As Oracle teams expanded their use of LLMs in 2023, evaluation work expanded just as quickly. Teams were benchmarking models, validating prompts, testing product scenarios, and comparing systems for local decisions. Useful work was happening everywhere, but getting a reliable answer about model behavior still took too long.
The issue was fragmentation. Evaluation lived across scripts, datasets, prompts, metrics, and reporting styles. Results could answer one team’s immediate question, but they were hard to compare, reproduce, or scale into a broader view of model quality.
Veritas was built to address that problem: to make evaluation a structured engineering system, with reusable components, reviewable methodology, and a runtime model that could support many workloads.
The Problem We Had to Solve
When we started, each new paper, benchmark, or product ask tended to create its own mini-stack: custom data loading, prompting, scoring, reporting, and glue code.
That was a reasonable local optimization under pressure. Over time, though, it became a global problem. Every new evaluation added another special case. Reuse became accidental. Comparing results across tasks got harder. Operational needs such as batching, retries, checkpointing, and exports were reimplemented repeatedly.
We needed an evaluation framework that could:
- cover a wide range of tasks quickly
- make benchmark onboarding cheap, with extension points when needed
- keep evaluation logic reproducible and reviewable
- support retries, checkpointing, reporting, and exports
- preserve velocity while reducing reinvention
Learning From the Existing Landscape
We were not building in a vacuum. Systems such as HELM, lm-evaluation-harness, and OpenAI Evals helped move the field toward more standardized and reusable evaluation. They showed the value of shared harnesses, transparent methodology, and treating evaluation authoring as a first-class capability.
Veritas was built for a different set of constraints, and at the time, many of these systems were either not yet available or not mature enough for our needs. We needed to support many internal workloads, let users author new evaluation pipelines quickly, treat the full pipeline as a structured object, and make execution concerns such as retries, checkpointing, and exports part of the framework itself.
What Veritas Built
The central idea in Veritas is simple: evaluations should follow a visible, reusable structure.
At a high level, that structure is:
- Transformation
- Generation (System Under Test)
- Evaluation
- Summarization
This four-stage backbone became the authoring model across the framework.
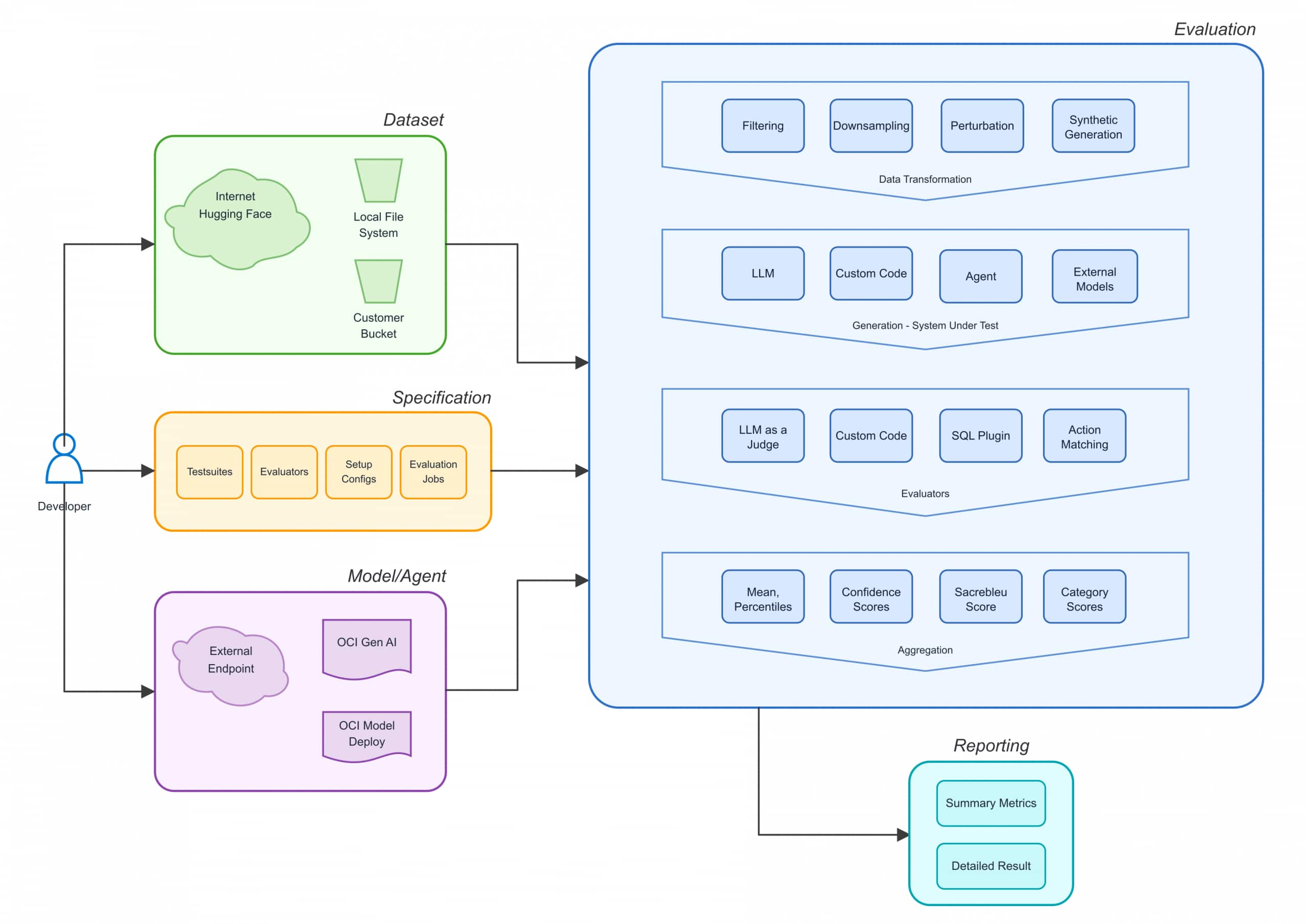
Naming these stages gave authors a common model for describing what an evaluation does and where custom logic belongs.
Pipeline Structure
Every evaluation pipeline can express:
- where the data comes from
- how it is transformed
- which predictor generates outputs
- which evaluators score those outputs
- which post-processing steps run
- how results are summarized and exported
That turns an evaluation from “some code that happened to work once” into a repeatable pipeline definition.
Composable Components
Veritas separates authoring concepts from runtime concepts. Most of these concepts are expressed as declarative YAML objects, which can be defined, reviewed, and composed without burying the evaluation pipeline inside imperative code.
Testsuites define end-to-end evaluation pipelines. Benchmarks group testsuites into larger campaigns. Evaluation jobs bind those pipelines to runtime settings and model endpoints. Predictors define generation behavior. Evaluators define scoring behavior. Systems and endpoints define how models are configured and reached at runtime. Setup configs describe external environments for stateful evaluations, while setup instances record the concrete resources created from those configs.
This makes reuse practical. A new benchmark often needs a new composition of existing pieces and only occasionally a new predictor or evaluator. The framework stays stable even as the workload mix changes.
Extensibility Model
One of the most important design goals in Veritas was that the cost of adding something new should be proportional to the complexity of what is new.
Veritas supports several extension paths, each matched to the amount of novelty in the benchmark.
- If the benchmark is mostly a new composition of existing pieces, the cheapest path is to add a testsuite that wires together existing data, predictors, evaluators, and summaries.
- If the benchmark needs lightweight customization, Python expressions can handle prompt shaping, normalization, answer extraction, and post-processing without requiring new framework code.
- If the benchmark introduces genuinely new reusable logic, the next step is to implement a predictor or evaluator and register it as a component.
- If the benchmark depends on an external codebase or more specialized behavior, plugin-style integration and custom code are still available, but they become the last resort rather than the default path.
Small changes stay small. Larger additions are supported, but the engineering cost is reserved for the cases that actually require it.
This becomes especially useful in the middle layer between pure configuration and full custom code. Authors can add benchmark-specific logic while staying inside the framework rather than branching into one-off infrastructure.
In this simplified example, the benchmark changes the prompt, runs a predictor, uses a reasoning evaluator, and derives two correctness metrics without adding new framework code.
test_data_location:
path: "perturbed_gsm.csv"
type: LOCAL
post_transformation:
prompt: "'Solve the following problem carefully and return only the final answer: ' + data.prompt"
prediction:
llm:
predictor_id: llm_1.0
input:
prompt:
column: data.prompt
evaluation:
reasoning:
evaluator_id: reasoning/reasoning_1.0
input:
answer:
column: prediction.llm.completion
post_evaluation:
exact_match_score: "1 if evaluation.reasoning.completion == data.reference else 0"
rounded_match_score: "1 if round(float(evaluation.reasoning.completion), 0) == round(float(data.reference), 0) else 0"
summary:
statistics:
type: statistics
has_mean: true
columns:
- evaluation.exact_match_score
- evaluation.rounded_match_score The value is not just convenience. post_transformation shapes the prompt, the evaluator handles the heavier reasoning logic, and post_evaluation derives multiple views of correctness from the same output. These adaptations stay lightweight and reviewable instead of becoming one-off benchmark code.
Runtime Model
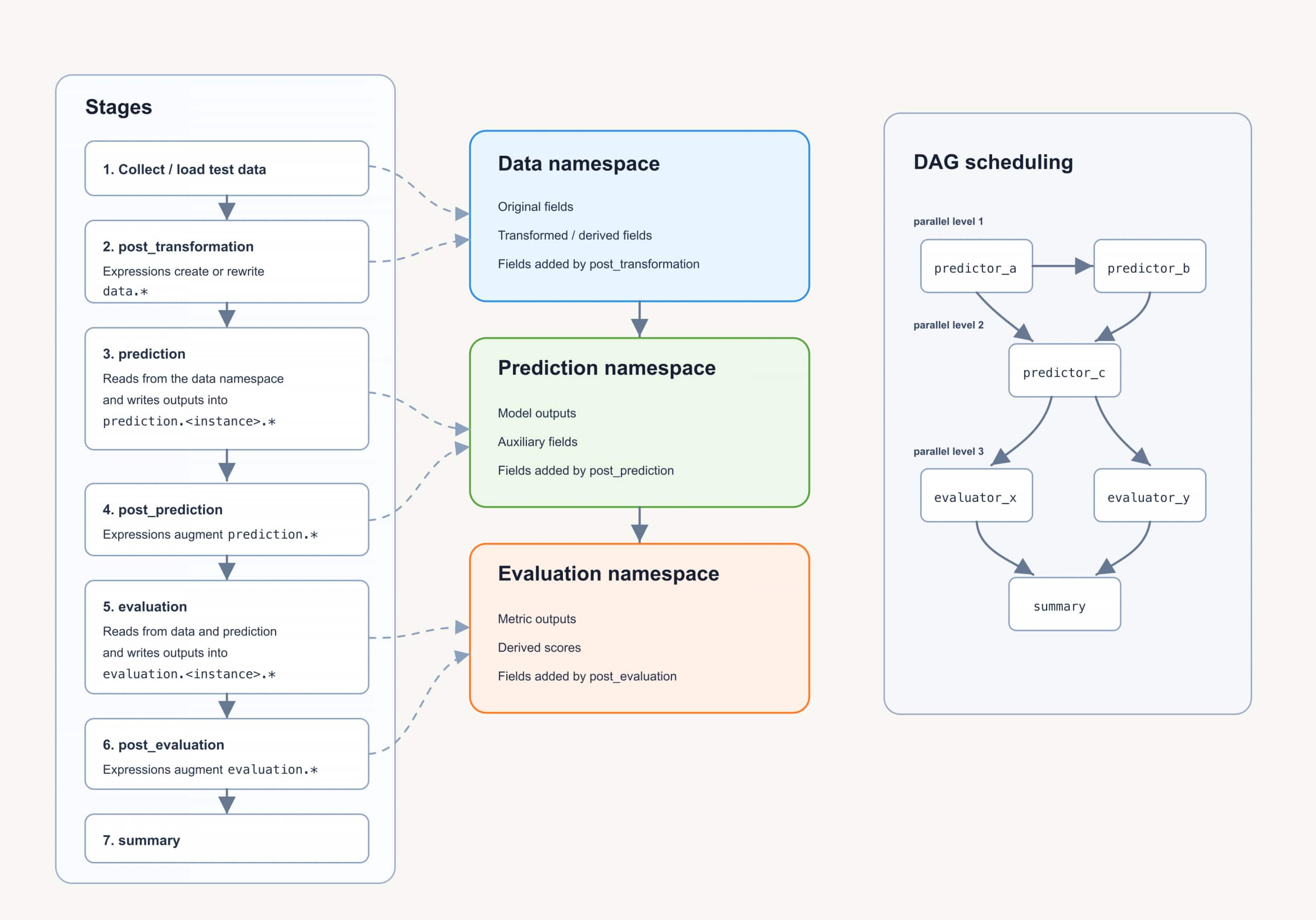
Veritas treats execution as part of the framework, not as an afterthought.
At runtime, each testsuite is lowered into tasks for data collection, transformation, prediction, evaluation, post-processing, checkpoint restore, and upload. The scheduler tracks dependencies, launches work when prerequisites are complete, and applies concurrency limits so complex evaluations can execute reliably at scale.
The runtime uses explicit namespaces for intermediate state, including data.*, prediction.*, and evaluation.*. Those references define the execution graph. If one processor depends on prediction.llm.completion and another depends on evaluation.reasoning.score, the scheduler can order them correctly, run independent work in parallel, and surface structural problems such as dependency cycles early.
External Evaluation Environments
Some evaluations need an external state: a database, seeded tables, or a service for executing generated code. Veritas makes that setup explicit.
A setup config describes the required environment, such as micro VMs for code execution, or an Oracle Database initialized with DDL and DML. A setup instance records the concrete resource created from that config, such as the deployment identifier.
This keeps stateful evaluations reproducible. The benchmark does not hide infrastructure inside scripts; it declares what must exist, runs against that resource, and can clean it up as part of the evaluation lifecycle.
Safe Expression Evaluation and Checkpointing
Veritas supports Python-like expressions for prompt shaping, normalization, answer extraction, post-processing, and summary calculations. Those expressions are evaluated through a constrained AST-based layer rather than unrestricted eval, which keeps configuration flexible without making it arbitrary code execution.
Checkpointing is built into the runtime as well. Intermediate work for predictors, evaluators, post-processing, and summaries can be restored and resumed, which matters when evaluations are long-running, expensive, or operationally noisy.
Pluggable Stages
High-level framework stages can be extended through registries and annotations such as @register_transformer and @register_summary. New capabilities plug into the same scheduling and execution model rather than creating a parallel path outside the framework.
What This Changed in Practice
The clearest sign that this worked is the ecosystem it enabled.
At the time of writing, the repository contains contributions from multiple scientists and engineers, including:
- 150+ testsuites
- 50+ model evaluation reports
These are not just variants of one narrow task. Veritas spans reasoning, RAG, responsible AI, web search, support-agent evaluation, multilingual tasks, multimodal evaluation, code generation, NL2SQL, and product-facing workloads.
The practical change was a better operating model. Teams could onboard new benchmarks without rebuilding common infrastructure, reuse shared predictors and evaluators across workloads, and compare results within a more consistent execution and reporting structure.
That shortened the path from question to answer. Scientists and engineers could spend more time on benchmark design, scoring logic, and model behavior, and less time reconstructing plumbing.
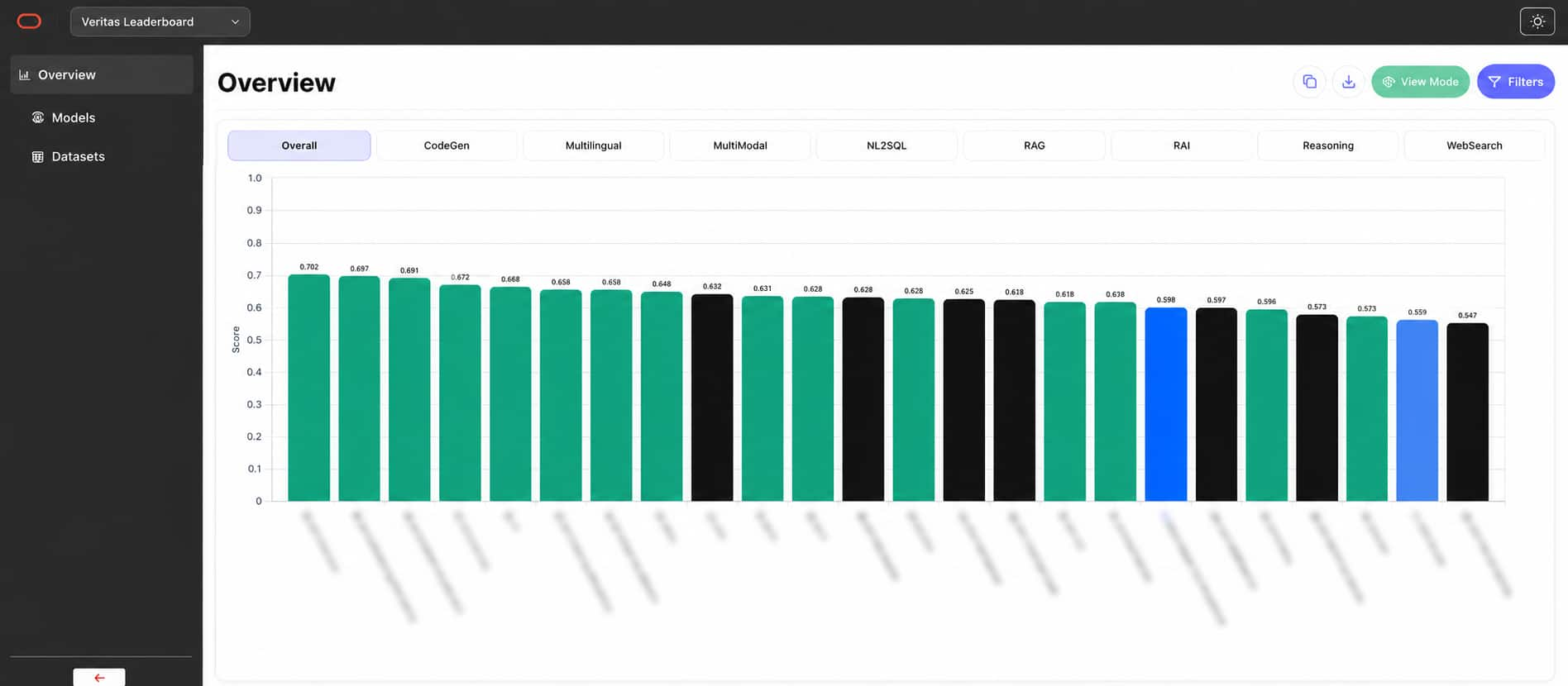
It also made an internal leaderboard possible. Once benchmark execution, summaries, and metadata were standardized, results could be aggregated into a common view of quality, cost, and latency. A model was no longer just “better” or “worse” in the abstract. Teams could see whether a quality gain justified a change in spend or response time for a particular use case.
AI Forward
Once evaluation authoring becomes structured, parts of benchmark onboarding become much more teachable and automatable.
The path from a paper or reference repository to an executable evaluation becomes clearer:
- Read the paper or reference repo
- Identify task definition, data format, prompts, and scoring logic
- Map those into testsuite, predictor, evaluator, and summary components
- Generate a draft recipe that a human can review and refine
That is the kind of workflow that can benefit from agentic assistance.
In Veritas, some of this integration knowledge is now packaged as skills. One example is the benchmark-integration skill: a repeatable set of instructions for reading a paper or repository, deciding whether direct integration or code addition is appropriate, reusing existing predictors and evaluators where possible, and generating the right specs.
There is also a broader research trend here. Systems such as PaperBench are exploring whether agents can turn research artifacts into executable implementations. The target in Veritas is narrower and more practical: produce a structured evaluation recipe inside a framework with clear interfaces rather than reproduce an entire paper end to end.
Closing Thought
Veritas turned evaluation from a collection of individualized scripts into a shared system with explicit stages, reusable components, and a common runtime model.
That made it easier to scale coverage, compare results, reduce reinvention, and support a broader range of Oracle evaluation workflows on top of the same foundation.
As evaluation moves toward more agentic, multimodal, and product-integrated systems, that foundation matters even more. It gives teams a structured way to keep expanding coverage without starting over each time.
Acknowledgements
Veritas was shaped through contributions from many engineers and scientists from the Veritas team and the OCI AI science organization. Special shout-out to Ashok Nagarajan, Anirudh Ayalasomayajula, Junru Pu, Graham Horwood, Liyu Gong, Shwan Ashrafi, Afshin Oroojlooy, Longjiao Zhang, Roshan Sridhar, Aziza Mirsaidova, Ksheeraja Raghavan, and many others who helped evolve the framework, benchmarks, and evaluation workflows over time.
References
- HELM: https://github.com/stanford-crfm/helm
- OpenAI Evals: https://github.com/openai/evals
- lm-evaluation-harness: https://github.com/EleutherAI/lm-evaluation-harness
- PaperBench paper: https://arxiv.org/abs/2504.01848

