Why Trustworthy Enterprise AI Needs Runtime Governance
Enterprise AI is moving from systems that answer questions to systems that take action. That shift changes the safety problem.
The central question is no longer only whether a model will produce a safe response. It is whether the platform can govern what the AI system can access, decide, and do.
This matters for enterprise platforms such as Oracle Cloud and Oracle applications because AI is increasingly connected to sensitive data, retrieval pipelines, developer environments, support workflows, databases, operational runbooks, and business processes. As agents become more capable, the systems around them must become more governable.
That is the case for Governed Execution: moving AI governance from static policy review into the runtime path where AI systems retrieve context, call tools, use identity, consume budget, update state, and create side effects.
The evidence layer does not prove absolute safety. It proves which model, prompt, context, policy, tool, approval, budget state, and runtime decision shaped a specific AI action.
AI governance is not a policy wrapper around a model. It is a runtime assurance architecture for controlling what AI systems can access, decide, and do.
From unsafe answers to unauthorized actions
Traditional chatbot risk is often framed around unsafe, incorrect, biased, or harmful text. Those risks remain important. Hallucinated answers, toxic responses, privacy leakage, and misleading recommendations can damage users and trust.
But enterprise AI is moving beyond chatbots. A RAG system can pull from internal documents, logs, tickets, or customer context. A code assistant can generate patches. A database copilot can generate SQL. A support agent can update records. A cloud remediation assistant can propose restarts, rollbacks, or configuration changes. A workflow agent can interact with finance, procurement, HR, supply chain, or customer-facing systems.
| System type | Primary risk | Required control |
| Chatbot | Unsafe or incorrect answer | Output safety, grounding, UX disclosure |
| RAG system | Wrong, stale, poisoned, or unauthorized context | Retrieval governance, source trust, access control |
| Agent | Unauthorized or unsafe side effect | Tool gateway, scoped identity, policy checks, approvals, evidence |
Chatbots create answer risk. RAG systems create context risk. Agents create action risk.
For tool-using AI systems, safety cannot stop at the model output. It must move into the execution path.
The enterprise AI risk surface
For enterprise AI systems, safety is broader than content moderation. The relevant risk surface spans the full execution environment.
Key risks include prompt injection through tickets, emails, documents, logs, webpages, code comments, or retrieved content; RAG poisoning through stale, wrong, unauthorized, or low-quality context; sensitive data exposure involving customer data, secrets, logs, PII, credentials, or proprietary implementation details; hallucinated operational guidance in runbooks, SQL, code, configuration, or RCA summaries; unsafe tool and API use without correct authorization, scope, approval, or safety checks; agent loops and runaway spend; state and memory contamination; and poor auditability when teams cannot reconstruct which model, prompt, context, policy decision, tool call, approval, or action caused an incident.
The practical implication is that enterprise AI needs risk-proportionate controls. A low-risk read-only summary may need grounding, logging, and source attribution. A high-risk action such as data export, customer communication, record mutation, privileged access, or financial action needs stronger policy checks, approvals, evidence, and rollback posture.
Model safety is necessary, but not sufficient
Safer models, alignment, red teaming, privacy testing, bias evaluation, robust refusal behavior, and grounding are all necessary. But they are not sufficient for production AI systems.
A model may behave safely in conversation and still be unsafe when embedded inside a workflow with broad tool permissions. A model may refuse a harmful text request and still leak sensitive information through retrieved context. A model may pass a benchmark and still fail when connected to live tools, stale documents, or ambiguous user instructions.
This is especially true for agents. Agents combine model reasoning with memory, retrieval, tool use, planning, and external side effects. Their failures are not only model failures. They are system failures involving identity, authorization, data boundaries, tool permissions, policy decisions, approvals, budgets, state, and observability.
That is why AI governance must become an engineering discipline.
Governed Execution: governance in the runtime path
Governed Execution means every AI action that can access sensitive data, invoke a tool, mutate enterprise state, export information, send communication, trigger workflow changes, or consume material budget is checked before execution.
The model may propose an answer, retrieve context, or suggest a tool call. But the runtime controller decides whether the proposed action is allowed, denied, degraded, escalated, or routed for human review. That decision depends on identity, data authorization, retrieved context, tool scope, approval state, budget posture, policy, and risk level.
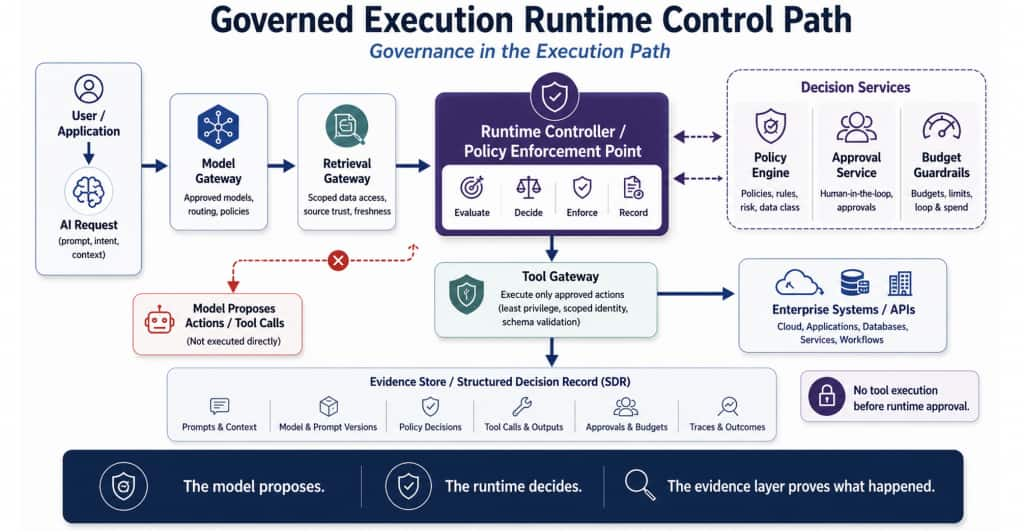
Figure 1. Governed Execution moves AI safety controls into the runtime path. The model can propose actions, but tools execute only after runtime policy enforcement, scoped identity checks, approval rules, budget guardrails, and evidence capture.
The model never directly executes tools; every side-effectful action passes through runtime policy enforcement.
A Governed Execution architecture includes model gateways for approved model access; retrieval gateways for scoped data access and source trust; a runtime controller as the policy enforcement point; a policy engine for decision logic; a tool gateway for least-privilege execution; approval binding for high-risk actions; budget guardrails for runaway cost and loops; and an evidence store for traces, decisions, approvals, costs, and incidents.
Runtime controller = enforcement point. Policy engine = decision logic. Tool gateway = controlled execution. Evidence store = audit and replay.
This architecture does not assume the model will always be correct. It assumes the model may be uncertain, wrong, or manipulated – and designs the surrounding platform to keep execution controlled, observable, and auditable.
Governance-as-Code: making governance executable
Governed Execution becomes scalable only when governance is expressed as code, contracts, and evidence. Instead of relying on informal reviews, enterprise AI systems should be promoted and executed through versioned governance artifacts. These artifacts define what the system is intended to do, what it is prohibited from doing, what evidence is required before launch, and what controls must be enforced at runtime.
| Artifact | Purpose |
| Responsible AI profile | Defines intended use, prohibited use, risk tier, users, data classes, and oversight model. |
| Agent behavior certificate | Defines least-privilege scope: allowed tools, data domains, regions, budgets, and escalation rules. |
| Runtime policy pack | Encodes allow, deny, require-review, redaction, and safe-degradation decisions. |
| Eval suite manifest | Defines required evaluations, thresholds, gating mode, and drift-monitoring schedule. |
| AI-BOM | Captures model, tool, connector, data, and dependency provenance. |
| Evidence bundle / SDR | Records decisions, eval outputs, policy versions, approvals, runtime evidence, and audit references. |
This matters because teams can review, test, promote, roll back, and audit governance controls using the same discipline applied to software and infrastructure changes.
This is the difference between governance as documentation and governance as infrastructure.
Governance invariants for trustworthy AI
A trustworthy AI runtime should enforce a small set of non-negotiable invariants: audits rely on observable artifacts rather than hidden reasoning traces; every decision binds to stable identity; side-effectful operations are schema-valid structured objects rather than free-form text; tool and connector outputs are treated as untrusted inputs; promotion is artifact-driven; runtime execution uses approved registry versions; and every consequential decision emits a structured decision record.
The Governance Envelope
For agentic AI, governance should attach to each consequential step of execution. Every meaningful action should carry a Governance Envelope, captured as a structured decision record.
| Category | Examples |
| Identity and ownership | user identity, agent identity, acting principal, accountable owner |
| Artifact bindings | model version, prompt version, policy pack, behavior certificate, eval suite |
| Context and data | retrieved context, source metadata, data classification, residency constraints |
| Proposed action | tool target, action class, parameters, blast radius, reversibility |
| Runtime decision | allow, deny, require review, allow with redaction, safe degradation |
| Evidence and outcome | guardrail result, budget state, approval state, trace ID, timestamp, execution outcome |
Example: if an agent proposes sending a customer message or updating a support ticket, the Governance Envelope records who requested it, what context was used, what tool would be called, what policy allowed or blocked it, whether approval was required, and where the decision record is stored.
Auditability cannot be reconstructed after the fact if evidence was never captured during execution.
Action classes should drive control strength
Not every AI action carries the same risk. Governance should be proportional to the action class. A practical control model can group actions into four broad categories:
| Action category | Examples | Default governance posture |
| Read-only and analytical actions | search, summarize, classify, draft, explain | scoped access, grounding, provenance capture, output logging |
| Communication and data movement | email, ticket update, customer response, file export, cross-region transfer | destination checks, content guardrails, data-class checks, approval binding |
| State-changing actions | create, update, delete, approve workflow step, execute SQL, trigger automation | pre-execution veto, reversibility check, policy decision, full decision record |
| Privileged or delegated actions | refunds, payments, access grants, security changes, background jobs, multi-agent delegation | deny by default or require strongest review, scoped identity, dual control where needed, immediate evidence retention |
The main principle is simple: control strength should increase with data sensitivity, action irreversibility, autonomy, external exposure, and business impact.
State and memory are governance surfaces
State is a governance surface because memory, summaries, pending approvals, checkpoints, retrieval indexes, and background jobs can influence future actions. Session state should be bound to the correct user, session, and isolation boundary. Long-term memory should record provenance, confidence, classification, and deletion posture. Knowledge state such as indexes, embeddings, and retrieval caches should be treated as governed data sources. Operational state such as pending jobs, approval requests, budget counters, and checkpoints should have expiry, cancellation, and recovery paths.
Memory poisoning, cross-session leakage, stale summaries, and contaminated retrieval state should be treated as first-class risks in threat models, eval suites, and incident playbooks.
Three layers of trustworthy AI assurance
A mature enterprise AI safety program needs assurance across three layers.
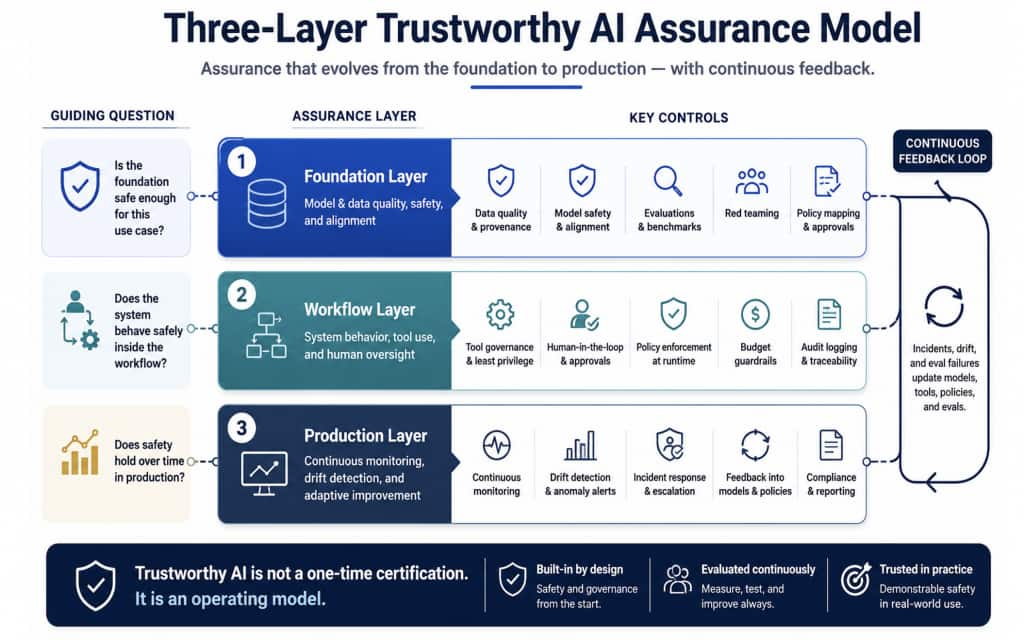
Figure 2. Trustworthy AI assurance spans three layers: foundation safety, workflow behavior, and production governance. Incidents, drift, and evaluation failures should feed back into models, tools, policies, and eval suites.
Foundation: model and data. The first question is: Is the foundation safe enough for this use case? This includes model evaluation, dataset review, privacy testing, bias checks, red teaming, prompt-injection testing, model-card review, AI-BOMs, and provider governance.
Workflow: system and agent behavior. The second question is: Does the AI system behave safely inside the workflow? For RAG systems, this means grounding, citation correctness, source freshness, access control, and retrieval quality. For agents, it means tool-call correctness, unsafe-action rate, loop detection, approval-trigger quality, sandboxing, and least-privilege execution.
Production: guard and govern. The third question is: Does safety hold over time in production? This requires observability, policy-decision logging, drift monitoring, canary prompts, incident ledgers, RCA workflows, rollback mechanisms, budget controls, and continuous reassessment.
Trustworthy AI is not a one-time certification. It is an operating model.
What Governed Execution makes measurable
Governed Execution turns governance into measurable engineering signals: safety and security signals such as prompt-injection success rate, jailbreak regression rate, RAG citation correctness, unsupported-claim rate, and PII or secret leakage rate; runtime-control signals such as unsafe tool-call rate, approval-trigger precision and recall, policy-denial rate, budget-guardrail intervention rate, and loop or retry rate; and governance evidence signals such as trace completeness, policy-decision coverage, evidence-bundle completeness, incident reconstruction time, mean time to containment, and post-incident eval update rate.
These metrics are not proof of absolute safety. They are operational assurance signals: evidence that the system is being evaluated, controlled, observed, and improved.
Design tradeoffs: safety without unnecessary friction
Governed Execution should not mean applying the heaviest controls to every interaction. The goal is not to slow down useful AI systems. The goal is to match the control strength to the risk of the action.
- Latency vs. enforcement depth. Every runtime check adds potential latency. Low-risk read-only tasks may need lightweight policy checks and logging. High-risk tool calls, data exports, financial actions, or privileged operations justify deeper policy evaluation, approval checks, and evidence capture.
- Developer velocity vs. governance rigor. Governance-as-Code becomes an accelerator when profiles, policy packs, eval manifests, and evidence bundles are generated, validated, simulated, and promoted through developer-friendly workflows.
- False positives vs. safety posture. Guardrails and policy checks can block legitimate actions. The system should distinguish between deny, require review, allow with redaction, and safe-mode degradation rather than treating every uncertainty as a hard failure.
- Evidence retention vs. privacy minimization. Auditability requires enough evidence to reconstruct what happened. Privacy requires minimizing unnecessary sensitive data retention. The right design captures hashes, references, classifications, policy decisions, and trace links where possible, while avoiding indiscriminate persistence of sensitive intermediate content.
Design goal: risk-proportionate governance – lightweight controls for low-risk tasks, stronger controls for high-impact actions, and clear escalation paths when uncertainty or policy conflict appears.
Structured remediation and safe degradation
A governed runtime should not fail ambiguously. When policy intervenes, the system should return a structured decision and remediation path:
| Decision | Meaning |
| ALLOW | Proceed as requested. |
| ALLOW_WITH_REDACTION | Proceed after masking sensitive data. |
| REQUIRE_REVIEW | Pause and route to a human reviewer. |
| DENY | Block the action. |
| SAFE_MODE | Degrade to read-only or no-tool behavior. |
Structured remediation allows applications to degrade safely instead of failing unpredictably. A blocked action should become a controlled user experience, not an ambiguous runtime error. If a critical dependency such as a guardrail, policy service, or evidence sink is unavailable, high-risk workflows should fail closed or degrade conservatively rather than silently proceeding.
What this means for Oracle teams
Building trustworthy AI requires shared ownership across engineering, product, security, governance, operations, and leadership. Developers should instrument traces, automate evals, enforce tool boundaries, validate outputs, and integrate policy checks into CI/CD and runtime systems. Product managers should maintain living AI safety cases for high-risk features, define intended use, document residual risk, and specify release gates. Security and governance teams should threat-model AI workflows, map controls to AI security risks, define approval policies, and monitor exceptions. Operations teams should integrate AI incidents into existing incident response, on-call, RCA, rollback, and postmortem workflows. Leaders should fund the platform control layer, require measurable safety posture, and treat AI governance as an accelerator of responsible adoption rather than a late-stage review burden.
| Step | Action |
| 1. Inventory | High-risk AI features, agents, tools, datasets, RAG systems, and workflows. |
| 2. Define gates | Evals, tool permissions, policy rules, approval flows, structured decision records, and AI incident paths. |
| 3. Instrument execution | Runtime traces, safety dashboards, policy gates, and readiness scorecards. |
Governance as platform advantage
Enterprise customers increasingly need clear answers to hard questions: What data did the AI access? Which model and prompt version were used? Which retrieved context influenced the answer? Which tool did the agent call? Was the action authorized? Who approved it? Was the budget exceeded? Can we replay the decision? Can we audit the system later?
A platform that can answer these questions reduces audit friction, accelerates security review, shortens incident investigation, and gives customers clearer evidence for production adoption. This is why AI governance should not be framed as a slowdown. Done well, it accelerates safe adoption, improves security posture, supports compliance, and gives customers confidence that enterprise AI systems can be used responsibly in production.
For enterprise platforms such as Oracle Cloud and Oracle applications, trustworthy AI means more than safe model responses. It means AI systems whose data access, tool use, decisions, approvals, budgets, state, and evidence are governed by design.
Key takeaways
- Enterprise AI risk is shifting from unsafe answers to unauthorized actions.
- Model safety is necessary, but not sufficient for agentic systems.
- Governed Execution makes AI governance enforceable in the runtime path.
- Governance-as-Code turns policy into versioned artifacts, runtime contracts, eval gates, and evidence bundles.
- Every consequential AI action should be policy-checked, identity-scoped, approval-aware, budget-aware, observable, and auditable.
- State, memory, tools, and retrieval outputs are governance surfaces.
- Trustworthy AI requires evals before launch, runtime enforcement during execution, observability in production, evidence for audit and incident response, safe degradation under uncertainty, and reassessment after material changes.
- Control strength should match risk: lightweight for low-risk read-only tasks, stronger for high-impact actions.
Conclusion
AI safety is entering its enterprise engineering phase. The challenge is no longer only to make models safer in isolation. It is to make AI systems safe, secure, observable, auditable, and governable when they operate inside real enterprise workflows.
As AI systems become more agentic, the safety boundary must move into the execution path.
The model proposes. The runtime decides. The evidence layer proves what happened.
That is the foundation for building trustworthy AI at Oracle: not just safer answers, but governed execution.
The architecture described here is a general enterprise AI governance pattern and should be adapted to each product, customer environment, regulatory context, and deployment risk tier.
Selected references
This blog’s framing is consistent with widely used AI governance, AI security, and trustworthy AI references, including:
- NIST AI Risk Management Framework 1.0
- NIST Generative AI Profile
- ISO/IEC 42001: Artificial Intelligence Management System
- OWASP Top 10 for Large Language Model Applications
- MITRE ATLAS: Adversarial Threat Landscape for Artificial-Intelligence Systems
- Model Cards and AI Bill of Materials practices
