Introduction
It is well known that when the RMS Titanic sank in 1912, tragedy could have been avoided had the ship simply carried enough lifeboats for everyone onboard. The incident revolutionized maritime safety regulations and serves as a key example of why disaster recovery planning is so important. You don’t want to realize your plan was insufficient after your ship hit the iceberg.

Disaster recovery planning is always front and center for the core cryptography product services I work on at OCI. A solid plan is an essential prerequisite for these services, as most other OCI services require secrets, keys, and/or certificates before they can start up and serve traffic. As a result, our services can have very limited dependencies on other services to recover from a major outage. This is something we consider for every design and routinely revisit. During my time here, I have had a front-row seat to large-scale recovery testing where disaster recovery and break-glass mechanisms were put into place and saved the day. Other times, recovery did not go as expected, and we had to scramble to come up with a backup plan for the backup plan. In these cases, we thought we had a lifeboat, but when it encountered an unforeseen series of events, we discovered it had a hole (quick, patch it!).
Through these experiences, it becomes very clear why services need a solid set of strategies for disaster recovery. One central strategy is to have copies of recovery-critical data backed up to another, geographically-paired region. Our services indeed employ this strategy, and so we naturally wanted to offer it as a feature to our customers as well. Through interviewing our customers and learning about their use cases, we shaped the requirements for the feature. For example, we discovered that many of our customers preferred the option to replicate their secrets (like passwords, API keys, database wallets, etc.) to multiple target regions, not just one, to allow for a stronger disaster recovery plan.
I was very excited to take on the challenge of building a cross-region replication feature for OCI Secret Management Service so that we could address the needs of our customers and allow them to bolster their disaster recovery stories. But what is the optimal way to build a feature like this into our existing service while designing it to be robust, resilient, and not cause a hazard to existing functionality? A lifeboat could do more harm than good if it is left to swing free and crash a hole in the side of the ship.
Fastening the Lifeboats
Customers depend on Secret Management Service for critical functionality such as storing credentials necessary to access other systems. As a result, when we work on the design and development process for our service, we are always thinking about protecting stability and minimizing the blast radius of potential problems. Therefore, one of the first questions that came to mind when designing this feature was: once cross-region replication is enabled, how do we prevent source region operations from being impacted by the health of the target region? Even if the target region is down and updates to a secret cannot be replicated as a result, customers would still expect that the original source secret is modifiable and operates the same way.
To accomplish this, we introduced a new, asynchronous flow for processing cross-region replication via a separate message queue. When a secret with cross-region replication is created, modified, or deleted, it enqueues a message for replicating the secret across regions. If the configured target region of the secret is up and available, the secret will be successfully replicated, and the message will be removed from the queue. On the other hand, if the target region is down, replication will fail, and the message will simply remain safe in the queue, automatically receiving occasional retries until the target region is back up and replication succeeds. Meanwhile, because this is happening separately from the synchronous and asynchronous flows managing the source secret, customers can freely update the source secret without it being impacted by the issue in the target region.
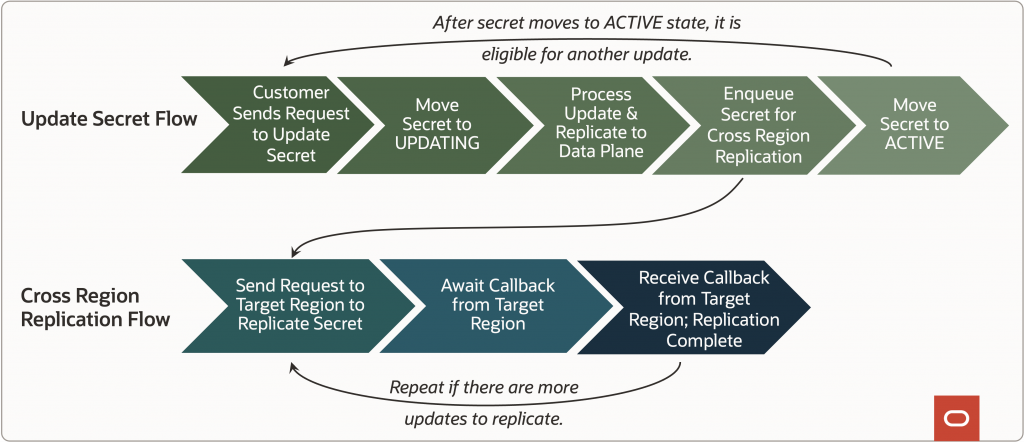
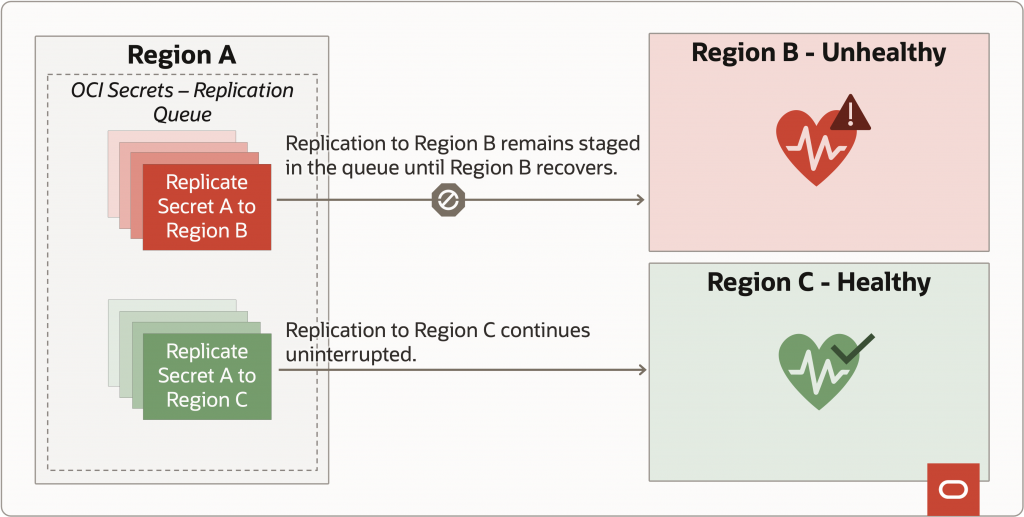
As mentioned in the introduction, while discussing the product requirements for this feature with our customers, we found that a key requirement was to be able to replicate secrets to more than one region. For example, to allow customers to have a geographically closer DR site (lower latency, easier fallback) and a geographically farther DR site (in case of a disaster impacting a larger geographic area). Upon considering this requirement, it became clear that the cross-region replication message queue needed to track separate messages per target region so failures in one target region would not impact replication to other regions, even for the same secret. For example, if the customer is replicating a secret from Region A to Region B and Region C, and Region B is down but Region C is up, replication to Region C should not be impacted by the outage in Region B. By using separate messages for each target region, replication to Region C can continue uninterrupted, while replication to Region B can be safely staged until the region is back up.
Protecting the Fleet
After considering how to protect the source region from target region issues, our next question was the reverse:how do we prevent an issue in the source region from spreading to the target regions?
A new challenge for us in designing this feature was to shift our mental model from thinking about our service as just a “regional” service to one that spans regions. Actions from the service in one region can now impact the service in another region, if we are not careful. It would be as if a fire started on one ship and then spread across a fleet of ships. One of the ways an issue could spread across regions is if data replicated from the source region is invalid or not understood by the target regions, so we need to prevent this.
One possible cause of such an issue would be a mismatch in schema changes. Let’s say that we add a property called “foobar” to the schema for a Secret. We make this change in Region A, but we don’t make the change in Region B, and then a secret with property “foobar” gets replicated from Region A to Region B. The problem is, Region B does not know about property “foobar,” so it can either:
- Try to accept it and potentially encounter processing issues as a result
- Accept it but discard the unrecognized property (which would mean that the replica secret in Region B would not be a true replica of the secret in Region A)
- Or reject the request
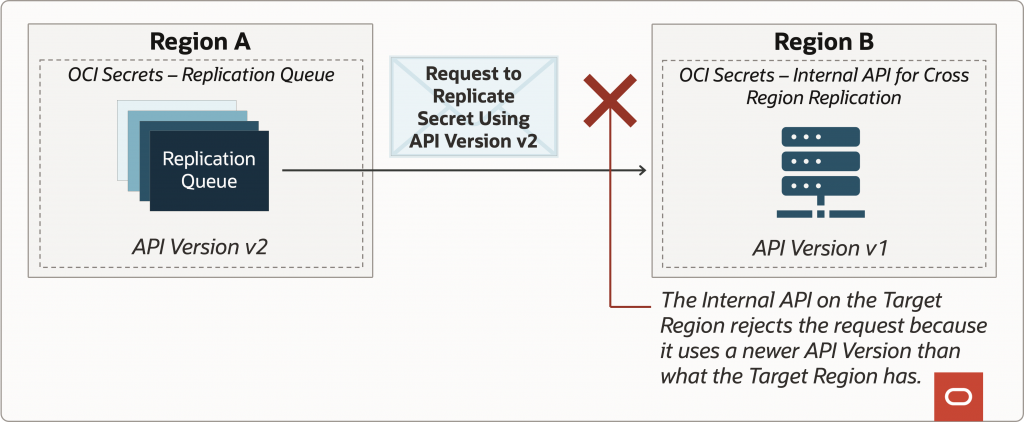
The last option is the safest and helps maintain the customer’s expectation that the replica secret is truly a replica, so we introduced versioning into our internal API used for cross-region replication. When schemas change, the version is updated, and if a region receives a request from a newer API version than what it currently has, it will reject the request. We strive to keep schemas in sync between regions, but this API versioning provides an additional safeguard.
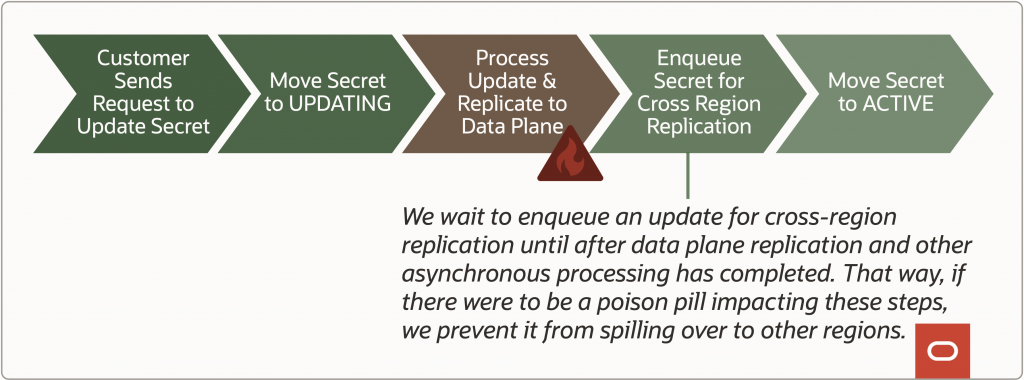
Another possible data issue that could have cross-region repercussions is if we let a poison pill impacting the source region to propagate to target regions. For example, if due to a bug, customers are able to modify their secrets in a way that the service does not know how to handle, asynchronous processing of the update or the replication of the update to the data plane component of our service could fail. Poison pills are unexpected by the system and can be difficult to deal with. Oftentimes, the best way to safely handle a poison pill is to modify the system such that it can recognize and appropriately handle the condition causing the poison pill. The problem is this generally requires rolling out a hotfix. Producing, testing, and deploying a hotfix takes time, so as not to accidentally introduce additional faults and instability into the system. While we are working to produce a hotfix and put out the fire in the source region, we don’t want the poison pill to have been replicated to other regions, expanding the blast radius of the impact and increasing the scope of work that needs to be done to return our service to a healthy state. To prevent this scenario, enqueuing a message to replicate a secret across regions is done at the very end of the asynchronous flow for processing a secret mutation. It happens after the mutation has been replicated to the data plane component and any other asynchronous processing for that mutation is completed. That way, if any of these steps are failing, there will not be any attempt to replicate that secret to another region until the issue is resolved.
Verifying Orders
In distributed systems, there are many things that can go wrong. For example, parts of the system may lose connection to each other, some processes may die unexpectedly, and a process may wake back up after a long pause. So, another problem we needed to solve was: how do we handle these situations by preventing replicas from accepting stale, out-of-order updates from the asynchronous replication worker processes?
Imagine the captain of a ship needs to send orders to crew members in a distant part of the ship. The captain sends a messenger to relay these orders but then receives new information and calls in a second messenger to relay a newer, conflicting set of orders. The first messenger is a new crew member who gets lost along the way and ends up arriving after the second messenger has already delivered the newer orders and left. Unfortunately, it is unknown to the crew members that the orders carried by the first messenger are outdated, so they accept them (in error) and begin carrying out the older orders instead of the newer ones.
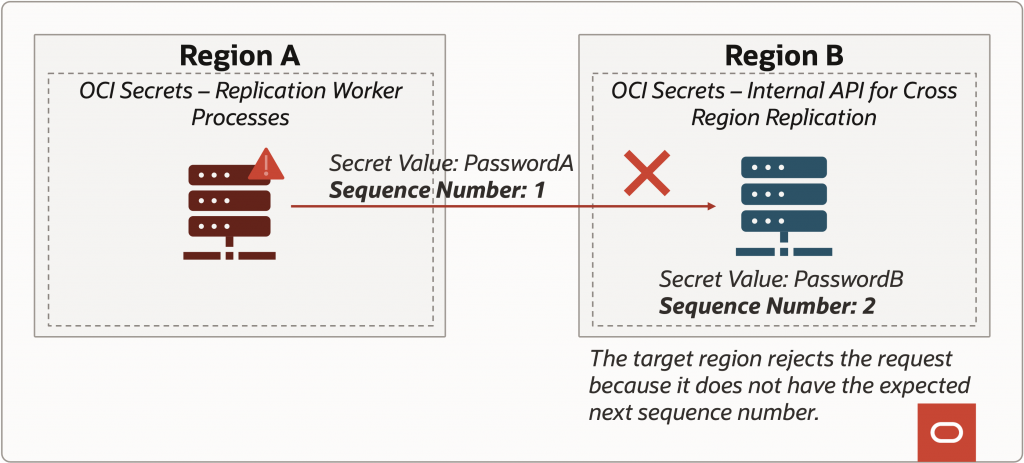
When replicating data, it is essential that the data is always replicated in order. If the customer sets a secret to Password-A and then quickly updates it to Password-B after realizing that they made a typo, we need to preserve the ordering such that the replica secret receives Password-B as the latest state, and not Password-A. Even with a message queue that sorts the messages in order, we cannot assume that this is sufficient for control. If a process responsible for replicating data to the target region gets blocked or delayed in sending Password-A, the overall system might assume that this process died and assign this work to a new process. The new process sends Password-A and then Password-B to the target region in the proper order, and the target region now has Password-B as the current password. But then, the original process wakes up and sends Password-A to the target region. How does the target region know that Password-A is outdated and to keep Password-B?
The solution is to associate a sequence number with each state of the replicated secret and havethe target region track that sequence number. If the source region sends a sequence number that is lower than what the target region has already processed, then the target region knows that this is an outdated state and rejects the request.
Conclusion
While building the Cross-Region Replication feature for OCI Secret Management Service, we had to validate that what we were building was right for our customers and right for our service—a disaster recovery feature designed for resiliency that can anticipate the potential for interruptions and outages. We wanted to provide a way for customers to strengthen their disaster recovery stories but did not want to make the same mistake as the Titanic by always assuming that everything would always be smooth sailing. We always hope to avoid those rougher, iceberg-filled waters, but with the protections we built into the feature, we intended to address those scenarios if they arise.
It was a very exciting experience to launch the feature, and watch customers try it out for the first time. We got to see them enable replication for their secrets and use it to prepare for possible disaster recovery use cases. We got to hear their feedback and use it to improve the feature, such as by simplifying the authorization model. I look forward to watching this feature grow and hearing more feedback from our customers so that we can continue to adapt this feature to their needs.
If you are interested in trying out the OCI Secret Management Service Cross-Region Replication feature, here are some articles to get you started:
