![]()
This article introduces Oracle Cloud Infrastructure Data Flow SQL Endpoints, Oracle Analytics Cloud, and explains how you can connect to Data Flow SQL Endpoints from Oracle Analytics Cloud.
Data Flow SQL Endpoints
Oracle Cloud Infrastructure (OCI) Data Flow SQL Endpoints allow engineers to interactively query data directly where it lives in the data lake in native formats without transforming or moving it. Data Flow SQL Endpoint is built on Spark for scalable, easy reading and writing of structured and unstructured data and interoperability with existing services. It supports all the file formats supported by Spark, such as Parquet, ORC, JSON, CSV, Avro, and so on. Data Flow SQL Endpoints enable you to economically process large amounts of raw data with cloud-native security. You can use token and API key authentication to connect to a Data Flow SQL Endpoint.
Oracle Analytics Cloud
Oracle Analytics Cloud (OAC) is a scalable and secure Oracle Cloud service that provides a full set of capabilities for exploring and performing collaborative analytics.
With OAC, you also get flexible service management capabilities, including fast setup, easy scaling and patching, and automated lifecycle management.
High-Level Flow
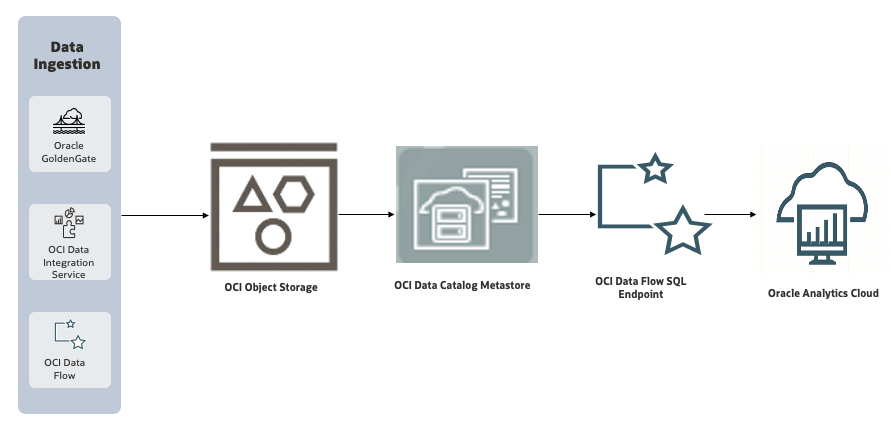
Data Catalog Metastore
The Data Catalog Metastore is a centralized, managed service within OCI that provides a unified metadata management solution. It acts as a metastore for organizing, discovering, and managing metadata for data assets across the cloud.
Prerequisites
Refer to the documentation for prerequisites and how to set up the required IAM policies.
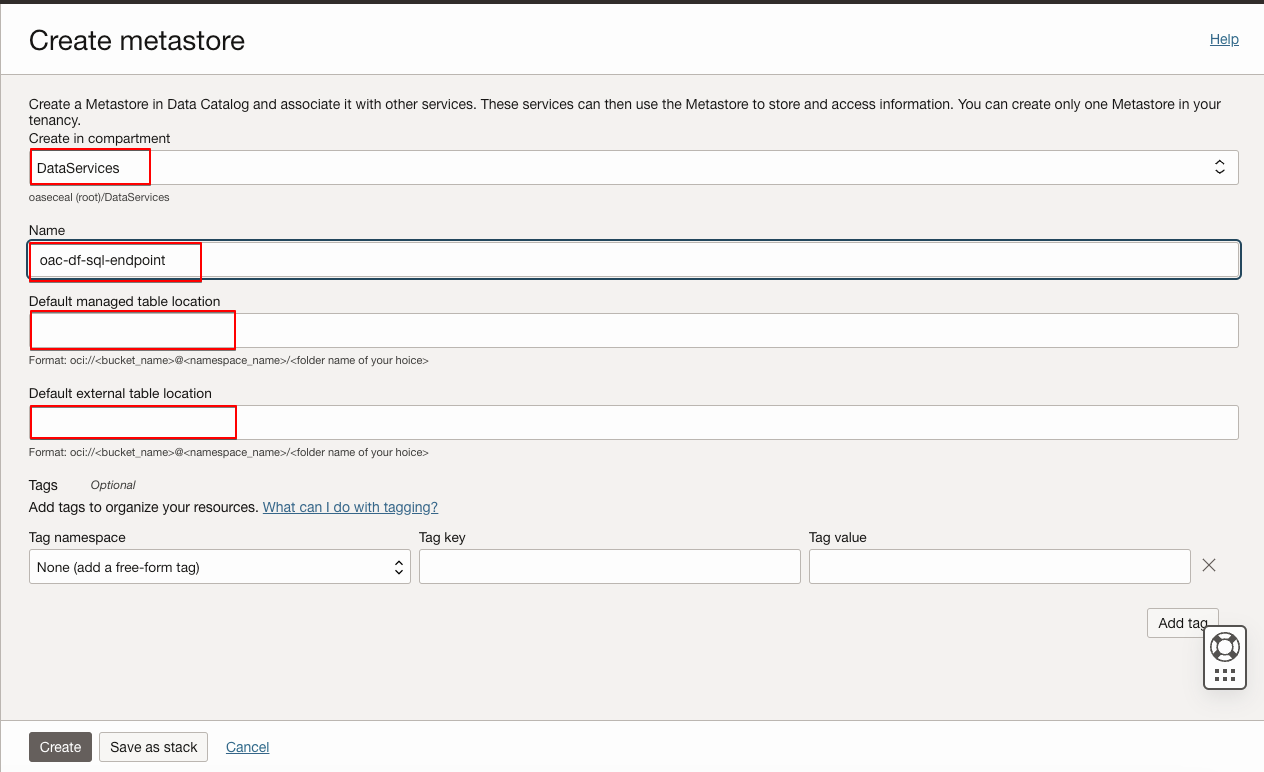
Create a Data Catalog Metastore
- Sign in to the OCI Console.
- Navigate to Analytics & AI.
- Under Data Lake, click Data Catalog.
- On the Data Catalog service page, click Metastores.
- Click Create metastore and provide the required information.
- Select the compartment where you want to create the metastore.
- Provide a suitable name for the metastore.
- Provide the default OCI Object Storage location for both managed and external tables.
Data Flow SQL Endpoint
Prerequisites
Refer to the documentation for prerequisites and how to set up the required IAM policies.
Create a Data Flow SQL Endpoint
- Sign in to the OCI Console.
- Navigate to Analytics & AI.
- Under Data Lake, click Data Flow.
- On the Data Flow service page, click SQL Endpoints.
- Select the Compartment where you want to create the SQL endpoint.
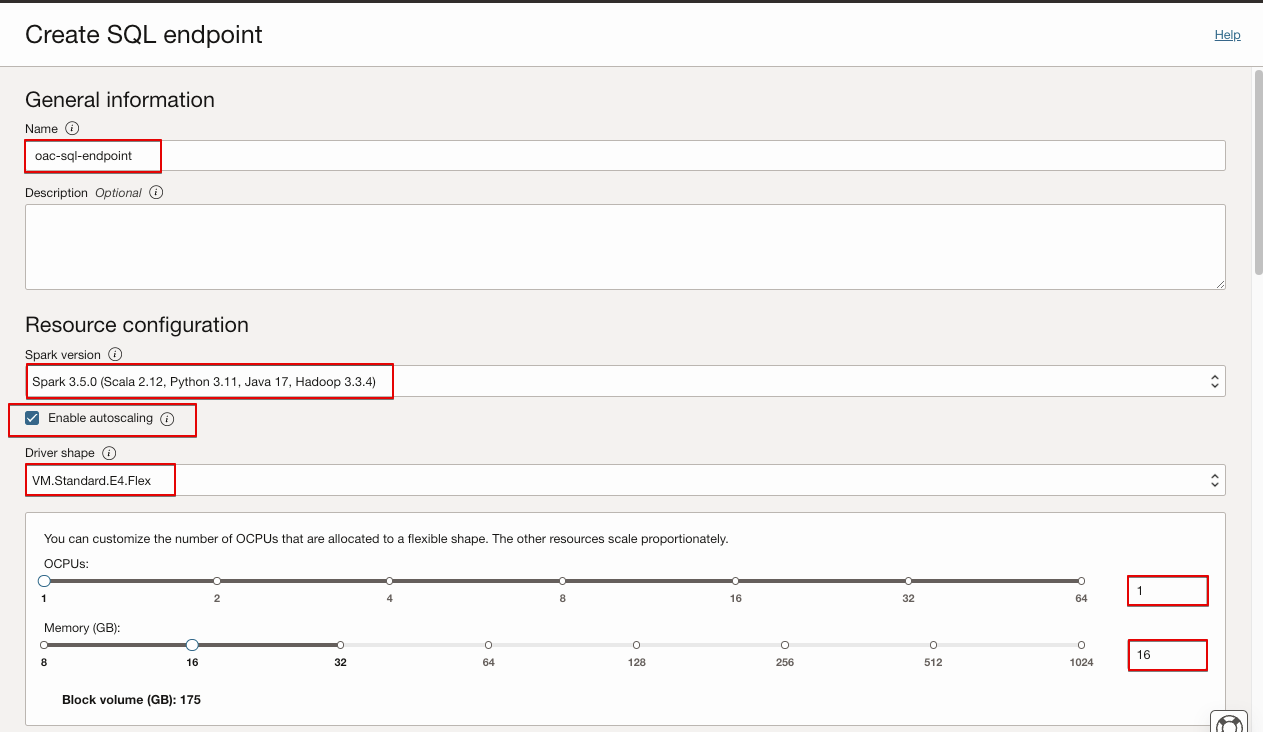
- Click Create SQL endpoint and provide the required details.
- Provide a name for the SQL endpoint.
- Select the Spark version for the cluster.
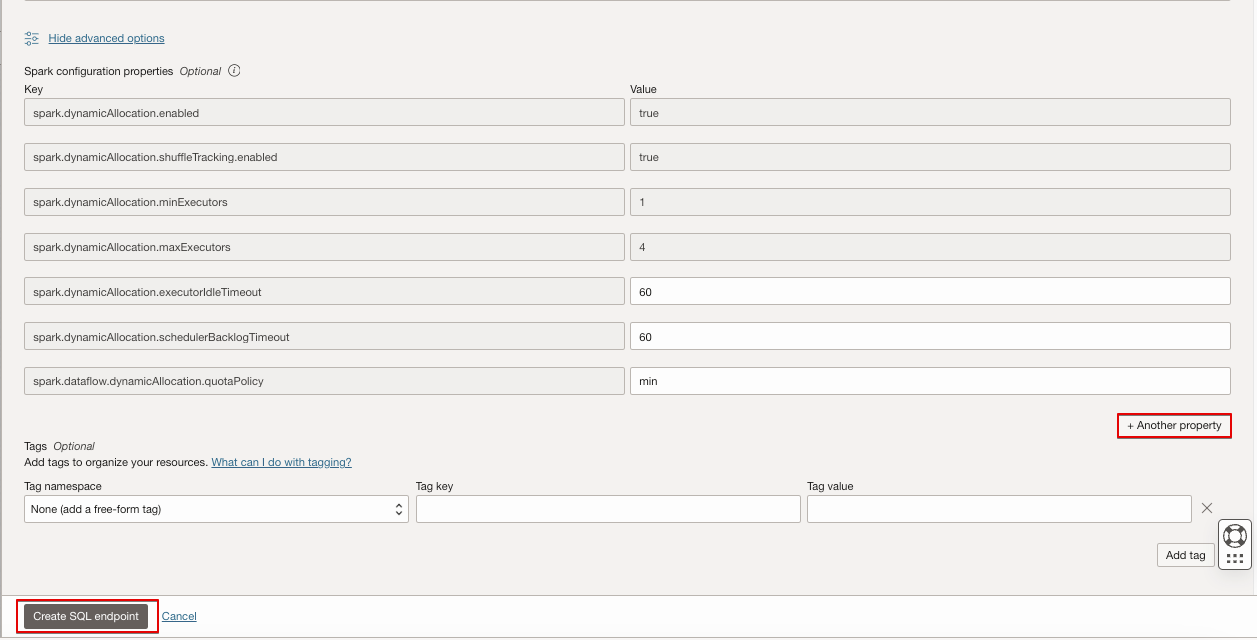
- Check Enable autoscaling to scale the cluster up and down dynamically based on the workload. Oracle recommend that you use autoscaling. If you don’t want to use autoscaling, uncheck Enable autoscaling.
- Select Driver shape. For a flexible shape, provide both OCPUs and Memory.
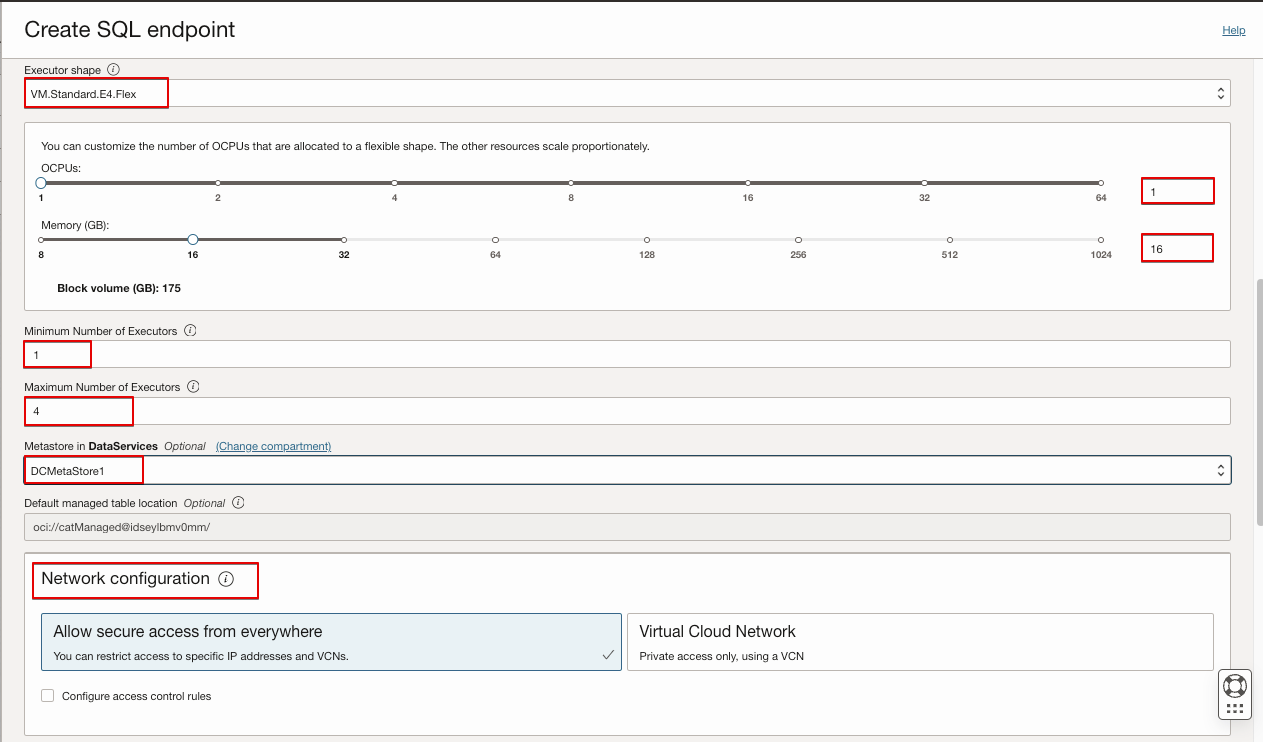
- Select Executor shape. For a flexible shape, provide both OCPUs and Memory.
- If autoscaling is enabled, provide minimum executor and maximum executor to be maintained during autoscaling.
- If autoscaling isn’t enabled, provide the number of executors for the cluster.
- Select the Metastore to use with the SQL endpoint.
- Select Network Configuration and control access based on your requirements.
- Click Show advanced options to control Spark behavior by overriding Spark properties. For Spark 3.5.0, refer to Spark Configuration to understand the supported Spark properties. SQL endpoints don’t support all the properties for overriding. You can override additional properties, by clicking on +Another Property.
Load Data to the Data Lake and Create Tables Pointing to the Data Lake Location
You can load and write data multiple ways, as SQL endpoints enable you to read data where it lives in a data lake without moving it.
One way you can load or write data to a data lake is to use a Data Flow application. For more information, refer to the documentation Creating a Data Flow Application.
For this blog, download the data file from the Internet and create a table pointing to OCI Object Storage.
- Download the Yellow Taxi Trip records as Parquet data files from the TLC Trip Record Data portal, and upload them to OCI Object Storage.
- Download and set up DBeaver to connect to the Data Flow SQL Endpoint to run SQL queries as described in the OCI documentation, Set Up DBeaver as a SQL Development Tool.
- Create a database and a table pointing to the OCI Object Storage location.
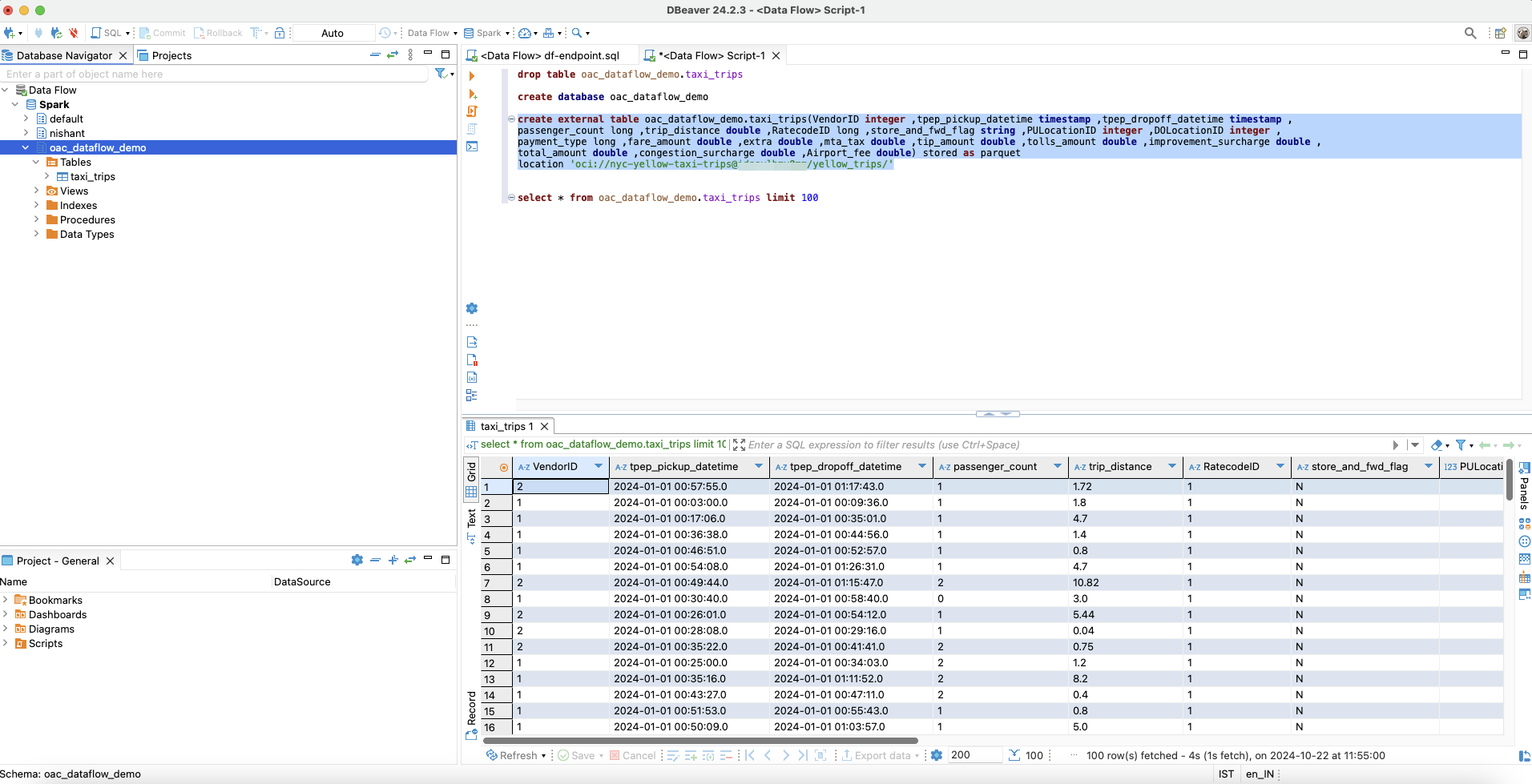
Create Database
create database oac_dataflow_demo
Create an External Table
create external table oac_dataflow_demo.taxi_trips(VendorID integer ,tpep_pickup_datetime timestamp ,tpep_dropoff_datetime timestamp ,
passenger_count long ,trip_distance double ,RatecodeID long ,store_and_fwd_flag string ,PULocationID integer ,DOLocationID integer ,
payment_type long ,fare_amount double ,extra double ,mta_tax double ,tip_amount double ,tolls_amount double ,improvement_surcharge double ,
total_amount double ,congestion_surcharge double ,Airport_fee double) stored as parquet
location 'oci://${OCI_BUCKET_NAME}@${OCI_NAMESPACE}/yellow_trips/'
Download the Connection Configuration File from the Data Flow SQL Endpoint
- Sign in to the OCI Console.
- Navigate to Analytics & AI.
- Under Data Lake, click Data Flow.
- On the Data Flow service page, click SQL endpoints.
- Select the required compartment.
- Select the SQL endpoint you want to connect to.
- Click Connect under Resources.
- Download the Connection Configuration File for Oracle Analytics Cloud.
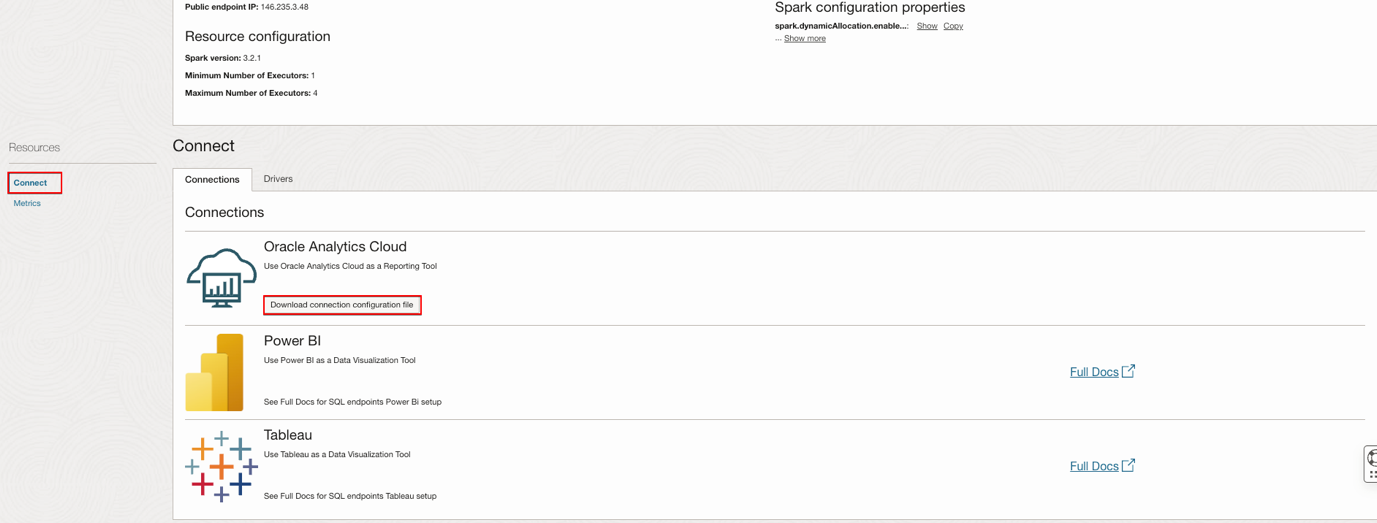
- If the Data Flow SQL Endpoint is launched with a private endpoint, update the hostname in the downloaded configuration file as follows.
- Sign in to the OCI Console.
- Navigate to Analytics & AI.
- Under Data Lake, click Data Flow.
- On the Data Flow service page, click SQL endpoints.
- Select the required compartment.
- Select the SQL endpoint that you want to connect to.
- Copy the Private Endpoint IP.
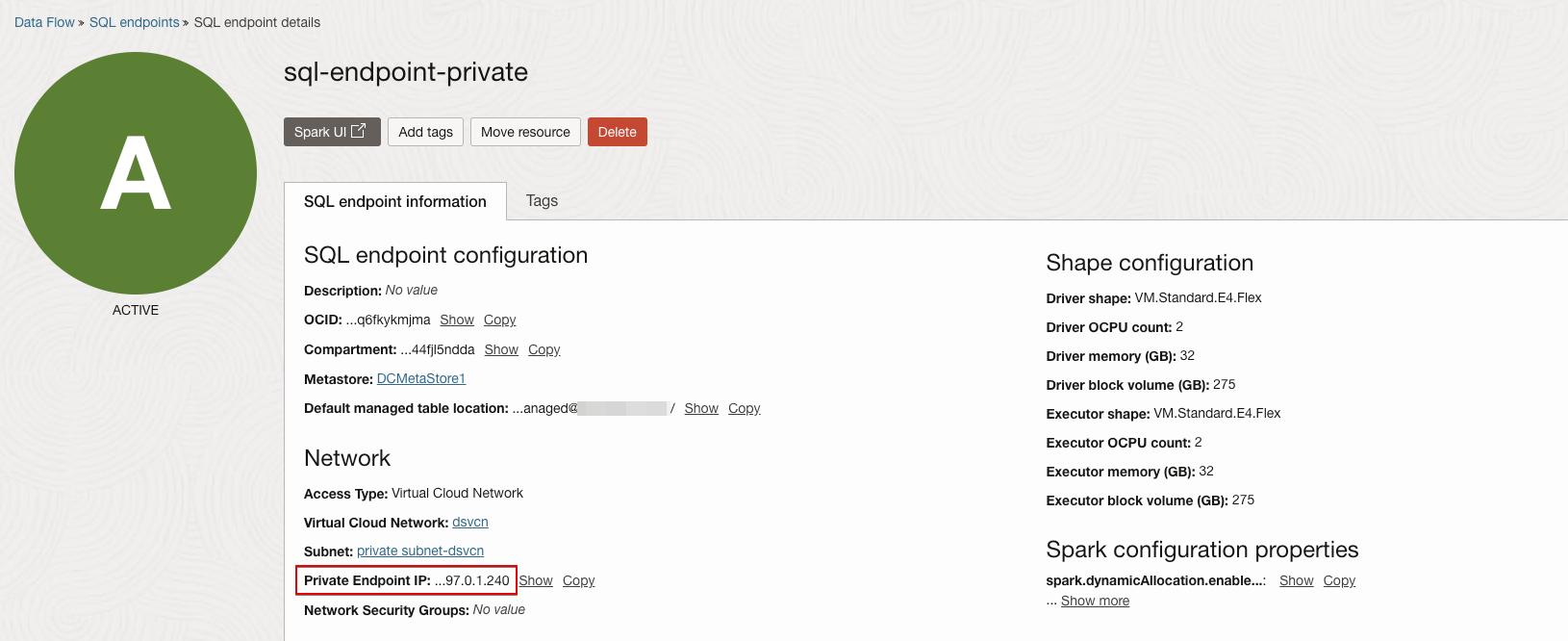
- Navigate to Networking.
- Click Virtual cloud networks (VCN).
- Select the required compartment.
- Select the VCN used to create the Data Flow SQL Endpoint.
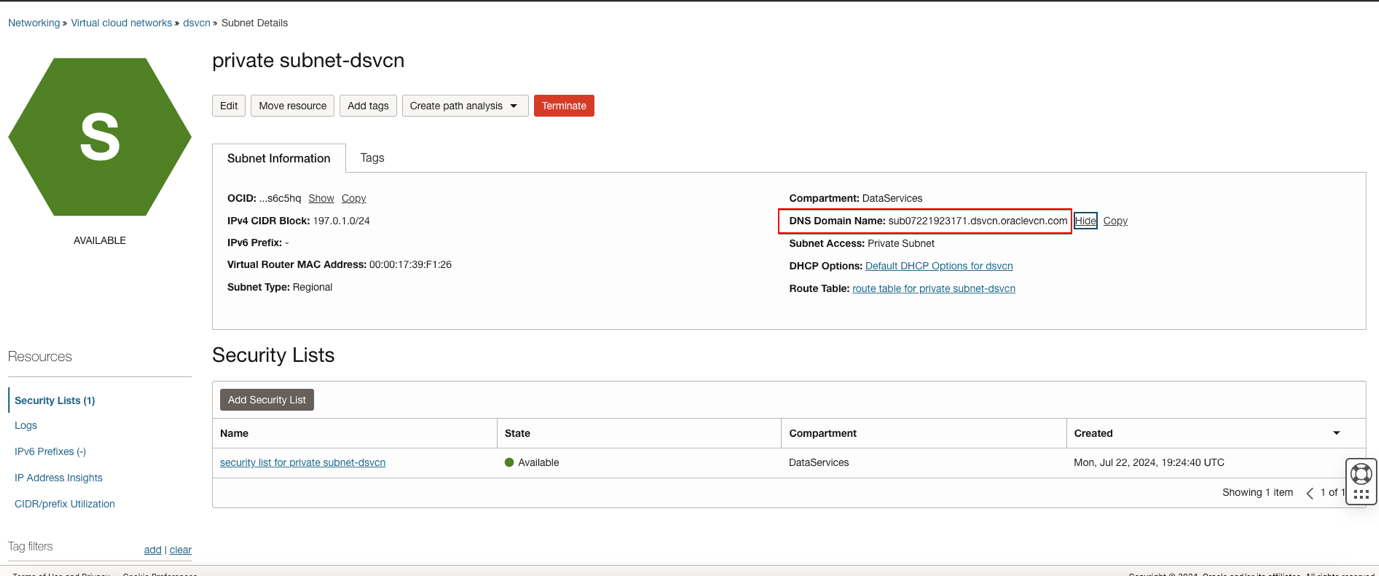
- From the subnet list, select the subnet used to create the Data Flow SQL Endpoint.
- Copy the DNS Domain Name.
- Navigate to Networking.
- Under DNS Management, click Zones.
- Click the Private Zones tab.
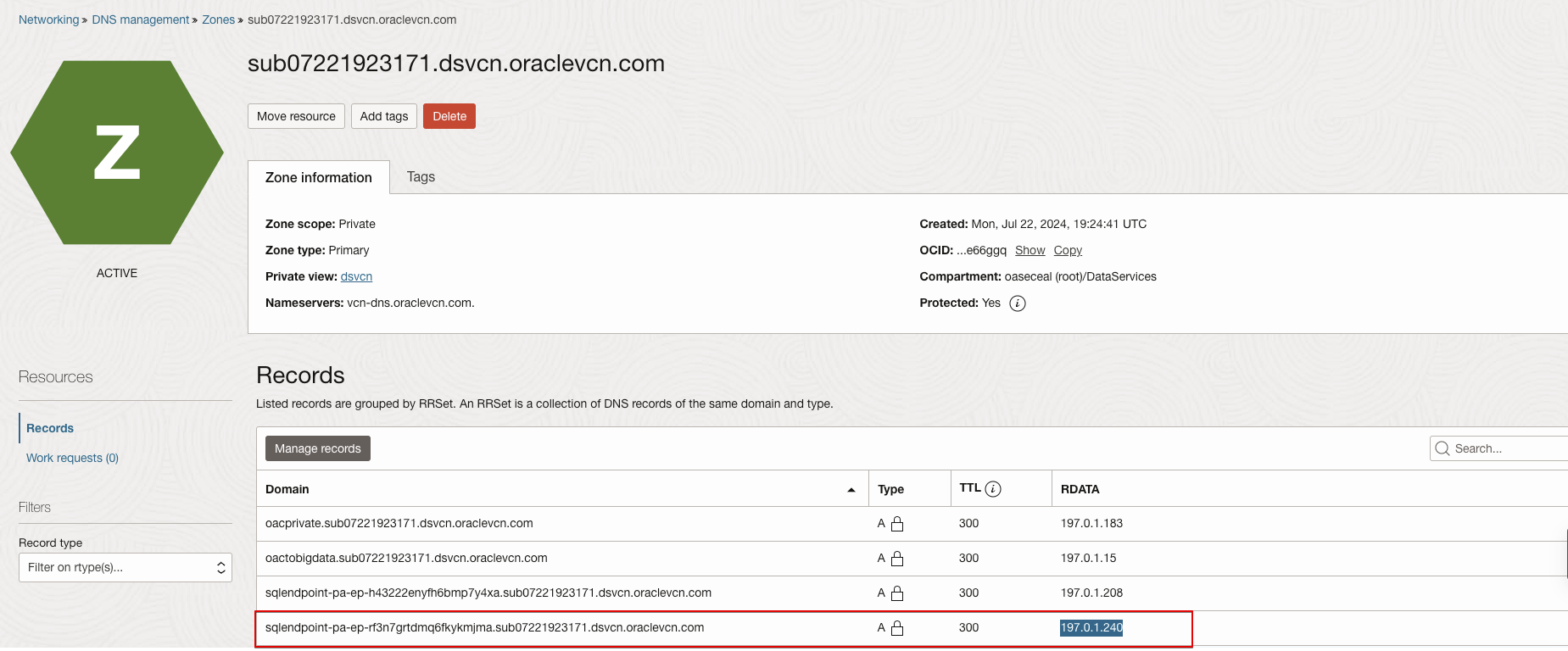
- Click the DNS Domain Name, which was extracted from the subnet.
- Search for Private Endpoint IP under the RDATA column, copied from the Data Flow SQL Endpoint. Use record with Type ‘A’.
- Copy the Domain from the filtered record.
- Update the hostname in the downloaded configuration file with the extracted Domain.
Create an Oracle Analytics Cloud Instance
To learn how to create an OAC instance, refer to the documentation.
If you create the OAC instance and Data Flow SQL Endpoint in different VCNs and subnets, ensure that the OAC instance can reach the Data Flow SQL Endpoint.
If the Data Flow SQL Endpoint is launched with a private endpoint, use the hostname and DNS name you extracted earlier (Download the Connection Configuration File from the Data Flow SQL Endpoint) to create a private access channel for the OAC instance. See Configure a Private Access Channel. Additionally, enable traffic on port 443 from the subnet CIDR of the OAC instance to the subnet of the Data Flow SQL Endpoint.
Connect to the Data Flow SQL Endpoint from the Oracle Analytics Cloud
- Sign in to OAC. For example, https://<oac-instance-name>-<namespace>-<region-code>.analytics.ocp.oraclecloud.com/ui/
- Click Create and click Connection.
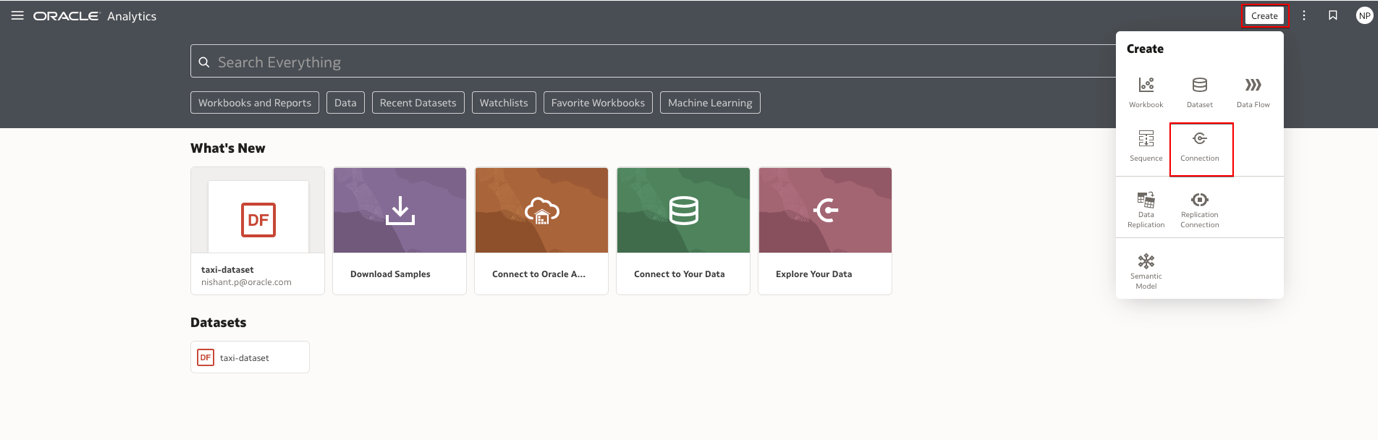
- For Connection Type, select OCI Data Flow.
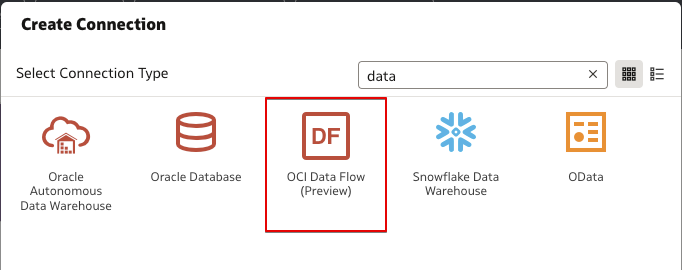
- Provide connection details.
- Provide a name for the connection.
- In Connection Details, select the configuration JSON file that you downloaded from the Data Flow SQL Endpoint.
- In Private API Key, navigate and select the private key in PEM file format.
- Click Save.

- Use the connection you just created to create a dataset and a workbook so you can analyze the data available in OAC.
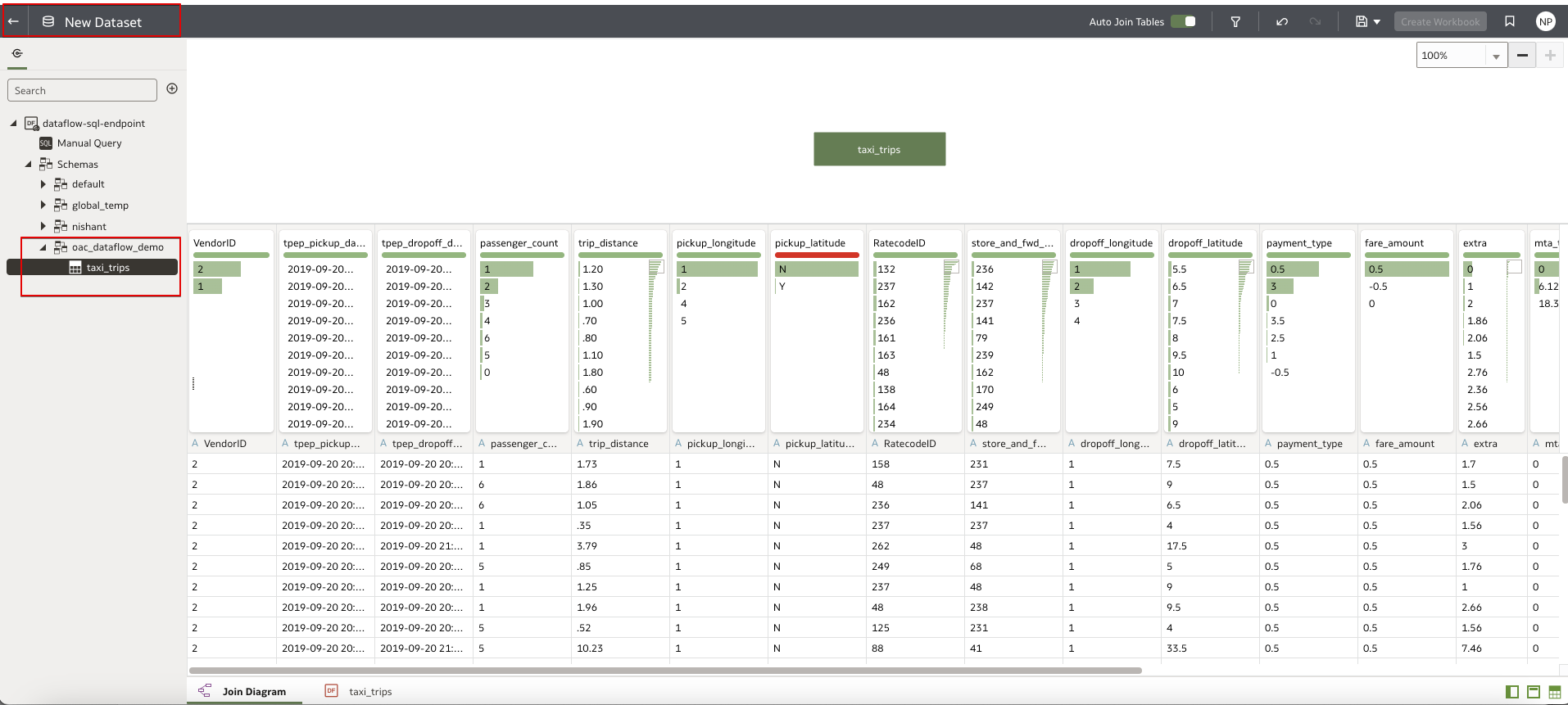
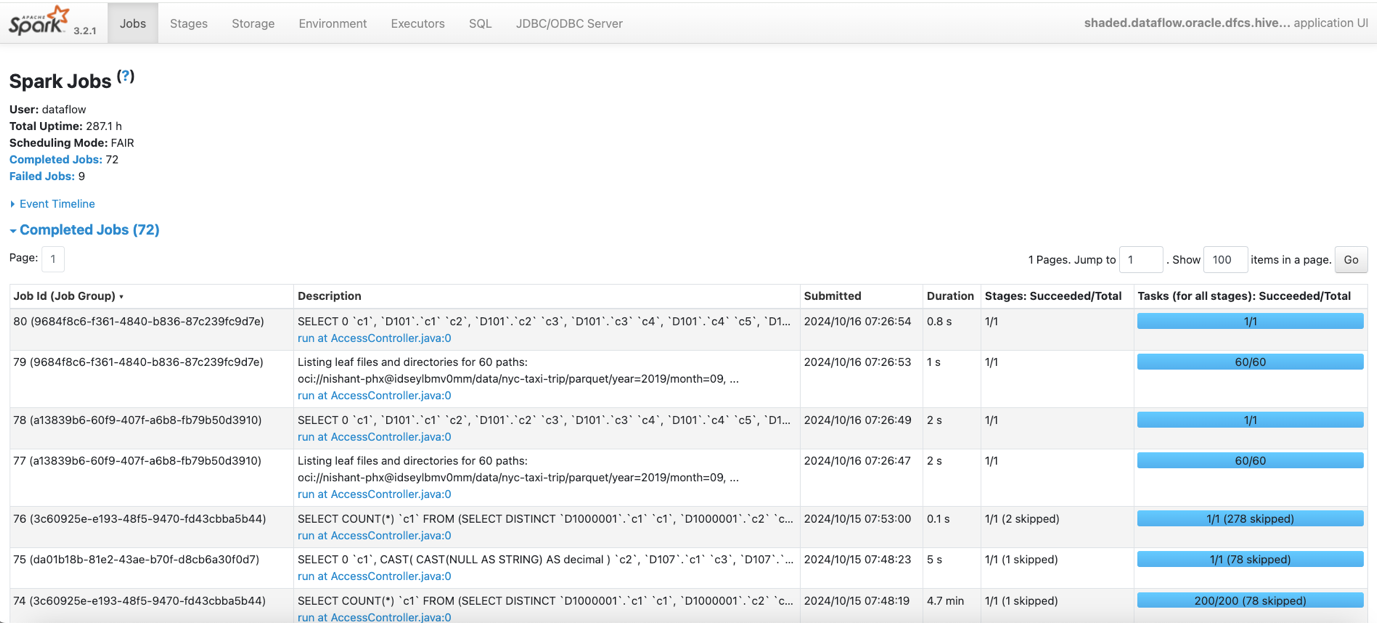
Monitor Query Performance
Open the Spark UI for the Data Flow SQL Endpoint to monitor query performance.
The Spark UI is a web-based interface provided by Apache Spark that allows you to monitor and debug Spark applications. It offers a detailed view of the execution process, including stages, tasks, and jobs, helping you to analyze the performance of your Spark jobs in real-time or after the jobs have finished.
- Sign in to the OCI Console.
- Navigate to Analytics & AI.
- Under Data Lake, click Data Flow.
- On the Data Flow service page, click SQL endpoints.
- Select the required compartment.
- Select the SQL endpoint to open the Spark UI.
- Click Spark UI.
Call to Action
Now you’ve learnt how to integrate Data Flow SQL Endpoints with Oracle Analytics Cloud, try it yourself. Create tables in Data Catalog Metastore from existing data in your data lake, and set up a Data Flow SQL Endpoint with access to the data. Connect OAC to the Data Flow SQL Endpoint and build enhanced data insights.
If you have questions, post them in the Oracle Analytics Community and we’ll follow up with answers.
![]()
