Overview
Oracle Kubernetes Engine (OKE) upgrades are typically planned around Kubernetes version compatibility, workload readiness, and maintenance windows. One dependency that is often overlooked is the worker image reference stored within a managed node pool.
Worker images and Kubernetes upgrades are often managed on different schedules. As a result, a node pool can continue referencing a worker image that has been retired or deleted. The issue may remain hidden until a worker node upgrade or node cycling operation occurs, at which point OKE may fail because the node pool still references an image that no longer exists.
This article examines why the issue occurs and presents a recovery workflow, validated in an OKE Enhanced Cluster, that allows a managed node pool to be recovered while preserving worker node metadata.
Why This Happens
A worker image is assigned to a managed node pool and later replaced by newer images as part of routine lifecycle management. Over time, older images may be retired or deleted while the node pool continues referencing the original image. When a worker node upgrade or node cycling operation is initiated, OKE may attempt to use the stale image reference, causing the operation to fail even though the upgrade itself is valid.
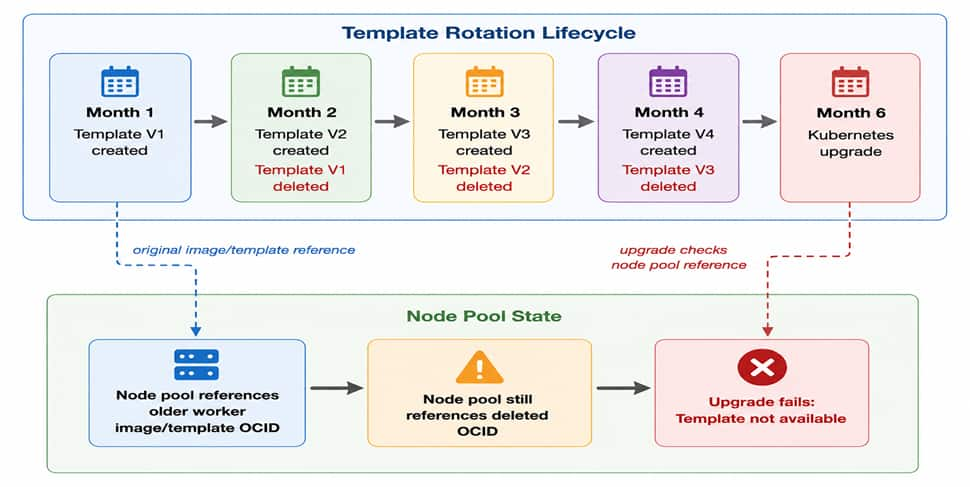
The Key Question
At first glance, a deleted worker image can make it seem like the node pool must be replaced before the upgrade can continue. However, there is a simpler question worth asking first:
Can the node pool be updated to reference a valid worker image before worker node cycling begins?
If the answer is yes, replacing the node pool may not be necessary.
Recovery Procedure
Testing was performed using an OKE Enhanced Cluster with a standard managed node pool. The control plane was first upgraded from Kubernetes 1.34.2 to 1.35.2 while the worker nodes remained at 1.34.2. The node pool was then upgraded to 1.35.2 after updating it to reference a valid worker image. The objective was to determine whether a node pool with a stale image reference could be recovered without replacement while preserving worker node network identity.
Step 1: Inspect the Existing Node Pool Configuration
oci ce node-pool get \
--region "$REGION" \
--node-pool-id "$NODE_POOL_ID" \
--query 'data."node-source-details"' \
--output jsonExample output:
{
"boot-volume-size-in-gbs": 50,
"image-id": "ocid1.image.oc1...redacted-old-image",
"source-type": "IMAGE"
}Step 2: Identify a Compatible Worker Image
oci ce node-pool-options get \
--region "$REGION" \
--node-pool-option-id "$CLUSTER_ID" \
--compartment-id "$COMPARTMENT_ID" \
--query 'data.sources[?contains("source-name", `"OKE"`) && contains("source-name", `"1.35"`)].["source-name", "image-id"]' \
--output tableStep 3: Record Existing Node State
kubectl get nodes -o wide
Step 4: Prepare the Upgrade
NEW_IMAGE_ID="ocid1.image.oc1.iad.redacted-current-v135-image"
TARGET_VERSION="v1.35.2"
CYCLING_DETAILS='{
"isNodeCyclingEnabled": true,
"cycleModes": ["BOOT_VOLUME_REPLACE"],
"maximumUnavailable": 1
}'
NODE_SOURCE_DETAILS='{
"sourceType": "IMAGE",
"imageId": "'$NEW_IMAGE_ID'",
"bootVolumeSizeInGBs": 50
}'
Step 5: Update the Node Pool
oci ce node-pool update \
--region "$REGION" \
--node-pool-id "$NODE_POOL_ID" \
--node-pool-cycling-details "$CYCLING_DETAILS" \
--node-source-details "$NODE_SOURCE_DETAILS" \
--kubernetes-version "$TARGET_VERSION"
Results
The upgrade completed successfully, preserving compute instance identity, VNIC attachments, and worker private IP addresses after the node pool was updated to reference a valid worker image.
kubectl get nodes -o wide
Why the Recovery Worked
The validation suggests that OKE requires a valid image reference when worker node cycling occurs. After the node pool was updated to reference a current worker image, the deleted image was no longer part of the upgrade workflow. Using BOOT_VOLUME_REPLACE preserved the underlying compute instance and, in the validated environment, retained the existing VNIC attachments and private IP addresses. By contrast, INSTANCE_REPLACE provisions new worker instances, which may result in different instance identities and network addresses.
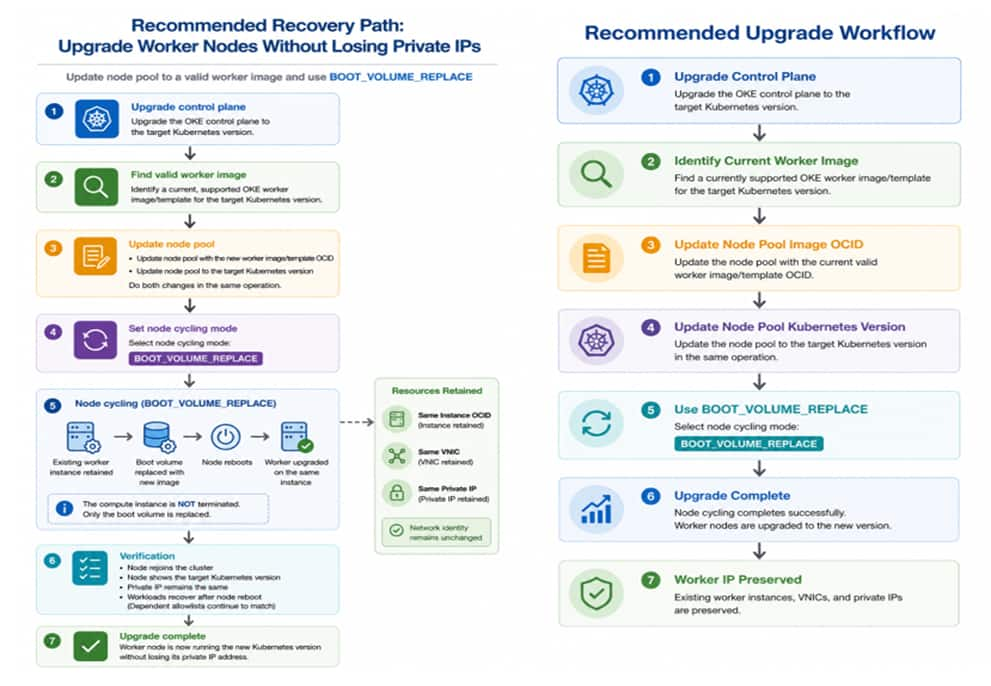
Recommended Recovery Workflow
If a managed node pool references a deleted worker image or template, update the node pool to use a valid worker image before upgrading the worker nodes. In environments where preserving worker node network identity is important, use BOOT_VOLUME_REPLACE during node cycling and validate node readiness after the upgrade completes.
Below Figures illustrate the validated recovery workflow and upgrade sequence used during testing. This approach removes the stale image dependency before OKE attempts worker node cycling.
Additional Scenarios and Design Considerations
Use Case 1: The Original Image Has Been Deleted and IP Preservation Is Required
This is the scenario validated in this article. If preserving worker node network identity is important, update the node pool to reference a valid worker image before upgrading the worker nodes and use BOOT_VOLUME_REPLACE for node cycling. In the validated environment, this approach successfully upgraded the worker nodes while preserving compute instance identity, attached VNICs, and private IP addresses.
Use Case 2: The Original Image Has Been Deleted and IP Preservation Is Not Required
If preserving worker node IP addresses is not a requirement, a blue/green node pool replacement strategy may be simpler. Create a new node pool using the desired Kubernetes version and worker image, migrate workloads, validate the environment, and then retire the original node pool. This approach can simplify rollback and may be preferable when broader infrastructure modernization is already planned.
Use Case 3: The Cluster Has Fallen Multiple Versions Behind
Long-lived clusters may face two independent challenges: a multi-version Kubernetes upgrade path and a stale worker image reference. For example, upgrading from Kubernetes 1.31 to 1.35 may require sequential control plane upgrades through intermediate versions before worker nodes can be upgraded. A stale image reference can block worker node cycling, while a multi-version gap can complicate the overall upgrade path. In these situations, first establish the supported control plane upgrade path, complete any required intermediate upgrades, validate workloads at each stage, and then resolve stale image references before upgrading worker nodes.
Other Scenarios
| # | Scenario | Recommendation |
| 4 | The original image still exists | Update node pools proactively before retiring older worker images. |
| 5 | The “Template OCID” is an Instance Configuration | Verify whether the dependency is an image, instance configuration, Terraform-managed resource, or another external dependency before proceeding. |
| 6 | The target image is incompatible | Validate architecture, operating system, GPU requirements, and Kubernetes version support before upgrading. |
| 7 | Infrastructure redesign is also required | Recover the node pool first. Perform shape, subnet, placement, or capacity redesign separately. |
| 8 | Workloads cannot drain successfully | Review Pod Disruption Budgets, replica counts, local storage dependencies, and maintenance windows. |
| 9 | External systems depend on worker node IPs | Prefer BOOT_VOLUME_REPLACE and evaluate long-term removal of direct worker IP dependencies. |
| 10 | Multiple node pools are involved | Inventory and recover one node pool at a time, validating results before proceeding to the next. |
Preventing Future Occurrences
The easiest recovery is the one that never becomes necessary. Before retiring worker images, inventory active node pools, identify image dependencies, update node pools to current images where appropriate, validate successful node cycling, and align image lifecycle management with Kubernetes upgrade planning.
Conclusion
Long-lived Kubernetes environments often accumulate hidden dependencies that remain invisible until a maintenance event exposes them. Stale worker image references are one example, capable of disrupting otherwise valid upgrade operations months or even years after the original image lifecycle has ended.
The validation described in this article demonstrates that a deleted worker image does not necessarily require node pool replacement. By updating the node pool to reference a valid worker image before node cycling begins, it is possible to recover the upgrade path and, when using BOOT_VOLUME_REPLACE, preserve worker node network identity.
More broadly, the exercise highlights the importance of treating worker image lifecycle management and Kubernetes upgrade planning as related operational processes. Regular image maintenance, proactive dependency validation, and staying reasonably close to supported OKE releases can help reduce upgrade complexity and avoid unexpected recovery scenarios.

