On October 20, Oracle hosted an Oracle Live event to highlight how our customers are using new services on their own and together to build a data lakehouse architecture on Oracle Cloud Infrastructure (OCI). In this blog, we discuss how new services, such as the Big Data Service, Data Flow, as well as enhancements to Autonomous Data Warehouse, and the OCI Catalog, make it easier than ever for customers to build a data lakehouse architecture on OCI.
OCI customers are expanding from the data that they know to the data that they need
Our customers are tackling innovative new scenarios every day that require them to connect to, understand and analyze more data than ever before. Data from line-of-business (LOB) applications, devices, sensors, weather, or even what the local population is saying about disease. While we’ve had these systems in place for some time, the cloud and AI are accelerating our customers’ ability to easily connect, store, and understand all this information.
The new services introduced make it easy for OCI customers to migrate the data lakes that they’ve built on-premises or on other clouds to OCI without rewriting the solution, extend their existing data warehouse into a data lakehouse using the skills they have today, and easily understand and join real world data with their LOB application data, automating routine processes, or building accurate predictions.
Having a single analytics architecture that enables our customers to ingest, store and analyze all of this data, makes it possible to accelerate time to insight for these new scenarios. Customers need the choice of the most popular open source data services, rich data warehouse capabilities, and services to easily ingest and move data within the architecture depending on the scenario. Of course, they also need the ability to use AI to understand the new data types and predict accurate outcomes.
A data lakehouse architecture combines the best of the data warehouse and the data lake
The data lakehouse architecture brings together the rich, transactional capabilities of the data warehouse with the scale, flexibility, and low cost of the data lake. At the heart of the data lakehouse architecture is OCI Object Storage service, which enables our customers to create and store their data lake data at high scale and low cost. The open source services, such as Big Data, Data Flow, and Interactive Spark SQL, enable our customers to lift and shift or build new solutions using the latest and most popular open source tools, fully managed. For our customers that want to use the richness and scale of a transactional data warehouse, Autonomous Data Warehouse, and MySQL Database Service with Heatwave work within this data lakehouse architecture.
Another critical component is a single, unified place to store tables and metadata for the data within the data lakehouse. OCI Data Catalog is a managed service that provides this capability. Whether your team is writing Oracle SQL in Autonomous Data Warehouse or Spark SQL in Data Flow, you can easily discover, view, and query the same table definitions in OCI Data Catalog. Moving data into the lakehouse, data warehouse, or data lake is easy using OCI GoldenGate and OCI Data Integration service. OCI Data Integration also makes it easy to move data within the lakehouse architecture as you flexibly use services together as part of a larger solution. For example, our customers use the power of the Spark ecosystem to write data engineering tasks in Data Flow, and then move aggregated data into the data warehouse, or leave it in the data lake to query it at rest using Autonomous Data Warehouse.
Let’s review the three primary ways our customers evolve into a lakehouse architecture on OCI
1. Moving and modernizing existing and building new data lakes on the OCI data lakehouse architecture
Our customers move their Hadoop clusters to OCI because of the benefits that Oracle Cloud Infrastructure gives them to increase scale and security, while reducing operational expenses. We’ve completely rebuilt the Big Data Service, our managed Hadoop service, which is now based on Oracle’s own distribution of Apache Hadoop, to further strengthen these benefits.
Our customers get the latest in the Apache ecosystem value without the headache of operational costs. You can decouple compute and storage to scale computing resources when necessary and store data at scale for low cost as well as use the rest of the OCI ecosystem as you integrate your data lake with the rest of the OCI data lakehouse architecture.
For our customers who want the benefit and power of Apache Spark but without any infrastructure to deploy or manage, we provide OCI Data Flow. During the event, we announced Data Flow Interactive, a capability with sophisticated OLAP indexes for fast Spark SQL queries, and because it’s within Data Flow, it’s serverless.
2. Transform your data warehouse into a data lakehouse
Customers of Autonomous Data Warehouse can run fast and scalable queries from Autonomous Data Warehouse directly over any data in Object Storage. A single query can join data in Autonomous Data Warehouse and a data lake. For our current customers, this method is the fastest and easiest path to transforming their data warehouse into a data lakehouse. Existing applications and tools that work with Autonomous Data Warehouse now get transparent access to data lakes. Existing skills also work—no need to learn anything new. At the Live event, we introduced new integration between Autonomous Data Warehouse and OCI Data Catalog, so customers can discover, understand, and query against all data within the lakehouse easily.
Combined with Autonomous Data Warehouse, our customers now have the power of a data warehouse and the richness of Spark data engineering that together enables them to tackle the most advanced big data scenarios, without any infrastructure to manage.
3. Build a data lakehouse using SaaS data for intelligent SaaS analytics
A lot of our customers have advanced analytics scenarios that start with their application data. For example, we have customers that want to understand how weather, events or even customer feedback is going to impact their supply chains, and how they forecast demand. The OCI lakehouse architecture gives our customers everything they need to ingest, understand and build advanced analytics that can mean the difference between a good or bad quarter. In the event, we discussed how customers can use features like the OCI Data Integration Connector for Fusion to easily ingest their application data into their lakehouse architecture. Either using our existing AI services or building their own ML models using Data Science platform, our customers are now able to join and understand all data that impacts their business, accurately with the power of ML.
What our customers are saying about OCI
At the event, Experian and Ingersoll Rand joined us to share their use of data lakehouses on Oracle Cloud Infrastructure.
Experian accelerates financial inclusivity with a data lakehouse on OCI
Experian improved performance by 40% and reduced costs by 60% when they moved critical data workloads from other clouds to a data lakehouse on OCI. The move sped up data processing and product innovation while expanding credit opportunities worldwide.
Ingersoll Rand builds a foundation for advanced analytics with a data lakehouse on OCI
Ingersoll Rand consolidated multiple, on-premises enterprise resource planning (ERP) systems, data warehouses, and big data systems into a data lakehouse on OCI, giving the company a single source of truth for all data with better reliability and performance.
Data lakehouse implementations on OCI typically use one or all the following services:
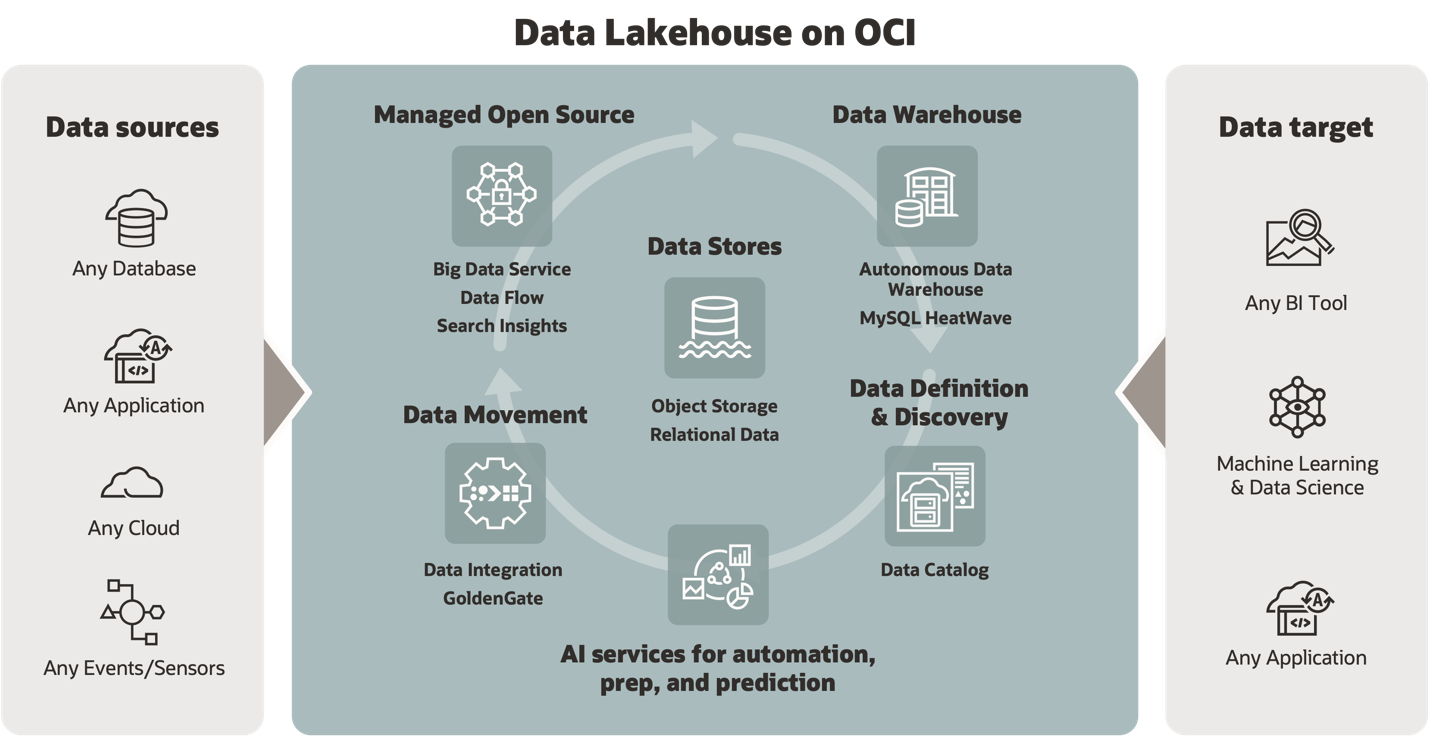
Managed open source services
- OCI Big Data Service: Provision open source data analytics, including Hadoop, Hive, Spark, and Hbase, integrated with OCI.
- OCI Data Flow: Process huge data sets with a fully managed Apache Spark service.
Data warehouse
- Oracle Autonomous Data Warehouse: Build a self-service data warehouse with Autonomous Data Warehouse.
- Oracle MySQL Database Service with HeatWave: Run MySQL applications faster with a low-cost, integrated, in-memory query accelerator for transactional and analytic workloads.
Data definition and discovery
- OCI Data Catalog: Metadata management to help discover data and support data governance on OCI.
AI Services
- OCI Anomaly Detection: Build business-specific anomaly detection models to detect critical incidents.
- OCI Language: Perform sophisticated text analysis at scale including sentiment, key-phrases, and named entities.
- OCI Digital Assistant: Broaden access to business applications with chatbots and conversational AI interfaces.
- OCI Data Science: Rapidly build, train, deploy, and manage machine learning models.
- In-database machine learning: Create and run in-database machine learning models using SQL, R, and Python.
Data movement
- OCI Data Integration: Easily extract, transform, and load (ETL) data for data science and analytics use cases.
- OCI GoldenGate: Managed real-time data replication to keep data highly available and enable real-time analytics.
- Data Integrator: Optimize high volume ETL/ELT data movement and transformation.
- OCI Streaming: Real-time, serverless, Apache Kafka-compatible event-streaming platform for developers and data scientists.
Data storage
- OCI Object Storage: Store any type of data in its native format at scale.
- Relational Data
Data lakehouse reference architectures
For detailed descriptions of data lakehouse patterns from Oracle architects, developers, and other experts knowledgeable of Oracle technologies and solutions, visit the Oracle Architecture Center. Review the following examples:
- Cloud data lakehouse – process enterprise and streaming data for analysis and machine learning: Use a cloud data lakehouse that combines the abilities of a data lake and a data warehouse to process a broad range of enterprise and streaming data for business analysis and machine learning.
- Design a data lakehouse for retail inventory analytics: With a need to capture a wealth of data, retailers are turning to cloud-based big data solutions to aggregate and manage data for real-time inventory visibility. A data lakehouse engineered on OCI can capture, manage, and gain insight from data produced from point of sale, inventory, customer, and operational systems to understand real-time inventory management.
- Design a data lakehouse for health insurance analytics: Health insurance providers need to analyze data across varied data sources for improving the claims management and customer experience, and preventing fraud. The data sources can include web transactions, office visits, phone transcriptions, billing, social media posts, and more. These sources are often siloed in multiple systems, without common storage, processing, or visualization tools.
- Analyze data from external object storage sources using OCI Data Flow: Your data resides in different clouds, but you want to analyze it from a common analytics platform. OCI Data Flow is a fully managed Spark service that allows customers to develop and run big data analytics, regardless of where their data resides, without having to deploy or manage a big data cluster.
- Analyse diverse data sources using OCI Data Integration and Oracle MySQL Heatwave: Your data often exists on-prem and within applications. OCI Data Integration is a serverless ETL service that can integrate almost any data from almost any source into a lakehouse, in this case, with Oracle MySQL Heatwave as the data warehouse component.
Want to know more?
If you want to know more data lakehouses on Oracle Cloud Infrastructure, you can review the recording of the Data Lakehouse Live event and hear from customers and experts. You can try data lakehouse architectures for yourself on Oracle Cloud Free Tier. Let us know what you think!