Introduction
The rapid evolution of artificial intelligence (AI) and machine learning (ML) is underpinned by exponential growth in data, model sizes, and hardware complexity. Networking is a key foundational component of the modern AI infrastructure. As organizations around the globe scale AI workloads to tens or even hundreds of thousands of GPUs, the demands placed on network infrastructure extend far beyond what traditional datacenter designs can reliably support.
Oracle Cloud Infrastructure (OCI) pushes the limits of scale, reliability, and efficiency with a major rethinking of cloud networking for AI. Oracle Acceleron’s multiplanar network architecture is OCI’s answer to the growing requirements for massive scale bisection bandwidth, predictable latency and resilience to faults. This innovative design combines physically and logically independent network fabrics, high radix switching with advanced cable management, and power-saving linear pluggable optics to create a network fabric capable of enabling the world’s largest and most complex AI clusters for next-generation Large Language Models as well as business critical enterprise workloads.
Multiplanar Network for Unprecedented Reliability and Scale
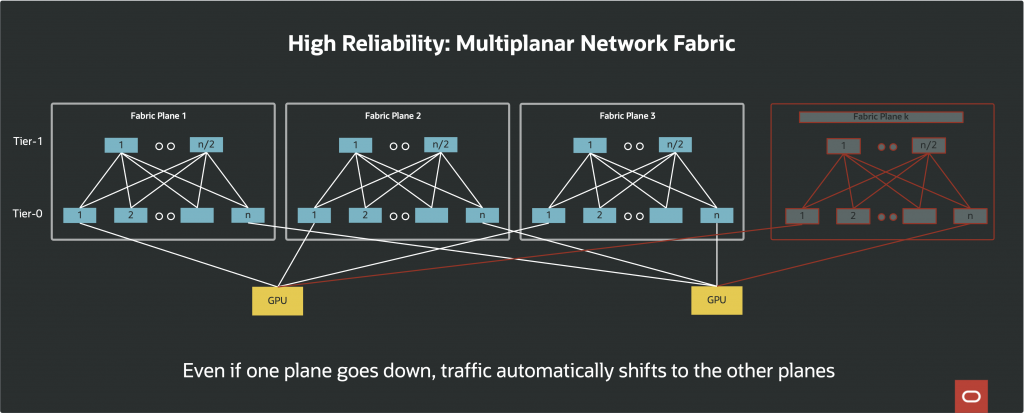
The multiplanar network consists of several completely independent network fabrics, or planes integrated to support AI clusters at a truly massive scale. Each plane is an independent Clos fabric. Each fabric plane has independent data and control planes; there is no physical or logical “fate sharing” between them. In networking terms, fate sharing refers to situations where a fault or disruption in one element (such as a switch, link, or control protocol) can propagate its effects to other elements, potentially resulting in a cascading failure or widespread outage. With multiplanar design, if a plane suffers a hardware fault, software bug, or congestion event, none of these issues impact the other planes. Network convergence events, such as link failures or recoveries, are also limited to a plane. As a result, the blast radius of even the most severe network faults is confined to a single plane.
This isolation is particularly important for AI/ML workloads since they require high bandwidth and are highly sensitive to disruptions. In a single-plane network, a link or switch failure can force expensive workload stalls or necessitate checkpoint/restart operations, which can mean hours or days of lost compute time on workloads that may already have been running for weeks. In contrast, the multiplanar approach provides instant fallback: if one plane experiences trouble, traffic is automatically shifted to use the healthy planes, enabling workloads to proceed without interruption or data loss.
Another aspect of multiplanar networks is its operational flexibility. Maintenance activities, NOS (network operating system) upgrades, and other administrative operations can be carried out on a single plane, minimizing customer impact. Since each plane is logically independent, it is possible to even run different versions of network switch software on different planes, allowing phased rollouts, staged updates, or rapid rollback without the risk of cluster-wide disruption.
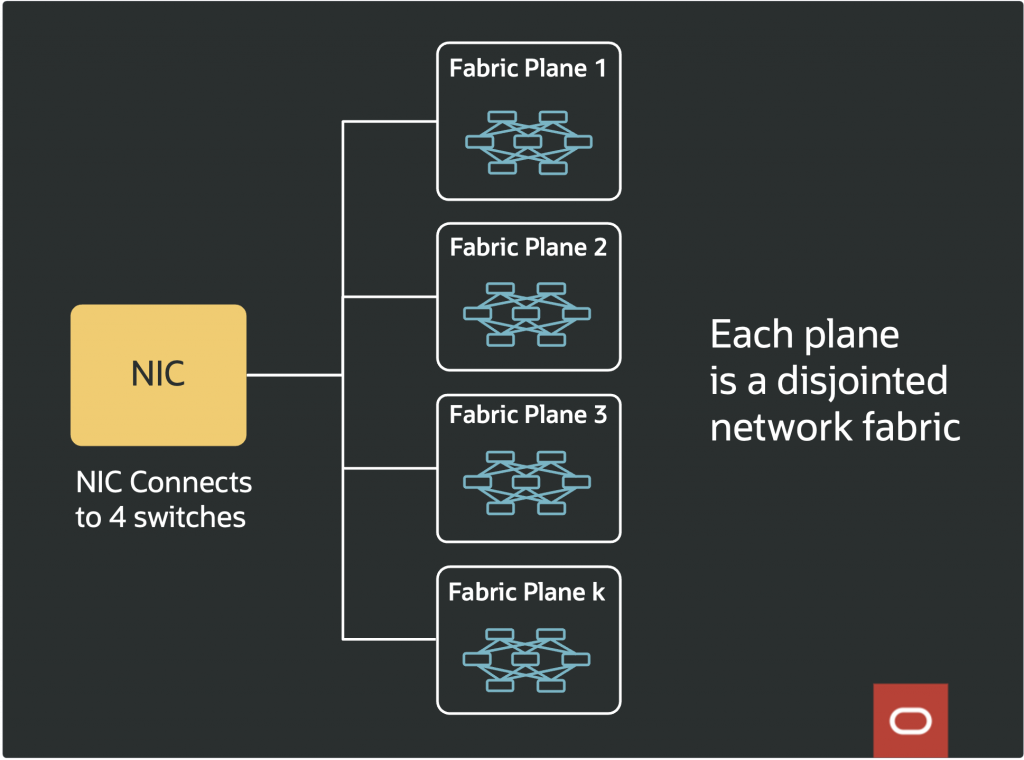
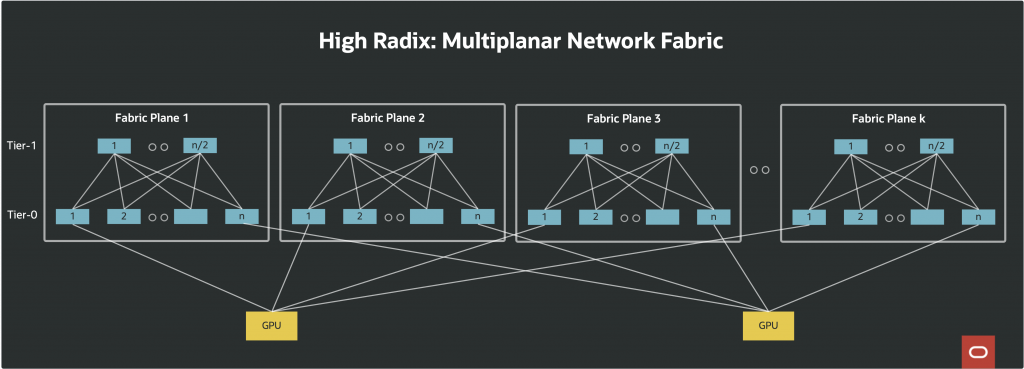
In terms of scalability, each plane contributes its full bisection bandwidth to the cluster. If a single plane can support a defined number of nodes at a given bandwidth, two planes double the number of nodes, three triple it, and so on. Each network interface card (NIC), such as an 800G GPU NIC, connects physically to multiple switches, one per plane. For example, a NIC might connect to four switches, each situated on a different plane, (e.g., using 4 x 200G links) rather than all links being redundantly connected within the same fabric.
OCI uses the multiplanar network topology to construct networks with higher aggregate bandwidth and reliability compared to single-plane networks, enabling clusters that can scale to 131,072 GPUs and beyond.
Cross-Plane Packet and Flow Management
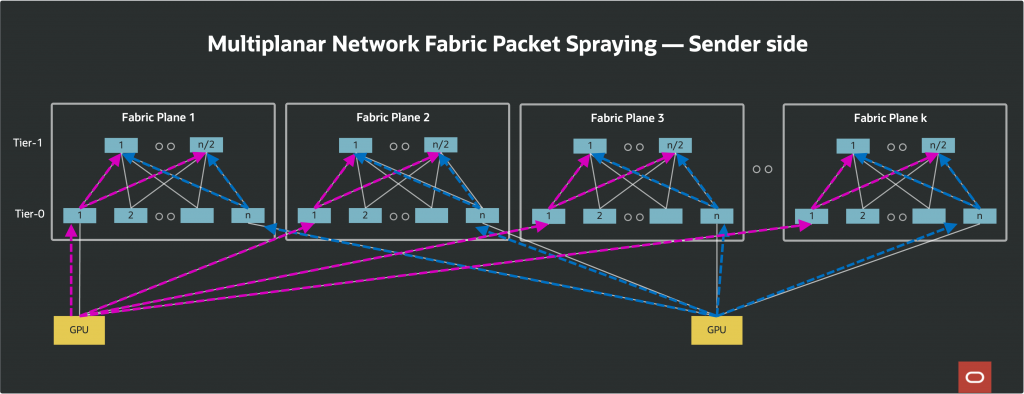
In a typical network, packet routing is usually driven by routing protocols across the network devices. With multi-planar network, typical physical network routing protocols is insufficient. By design, the network devices that are part of a plane lack sufficient insight across all the planes to make the best packet routing decision.
A key to the multi-planar networking is the packet routing logic at the edge of the network, specifically in the NICs. The packet routing logic at the edge of the network probes the network to identify optimal routes. This is handled by combination of firmware on the NIC and the software on the host / server.
In summary, multiplanar networks deliver the following technical advantages:
- True disjoint fabrics: No fate sharing, no single points of network-wide failure
- Load balancing and traffic engineering: Host software or NIC firmware can distribute load intelligently across planes, maximizing throughput and reliability.
- Scalable network capacity: Aggregate bisection bandwidth scales with the number of planes, allowing hyper scaling for AI clusters.
- Fewer tiers in network topology: Two-stage instead of three-stage Clos for most deployments, providing lower and more consistent inter-GPU latency.
High Radix Switches & Shuffle Cables: Scaling the Fabric Without Compromising Efficiency
A critical limitation on scaling any Clos network is the radix, the number of ports available on the switch silicon. Switches with a higher radix can fan out to more endpoints, supporting flatter network topologies (which have fewer tiers and less cumulative latency) and larger fabrics without requiring additional layers of aggregation.
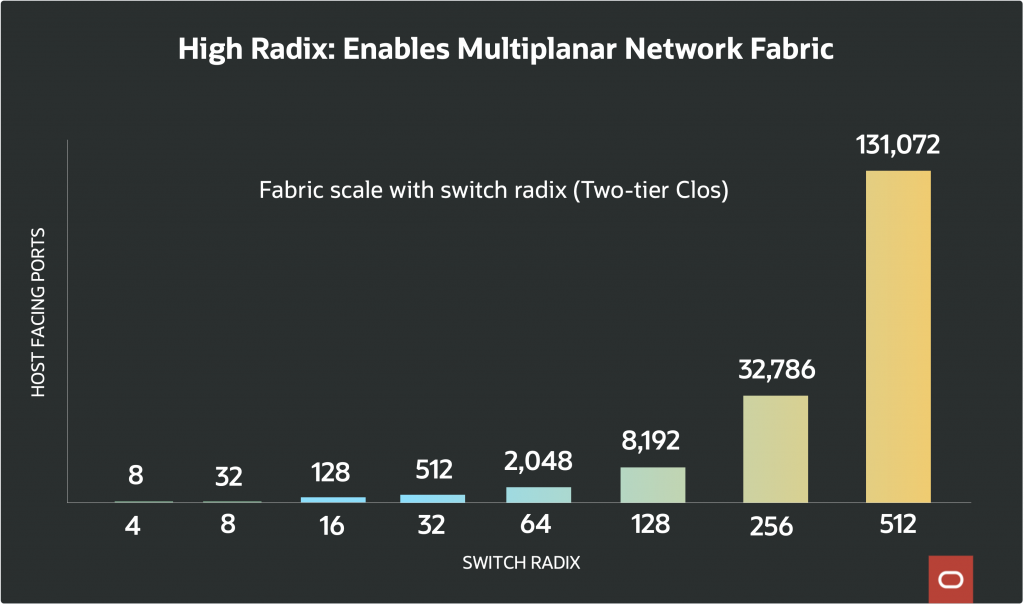
OCI’s multiplanar fabric architecture aims to maximize the advantages of high radix switches. A key enabler for scale is breakout cabling, which multiplies radix yet further. As an example, a single 800G port can be broken out into multiple independent lower-bandwidth ports – four 200G ports or even eight 100G ports.
By taking this approach, a 64-port 800G switch with 4x breakout per port gives 256 endpoints per switch at 200G each, multiplying the reach of each switch and flattening the network hierarchy. This increases the network radix at each tier without the need for more switches, dramatically lowering both capital expenditure and operational complexity.

With so many physical links and breakouts, cable management can become a logistical challenge, where thousands of GPUs (and millions of fiber strands) must be deployed and serviced. We use high density connectors to manage large numbers of fibers. These connectors group fiber strands together more densely than the logical connections. This necessitates shuffling logical channels among many physical connectors. OCI addresses this with shuffle cables or breakout cables designed to reduce physical clutter while maximizing connectivity. Shuffle cables allow both ends (the switch and the NIC) to fan out their connections in a structured manner, minimizing both cable bulk and the risk of miswiring, and supporting efficient large-scale rollout.
Cabling complexity is an often-underestimated barrier to cluster scale. By leveraging shuffle cabling with modular breakout harnesses, OCI reduces both the interconnect cost and the risk of human error in deployment. These structured cabling systems also facilitate rapid troubleshooting and modular replacement, which is crucial for maintaining uptime in massive AI clusters where service windows are rare, and interruption is costly.
Furthermore, reducing the total switch count (by maximizing effective radix per switch) means fewer devices to power, cool, and monitor, directly improving both energy efficiency and operational resilience. In effect, high radix switches combined with shuffle cabling geometry result in an “accordion-like” scale multiplier—an infrastructure that expands horizontally with high efficiency while maintaining manageability.
Energy Efficiency with Linear Pluggable Optics (LPO)
Modern AI workloads are extraordinarily power-hungry. Compute nodes loaded with high-end GPUs consume enormous amounts of energy. However, the network fabric itself (switches, optics, fans) accounts for a large and growing proportion of total datacenter power draw. For customers and cloud providers alike, every watt spent on networking is a watt not available for compute. Power efficiency is not just an environmental or cost concern; it directly impacts the maximum scale of AI workloads that can be supported in each facility.
OCI addresses this challenge using a new class of optical transceivers: linear pluggable optics (LPOs) and their close variant, linear receive optics (LROs). Traditional fully retimed optics (sometimes called FROs) use a pair of digital signal processors (DSPs) to handle signal modulation and error correction at each end of an optical link. While DSPs are powerful, they are also power-hungry.
Recent advances in switch silicon have integrated many of the DSP functions directly onto the switch ASIC, making it possible to operate optical links with fewer DSPs—or even none. LPOs require no external DSPs, and LROs require only one. Switching to LPOs can yield up to 4-7W per module in direct power savings; on a switch with 64 modules, this translates to savings of 250W to 500W per switch, without even counting reductions in cooling overhead.
The switches are generally air-cooled. The amount of airflow required is directly proportional to heat generated by the optics, and the power cost of fans increases exponentially with required airflow rate. Thus, trimming power draw at the optics layer has an outsized effect on total cooling cost and power budget. Fans can operate at lower speeds, and cooling infrastructure can be scaled back, leading to an overall greener, more sustainable datacenter.
The efficiency gains from LPOs become even more critical when operating the zettascale OCI superclusters, where incremental watt savings per module compound into megawatts across the fabric. More importantly for customers, these savings allow more of the facility’s power to be devoted to GPU workloads, meaning customers can run larger models, longer training runs, or more experiments within the same facility power envelope.
Most importantly, these efficiency gains are achieved without sacrificing network performance. LPO-enabled fabrics allow for throughput of 400G or 800G per link, maintaining OCI’s commitment to industry-leading network bandwidth and minimal latency.
Bringing It All Together: The Foundation for the Next Generation of AI
The Oracle Acceleron multiplanar network architecture creates the backbone for the next-gen AI workloads. By systematically addressing the twin challenges of scale and reliability, while also tackling the issues of power consumption and operational manageability, OCI is providing customers with the confidence to push their AI workloads further than ever before.
The result is a platform where:
- Resilience is engineered in at every layer, minimizing the impact of rare-but-high-impact failures on massive clusters.
- Latency and bandwidth are both preserved at scale, thanks to reduced network tiers and parallel planes.
- Massive AI/ML workloads can be run without fear of costly interruptions, with dynamic rerouting and plane isolation providing peace of mind for long-running, mission-critical computations.
- Operational flexibility is maximized, with the ability to perform staged plane upgrades and surgical maintenance.
- Sustainability is baked in, with intelligent decisions at the optics and switching layers freeing up power for customer workloads and lowering the overall energy footprint.
Conclusion
In an era where computing superclusters are powered by hundreds of thousands of GPUs, conventional network designs simply cannot deliver the necessary bandwidth, reliability, and efficiency. Oracle Acceleron addresses these challenges with the robust foundation for the network of the future with multiplanar design, high radix switches, shuffle cables and pluggable optics.
Key Takeaways
- High Reliability: OCI’s multiplanar architecture uses multiple, fully disjoint network planes, enabling traffic to quickly reroute in case of a failure in any plane. This eliminates fate sharing and reduces the impact of network faults on large-scale AI workloads.
- Arbitrary Scale: By leveraging high-radix switches with port breakouts and intelligent shuffle cables, OCI can efficiently interconnect hundreds of thousands of GPUs, supporting AI clusters of unprecedented size with a flatter, more manageable topology.
- Energy Efficiency: Replacing traditional optics with LPOs and LROs dramatically cuts the network power consumption by up to 30% per optic module. Reduced power and cooling demands allow more facility capacity for customer compute, enhancing scalability and sustainability.
- Operational Flexibility and Lower Latency: Multiple isolated planes and higher radix switches mean less need for network maintenance windows, easier upgrades, and more predictable, lower-latency connections across the cluster, which are critical for time-sensitive and data-intensive AI workloads.


