Oracle Cloud Infrastructure (OCI) offers a variety of compute instances that are specifically designed for machine learning, high performance computing, and AI/ML research and development. Like our BM.DenseIO.E4 / BM.DenseIO.E5 shapes, OCI GPU and HPC compute shapes also come with local NVMe SSD storage.
In this article, we ran FIO benchmark on Hammerspace’s Hyperscale NAS (Network-Attached Storage) solution running on a cluster of BM.DenseIO.E4 nodes (with 8 local NVMe drives) acting as dedicated file servers and hyperconverged client nodes to validate Tier 1 and Tier 0 storage performance respectively. For a production deployment, the BM.DenseIO.E4 nodes acting as hyperconverged client nodes can be replaced with OCI GPU/HPC shapes.
Hammerspace Hyperscale NAS & Tier 0 Storage
Hammerspace Hyperscale NAS is a new NAS architecture – a standards-based parallel file system architecture – that combines the performance and scale of HPC file systems with the simplicity of enterprise NAS, so you can meet the extreme performance requirements of GPU computing while reducing costs and complexity.
Hammerspace Hyperscale NAS unlocks a new tier of storage by transforming existing local NVMe storage on GPU servers into a Tier 0 of ultra-fast, persistent shared storage. Data placed in this local storage is no longer siloed within each GPU server but instead is part of a unified namespace.
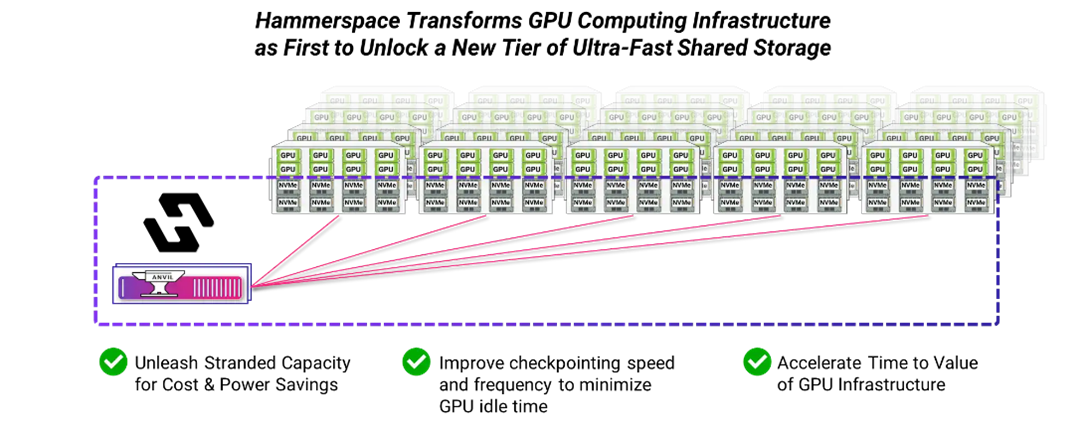
Figure 1: Hammerspace unlocks a new Tier of Ultra-fast Shared Storage
External storage subsystems, however fast, are as fast as the speed of the network connection between the GPU servers and storage. Any form of latency (usually from external storage) can cause slow job completion, underutilization of hardware, and excess cost.
Using local NVMe’s directly installed on GPU nodes (A10/A100/H100/H200/MI300X/L40S/B200/GB200) allows to address the bottlenecks and cost issues identified above. Using local NVMe’s via Hammerspace will allow us to see the performance difference between Tier 1 (external to the GPU client node) storage and Tier 0 (local to the GPU client node).
Benchmark Objective
The objective of this exercise with Hammerspace was to test the viability and performance of Tier 0 and performance improvement in comparison to Tier 1 storage solution.
Testing Methodology
We used a total of five OCI BM.DenseIO.E4.128 nodes because they come with locally attached NVMe SSDs. Dense I/O shapes are designed for filesystem, large databases, big data workloads, and applications that require high-performance local storage.
See more at: https://docs.oracle.com/en-us/iaas/Content/Compute/References/computeshapes.htm
Figure 2: Hammerspace Converged (Tier 0) on OCI benchmark architecture
Figure 3: Hammerspace Dedicated (Tier 1) on OCI benchmark architecture
Figure 4: Hammerspace Tier 0 with Tier 1 on OCI benchmark architecture
The test environment consisted of:
1 x Anvil
- Metadata Server
- Configure with Metadata drives in RAID1
- Running Oracle Enterprise Linux 8
2 x DSX
- Acting as the mobility server as well as Tier 1 (External to H100 applications)
- 8 x NVMe drives – each drive acting as its own NFS Volume
- Running Oracle Enterprise Linux 8
2 x Clients
- Configured as Clients as well as Tier 0 Servers
- 8 x NVMe drives exported as NFSv3 each
- Running Ubuntu 22.04
A 1 x 50Gbps network is used for connectivity from the Tier 1 DSX nodes to the client nodes. So, the aggregate throughput from Tier 1 to clients is 100Gbps or 12.5 GB/s.
Production Setup
High Availability (HA) for Anvil is generally required to ensure continuous access and data resiliency. However, when using Anvil Server with OCI Block Volumes instead of NVMe storage, data remains durable even if a node experiences a permanent failure. In this configuration, while the data is safe, downtime may still occur while services are being restored.
DSX is an essential component of every Hammerspace deployment. In addition to facilitating storage movement, DSX is responsible for balancing data across storage nodes and managing the process of “re-slivering” data after a node failure. It also serves as the primary gateway for SMB, NFS4.1, and S3 front-end protocols. For optimal performance and redundancy, it is recommended to deploy at least two DSX nodes. Based on requirements, DSX can run on Storage Nodes.
Figure 5: Hammerspace Converged (Tier 0) on OCI production architecture [1,2]
Figure 6: Hammerspace Dedicated (Tier 1) on OCI production architecture [1,2]
Figure 7: Hammerspace Tier 0 with Tier 1 on OCI production architecture [1,2]
[1] Production architectures may differ.
[2] If you are using BM shapes for Anvil or DSX, they will be deployed using KVM until Hammerspace adds support for iSCSI.
FIO Benchmark Test Configuration
Before we get to the results, it is important to create a schematic diagram showing the 4 FIO test runs. All the FIO data was driven from the two client nodes. For simplicity, we show files created by Client 1 in blue and files created from Client 2 in yellow.
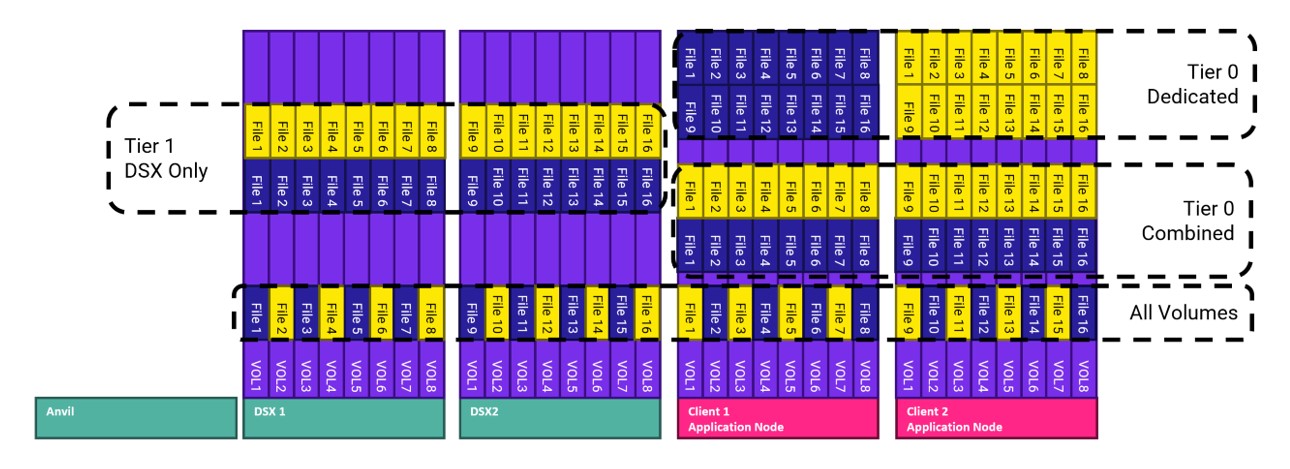
Figure 8: Data Placement
Tier 1 – DSX only
- Consists of volumes residing on the DSX nodes. These are external to the AI/ML application nodes. FIO files created in this configuration can only land on either DSX node 1 or DSX node 2.
Tier 0 – Combined
- Consists of the two Tier 0 application nodes combining their volumes into one volume group. FIO files created in this configuration can land on either Client 1 or Client 2.
Tier 0 – Dedicated
- In this configuration, all Client 1 files are “confined to Client 1”. All Client 2 files are “confined to Client 2”. This is achieved by a Hammerspace Objective. An objective can be applied to the share (or subfolder) and the objective will tell the client where to put the data.
All volumes
- This will write the files from Client 1 and Client 2 to all volumes in the namespace. FIO files created in this configuration can land on any of the storage nodes (DSX 1, DSX2, Client1, or Client 2)
The following FIO configuration was used for every test scenario above.
- Clients: 2.
- Per Client: Files: 16. Filesize: 50GB. Direct: True. Blocksize: 1MB. IO Depth: 2. IO Engine: libaio. Number of Jobs: 1 (Per File). Run Time=300.
- Workloads: 100% Sequential Read, 100% Sequential Write, 100% Sequential 50/50 Read/Write Mix,
- Iterations: 3. Results were averaged.
Results
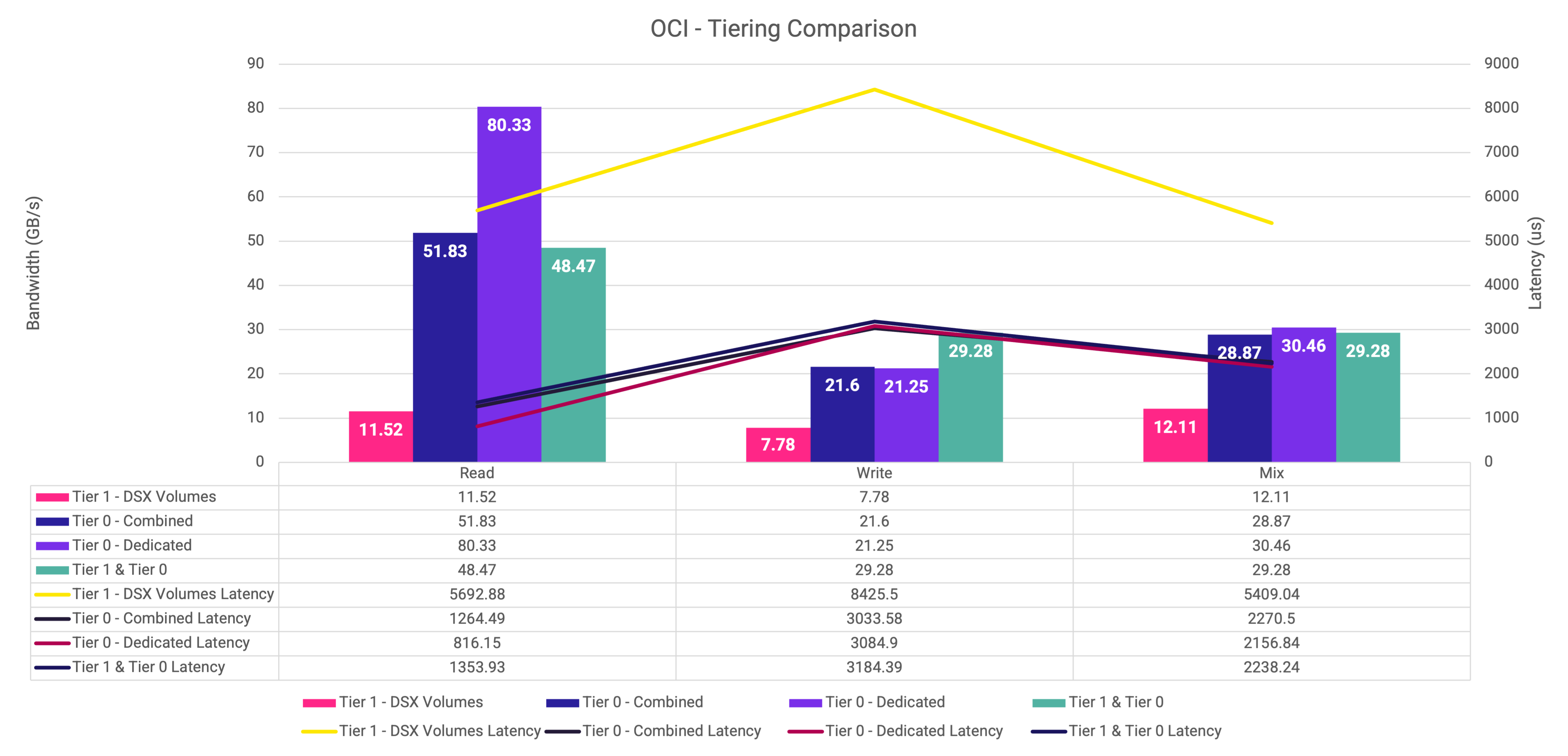
Figure 9: Graph representing the FIO results of each configuration of Hammerspace on OCI
Let’s breakdown the results based on the FIO run. We will start with all 4 configurations in 100% READ, then 100% WRITE, then 50%/50% MIX.
100% READS
As mentioned above in this blog, the network used for connectivity from the Tier 1 DSX nodes to the client nodes is via 1 x 50Gb network connection. So, the aggregate throughput from Tier 1 to clients is 100Gbps or 12.5 GB/s. As we see – we are right at that theoretical number for reads and the mixed workload. For writes, we are slightly above half that number.
Tier 0 dedicated reads were 80.33 GB/s. Recall that the dedicated configuration will use the “confine to” objective in Hammerspace ensuring that all data is local to the host. By using NVMe drives in the same host as the client application, we achieve:
A 597.3% improvement in read performance vs Tier 1.
A 54.97% improvement in read performance vs Tier 0 combined.
A 65.73% improvement in read performance over All volumes.
Tier 0 is the higher-performing, lower-latency storage layer available to an application server. Without the throttling of the networking, data processes exceptionally fast. In the context of real-world scenarios – No data starvation for the GPU = No wasted GPU cycles.
Now, turning our attention to Tier 0 combined. Tier 0 combined means the file has a fifty-percentage chance of being local to the application and fifty percentage chance it is not. So, the network plays a role. The results are still a 4.5x improvement over Tier 1.
Finally, All volumes (Tier 1 & Tier 0) will spread the data across all four nodes. The network latency is compensated by the fact this configuration has all 32 drives at its disposal (8 drives per node). Again, using Tier 0 as a part of this larger configuration increases read performance significantly vs Tier 1.
100% WRITES
What strikes out in this test is the fact there is a write limitation within the client nodes. Either it’s a limitation in the Linux kernel, the NFS servers mounted on the NVMe volumes, or a combination of both. This is evidenced by the fact that the Local IO write number (purple) and the Tier 0 combined (Dark Blue) are almost the same number. More investigation has to be done here to determine where the bottleneck is.
These numbers are still showing a significant improvement over the Tier 1 number. Just under 3x the performance. Once the write limitation is identified, we expect the delta between Tier 1 and Tier 0 to increase.
The “All volumes (Tier 1 & Tier 0)” bar graph shows the highest throughput which is primarily due to the greater resources allocated to this configuration. With four nodes, each containing 8 NVMe drives, the system can deliver significantly more I/O than the Tier 0 configuration that utilizes only half the number of nodes and drives. This is to be expected. It shows that Tier 0 can be beneficial in a Local I/O state (such as reads) as well as in a combined fashion with Tier 1.
50% Reads and 50% Writes
This configuration shows a similar pattern to the write configuration above. As expected, the Tier 1 case was the slowest of the 4 test runs. Like the write configuration, we are investigating the write bottleneck to see if we can expand the delta from all the Tier 0 cases and the Tier 1 case.
Latency
Tier 0 significantly reduces latency across all three workload types when compared to Tier 1. For reads, we saw a 7x improvement, writes were closer to 3x and mix was a 2.5x improvement in latency when dedicated Tier 0 was compared to Tier 1.
Assimilation and Data Orchestration on OCI
Hammerspace on OCI enables organizations to manage and serve data without first having to physically relocate it. This is accomplished by separating the data migration process into two key phases:
- Assimilation: Ingests all existing file and folder metadata, allowing Hammerspace to serve data immediately through its global namespace. This phase is quick and non-disruptive, bringing existing storage under management with minimal effort.
- Data Orchestration: Once assimilation begins, Hammerspace can start orchestrating the underlying data according to defined objectives. Data migration from the existing NAS can commence even before assimilation completes. Data is moved transparently between storage volumes, without downtime or disruption to clients.
This approach allows customers to migrate data from existing platforms to OCI using Hammerspace efficiently and with minimal disruption.
Designing Your Global Namespace
Planning for unified namespaces is critical to avoid complications during assimilation—especially when integrating multiple NAS sources or environments with multi-tenancy. It’s important to review and understand existing namespaces before proceeding.
After Hammerspace assumes control of the NAS namespace, data can be orchestrated seamlessly and invisibly to clients. Typical use cases include tiering cold data to object storage, migrating to new storage solutions, or implementing tailored tiering strategies that enables the data to reside on the optimal storage class.
Key Benefits
The Hammerspace assimilation process enables fast and low-impact NAS namespace migrations. By decoupling file metadata migration from the movement of physical files, organizations can significantly reduce downtime, risk, and complexity during both current and future data migrations.
Conclusion and Next steps
By running the Hammerspace solution on OCI Compute, our customers can build a single global namespace with Tier 0, Tier 1, or both types of storage, utilizing the local NVMe drives of Bare Metal GPU compute nodes and Bare Metal DenseIO storage compute nodes. Based on their throughput, latency, and cost requirements, customers can choose Tier 0 storage, Tier 1 storage, or a combination of both.
Ready to experience breakthrough performance? Contact Pinkesh Valdria at Oracle or ask your Oracle Sales Account team to engage the OCI HPC GPU Storage team. Also, visit the Hammerspace website to learn more about the Hammerspace on OCI solution.

