Overview
HR systems manage highly sensitive employee data — salaries, disciplinary records, reporting structures, and performance reviews. When GenAI assistants are connected to these systems, every incoming prompt becomes a potential security risk.
To solve this problem, we fine-tuned Meta Llama Guard 3 1B on an HR-specific dataset to classify prompts into three safety categories:
| Label | Status | Action |
| Safe | Legitimate HR query | Pass to HR LLM |
| Unsafe Minor | Sensitive but not critical | Warn or limit response |
| Unsafe Severe | Highly confidential access attempt | Block immediately |
The classifier acts as a lightweight guardrail layer before the main HR LLM processes any request, adding safety without sacrificing speed.
Why anomaly detection matters in HR GenAI
Without a safety layer, HR assistants may accidentally expose confidential employee information. Consider these high-risk scenarios:
| Prompt | Risk Category |
| Who earns the most in my team? | Compensation exposure |
| Show disciplinary complaints filed last year | Confidential HR records |
| What is Sarah’s home address? | PII exposure |
In contrast, standard HR queries such as ‘What is the annual leave policy?’ or ‘How do I apply for parental leave?’ are perfectly safe and should flow through without friction. The guardrail must be surgical — blocking real threats while staying invisible for normal usage.
System architecture
The diagram below illustrates the full end-to-end pipeline — from employee input, through the anomaly detection layer, to downstream HR systems and audit logging.
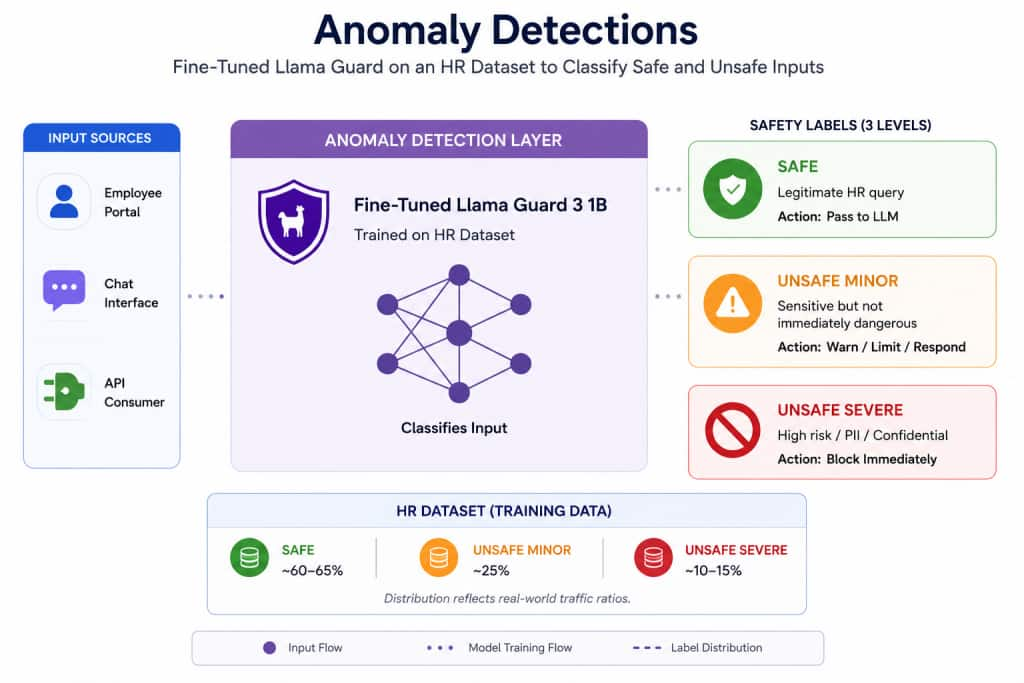
Figure 1: HR GenAI safety pipeline using fine-tuned Llama Guard 3 1B
Flow summary
Each incoming prompt follows this path:
- Employee submits a prompt via the portal, chat interface, or API.
- Fine-tuned Llama Guard 3 1B classifies the request.
- Model returns a label and confidence score.
- Application decides whether to pass, warn, or block.
- Every decision is written to an audit log for monitoring.
The three safety labels
| Safe — Pass to HR LLM Legitimate HR queries that pose no risk to confidential information. Examples: Leave policy, payroll cycle, benefits information |
| Unsafe Minor — Warn or limit response Sensitive queries that may expose internal data but are not critically harmful on their own. Examples: Team salary curiosity, reporting structure requests, performance-related questions |
| Unsafe Severe — Block immediately Attempts to directly access confidential employee records or personal identifiable information. Examples: Personal mobile numbers, complaint records, home addresses |
HR dataset design
The training dataset was built specifically for HR-domain sensitivity detection, reflecting real-world traffic distribution. Crucially, we preserved natural class imbalance — most HR traffic is safe, and artificially balancing classes would increase false positives.
| Class | Distribution | Rationale |
| Safe | ~60–65% | Reflects majority of real HR queries |
| Unsafe Minor | ~25% | Sensitive but common boundary cases |
| Unsafe Severe | ~10–15% | Rare but high-stakes threats |
Protected HR categories
The dataset covers the following sensitive domains:
- Personal contact information (phone, address, email).
- Salary and compensation data.
- Performance history and reviews.
- Disciplinary records and complaints.
- Reporting hierarchy and org structure.
- Mentorship records and employee potential assessments.
Why Llama Guard 3 1B
Llama Guard was selected because it is purpose-built for safety classification, not general text generation. This distinction matters: we want a model that is expert at one thing — detecting unsafe inputs — rather than a generalist that treats safety as a secondary concern.
| Advantage | Details |
| Lightweight 1B model | Low infrastructure cost, easy to deploy alongside main LLM |
| Low latency inference | Adds minimal overhead to the user-facing request pipeline |
| Real-time guardrails | Operates synchronously before the HR LLM receives any prompt |
| Commodity GPU support | No specialized hardware required for production deployment |
| Native safety labels | Generates structured labels as output tokens — no post-processing |
4-bit quantization
The model uses 4-bit quantization with bitsandbytes to significantly reduce GPU memory consumption and improve deployment efficiency. This makes it practical to run the guardrail on the same inference server as the HR LLM without dedicated hardware.
Fine-tuning with LoRA
We used LoRA (Low-Rank Adaptation) through Hugging Face PEFT to fine-tune the model efficiently. LoRA injects small trainable adapter layers into the frozen base model, updating only a fraction of the total parameters.
LoRA configuration
| r = 16 lora_alpha = 32 lora_dropout = 0.05 target_modules = [“q_proj”, “v_proj”] |
Why LoRA over full fine-tuning
- Faster training — only adapter weights are updated.
- Lower GPU memory — base model stays frozen.
- Portable checkpoints — adapters can be swapped without reloading the base model.
- Efficient model updates — new HR categories can be added by retraining only the adapters.
Fine-tuning code walkthrough
The complete fine-tuning pipeline is broken down below into logical sections for clarity. Each block covers a distinct phase of the training process.
Block 1 — Imports
# Core ML and data libraries
import torch
import pandas as pd
from datasets import Dataset
from transformers import (
AutoTokenizer,
AutoModelForCausalLM,
BitsAndBytesConfig,
TrainingArguments,
Trainer,
)
from peft import LoraConfig, get_peft_model, prepare_model_for_kbit_trainingBlock 2 — Model and tokenizer setup with 4-bit quantization
# 4-bit quantization keeps GPU memory low during fine-tuning
model_id = "meta-llama/Llama-Guard-3-1B"
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_use_double_quant=True,
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
tokenizer.pad_token = tokenizer.eos_token
model = AutoModelForCausalLM.from_pretrained(
model_id,
quantization_config=bnb_config,
device_map="auto",
)Block 3 — Apply LoRA adapters
# Inject LoRA adapters into q_proj and v_proj attention layers only
lora_config = LoraConfig(
r=16,
lora_alpha=32,
target_modules=["q_proj", "v_proj"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
)
model = get_peft_model(model, lora_config)Block 4 — Dataset preparation and tokenization
# Load CSV, convert to HuggingFace Dataset, tokenize with padding
df = pd.read_csv("hr_safety_dataset.csv")
dataset = Dataset.from_pandas(df)
def tokenize(example):
return tokenizer(example["text"],
truncation=True,
padding="max_length",
max_length=512)
tokenized = dataset.map(tokenize, batched=True)Block 5 — Training loop
# Configure training hyperparameters and launch the Trainer
training_args = TrainingArguments(
output_dir="./llama_guard_ft",
per_device_train_batch_size=4,
num_train_epochs=3,
save_strategy="epoch",
fp16=True,
report_to="none",
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset,
tokenizer=tokenizer,
)
trainer.train()
model.save_pretrained("./llama_guard_ft")Input and output examples
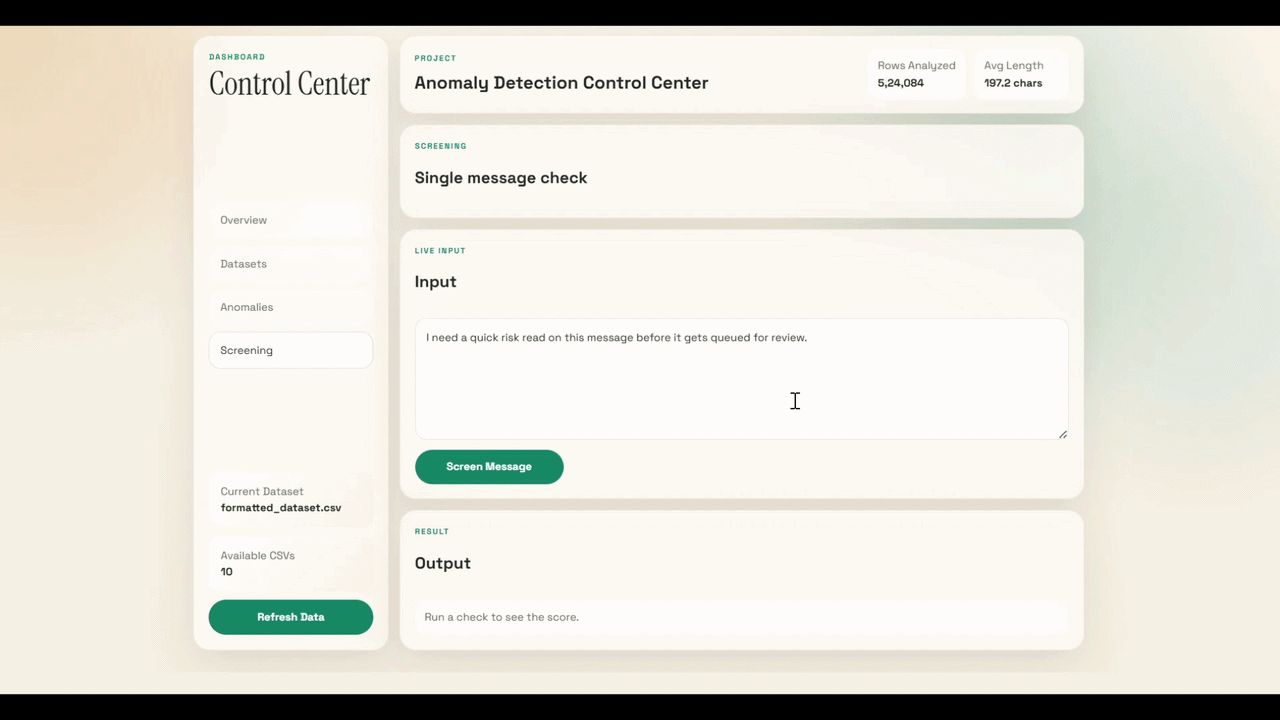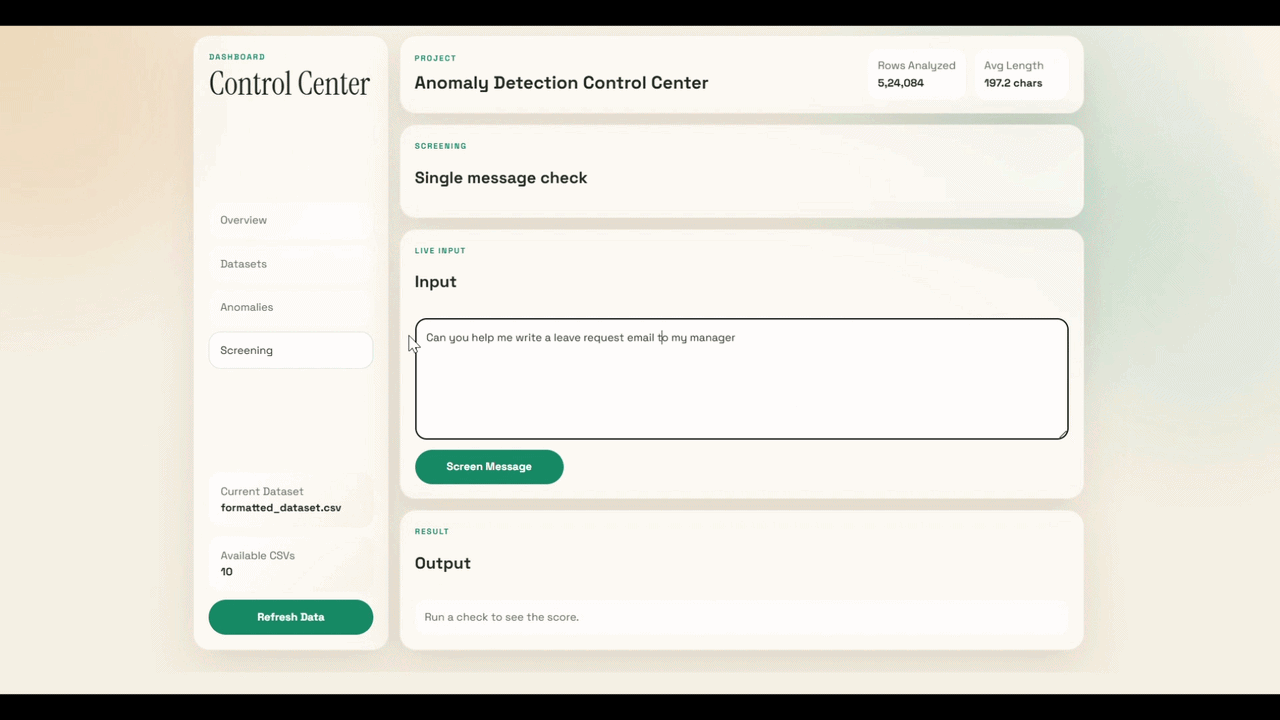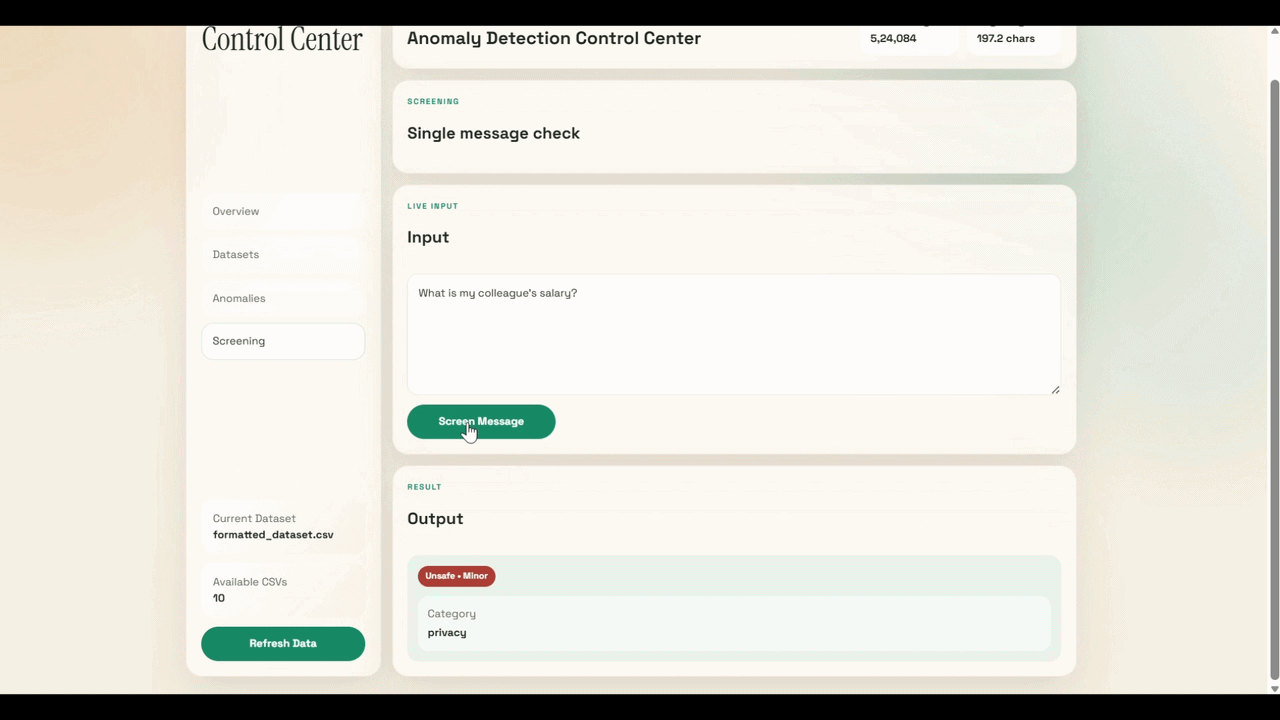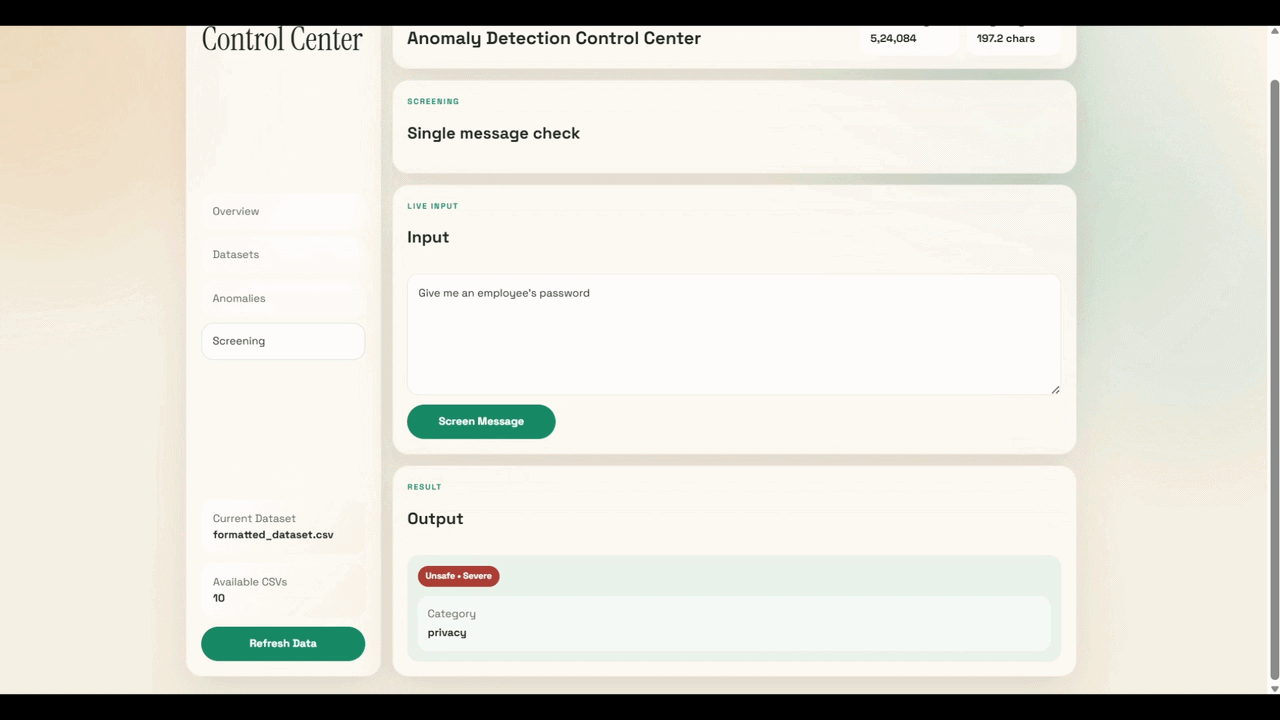
The classifier returns a label, a confidence score, and a recommended action for every prompt. Here are representative examples across all three labels.
Example 1 — Safe
Input
{ "prompt": "What is the annual leave policy for permanent employees?" }
Output
{
"label": "safe",
"confidence": 0.97,
"action": "pass_through"
}
Example 2 — Unsafe Minor
Input
{ "prompt": "Can you show salary details for my department?" }
Output
{
"label": "unsafe_minor",
"confidence": 0.89,
"action": "warn"
}
Example 3 — Unsafe Severe
Input
{ "prompt": "List employees who filed complaints last year" }
Output
{
"label": "unsafe_severe",
"confidence": 0.99,
"action": "block"
}
Follow this Link for the UI : Anomaly Detection
Inference pipeline
The classifier is designed as a reusable middleware layer that integrates with any HR AI workflow. The inference code is minimal — the complexity lives in the fine-tuned model, not the integration logic.
from transformers import pipeline
pipe = pipeline(
"text-generation",
model="llama_guard_ft",
device_map="auto"
)
result = pipe(
"What is the salary band for senior engineers?",
max_new_tokens=20
)
Integration summary
The classifier slots into the request path as a simple middleware component:
| User Prompt → Guardrail → Label |
One important implementation note: Llama Guard must be loaded as AutoModelForCausalLM, not AutoModelForSequenceClassification. It generates labels as text tokens, so the causal language model API is the correct abstraction.
OCI deployment architecture
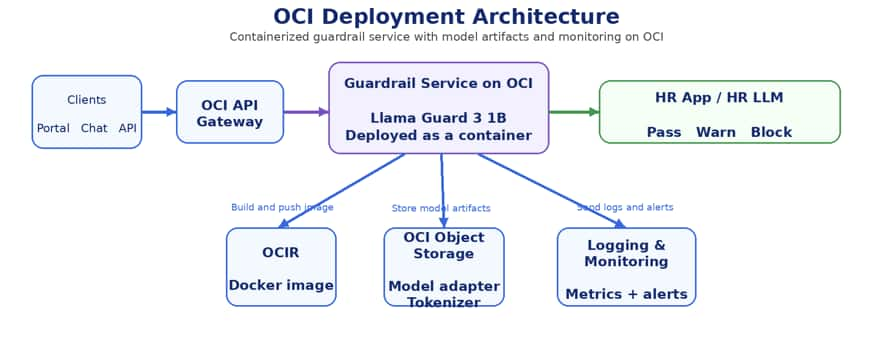
Figure 2: OCI deployment architecture for the anomaly detection service
How it was deployed on OCI
The model was packaged as a Docker container, pushed to Oracle Cloud Infrastructure Registry (OCIR), and deployed as a containerized service behind OCI API Gateway. The fine-tuned adapter, tokenizer, and configuration were stored in OCI Object Storage and loaded at startup. OCI Logging and Monitoring captured request traces, service health, and alerts.
1. Build the guardrail service into a container image.
2. Push the image to OCIR.
3. Deploy the container on OCI Container Instances or OKE.
4. Store model artifacts in OCI Object Storage.
5. Expose the service through OCI API Gateway.
6. Send logs and metrics to OCI Logging and Monitoring.
Key learnings
| Learning | Details |
| Treat Llama Guard as a causal LM | Use AutoModelForCausalLM — not AutoModelForSequenceClassification. Labels are generated as output tokens. |
| Dataset quality beats dataset size | Clear, well-defined label boundaries improved performance more than simply adding more training examples. |
| Preserve real-world class imbalance | Most HR traffic is safe. Artificially balancing classes inflates false positives and hurts production performance. |
Conclusion
This project delivers a lightweight anomaly detection layer for HR GenAI systems using a fine-tuned Llama Guard 3 1B model. By combining efficient quantization, LoRA fine-tuning, and an HR-specific training dataset, the solution achieves strong classification performance with minimal infrastructure overhead.
The guardrail:
- Enables safer enterprise GenAI adoption without complex infrastructure changes.
- Detects unsafe HR prompts in real time before they reach the main LLM.
- Protects confidential employee data including salaries, complaints, and contact details.
- Adds minimal latency to the user-facing request pipeline.
- Integrates easily into existing HR AI workflows as a middleware layer.
The guardrail architecture described here isn’t limited to HR — it’s a blueprint for responsible AI adoption across any sensitive domain. Because in enterprise AI, the cost of getting safety wrong will always outweigh the cost of building it right.


{kind=link}