NVIDIA NIMTM is a set of easy to use microservices designed for secure, reliable deployment of high performance AI model inferencing across clouds, data centers, and workstations. NIM offers microservices for the latest AI models across multiple domains. For instance, NVIDIA NIM dedicated to large language models (LLMs) equips enterprise applications with advanced LLMs, delivering superior natural language processing and comprehension abilities. NIM simplifies the process for IT and DevOps teams to manage LLM hosting within the OCI Data Science service, while providing developers with standard APIs. These APIs enable the creation of sophisticated copilots, chatbots, and AI assistants, revolutionizing business operations. By harnessing NVIDIA’s advanced GPU acceleration and scalable deployment capabilities, NIM ensures rapid inference and unmatched performance.
High performance features of NIM
NIM abstracts away model inference internals, such as processing engines and runtime operations. NIM inference runtimes are built on robust foundations including Triton Inference Server, TensorRT, TensorRT-LLM, and PyTorch, are are prebuilt and optimised to deliver lowest latency, highest throughput inferencing on NVIDIA accelerated infrastructure. NIM offers the following high-performance features:
- Scalable deployment: Performant and can easily and seamlessly scale from a few users to millions.
- Advanced language model support: Uses pre-generated optimized engines for a diverse range of cutting edge LLM architectures.
- Flexible integration: Easily incorporate the microservice into existing workflows and applications. Developers are provided with an OpenAI API compatible programming model and custom NVIDIA extensions for more functionality.
- Enterprise grade security: Emphasizes security by using safetensors, constantly monitoring and patching common vulnerabilities and exposures (CVEs) in our stack and conducting internal penetration tests.
Why choose OCI
Customers are choosing OCI for all their cloud workloads for the following reasons:
- Far easier to migrate critical enterprise workloads.
- Everything you need to build modern cloud native applications.
- Autonomous services automatically secure, tune, and scale your apps.
- OCI provides the most support for hybrid cloud strategies.
- Our approach to security: Built in, on by default, at no extra charge.
- OCI offers superior price-performance.
Applications
Customers have used NIM for LLMs in the following use cases:
- Chatbots and virtual assistants: Empower bots with human-like language understanding and responsiveness.
- Content generation and summarization: Generate high-quality content or distill lengthy articles into concise summaries with ease.
- Sentiment analysis: Understand user sentiments in real-time, driving better business decisions.
- Language translation: Break language barriers with efficient and accurate translation services.
High level solution overview
NIMs microservices are delivered as container images for each model. Each container includes an inference runtime, such as TensorRT, Triton Inference Server and more, that runs on any NVIDIA GPU with sufficient memory, with optimized engines available for a growing number of model and GPU combinations. NIM containers download models from NVIDIA NGC, using a local filesystem cache when available. Built from a common base, downloading more NIM microservices is rapid after one has been downloaded. After deployment, NIM inspects the local hardware and available optimized models, choosing the best version for the hardware. For specific NVIDIA GPUs, NIM downloads the optimized TensorRT engine and runs inference using the TensorRT-LLM library, while for other GPUs, it uses alternatives including the open source libraries such as vLLM. The following diagram illustrates a high-level solution architecture demonstrating how you can utilise NVIDIA NIM in an OCI tenancy:-
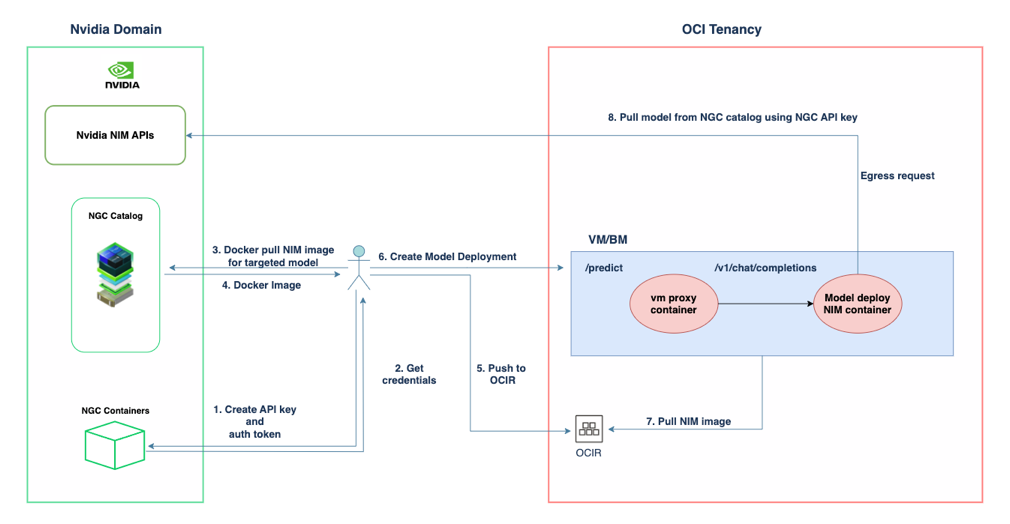
To deploy NIM in OCI, use the following steps:
- Create an API key and auth token: In the NVIDIA domain, create an API key and an authentication token to access the NGC catalog.
- Get credentials: Obtain the necessary credentials using the created API key and auth token.
- Docker pull NIM image for targeted model: Use the Docker pull command to retrieve the NIM image for the targeted model from the NGC catalog.
- Docker image: The pulled NIM image is now available as a Docker image.
- Push to Oracle Cloud Infrastructure Registry (OCIR): Push the Docker image to the OCIR.
- Create Model Deployment: User shall create a model deployment in the OCI tenancy, utilizing the Docker image pushed to OCIR.
- Pull the NIM image: In the OCI tenancy, pull the NIM image from OCIR to the virtual machine or bare metal environment.
- Pull the model from the NGC catalog using then NGC API key: The model deployment retrieves the model from the NGC catalog using the NGC API key, making an egress request to the NVIDIA domain if necessary.
The components of this deployment interact in the following ways:
- VM or bare metal environment: In the OCI tenancy, a VM or bare metal environment is set up to handle predictions and chat completions. This environment includes a VM proxy container and a model deployment NIM container.
- VM proxy container: Facilitates the communication between the user’s request such as predict and chat completions, and the model deployment NIM container.
- Model deployment NIM container: Runs the model inference and processes the user’s request, using the deployed NIM model.
When a NIM is first deployed, NIM inspects the local hardware configuration, and the available optimized model in the model registry – and then automatically chooses the best version of the model for the available hardware. For a subset of NVIDIA GPUs, NIM downloads the optimized TensorRT engine and runs an inference using the TensorRT-LLM library. For all other NVIDIA GPUs, NIM downloads a non-optimized model and runs it using an alternate library such as vLLM. NIM microservices are distributed as NGC container images through the NVIDIA NGC catalog. A security scan report is available for each container within the NGC catalog, which provides a security rating of that image, breakdown of CVE severity by package, and links to detailed information on CVEs.
Let’s demonstrate how to integrate NVIDIA NIM features into OCI. NIM, which can seamlessly be integrated with OCI Data Science, can transform the deployment and management of generative AI models. It enhances the capabilities of OCI Data Science in the following ways:
- Simplified AI deployment: Streamlines operations, enabling efficient management of large language models (LLMs) by development teams.
- Scalable solutions: Offers scalable deployment options that maintain performance across varying loads, from a few users to millions.
- Advanced AI capabilities: Provides robust support for advanced LLMs, enhancing OCI with powerful natural language processing and understanding for applications like chatbots and AI assistants.
- Flexible developer tools: Equips developers with OpenAI API-compatible programming models and NVIDIA custom extensions, facilitating easy integration into existing and new applications.
- Optimized performance: Each container is optimized for specific NVIDIA GPUs, to help ensure optimal performance within the OCI environment.
- Enhanced security: Implements comprehensive security measures, including continuous monitoring and proactive vulnerability management, to help maintain high standards of data protection.
Getting started
To get started with NIM on OCI, customers can bring the required NIM image to OCIR. They can use these images as a Bring Your Own Container (BYOC) offering in OCI Data Science model deployments. To show an example of deploying Llama 3 8B using NIM, refer to the end-to-end Readme file on our GitHub repository. It details the steps on how to customize NIM-based images and make them compatible to successfully run them on OCI Data Science. To learn more about NVIDIA NIM, its offering, and enabling these offerings on Oracle Cloud Infrastructure, use the following resources:




