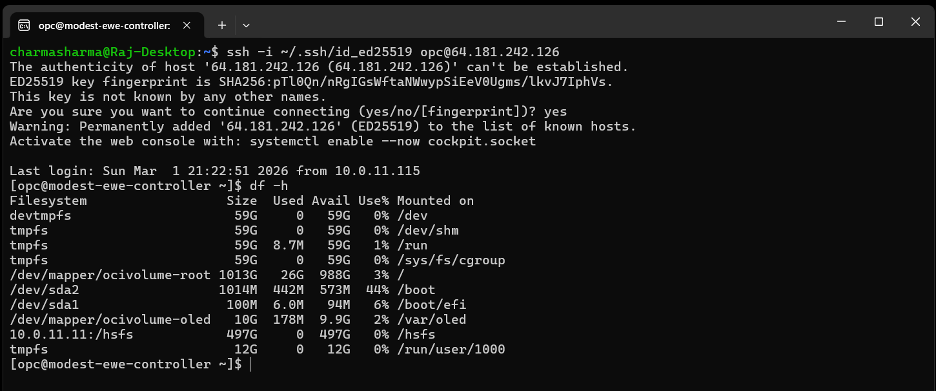
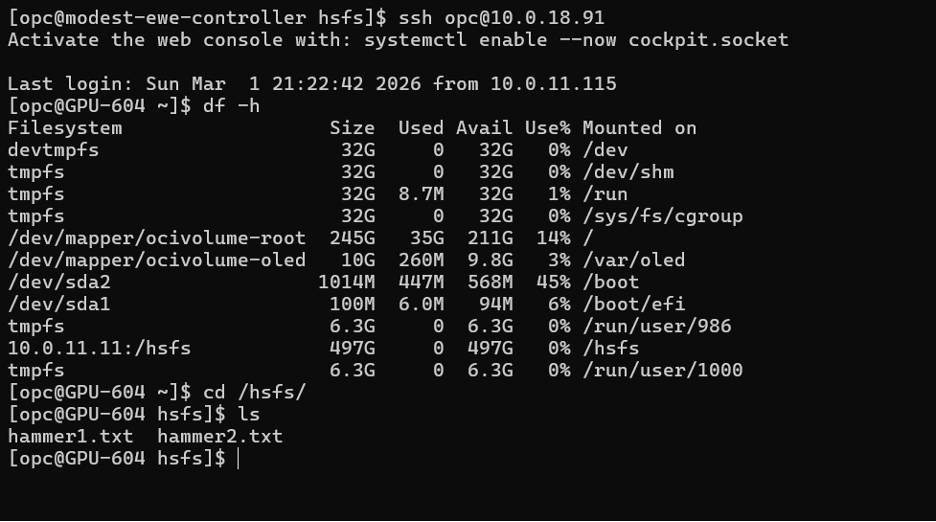
1. Verify the Mount on the Controller Node
Log in to the Slurm Controller node and run:
df -hConfirm that the /hsfs mount point is listed and accessible, indicating that the Hammerspace NFS export has been mounted successfully.
2. Create Test Files
On the controller node, create two test files:
touch /hsfs/hammer1.txt
touch /hsfs/hammer2.txt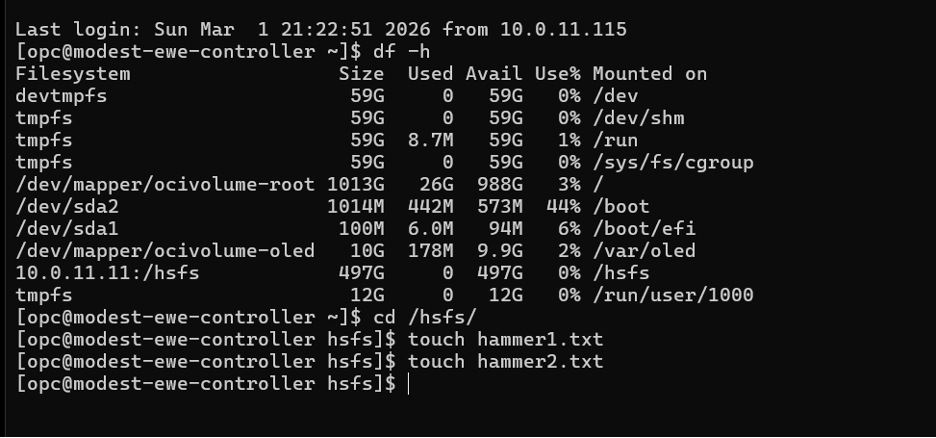
3. Validate from a Compute Node
Log in to one of the compute nodes and navigate to the /hsfs mount. Verify that both hammer1.txt and hammer2.txt are visible. This confirms that the filesystem is consistently mounted across the cluster and accessible to all Slurm nodes.
4. Verify via the Hammerspace UI
Finally, log in to the Hammerspace user interface.
Navigate to Shares → hsfs.

You should see the two files created from the controller node, demonstrating end-to-end visibility and confirming successful integration between Hammerspace and the OCI HPC/GPU environment. This completes the validation and confirms that the shared filesystem is fully operational across the cluster.
Conclusion
Integrating the OCI HPC/GPU Stack with Hammerspace provides a robust and scalable foundation for data-intensive workloads in the cloud. By combining Oracle Cloud Infrastructure’s high-performance, low-latency compute capabilities with Hammerspace’s Linux-native, NFS-based global data platform, organizations gain seamless, POSIX-compliant access to shared datasets across Slurm clusters without disrupting existing workflows.
This integration simplifies storage management while improving operational efficiency. HPC jobs benefit from faster startup times, consistent data visibility across nodes, and better overall compute utilization. At the same time, Hammerspace enables intelligent, policy-driven data placement that aligns performance, cost, and compliance requirements thus eliminating the need for manual data movement or complex storage reconfiguration.
For HPC teams modernizing their environments, this approach offers a practical path to cloud elasticity, hybrid data mobility, and scalable performance while preserving the familiar Slurm-based operational model.
In the next post, we will explore how these same Hammerspace capabilities extend to Oracle Kubernetes Engine, enabling high-performance data services for cloud-native and containerized workloads.

Raj Sharma
Field CTO, Hammerspace
