In modern data-driven environments, the main hurdle for high-performance compute clusters—especially when leveraging GPUs—is data access latency and I/O throughput. This inefficiency causes valuable compute resources to idle and significantly increases operational costs.
Alluxio addresses this issue by building a solution based on a tiered data architecture that bypasses these bottlenecks, resulting in better GPU utilization and higher return on cloud infrastructure investments. In this article, we show how the integration of Alluxio with Oracle Cloud Infrastructure (OCI) Object Storage and dense IO compute shape delivers sub-millisecond average latency, linear scalability of throughput, and nearly perfect GPU utilization without requiring data migration.
Key benchmark results
- MLPerf 2.0 [1]: sustaining 350 H100 Accelerators with over 90% accelerator utilization achieving throughput of 61.55GB (80+% NIC) with 6 BM.DenseIO.E5.128 nodes
- Warp test: sub-millisecond in average and p99 latencies
Alluxio High-Performance Cache Architecture
Alluxio serves as a near-compute data acceleration layer that sits between compute and OCI Object Storage. It intelligently manages data across memory and NVMe while exposing a unified namespace to applications through both POSIX and S3 APIs.

Alluxio’s architecture delivers the following core values for OCI users:
- Plug-and-Play Integration: Simply mount your OCI Object Storage buckets – no data migration from one storage to another. No import or refactoring required. Applications continue using the same object paths with zero code changes.
- High Performance Throughput and Latency: Sub-millisecond data access and TBs/sec of throughput – scaling near-linearly, reaching up to 80% of available network bandwidth.
- Consistency without Lock-In: Alluxio preserves native OCI Object Storage formats and provides consistency between cache and backend data. No proprietary formats or vendor dependencies.
- Flexibility to Go Multi-GPU Cloud: Alluxio seamlessly and automatically brings the right data to each GPU to deliver applications low-latency and high-bandwidth data access.
After caching or warming data from OCI Object Storage into Alluxio, subsequent reads are served directly from local NVMe or memory at orders-of-magnitude lower latency.
Deployment Flexibility: Dedicated and Co-located Modes
Alluxio supports two complementary deployment options on OCI:
Dedicated Mode (left): Alluxio runs on a cluster of DenseIO nodes which have NVMe drives and high network bandwidth per node. This cluster provides all required file and object services to external clients, maximizing throughput and consistency for large multi-GPU clusters.

Co-located Mode (right): Alluxio runs on the same GPU servers using spare NVMe drives, requiring no new hardware. This is the cost-effective model, ideal for compact clusters or single-tenant workloads. Performance can be slightly lower than dedicated mode due to shared CPU and cache resources between Alluxio services and user applications running on the same node.
This flexibility allows organizations to choose between absolute peak performance and operational efficiency, depending on workload scale and budget.
What This Means for Your Team
Consider an ML team training a large language model on OCI. They consistently see GPU utilization hover around 50% as their expensive compute instances wait for data from object storage.
By implementing Alluxio in Co-located Mode on their existing GPU servers, they immediately boost GPU utilization to over 95%. This single change could cut their model training time nearly in half, allowing them to iterate faster and deliver models to production ahead of schedule—all without changing a single line of application code or adding new hardware.
Benchmark
Configuration Overview
Test Platform – BM.DenseIO.E5.128: OCI Bare Metal DenseIO.E5.128 instances were used for both server and client nodes, each equipped with 128 OCPUs, 1500 GB of RAM, over 80 TB of local NVMe storage (12 × 6.8 TB in RAID 0), and 100 Gbps networking. This provides the ideal hardware backbone for Alluxio to deliver maximum performance.
Dedicated Mode: Six BM.DenseIO.E5.128 nodes are used as Alluxio services nodes. Another six BM.DenseIO.E5.128 nodes are used as client nodes. In case of one node solution, one BM.DenseIO.E5.128 is used as an Alluxio server and another BM.DenseIO.E5.128 is used as an Alluxio client.
Co-located Mode: Both Alluxio services and client workloads are running on the same six BM.DenseIO.E5.128 nodes.
OCI Object Storage: One S3-compatible bucket in the same OCI region is used as Alluxio Under File System (UFS).
Benchmarks: To evaluate performance, we used Warp S3 and MLPerf Storage 2.0 [1] benchmarks simulating real-world data access patterns.
Results Analysis: Extremely Low Latency and Scalable High Throughput
ML Perf Storage 2.0[1]
MLPerf® Storage is a benchmark suite to characterize the performance of storage systems that support machine learning workloads.
Test Setup:
- Model: Resnet50 v2.0
- Alluxio configurations: 6-node dedicated or co-located
Test Results:
| Deployment Model |
# of Alluxio worker |
Accelerators (Emulated H100) |
Mean AU (%) |
Sample Throughput (samples/sec) |
Throughput (GB/s) |
| Dedicated |
6 |
350 |
90.19 |
562,874 |
61.6 |
| Co-located |
6 |
200[2] |
97.39 |
347,491 |
38.0 |
Alluxio on OCI demonstrates exceptional GPU efficiency and scalability across both dedicated and co-located deployments when tested with MLPerf Storage 2.0 (ResNet50 v2.0).
- High GPU Utilization:
Sustained >90% Accelerator Utilization (AU) across all configurations, peaking at 97.9% AU in the co-located case where the number of supported accelerators is smaller due to resources sharing. - Dedicated Mode Efficiency:
In dedicated deployments, Alluxio supported 350 H100 GPUs with ~90% AU and ~82% NIC saturation, achieving 61.6 GB/s throughput—the optimal balance point before I/O saturation. - Cost Efficiency:
For co-located mode on shared GPU nodes, Alluxio reached 38.0 GB/s throughput and 97.4% AU, validating a lower-cost option that maintains high utilization with no extra hardware. - Production-Grade Validation:
MLPerf results help confirm Alluxio as a production-ready caching and orchestration layer for large-scale AI workloads—combining high throughput, low idle GPU time, and predictable scalability.
[2] In the co-located deployment, MLPerf Storage used CPU resources to emulate GPU workloads. As a result, Alluxio shared and contended for CPU cycles with the Accelerators (emulated H100) on the same sever. This led to only 200 accelerators compared to the dedicated setup. We expect that in real production environments the dedicated mode with isolated CPU resources will deliver superior and more consistent performance.
Warp Test
WARP is an open-source performance benchmarking tool specifically designed for S3-compatible object storage. It allows users to measure the performance of their S3-compatible storage solutions, such as MinIO or other object storage services, by simulating various workloads.
Test Setup:
- Alluxio configurations: clusters of 1 and 6-nodes
- Warp configuration: 1 and 6 nodes, separately from Alluxio nodes
Test Results:
The following charts show Warp GET performance from OCI Objet Storage, from Alluxio in 1-node configuration, and from Alluxio in 6-node configuration, all in dedicated mode.

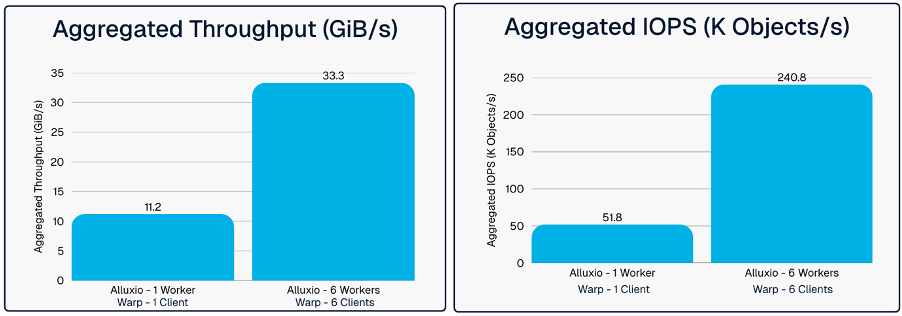
Alluxio on OCI delivers consistent sub-millisecond performance and near-linear scalability for S3-compatible object storage workloads benchmarked with Warp.
- Sub-Millisecond Latency:
For single node tests, Alluxio achieved very low and consistent latencies for warm GET: average being 0.3 ms and P99 0.4 ms. This shows superior performance of Alluxio with OCI compute BM.DenseIO.E5.128 nodes. - Predictable at Scale:
Even with six nodes, latency remained stable (0.6 ms avg, 0.9 ms P99), proving predictable responsiveness under scale-out conditions. As a reference, we did a measurement on Warp GET directly from object storage using six client nodes and got 24.1 ms for the average value and 311.4 ms for the P99 value, with a understanding that the performance would vary with respect to factors such as workloads of the object storage system. It can be seen that Alluxio with caching can improve the performance by 1 to 2 orders of magnitude. - High IOPS Scaling:
Aggregate IOPS rose from 51.8 K to 240.8 K, a 4.6× improvement over 1 worker node, showing that additional workers directly translate to higher request concurrency. - Horizontally Scalable Throughput:
Throughput increased from 11.2 GiB/s (1 node) to 33.3 GiB/s[3] (6 nodes), with minimal latency impact. - Operational Impact:
By maintaining data locality near compute, Alluxio eliminates idle GPU time and fully utilizes OCI infrastructure, maximizing efficiency for AI and analytics workloads.
[3] Warp does not support “HTTP 307 temporary redirect”, as a result an additional internal hop within Alluxio workers was introduced during data transfer. This limitation effectively reduces the maximum cluster throughput by about half compared to other benchmark tools like Cosbench which supports “HTTP 307”.
Conclusion and Recommendations
Our benchmarks conclusively prove that combining Alluxio with OCI’s high-performance bare-metal instances is a powerful strategy to eliminate data access bottlenecks in AI/ML and big-data analytics. By creating a performance-oriented data tier close to applications, this solution unlocks the full potential of OCI compute and GPU resources—delivering both speed and consistency at scale.
Key Advantages:
- Sub-millisecond average latency and 5× faster data access verified by Warp benchmarks.
- Consistent data layer with a single s3:// endpoint for transparent integration and accuracy.
- Near linear scalability 61.55 GB/s throughput (with minimal latency increase) for six nodes connected by 100Gbps network.
- Maximized GPU utilization: MLPerf results show 90–97 % Accelerator Utilization up to 350 GPUs[1].
- Flexible deployment: Co-located for cost efficiency, dedicated for maximum performance.
- Multi-GPU cloud ready: Get sub-ms latency and full throughput wherever your GPU servers are located.
- No data migration required: Data remains in OCI Object Storage with full consistency.
For organizations looking to maximize OCI’s compute efficiency, accelerate AI innovation, and simplify operations, Alluxio on OCI delivers validated, production-ready performance—without data silos, duplication, or configuration changes.
Ready to try Alluxio on OCI or learn more? Contact Pinkesh Valdria at Oracle or ask your Oracle Sales Account team to engage the OCI HPC GPU Storage team.
[1] MLPerf® v2.0 Training ResNet-v2.0. Result not verified by MLCommons Association. Unverified results have not been through an MLPerf review and may use measurement methodologies and/or workload implementations that are inconsistent with the MLPerf specification for verified results. The MLPerf name and logo are registered and unregistered trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use strictly prohibited. See www.mlcommons.org for more information.

