June 16, 2026, by the OCI AI Foundations Infrastructure and AMD AI Workload Optimizations teams · 6 min read
Applications & models | AI/ML | GenAI | Performance | Optimization | MLPerf® | MLPerf® Training | AMD ROCm Software
| Oracle Cloud Infrastructure (OCI) has achieved the first MLPerf® Training FLUX.1 results on AMD Instinct MI300X GPUs1 — training a modern text-to-image diffusion transformer across 64 OCI bare metal BM.GPU.MI300X.8 nodes, 512 GPUs in total, with a verified time-to-train of 74.44 minutes and every submitted run converging to the benchmark’s quality target. |
Highlights
- Largest scale MLPerf submission on AMD Instinct: OCI submitted the first MLPerf® Training results for the FLUX.1 text-to-image benchmark on AMD Instinct GPUs, run on 64 OCI BM.GPU.MI300X.8 bare metal nodes — 512 MI300X GPUs.1
- Verified time-to-train: the official v6.0 result is 74.441 the ten submitted runs ranged from 70.77 to 76.30 minutes.
- Repeatable at scale: all ten runs reached the 0.586 validation-loss quality target, within a 5.53-minute spread — run-to-run variation under 8% across 512 GPUs.
- Production-relevant configuration: global batch size of 4,096 with validation every 262,144 training samples — settings representative of real diffusion-transformer training.
- AMD ROCm™ software stack: ROCm 7.2, PyTorch 2.9.1, ROCm Megatron-LM, NeMo 2.6, ROCm Transformer Engine (FP8), AITER, RCCL, hipBLASLt, and Megatron-Energon.
- Joint engineering with AMD: the submission was developed in close collaboration with AMD’s ROCm software engineering teams, and this post is co-published with AMD.
Why text-to-image training matters
Text-to-image generation has moved from novelty to production workloads. Media, advertising, e-commerce, and design teams now train and fine-tune diffusion models on proprietary data. FLUX.1, introduced in MLPerf® Training v5.1, is the industry’s benchmark for exactly that workload: an 11.9-billion-parameter diffusion transformer trained to a strict validation-loss target. It stresses accelerator memory capacity, transformer compute, storage locality, distributed communication, and validation repeatability — all at the same time. MLPerf®, developed by MLCommons, is the most recognized industry-standard benchmark suite for AI systems, and submissions are peer-reviewed before publication, providing independent, apples-to-apples comparison across platforms.
| Dr. Sujith Ravi – Group Vice President AI Foundations, Oracle OCI AI Foundations is excited to partner with AMD to publish the first-ever MLPerf Training results running at scale on 512 AMD Instinct MI300X GPUs for FLUX.1, a frontier model for image generation. This submission marks several firsts: the first MLPerf benchmark of its kind for FLUX.1 training on AMD hardware, a large-scale demonstration of MI300 for frontier-model training, and a proof point for the training infrastructure stack our teams co-developed across OCI and AMD. The results show consistent, reliable performance across a 512-accelerator cluster, validating the platform’s readiness for demanding frontier AI workloads. We see this milestone as the start of a continued partnership with AMD to scale frontier-model training and inference at planet scale on OCI infrastructure. |
| Dr. Emad Barsoum, Corporate VP of AI and Engineering, AMD Oracle has been a key partner in bringing AMD Instinct to cloud customers, and this MLPerf 6.0 Training submission shows what that collaboration delivers: verified, repeatable training of an 11.9-billion-parameter diffusion transformer at 512-GPU scale. OCI’s bare metal infrastructure and ROCEv2 RDMA cluster network, combined with AMD ROCm software, and PyTorch, turned a demanding benchmark into a predictable production recipe. |
The platform: OCI Compute BM.GPU.MI300X.8
The submitted training job ran on 64 OCI bare metal BM.GPU.MI300X.8 nodes — 512 AMD Instinct MI300X GPUs in total.
| Component | OCI BM.GPU.MI300X.8 (as submitted) |
| GPUs | 8x AMD Instinct MI300X GPUs per node, 192 GB HBM3 per GPU(1.5 TB HBM3 per node) with 5.3 TB/s GPU memory bandwidth; 64 nodes / 512 GPUs in the submitted run |
| Intra-node GPU interconnect | AMD Infinity Fabric™ (XGMI) |
| CPUs | 2x Intel Xeon Platinum 8480+ (Sapphire Rapids), 56 cores each |
| System memory | 2 TB DDR5 |
| Local storage | 8x 3.84 TB NVMe (30.7 TB per node, RAID0), mounted at /mnt/localdisk |
| Cluster network | 8x 400 Gbps RoCEv2 RDMA (Mellanox ConnectX-7) — 3,200 Gbps of cluster network bandwidth per node |
| Front-end network | 1x 100 Gbps |
| OS / kernel | Ubuntu 22.04.5 LTS, Linux 6.8.0-1038-oracle |
| Core software | ROCm 7.2.0, PyTorch 2.9.1+rocm7.2, RCCL 2.27.7, hipBLASLt 1.2.1, MIOpen 3.5.1 |
For FLUX.1, this configuration matters in three places. The 192 GB of HBM3 per GPU provides headroom for large transformer blocks, activations, and optimizer state. Local NVMe scratch storage removes pressure on shared storage once the dataset is staged. And the RoCEv2 RDMA cluster network, paired with RCCL tuning, carries multi-node synchronization across all 64 hosts. The same OCI Supercluster architecture scales to 16,384 AMD Instinct MI300X GPUs, so the 512-GPU footprint used here is an operating point, not a ceiling.
The results: convergence in 74.44 minutes at 512 GPUs
On the MLPerf® Training v6.0 FLUX.1 benchmark, the 512-GPU OCI system reached the 0.586 validation-loss quality target with an official time-to-train of 74.441 (RCP leveled). Across the ten submitted runs, the fastest reached target in 70.77 minutes; the median was 72.46 minutes, and the mean was 72.94 minutes — a full run-to-run spread of just 5.53 minutes.
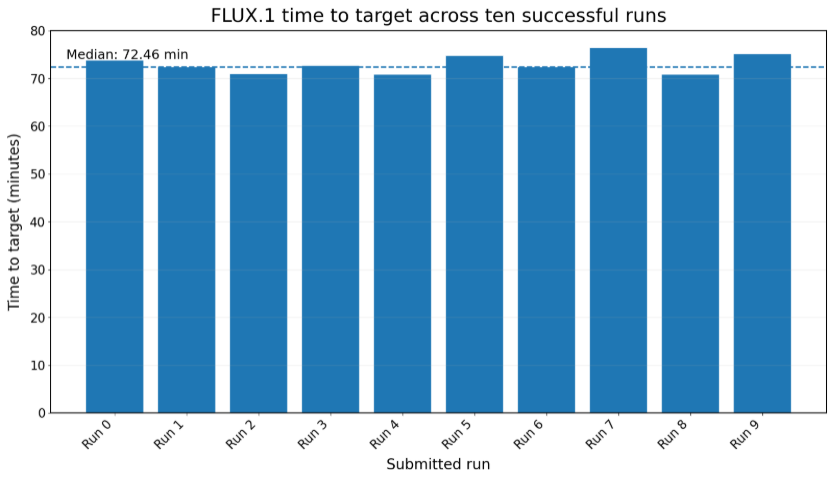
Figure 1: Time to target across the ten submitted FLUX.1 runs Source: MLPerf® Training v6.0 Closed, FLUX.1, OCI BM.GPU.MI300X.8 (64 nodes), entry 6.0-0032. Lower time to target is better.
That consistency is the real story for production teams: ten runs, ten convergences, all within a five-and-a-half-minute window. At 512 GPUs, the system behaves like one predictable training platform rather than a collection of independently launched workers. Combined throughput near convergence was approximately 3,434 to 3,457 samples per second including validation overhead, with train-only throughput of approximately 3,624 to 3,648 samples per second.2
Inside the benchmark
The submitted implementation trains the schnell FLUX.1 model configuration on preprocessed CC12M training data with COCO validation data, in Megatron-Energon WebDataset format. The quality metric is validation loss (lower is better) with a target of 0.586, evaluated on 29,696 samples every 262,144 training samples. The runs use a sequence length of 256, a micro-batch size of 8, and a global batch size of 4,096. Validation averages per-sample denoising loss over eight evenly spaced timesteps, aggregated across all data-parallel ranks.
How we did it: optimizations across the stack
This was a joint engineering effort between Oracle and AMD. Performance came from system, data, kernel, precision, and distributed-training optimizations working together across the AMD ROCm software stack. The guiding pattern: keep the timed benchmark path focused on the FLUX transformer and the distributed training step, and keep preprocessing, cache placement, and launch orchestration outside the hot loop.
Preprocessed text and image latent inputs
The dataset stores T5 prompt embeddings, CLIP pooled prompt embeddings, and VAE latent means and log-variances as serialized bfloat16 arrays, which the task encoder deserializes directly from the Megatron-Energon dataset. The text encoders and VAE encoder never run inside the measured path: the model samples latents from the stored statistics, applies the FLUX VAE scale and shift, samples diffusion noise, and trains the transformer on the denoising objective.
Key takeaway: the measured loop spends its time on the diffusion transformer, optimizer, and collectives — not on input preprocessing.
FP8 training through ROCm Transformer Engine
The 64-node configuration enables the delayed FP8 recipe through ROCm Transformer Engine. The optimizer is AdamW with beta1 0.9, beta2 0.95, epsilon 1e-8, weight decay 0.1, gradient clipping at 1.0, a base learning rate of 0.0004, and 400 warmup steps. A short synthetic warmup initializes the execution path before the measured loop, and FP8 state is reset after warmup, so the benchmark run starts with fresh FP8 metadata.
Key takeaway: FP8 execution improves per-step efficiency while every run still converges to the benchmark’s quality target.
Fused attention, hipBLASLt, and AITER kernels
The software stack is built around ROCm-optimized transformer kernels: Transformer Engine fused attention paths, CK fused attention controls, hipBLASLt-backed matrix multiplication, AITER components, RoPE fusion, and the Transformer Engine RNG tracker. The submitted Dockerfile builds ROCm Megatron-LM, NeMo, ROCm Transformer Engine, and AITER into a single training container, so every node runs the benchmark from a controlled, identical environment.
Key takeaway: the hottest paths in a diffusion-transformer step — matrix multiplies, attention, rotary embeddings, and precision casts — run on tuned ROCm kernels on every node.
Distributed optimizer and communication overlap
The configuration enables the distributed optimizer and overlaps gradient reduction with backpropagation (parameter-gather overlap is disabled for this run). The run uses pure data parallelism across the 512 GPUs, with tensor, pipeline, context, and sequence parallelism all set to one. The RCCL/NCCL environment is tuned for OCI’s RDMA fabric: HCA selection, GID index, retry and timeout values, socket reuse, receive-queue lengths, and one channel per network peer.
Key takeaway: tuned collectives let 64 nodes behave like one predictable training system.
Data locality and launch orchestration
The Slurm job runs one task per node and launches eight local GPU workers per node with torchrun. The FLUX.1 dataset and all runtime caches — temporary, Triton, TorchInductor, Torch, and HIPRTC — live on local NVMe under /mnt/localdisk. The launch wrapper supports staging data from shared storage and fan-out staging between nodes; in the submitted job, staging is disabled because the dataset is pre-staged locally.
Key takeaway: local data paths remove shared-filesystem variability — a major contributor to the tight 5.53-minute run-to-run spread.
Warmup and validation handling
A synthetic warmup pass covers both training and validation: deterministic synthetic batches, optimizer behavior temporarily adjusted so real training state is untouched, ranks synchronized, gradients cleared, and trainer metrics reset before the measured run begins. Validation uses a custom Megatron loss-reduction path: each rank computes its validation loss sum and sample count, both are all-reduced across the data-parallel group, and the aggregate is reported through the MLPerf® logging callback.
Key takeaway: validation stays lightweight while preserving the benchmark’s exact loss definition across the full 512-GPU job.
What this means for customers
Text-to-image training is one of the most demanding generative AI workloads: it stresses accelerator memory, compute, storage locality, distributed communication, and validation repeatability simultaneously. This result shows OCI supporting those requirements as one integrated, repeatable training system on AMD Instinct MI300X GPUs— not a collection of isolated accelerators.
For teams training diffusion-transformer models, the takeaway is practical: scaling depends on more than raw GPU count. It takes a consistent software stack, local data paths, tuned collectives, precision support, fused kernels, and benchmark-grade observability. This submission packages those pieces into a repeatable 512-GPU recipe — and the full implementation is available in the MLPerf® Training v6.0 results repository for anyone to review and reproduce.
Summary
Oracle’s MLPerf® Training v6.0 FLUX.1 submission delivers the first FLUX.1 results on AMD Instinct MI300X GPUs: a verified 74.44-minute time-to-train on 512 GPUs across 64 OCI bare metal BM.GPU.MI300X.8 nodes, with all ten runs reaching target quality.1 Preprocessed embeddings keep the training loop on the diffusion transformer; FP8 and fused ROCm kernels raise per-step efficiency; the distributed optimizer and gradient-reduce overlap absorb communication cost at 512 GPUs; and local data placement keeps I/O variance out of the measured path.
The same ingredients that matter for MLPerf® — predictable launch orchestration, tuned collectives, fast kernels, local data paths, and strict validation accounting — are the ingredients for production-scale generative AI training. They are available today on OCI.
Get started
Learn more about OCI AI Infrastructure and OCI Compute GPU shapes, or speak to an Oracle AI expert. The complete MLPerf® Training v6.0 results are available at mlcommons.org, and the full submitted implementation is in the MLPerf® Training v6.0 results repository. Read AMD’s companion post: Technical Deep Dive into AMD Training v6.0 Submission
Acknowledgements
This result reflects a joint effort across the OCI AI Foundations Infrastructure engineering team and AMD AI Workload Optimizations teams. The authors thank everyone who contributed to building, tuning, and validating the submission.
Footnotes
1 MLPerf® Training v6.0, Closed Division, FLUX.1 benchmark, OCI BM.GPU.MI300X.8 systems (64 nodes, 512 GPUs). Official result: 74.436 minutes, retrieved from www.mlcommons.org on June 16, 2026, entry 6.0-0032. Result verified by MLCommons Association. The official score includes MLCommons’ standard reference convergence point (RCP) normalization, which adjusts results for runs that converge in fewer training samples than the reference implementation’s convergence envelope; it can therefore differ slightly from the arithmetic mean of the individual run times shown in this post. The MLPerf name and logo are registered and unregistered trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use strictly prohibited. See www.mlcommons.org for more information. The “first” claim is based on a review of all published MLPerf® Training rounds through v6.0 as of June 16, 2026: no earlier text-to-image training submission on AMD Instinct GPUs appears in any published round.
2 Throughput in samples per second is derived from measured step times and samples processed; it is not an official MLPerf® metric. The official MLPerf® Training metric is time-to-train.
