How OCI bet big on modern AI cloud
Over the past year, advances in AI models have driven an unprecedented demand for high-performance cloud infrastructure. To meet these demands, Oracle Cloud Infrastructure (OCI) selected the NVIDIA GB200 NVL72 rack-scale architecture, which integrates 72 NVIDIA Blackwell GPUs through high-speed NVLink™. This setup effectively transforms each rack into a single AI supercomputer, delivering up to 4x faster training and 30x faster inference performance. However, simply deploying advanced hardware wasn’t enough; OCI engineers needed to automate GPU management at rack scale to minimize manual overhead for customers.
To achieve this, OCI engineers pioneered a new set of APIs specific to architectures like NVIDIA GB200 NVL72 and NVIDIA GB300 NVL72. With these new APIs, customers can now manage hundreds of GB200 NVL72 racks with capabilities, such as:
- Resizing
- Impact-less host repair
- Whole rack monitoring and maintenance
In this blog, we’ll dive into the OCI API for GB200 NVL72, exploring its capabilities and how it enables OCI customers to unlock the true scale and power of GB200 NVL72 racks. We’ll also look at various challenges that OCI engineering teams overcame to deliver this solution that stands out among cloud providers.
OCI unlocks the true power of GB200 NVL72
In the GB200 NVL72 supercluster planning stages, OCI accepted the shift in AI infrastructure design , as GB200 NVL72 is only the first in a series of rack-scale architectures for AI and High-Performance Computing workloads and the broader industry is already standardizing similar rack-scale designs.
OCI wanted to enable maximum automation for management of large scale GB200 NVL72 deployments, while also providing peak performance. In working towards this goal , our engineering teams realized that the standard cloud infrastructure stacks that offer servers or instances wouldn’t suit GB200 NVL72 rack customers. Launching the whole rack as a single AI supercomputer in an optimized and scalable manner would take some creative engineering.
So, OCI teams reimagined how cloud APIs could harness the true scale and power of GB200 NVL72 data centers. The team created a new set of APIs specific to architectures like GB200 NVL72 and GB300 NVL72, as the primary method for customers to interact and manage hundreds of GB200 NVL72 racks. These APIs and their workflows are designed to hide the complexity of configuring and launching the GB200 NVL72 rack as a single supercomputer with optimized NVLink and RDMA with NVIDIA Quantum InfiniBand or NVIDIA Spectrum-X Ethernet with RDMA over Converged Ethernet ( RoCE ) configuration. They also allow for resizing, impact-less host repair, and whole rack monitoring and maintenance.
Let’s go through all the physical and logical resources that enable these new APIs to automate GPU management on behalf of customers.
GB200 NVL72 API overview – The new physical and logical resources
To start creating our APIs, we first need a representation of an NVLink domain. An NVLink domain is a set of hosts on a GB200 NVL72 rack whose GPUs are interconnected using NVLink technology. The NVL72 platform has 72 Blackwell GPUs across 18 hosts. Every GPU in the rack is connected via an NV Link Switch. A n NV Link Switch is a specialized NVIDIA accelerator that performs all-to-all switching in the NVLink traffic at 1.8 TB/sec, allowing fast and direct GPU-to-GPU communication for every GPU within the NVLink domain.
The NVLink domain is used as the scale-up network within a rack, and the InfiniBand or RoCE RDMA network is then used as the scale-out network across racks.
Our next physical resource is the ComputeGpuMemoryFabric, which is used to represent the physical NVLink Domain infrastructure (i.e. the GB200 NVL72 rack with its 18 hosts).
To use the ComputeGpuMemoryFabric, the customer must create a ComputeGpuMemoryCluster, a logical resource. The creation of a ComputeGpuMemoryCluster results in instances being launched on an underlying ComputeGpuMemoryFabric. A partition will be created that authorizes GPUs in ComputeGpuMemoryCluster to communicate with each other over NVLink while these instances are simultaneously added in the InfiniBand partition for scale-out network. More than one ComputeGpuMemoryCluster may be launched on a ComputeGpuMemoryFabric with different hosts, which enables running multiple isolated AI workloads on the same GB200 rack and is backed by NVLink and
NVIDIA Quantum
InfiniBand/
Spectrum
-X Ethernet
RoCE networks. Figure 1 details the Data Center network topology, including physical and logical resources below.
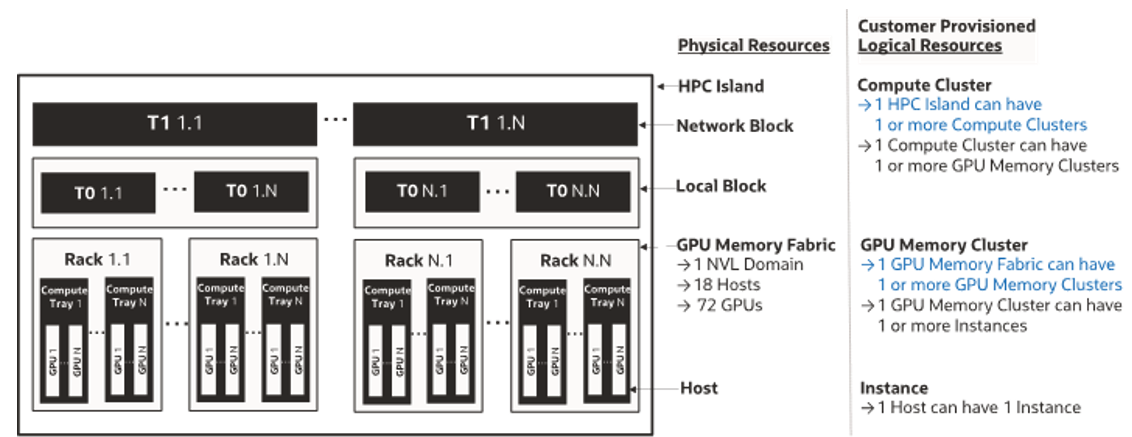
Figure 1: NVIDIA GB200 NVL72 rack physical and logical resources.
Key features & capabilities of GB200 NVL72 API
The GB200 NVL72 specific OCI APIs offer several advantages for managing bare metal GB200 NVL72 racks at-scale in the cloud. They enable efficient provisioning and management of AI workloads with optimized capacity utilization and automate repair and maintenance workflows. Here are some of the key potential benefits:
- Simplified Launch and Provisioning: Launching a NVL72 rack as a single AI supercomputer requires the correct settings for each host, NVIDIA NVLink S witch, and the NVIDIA Quant um InfiniBand or Spectrum-X Ethernet RoCE network between racks. OCI’s GB200 NVL72 APIs simplify all of this complexity in a single API call that launches the whole rack in the optimal configuration.
- Manage Large – Scale GB200 Deployments: These APIs offer fully automated workflows for capacity management, workload management, and host and rack level maintenance. This helps customers easily manage large scale deployments of hundreds of NVL72 racks in a region.
- Limit Failure Impact: GPUs can have higher failure rates than CPUs. These APIs are equipped with automation to add/remove individual hosts for repairs without impacting existing jobs on the rest of the rack.
- Topology – Aware Workload Placement: The Instance Metadata Service APIs provide details of GB200 specific NVLink and RDMA topologies to allow optimum workload placement. This helps enable maximum performance through maximum bandwidth and minimum latency.
- Declarative Configuration with Terraform: The APIs are also available through terraform and support Infrastructure-as-code for large scale declarative infrastructure management.
- Configurable NVIDIA NVLink Partitions in a Rack for workload Isolation: A single NVL72 rack can be configured to launch multiple NVLink groupings for smaller workloads and provide strong isolation for efficient workload distribution.
- Integration with OKE and K8s: Customers can integrate different orchestrators and schedulers to manage their workloads using these APIs in an easy and performant manner.
- Full and Secure integration of workloads with other OCI Cloud Services: These APIs enable NVL72 workloads to securely interact with most OCI cloud services and offerings in a performant manner.
- Observability and Monitoring: Using these APIs, the customer can get a good view of the status of their GB200 fleet including health and topology.
To reap these key potential benefits that can deliver highly efficient and performant AI workloads, our teams had to overcome some engineering challenges.
A technical deepdive of design benefits
Supporting InfiniBand and NVLink Control Planes in Cloud
Many control plane management software applications are traditionally designed to run as on-premises enterprise software. OCI Engineering’s approach involves deploying and operating these solutions as native OCI cloud services while replicating a customer’s intention. This method helps enable communication while maintaining tight control over security.
To do this, OCI runs continuous monitoring and reconciliation processes that are designed to early-detect any divergence between these NVL72 specific control planes and the customer’s intention. These automated processes aim to proactively correct inconsistencies in states and configurations of instances, as well as in the NVLink domain and InfiniBand/RoCE before they can affect customer workloads. They also help free customers from having to manage these challenges and cleanup resources after failed operations.
Enabling both node and rack level repair scenarios with customer voice
Because GPUs can have grey failures that are first visible to customers, OCI offers customers the choice to designate a GB200 host or the entire NVL72 rack, as defective. Customers can do this even when OCI monitoring reports that nothing is wrong with the host or rack. OCI integrates the repair workflow with its Validation Suite to root – cause issues and orchestrate repairs.
NVL72 is unique because a single failed hosts (a . k . a . Compute trays) can degrade the vertical capabilities of the whole Rack. Hosts also have higher failure rates, and a 10% host failure rate exacerbates to ~27% rack degradation rate. To help prevent all these potential failures, OCI designed APIs to continue a job on the rest of the rack even when a host tray is removed for repair. Most OCI repair recipes are specific to faults, and they are backed by well – modeled sparing and cannibalization processes.
If rack level components like NV Link Switch are faulted, the customer is notified for rack repair using the same correlation ID for draining the hosts. A Correlation ID is like a logical identifier which distinguishes individual host level faults from the faults affecting the whole rack.
Comprehensive monitoring of fabric hardware
OCI designed and implemented observability solutions to continuously monitor both hosts and NVIDIA NV Link Switches, enabling the collection of low-level telemetry and control data. This includes real-time visibility into switch health, port status, error counters, as well as hardware metrics like temperature, power consumption, fan speeds, and system faults.
Given the high volume and granularity of data, OCI leveraged high – throughput event streaming platforms to ingest and process telemetry at-scale. This data can then be transformed into actionable insights and visualized through comprehensive dashboards and reports. These telemetry resources provide multi-level visibility — from individual devices and racks up to an entire Region or Availability Domain.
Managing NV Link Switches
OCI handles provisioning and configuring NV Link Switches. This helps ensure the NVLink Domain is correctly configured during GPU Memory Cluster creation, update, and teardown on the GB200 racks.
We provision the NVLink Controller software and establish secure communication channels to interact with these devices, while also proactively identifying and repairing faults.
Maintaining firmware compatibility
A GB200 rack consists of multiple device types : Hosts, GPUs, and NV Link Switches — all of which must run compatible firmware versions to help ensure stable operation. To help maintain this critical compatibility, OCI enforces firmware version consistency across all components and will soon provide self-service Firmware management in G B 200.
Customers are able to specify their desired firmware versions, and OCI helps ensure the devices are provisioned accordingly, while enabling flexible and predictable firmware management at-scale.
Revolutionizing testing: From component-level to rack-scale validation
Traditional GPU infrastructure testing followed a fragmented approach, where individual components like GPUs, CPUs, network interfaces, and storage were validated separately before integration. OCI had to modify the testing paradigm for GB200, which consists of a rack with Compute GPU B200 Nodes connected by NV Link Switches through NVLink.
The GB200 NVL72 testing paradigm shift
With GB200 NVL72’s rack-scale architecture, OCI Engineering fundamentally reimagined our testing methodology. Rather than testing components in isolation, we now validate the entire rack as a unified supercomputing system, leveraging NV Link Switch as the central orchestrator for comprehensive rack-level testing. We launch GPU Memory Clusters using the same APIs that customers use so that our testing setup is as close to customer workload setup as possible.
NV Link Switch-orchestrated validation framework
The NV Link Switch infrastructure enables unprecedented testing capabilities:
- End-to-End NVLink Topology Validation: Every GPU-to-GPU connection across all 72 Blackwell GPUs are simultaneously tested through the NV Link Switch, supporting optimal bandwidth and latency characteristics across the entire fabric.
- Unified Memory Coherency Testing: The rack’s unified memory space is validated as a single entity, testing memory access patterns and coherency protocols that span multiple hosts and GPUs.
- Real-World Workload Simulation: Instead of synthetic component tests, we run actual AI training and inference workloads across the entire rack to better validate performance under realistic conditions.
Potential operational benefits of rack-scale testing
This holistic testing approach can deliver significant advantages:
- Faster Time-to-Production: Racks are validated as complete systems, eliminating the integration testing phase that traditionally occurred after deployment.
- Higher Confidence in Performance: Real workload testing across the entire fabric provides improved performance baselines before customer deployment.
- Predictive Failure Detection: Rack-level stress testing identifies potential failure modes that component-level testing cannot reveal.
- Streamlined Deployment: Pre-validated racks can be deployed directly into production with minimal additional testing overhead.
Power capacity and liquid cooling in the OCI data center
Deploying NVIDIA GB200 at-scale introduces significant challenges in both power delivery and thermal management. Each GB200 rack can draw over 120 kW at peak, exceeding the limits of traditional air-cooled infrastructure.
Power Capacity Upgrades
OCI data centers hosting GB200 NVL72 clusters have been re-engineered with:
- High-density power delivery, including dedicated 3-phase power feeds
- Dynamic load balancing for more sustained AI/ML workload performance
- Upgraded Power Distribution Units (PDUs) designed to support bursty training jobs
These enhancements help ensure full-capacity operation of GB200 racks without impacting overall data center efficiency or reliability.
Liquid Cooling: Now a Necessity

Figure 2: NVIDIA GB200 NVL72 Rack
Air cooling is no longer viable at this scale. OCI has adopted direct-to-chip cold plate liquid cooling for all GB200 systems, covering:
- CPUs, GPUs, and NV Link Switch components
- Coolant Distribution Units (CDUs) with redundant design
- Specialized cooling loops and fault-tolerant plumbing infrastructure
Here are the core benefits of utilizing liquid cooling:
- Lower Power Usage Effectiveness (PUE) through improved thermal efficiency
- Higher compute density per rack, enabling more performance per square foot
- Predictable thermal behavior, reducing hotspots and throttling risks
OCI’s investment in these advanced power and thermal systems helps ensure that our infrastructure can meet the demands of GB200 today, while providing a foundation for scaling to future-generation AI accelerators.
Touchless HPC configuration – Seamless plugins with GPU-optimized images
Traditionally, deploying HPC workloads on GPU clusters required manual configuration of NVIDIA CUDA, MPI, NCCL, and NIC parameters. This led to slower deployment times, inconsistent performance, and increased operational effort. Now, when a GB200 NVL72 cluster is launched using OCI GPU Images, Oracle Cloud Agent HPC Plugins can automatically configure the full software stack, optimizing based on hardware topology, with minimal customer input. These configurations also come with built-in:
- Real-Time Telemetry: Monitors GPU, memory, and network performance
- Adaptive Tuning: Adjusts communication strategies dynamically
- Predictive Optimization: Designed to learn from workload patterns across the OCI fleet
Conclusion
The new OCI API specific to AI supercomputing architectures like NVIDIA GB200 NVL72 and NVIDIA GB300 NVL72 allows OCI to stand out among cloud providers by enabling maximum automation for management of large scale GB200 deployments, while also allowing peak performance. Whether you’re a distributed systems engineer managing AI infrastructure, a platform engineer scheduling AI workload, or an enterprise leader who envisions creating the latest AI solutions, using OCI’s GB200 NVL72 infrastructure with dedicated API allows you to do much more with less manual effort.
The OCI GB200 NVL72 racks are now available for customers to try through the OCI AI Infrastructure page.
References
- OCI Announces First Zettascale AI Supercomputer
- OCI Deploys Thousands of NVIDIA Blackwell GPUs
- OCI HPC Plugins
