Training large models is hard. Training them reliably on a shared GPU cluster — where a bad NIC, a flaky node, or a noisy neighbor can erase hours of progress — is harder. This post walks through a training system on Oracle Kubernetes Engine (OKE) that:
- orchestrates multi-node PyTorch jobs from a single controller,
- is aware of the cluster’s RDMA topology so collective traffic stays on the fast lane,
- and survives mid-run failures without restarting from scratch.
We get there step by step — each a small, testable change, each with real numbers from our cluster.
Architecture Diagram
Here’s where we’re headed — the full system end-to-end (the final configuration 3.5). We’ll assemble it one piece at a time in the sections below.
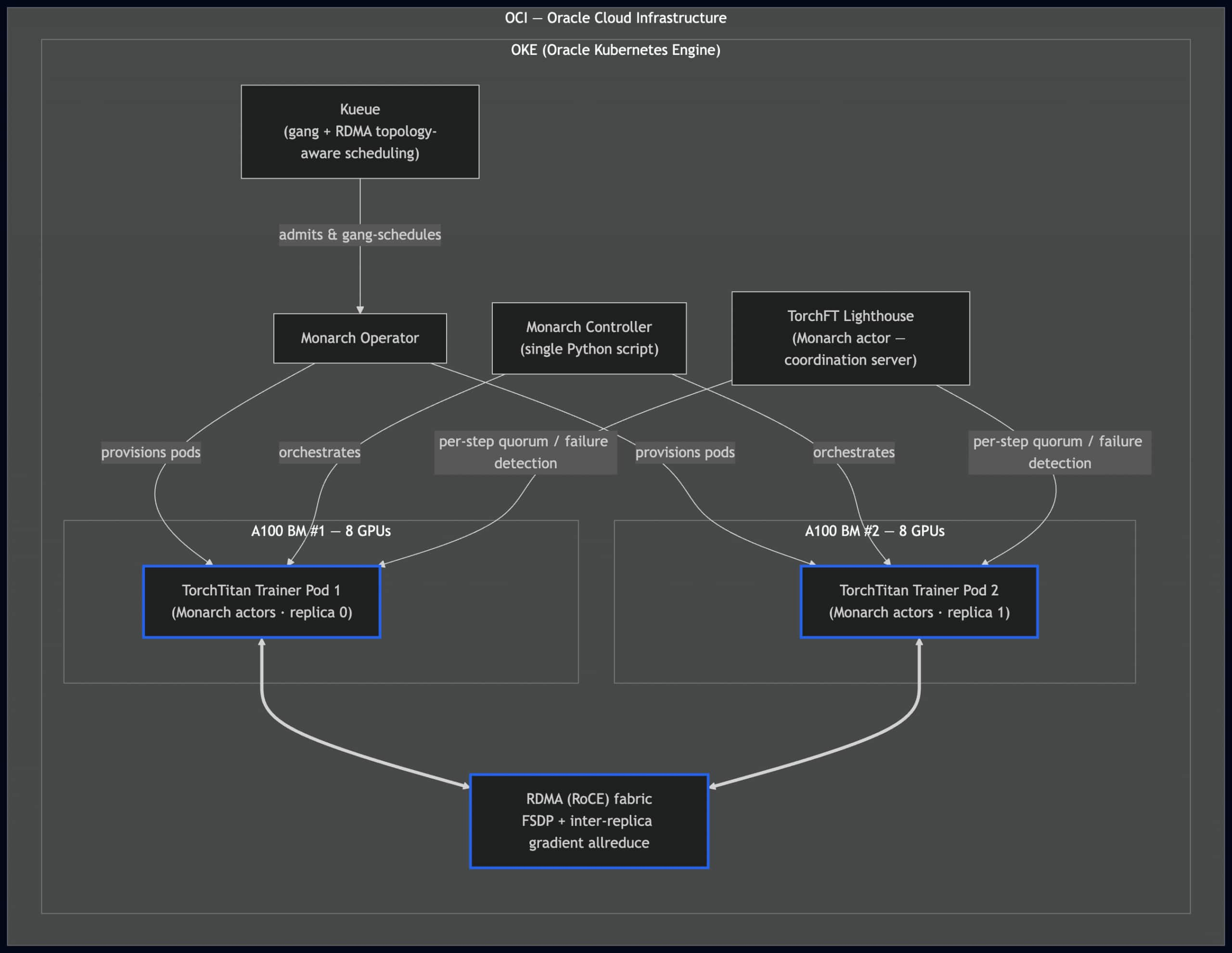
How the layers stack: Kueue admits the job atomically and places pods to minimize RDMA switch hops. The Monarch Operator provisions the worker pods, and the Monarch Controller — one Python script — orchestrates them. Two TorchTitan trainer pods (one per A100 node, 8 GPUs each) run as Monarch actors, with the TorchFT Lighthouse coordinating per-step fault tolerance. The RDMA (RoCE) fabric (bold blue) carries both FSDP and inter-replica gradient allreduce at line rate.
1. The building blocks
A quick tour of the pieces we’re combining.
OKE (Oracle Kubernetes Engine) — Oracle Cloud’s managed Kubernetes service: the foundation for pods, jobs, the operator that schedules Monarch workers, and the RDMA configuration. Our cluster:
2 × A100 bare-metal nodes, 16 GPUs total, with RDMA-capable inter-node networking.
Two nodes is the smallest configuration where multi-node networking, gang scheduling, and topology awareness actually matter.
PyTorch Monarch — Open Source distributed orchestration framework. Instead of a torchrun wrapper, a Helm chart, and an operator config, you write one Python controller script describing the job — hosts, GPUs per host, and what runs on each rank — and Monarch handles the rest. It runs on Kubernetes (via the Monarch Operator and ports to Slurm by swapping just the pod-spec helper. And it’s a single point of orchestration: failures, resizing, and restarts all flow through the same controller — exactly what we need before layering fault tolerance on top.
TorchTitan — PyTorch’s reference implementation for large-model training. It bundles FSDP, tensor/pipeline parallelism, and activation checkpointing behind a clean config, letting us focus on the system instead of the model-parallelism strategy.
TorchFT — PyTorch’s fault-tolerance library. The headline idea is per-step fault tolerance: when a replica dies, survivors keep training and the dead replica rejoins later. It works via a coordination server (the Lighthouse) plus runtime wrappers around DDP and the optimizer. Monarch orchestrates; TorchFT handles “what happens when something dies mid-step.”
Kueue — a Kubernetes-native job queue. We use it for gang scheduling (all pods of a job start together or not at all) and RDMA topology-aware scheduling (placing pods so their NICs share the fewest switch hops).
2. The evaluation model
To compare each step apples-to-apples, we train the same model every time:
Llama 3 — 8B parameters, trained on the C4 dataset.
This isn’t about a state-of-the-art checkpoint — it’s about validating the *system*. Llama 3 8B is large enough to be realistic, small enough to iterate quickly, and well-understood enough that the metrics tell a clear story.
3. Construction
We build the system incrementally — start simple, measure, then add one component at a time. Each configuration links to its own branch with a detailed write-up.
3.1 The baseline — OKE + TorchTitan + torchrun
3.2 Adding Monarch — one controller to orchestrate them all
3.3 Adding TorchFT — surviving the failures that will happen
3.4 Adding RDMA — paying off the TorchFT bill
3.5 RDMA Topology-Aware Scheduling and Gang Scheduling
Results
All runs train Llama 3 8B on C4 for 1000 steps on 2 × A100 BM (16 GPUs)
| Config | Time | Loss | Status | MFU | TPS | TFLOPs | Grad Norm | Memory |
| 3.1 torchrun baseline | 2473 s | 12.25 → 4.64 | Success | 55.34% | 3355 | 172.68 | 1.0655 | 50.26 GiB |
| 3.2 + Monarch | 2505 s | 12.27 → 4.65 | Success | 55.49% | 3364 | 173.13 | 1.0923 | 50.26 GiB |
| 3.3 + TorchFT (TCP overlay) | 6389 s | 12.25 → 4.65 | Success | 21.46% | 1301 | 66.97 | 1.2422 | 55.12 GiB |
| 3.4 + RDMA (RoCE) | 2566 s | 12.24 → 4.31 | Success | 54.25% | 3288 | 169.25 | 0.9664 | 55.12 GiB |
| 3.5 + Kueue | same as 3.4 | same as 3.4 | Success | — | — | — | — | — |
Notes:
- 3.3: TorchFT buys per-step fault tolerance but is ~2.5× slower — its cross-replica gradient allreduce runs over the slow TCP/IP pod overlay instead of RDMA.
- 3.4: Moving that allreduce onto the RDMA fabric (RoCE) erases the slowdown — back to baseline throughput with fault tolerance kept.
- 3.5: Kueue adds gang scheduling and RDMA topology-aware admission. It’s invisible during steady-state training — it changes how jobs land on and share the cluster, not the per-step math — so its throughput matches 3.4.
Conclusion
The system now has:
- a single Python controller (3.2 — Monarch),
- per-step fault tolerance with no restart cost (3.3 — TorchFT),
- inter-replica gradient sync at line rate on the RDMA fabric (3.4 — RDMA),
- and atomic, topology-aware admission so jobs don’t strand resources or hop across the fabric (3.5 — Kueue).
That’s the system we set out to build.
Build it yourself
Building a reliable, large-scale training system is genuinely hard — but it doesn’t have to be built from scratch. With OKE, Monarch, and the recipes in this post, the hard parts — multi-node orchestration, RDMA-aware scheduling, and per-step fault tolerance — collapse into a handful of composable, testable steps.
👉 Explore the full repo — every configuration links to its own branch with runnable code and write-ups, so you can reproduce these results and adapt them to your own cluster.
And to stand up the underlying cluster even faster, check out OCI AI Blueprints for simplified, opinionated OKE provisioning.