Hiring teams often lose time across disconnected steps: requisitions and resumes sit in HCM, screening is manual, interviews vary by panel, and feedback is hard to compare. This Agentic Recruiter workflow connects the full process: HCM-driven JD and resume intake, LLM-based entity extraction, Oracle Graph-powered matching, agentic interview scheduling, LiveKit interview rooms, and transcript-backed scorecards.
The goal is simple: help recruiters move from role requirements to explainable shortlists and consistent interview outcomes without losing human control over the final hiring decision.
Why Agentic Hiring Orchestration Matters
HCM as the source of truth:
The workflow starts by pulling requisition context, job descriptions, candidate resumes, role details, and hiring metadata from HCM instead of treating uploads as isolated files. This keeps matching and interview evaluation tied to governed HR data.
LLM-based resume and JD understanding:
The JD and resumes are not stored as raw text only. An LLM extracts structured entities such as skills, education, experience, projects, certifications, location, responsibilities, and evaluation criteria. This converts unstructured documents into reusable hiring intelligence.
Graph-powered candidate matching:
Recruitment data is highly relational. A candidate connects to skills, projects, education, certifications, locations, and experience. A JD connects to required skills, preferred skills, role expectations, and constraints. Oracle Graph models these relationships so the system can match candidates using evidence paths, not just keywords.
Agentic interview scheduling:
After matching, the scheduler becomes part of the agentic flow. It moves shortlisted candidates into the next stage by creating interview records, blocking panel time, generating the LiveKit meeting link, and sending email or calendar invites to the candidate and interview panel.
Consistent multi-round evaluation:
Round 1 is an AI-led adaptive screening round. Round 2 is a human interview supported by transcript capture and interviewer question generation. Both rounds produce scorecards across technical knowledge, communication, problem solving, and confidence.
Architecture: Agentic Recruiter Workflow
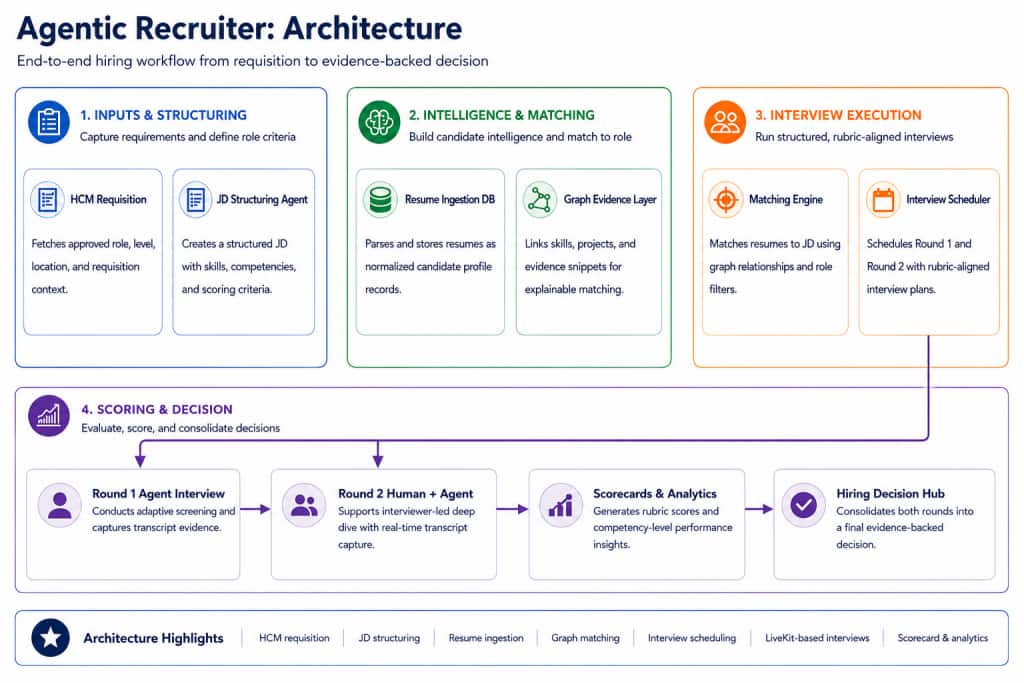
At a high level, the solution has five layers.
1. HCM and recruitment data sources
The workflow begins with HCM requisitions, JDs, resumes, candidate profiles, HR requirements, panel details, and historical feedback.
2. Extraction and parsing layer
LLMs convert JDs and resumes into structured JSON. For resumes, the system extracts candidate identity, skills, projects, education, certifications, experience, and location. For JDs, it extracts role metadata, must-have skills, nice-to-have skills, responsibilities, constraints, and evaluation criteria.
3. Oracle Database and Oracle Graph layer
Structured entities are stored in Oracle Database. Candidate, resume, skill, project, certification, education, job, and requirement records are then represented as graph nodes and edges. Oracle Graph Studio is used to create a PGQL graph over these node and edge tables, enabling relationship-aware candidate filtering. Oracle documentation describes PGQL as a SQL-like query language for property graph data, and Oracle property graphs can be created directly over relational database tables.
4. Matching, scheduling, and interview preparation layer
When a recruiter selects a JD, the matching engine converts the JD requirements into graph filters. It returns explainable candidate shortlists, then the scheduling flow blocks time, creates the interview record, generates the LiveKit link, and sends invites. The same layer can also generate Round 2 question kits for interviewers.
5. LiveKit interview and scoring layer
LiveKit powers the real-time interview rooms. Round 1 includes the candidate and AI interviewer. Round 2 includes the candidate, human interviewer, and passive transcript agent. LiveKit is designed as a horizontally scaling WebRTC SFU for real-time audio/video sessions.
Oracle Graph Studio and PGQL Matching
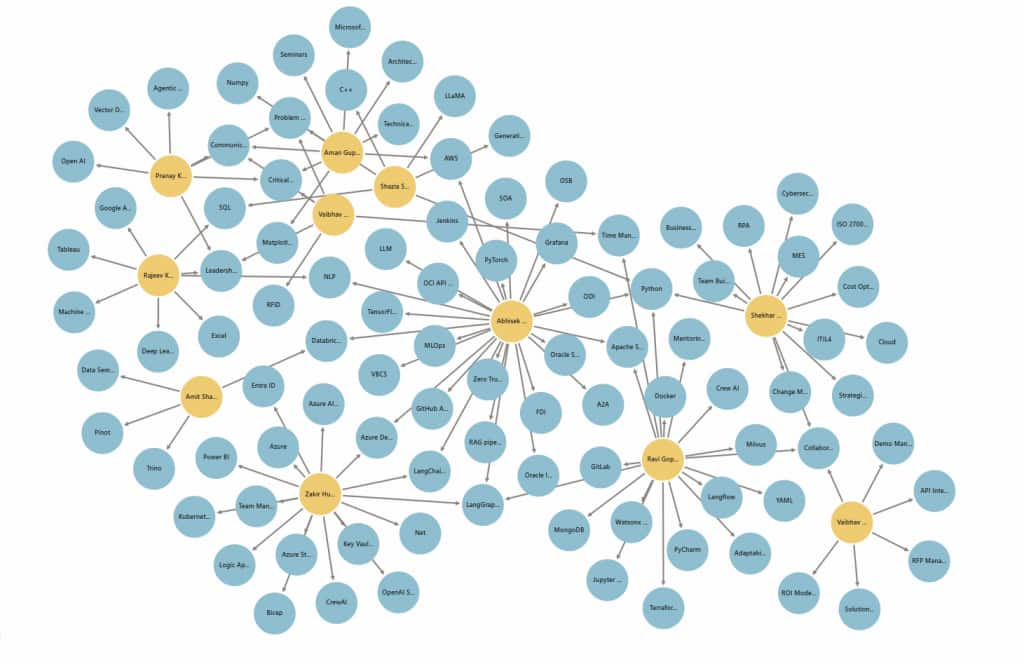
The key matching step happens after LLM extraction.
The extracted resume entities are stored as graph nodes: candidates, skills, projects, education, certifications, locations, and experience. The JD requirements are also represented as graph-connected entities. Oracle Graph Studio then creates a PGQL graph from node and edge tables in Oracle Database.
This lets recruiters ask richer questions than “does the resume contain Python?” The system can check whether the candidate has Python as a skill, used Python in a project, also has SQL, matches the location, and satisfies the role’s experience requirement.
Example PGQL query to inspect candidate-skill relationships:
SELECT c, e, s
FROM MATCH
(c:CANDIDATE)-[e:HAS_SKILL]->(s:SKILLS_MASTER_NEW)
ON GRAPH9Example PGQL query to match candidates against required JD skills:
SELECT c, s
FROM MATCH
(j:JOB_DESCRIPTION)-[:REQUIRES_SKILL]->(s:SKILLS_MASTER_NEW)<-[:HAS_SKILL]-(c:CANDIDATE)
ON GRAPH9
WHERE j.job_id = :job_idExample PGQL query to prioritize project-backed evidence:
SELECT c, p, s
FROM MATCH
(c:CANDIDATE)-[:WORKED_ON_PROJECT]->(p:PROJECT)-[:USED_TECH]->(s:SKILLS_MASTER_NEW)
ON GRAPH9
WHERE s.name IN ('Python', 'SQL', 'FastAPI')The outcome is an explainable shortlist. Recruiters can see not only which candidate matched, but also which skill, project, education, or certification supported the match.
Agentic Interview Scheduler
After JD-resume matching, the workflow should not stop at a shortlist. The interview scheduler continues the agentic story.
It receives the selected candidate, job, panel, interview duration, and preferred date. It then fetches candidate email, HR details, job title, panel information, and match metadata from the database. From there, it creates the interview record, blocks the time slot, prepares the calendar invite, generates the LiveKit interview link, and sends the invite to the candidate and panel members.
This solves a common hiring bottleneck: recruiters no longer need to manually copy candidate details, coordinate panel emails, create meeting links, and update interview status across tools.
LiveKit Multi-Round Interviews
Round 1: AI Screening
The candidate joins a LiveKit room with an AI interviewer. The AI asks role-aligned technical questions, evaluates the candidate’s previous answer, and dynamically changes the next question’s difficulty. Strong answers lead to deeper follow-ups, while weaker answers shift the screening toward easier or broader questions. The graph orchestration layer maintains state such as skill context, current question, difficulty, answer history, and transcript.

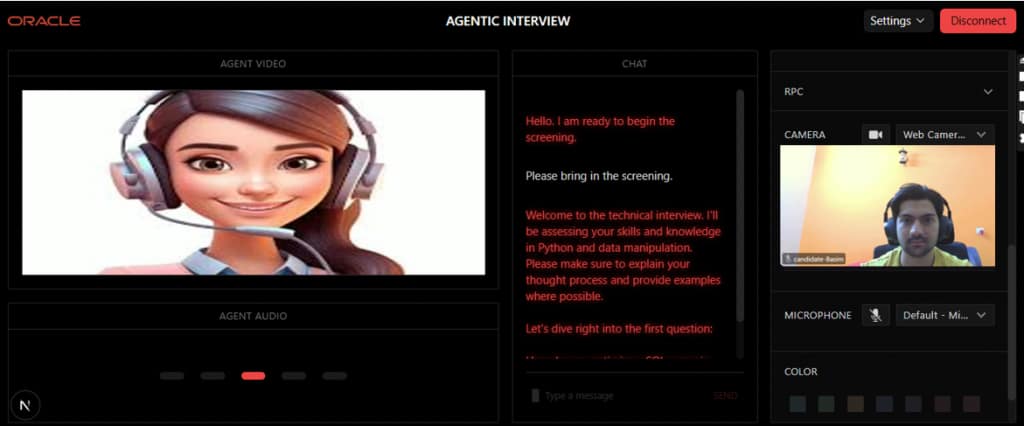
Round 2: Human Interview
The interviewer and candidate join a LiveKit room. The AI does not conduct the interview. A transcript capture agent listens silently, records speaker-wise transcript lines, converts the discussion into structured Q&A, and sends it for scoring.
After the meeting is scheduled, the app can generate an interviewer question kit. The interviewer can specify broad topics, number of questions per topic, and difficulty. This helps ensure the interview covers all important areas instead of depending only on the interviewer’s preferred topics.
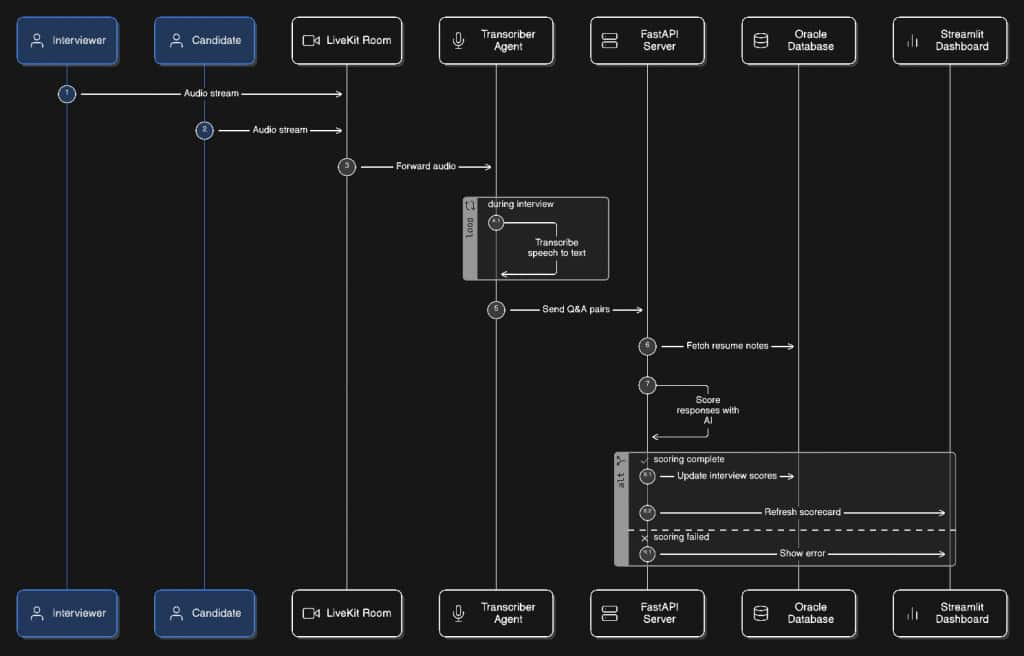
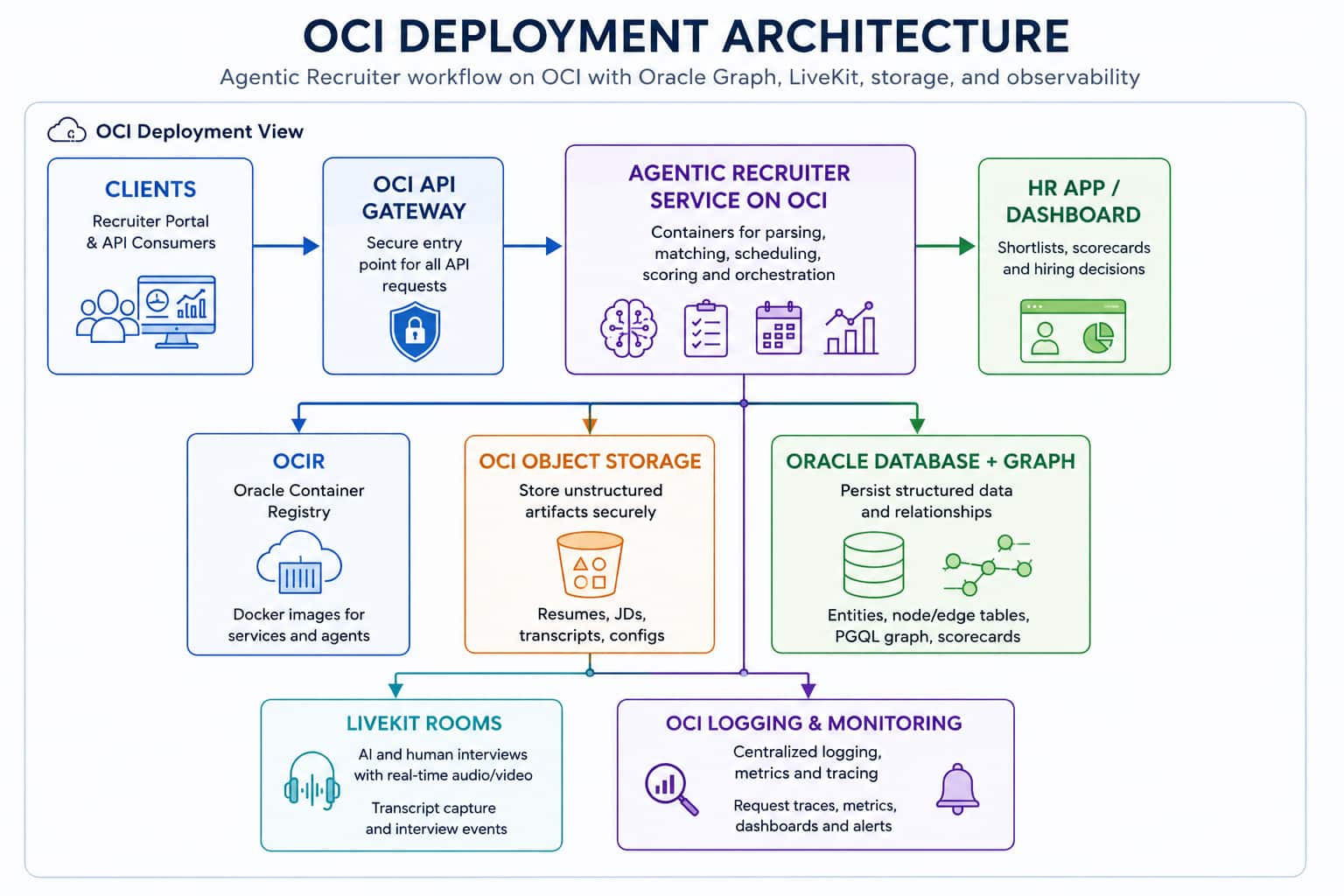
OCI Deployment Architecture
This solution can be deployed on OCI to bring the application, database, graph, AI, speech, and observability layers into a governed enterprise environment.
For scalable deployment, the app services and workers can run on OCI Compute or Oracle Kubernetes Engine. OKE is Oracle’s managed Kubernetes service for deploying containerized applications, and Oracle’s OKE guidance supports tiered network architectures with public and private subnets for APIs, worker nodes, pods, and load balancers.
OCI Generative AI supports the LLM-based parts of the workflow, while OCI Cohere embeddings are used to create semantic representations of structured candidate profiles for search and matching. The resume ingestion flow stores both structured resume JSON and profile embeddings generated from structured fields such as title, summary, skills, experience, education, projects, and certifications.
The matching layer uses Oracle Graph-style PGQL query patterns to evaluate candidate relationships against JD requirements across skills, projects, certifications, and profile evidence. This shifts screening from manual CV review and basic keyword search to structured, explainable matching.
The interview flow is automated in code end to end: candidates are moved from shortlist into the interview workflow, interview questions are generated through dedicated APIs, calendar invite files (ICS) are created and sent via email, LiveKit interview links are attached during scheduling, and transcript-backed scoring and feedback endpoints help ensure more consistent candidate evaluation.
Problems This Solves
Manual screening:
Resumes are parsed, structured, stored, and matched through graph queries instead of manually reviewed one by one.
Keyword-only matching:
Oracle Graph checks relationships across candidates, skills, projects, certifications, and JD requirements.
Scheduling delays:
The agentic scheduler moves candidates from shortlist to interview by generating records, calendar invites, and LiveKit links.
Biased or narrow interviews:
Round 2 question generation helps interviewers cover broader JD-aligned topics instead of focusing only on familiar areas.
Inconsistent interview feedback:
Both rounds generate transcript-backed scorecards, making candidate comparison easier and more defensible.
Executive-Ready Outcome
The final output is a complete hiring insight package:
Graph-based shortlist: candidates filtered through JD-driven PGQL matching.
Match explanation: evidence showing which skills, projects, certifications, and requirements support the match.
Scheduled interview: blocked time, calendar invite, and LiveKit room link sent to candidate and panel.
Round 1 scorecard: adaptive AI screening results.
Round 2 scorecard: human interview results supported by transcript evidence.
Consolidated recommendation: a recruiter-ready view that combines graph evidence, interview performance, and scorecard summaries while keeping the final decision human-led.
Conclusion
This workflow turns recruitment into a connected, explainable, and evidence-backed process.
HCM provides the source data. LLMs extract structured JD and resume entities. Oracle Database stores the candidate and role data. Oracle Graph Studio creates a PGQL graph for explainable JD-to-resume matching. The agentic scheduler moves shortlisted candidates into interviews. LiveKit powers Round 1 AI screening and Round 2 human interviews. OCI services support deployment, AI, speech, storage, security, and observability.
Together, the system creates a practical Agentic Recruiter workflow: graph-powered matching, automated scheduling, LiveKit interviews, broad question coverage, transcript-backed scoring, and human-led hiring decisions.