Artificial intelligence in Oracle Analytics Cloud relies on semantic metadata to interpret user questions accurately. AI agents use the subject area definition, not the raw data source, to generate responses. When business attributes are ambiguous, such as non-unique customer names, AI agent results may become inaccurate if the semantic model doesn’t clearly define entity grain. Proper semantic modeling ensures accurate aggregation, filtering, and entity resolution. This article focuses on a specific and highly effective tuning technique that uses the Descriptor ID property in the semantic model to improve AI agents’ aggregation accuracy, entity resolution, grouping behavior, and filtering, even when business attributes are non-unique.
Understand the Business Challenge of Ambiguous Customer Attributes
Consider a customer domain with the following attributes:
- Customer ID (unique identifier)
- First Name
- Last Name
- Preferred Name (non-unique display attribute)
- Age
- Country
In real-world enterprise data, names are rarely unique. For example, Preferred Name is not guaranteed to be unique. Multiple records may share the same Preferred Name, while each record maintains a distinct Customer ID.
If the semantic model doesn’t define how Preferred Name relates to Customer ID, AI agents may group by name instead of by identifier. This can cause aggregation and entity resolution errors in AI-generated queries.
Why Agent Tuning Begins in the Semantic Layer
AI agents rely on:
- Logical keys
- Aggregation rules
- Logical table grain
- Column relationships
- Descriptor mappings
If a descriptive column (such as Preferred Name) is not uniquely mapped to its identifier (Customer ID), AI agents may:
- Aggregate at the wrong level
- Collapse duplicate names
- Miscalculate distinct counts
- Apply filters inconsistently
The accuracy of AI agents is directly tied to semantic precision.
Steps to Configure the Descriptor ID to Control Aggregation and Display Behavior
You can use the Descriptor ID property to map the Preferred Name to Customer ID:
- Define Customer ID as the logical identifier.
- Configure Preferred Name as the descriptor column.
- Set the Descriptor ID property to link Preferred Name to Customer ID.
With this configuration, aggregation and filtering operate at the identifier-level, while Preferred Name remains the display attribute.
Example
The following example illustrates how ambiguous customer names can impact AI aggregation behavior.
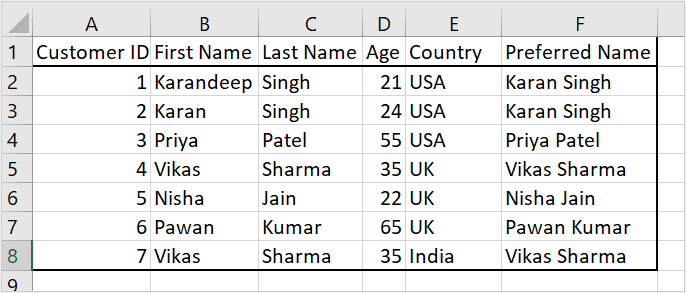
1. Review data in the physical table
The physical table contains duplicate Preferred Name values associated with different Customer IDs. The names Vikas Sharma and Karan Singh each appear more than once with different Customer IDs. This creates ambiguity when aggregation occurs at the name level.
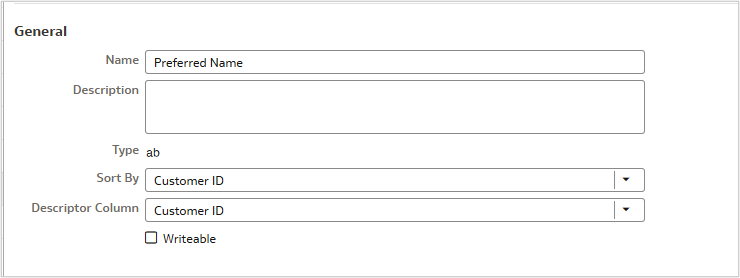
2. Configure Descriptor ID in the semantic model
Open the Preferred Name logical column properties and set Customer ID as the Descriptor ID column. This links the display attribute to its unique identifier.
3. Reinforce behavior in AI agents (optional)
Optionally, provide custom instructions in the AI agent configuration panel to reinforce identifier-based aggregation logic.

4. Validate results in a workbook
After deploying the semantic model, test AI queries in a workbook to confirm the correct aggregation and filtering behavior.
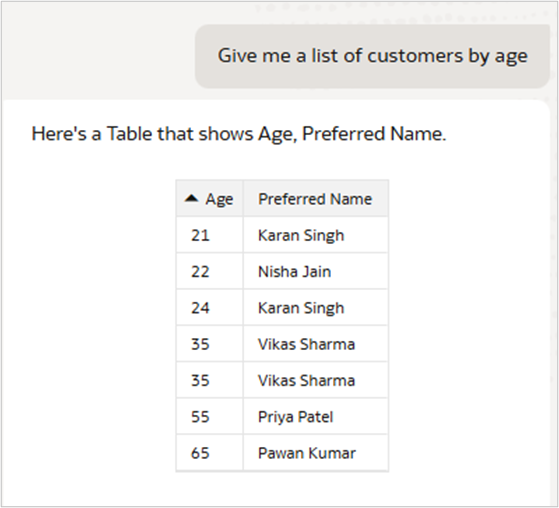

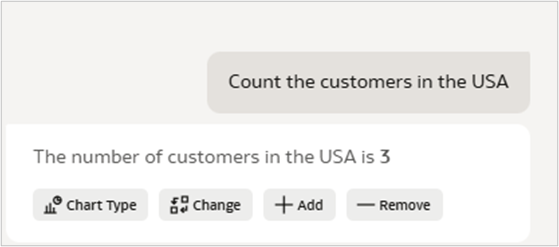
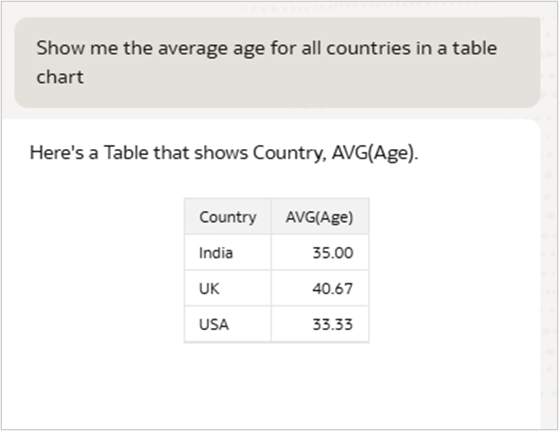
Observe how AI agent behavior improves after Descriptor ID configuration
- Correct aggregations at the Customer ID grain
- Accurate distinct counts without duplicate-name collapse
- Reliable aggregate filters
- Proper entity resolution
Summary
Tuning AI agents in Oracle Analytics Cloud is about strengthening the semantic foundation. The Descriptor ID property ensures identifier-level aggregation, accurate grouping, and reliable AI responses at scale.
Call to Action
Review your semantic model and validate identifier-to-descriptor mappings in your subject areas. Visit the Oracle Analytics Community to share your scenario or consult the Oracle Analytics Cloud documentation for additional guidance.