Oracle Cloud Infrastructure (OCI) customers have been running some of the most advanced AI workloads on OCI. Their success reinforces our strategy of providing the highest performance AI infrastructure, with powerful security and sovereignty controls, at the best value in the cloud.
At Oracle CloudWorld 2024, we’re excited to announce a host of new AI infrastructure capabilities across small, medium and large use cases, including the largest AI supercomputer in the cloud. We’re announcing the following features and offerings:
Orderable now:
- OCI Compute bare metal with NVIDIA H200 Tensor Core GPUs (Generally available later this year)
- OCI Compute bare metal with NVIDIA Blackwell GPUs (Generally available H1 2025)
- OCI Compute bare metal with NVIDIA GB200 NVL72 (Generally available H1 2025)
- OCI Supercluster with up to 65,536 NVIDIA H200 Tensor Core GPUs
- OCI Supercluster with up to 131,072 NVIDIA B200 Tensor Core GPUs
- OCI Supercluster with over 100,000+ GPUs in NVIDIA GB200 Grace Blackwell Superchips
- OCI Supercluster with RoCE v2 or NVIDIA Quantum-2 InfiniBand networking
Generally available now:
- OCI File Storage with high-performance mount target (HPMT)
- OCI Compute bare metal with NVIDIA L40S GPUs
- OCI Supercluster with up to 3,840 NVIDIA L40S GPUs
- OCI Kubernetes Engine (OKE) support for NVIDIA L40S GPUs
- OKE AI observability features
World’s largest AI supercomputer in the cloud
For AI companies with the most advanced requirements, OCI is now taking orders for the world’s first zettascale AI supercomputer1, available with up to 131,072 NVIDIA GPUs—more than three times as many GPUs as the Frontier supercomputer2 and more than six times that of other hyperscalers3.
Maximum Cluster Scalability Across Cloud Providers
| Cloud Provider’s Scalability (Based on Publicly Available Data) | |||||
|---|---|---|---|---|---|
| GPU Type in Cluster | OCI Supercluster | CSP 1: UltraClusters | CSP 2: AI Infrastructure | CSP 3: GPU Cluster | |
| NVIDIA A100 | 32,768 | 10,000 | Not publicly available | Not publicly available | |
| NVIDIA H100 | 16,384 | 20,000 | 14,400 | Not publicly available | |
| NVIDIA H200 | 65,536 | Not publicly available | Not publicly available | Not publicly available | |
| NVIDIA B200 | 131,072 | Not publicly available | Not publicly available | Not publicly available | |
| NVIDIA GB200 | 100,000+ | 20,736 | Not publicly available | Not publicly available | |
OCI Superclusters are orderable with OCI Compute powered by either NVIDIA H100, H200, or B200 GPUs, or GB200 NVL72. An OCI Supercluster with H100 GPUs can scale up to 16,384 GPUs with up to 65 ExaFLOPS of performance. An OCI Supercluster with H200 GPUs can scale to 65,536 H200 GPUs with up to four-times the peak FLOPS performance of clusters with H100 GPUs (260 ExaFLOPS). OCI Superclusters with Blackwell GPUs can scale up to 131,072 GPUs in a single cluster, with up to 2.4 zettaFLOPS (one zettaFLOP is 1,000 exaFLOPS) of AI compute power.
OCI Superclusters can be powered by RDMA over converged ethernet v2 (RoCE v2) with NVIDIA ConnectX-7 NICs and now with NVIDIA Quantum-2 InfiniBand-based switches for GB200 NVL72. Our cluster network fabric is designed to offer low latency and high bandwidth to deliver high performance at low cost to you. We use NVIDIA NVLink and NVLink Switch technologies to deliver performance at scale, both for training and inference, as they enable very fast GPU-to-GPU communication. OCI Supercluster with GB200, featuring liquid-cooled bare metal instances, is being developed in collaboration with NVIDIA and are based on the ultra-fast InfiniBand cluster networking protocol with support for NVIDIA Scalable Hierarchical Aggregation and Reduction Protocol (SHARP). The SHARP technology’s in-network processing capability reduces the amount of data being sent over the network and accelerates the performance of collective operations used in AI and machine learning (ML) by providing data processing and aggregation capabilities using the network switches.
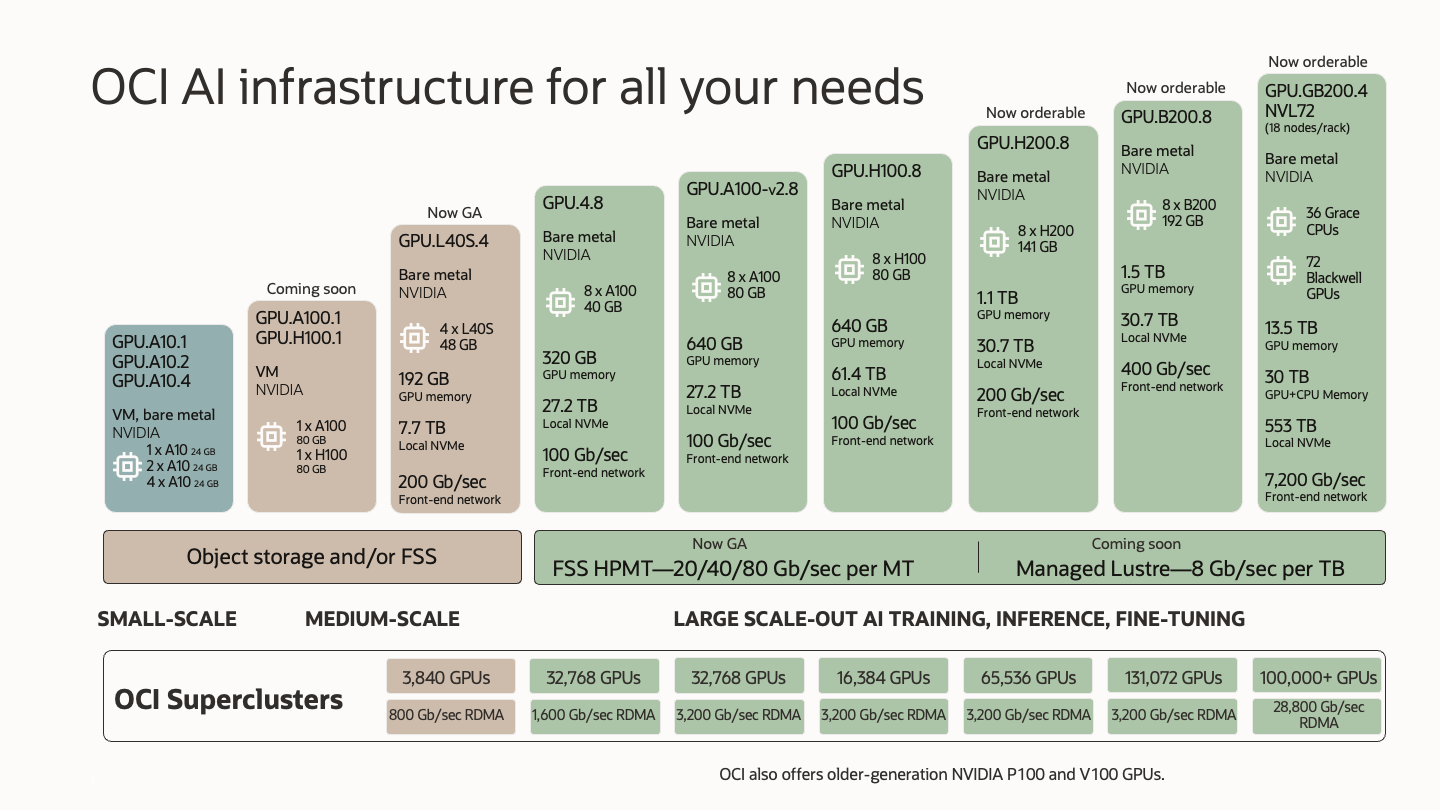
Broadest portfolio of bare metal GPU compute
To support a wider range of small, medium, and large use cases, OCI is broadening its lineup of GPU compute. We’re now taking orders for OCI Compute with H200 GPUs, B200 GPUs, and GB200 Superchips, and OCI Compute with L40S GPUs is now generally available.
NVIDIA Hopper architecture-based H200 GPUs offer powerful performance for training and inference of trillion-parameter models, with general availability coming soon. Generally available in 2025, the Blackwell architecture-based B200 GPUs and GB200 Grace Blackwell Superchips provide up to four times faster training performance and up to 30 times faster inference performance than H100, supporting AI models with multiple trillions of parameters and multimodal large language model (LLM) training and inferencing.
Extreme performance AI storage
We can now achieve terabits per second of throughput in a single file system with OCI File Storage and the general availability of its new high-performance mount target (HPMT) feature. We will also soon introduce a fully managed Lustre file service that can support dozens of terabits per second. To match the increased storage throughput, we’re increasing the OCI GPU Compute frontend network capacity from 100 Gbps in the H100 GPU-accelerated instances to 200 Gbps with H200 GPU-accelerated instances, and 400 Gbps per instance for B200 GPU and GB200 instances (7,200 Gbps aggregate capacity per NVL72 rack).
Providing a complete AI platform
You need a complete AI platform. We include supercluster monitoring and management APIs to enable you to quickly query for the status of each node in their cluster, understand performance and health, and allocate nodes to different workloads, greatly enhancing availability.
You continue to have quick and easy access to train and deploy generative AI applications with OCI Compute Bare Metal and OCI Kubernetes Engine (OKE). We have worked with NVIDIA to deliver a full-stack approach that includes software such as NVIDIA NeMo™ for developing custom generative AI or NVIDIA TensorRT-LLM for real-time inference. We’re enhancing AI observability for OKE, adding GPU and cluster monitoring. From an ecosystem perspective, we’re adding support for the Yunikorn and Volcano schedulers, enabling more choice.
Thanks to the monitoring and management features for cluster management, we can work with you to achieve and maintain the highest model FLOPS utilization (MFU) targets for their workloads as they optimize their training. With these new observability capabilities, we can help quickly resolve problems and maintain a targeted 95% uptime in clusters larger than 16,000 GPUs.
To use Arm-based CPUs in OCI Compute with GB200, porting may be required from the more common x86 platforms. NVIDIA’s support for existing libraries on Arm and Oracle’s deep experience porting over our software and services to Arm-based CPUs can help make this transition easy.
Sovereign AI solutions
OCI offers the unique ability to access comprehensive cloud services in distinct government clouds, EU Sovereign Cloud, on premises with Dedicated Region, or as a partner through Alloy. Each of these deployment options supports Oracle’s AI stack with the specific location, control, and governance you need to support a host of compliance and sovereignty requirements. This availability enables customers that want to build and maintain sovereign AI models in their country or retain AI-generated data with strong data residency controls. OCI Compute with L40S, Hopper architecture-based, and Blackwell architecture-based GPUs are now orderable for sovereign AI deployments.
OCI AI infrastructure is designed for all your needs
OCI offers a complete AI platform, ranging from single instances to the world’s largest AI supercomputer in the cloud with advanced compute, networking, and storage. The raw horsepower is complemented by improved observability and management for even the largest clusters, whether you’re using OKE or open-source schedulers. Our job is to provide a secure, scalable, performant, and highly available platform, whether your workload is enterprise inferencing, sovereign model tuning, or foundation model training.
Regardless of whether you prioritize fastest time to market, largest scale, sovereign AI, or compatibility with existing software, OCI can help you realize your AI goals in our distributed cloud. We’re excited to see what you can do with our AI infrastructure. To learn more, contact us.
Endnotes
1 NVIDIA: 155 PFLOPS of FP4 Inference performance for eight NVIDIA B200 GPUs
2 Oak Ridge National Laboratory: Frontier Supercomputer includes “more than 37,000 GPUs in the entire system”
3 Hyperscaler cluster scalability as documented on their websites at the time of publication
- OCI: OCI AI Infrastructure
- AWS: AWS UltraClusters
- Azure: Annual Roundup for AI Infrastructure Breakthroughs for 2023
- Google Cloud: GPU Machine Types
