Chat is the most natural interface for working with large language models (LLMs). But it also exposes a common weakness: as conversations unfold across multiple turns, models can lose track of what matters, especially when requirements, constraints, and corrections arrive gradually.
That resembles how people use chat. They don’t provide a perfectly specified prompt up front. They iterate.
The multi‑turn problem (it shows up sooner than you think)
A common pattern in chat applications is to append the entire chat history to every new request. It’s straightforward and often works initially. But even in relatively short conversations, it can introduce three practical issues:
- Quality drift: Fragmented context and early ambiguity can cause the model to miss constraints, carry forward outdated assumptions, or get distracted by irrelevant dialog.
- Latency and cost growth: As prompts expand turn by turn, time‑to‑first‑token and inference cost typically rise.
- Context window pressure: Prompt length grows roughly linearly and can quickly consume the model’s input budget, eventually forcing truncation and loss of earlier context.
In other words: as the conversation gets longer (and messier), it gets more expensive and more likely to drift. [1][2][3][4]
Importantly, while some state‑of‑the‑art hosted models include built‑in conversation compaction (often tuned for very long chats approaching or exceeding the context window), that capability is typically model-specific and may apply only to a limited set of models. Many open‑weight models also do not provide this behavior out of the box. That’s why we built OCI‑STM: a short‑term memory capability designed to work consistently across the models we support through the OCI GenAI Enterprise AI Responses API.
OCI‑STM: compact memory, updated as the chat evolves
OCI‑STM (OCI Short‑Term Memory) compresses multi-turn chat history by periodically replacing older conversation turns with a compact, structured “memory state” that aims to preserve the user’s key requirements, decisions, and constraints while removing redundancy and irrelevant dialog, and we keep the most recent turns verbatim to maintain recency and fidelity.
A key design point: condensation runs asynchronously in the background. In our reference implementation, this is designed to keep memory-updates off the critical path of the user-facing response, so it typically does not add user‑perceived latency, while the main model benefits from prompts with fewer tokens. [1]
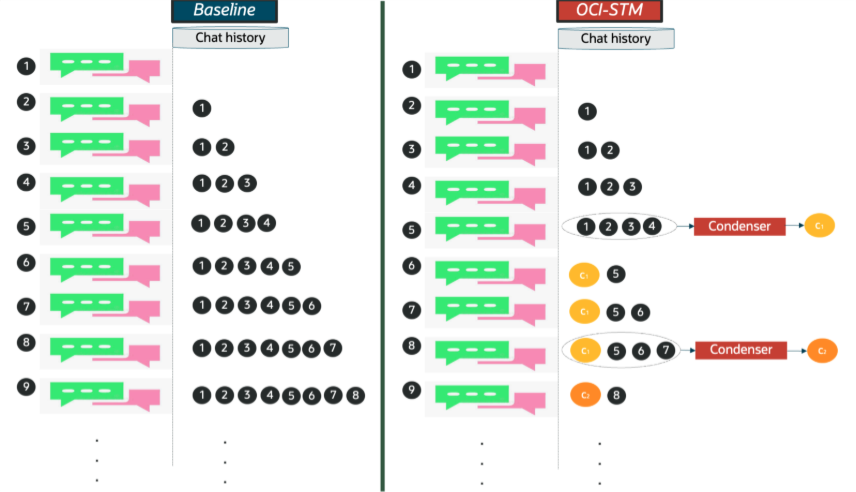
Figure 1: OCI-STM operation overview.
In our evaluations, OCI‑STM:
- produces fewer tokens per turn, with larger benefits as conversations grow. (Figure 2)
- can lead to net token savings over the lifetime of a conversation, even after accounting for the background condensation work. (Figure 3)
- is model-agnostic and works with all models across model families supported by Oracle Cloud.
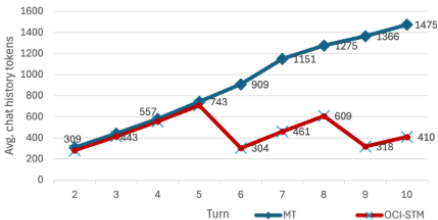
Figure 2: Chat-history token reduction in the main user chat prompt
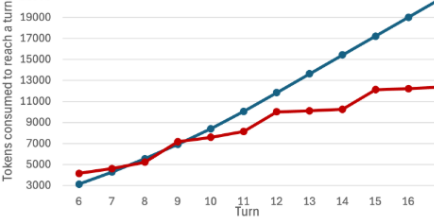
Figure 2: Chat-history token reduction in total token consumption to reach a turn (main chat + background OCI-STM processes token consumption)
We also observe that response quality is maintained, and in some cases improves, relative to sending the full raw transcript in each turn in multi‑turn scenarios. (see Figure 3)
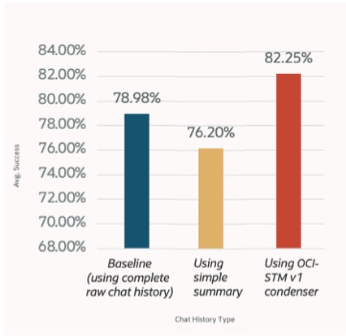
Figure 3: Task success accuracy sending raw turns, using summarization with our one-off-sequential implementation, versus using our OCI-STM condenser.
We validate across broad domain and dataset coverage by using multi-turn benchmarks spanning math, code, text-to-SQL, and tool/function-calling, plus robustness variants that inject realistic conversational noise and distractors. The core suite includes sharded versions of standard datasets—GSM8K (incremental multi-step math constraints), HumanEval (requirements revealed over turns), Spider (schema/constraint clarification over turns), and BFCL (multi-turn tool-use specification)—alongside episodic multi-turn categories (recollection, refinement, expansion, follow-up) to test memory and iterative instruction adherence. For evaluation method coverage, we measure both token efficiency and task quality in multi-turn settings, reporting dataset-appropriate metrics such as accuracy/exact match for math/code/SQL/tool calls, BLEU or task-specific structured-generation scores, and LLM-judge/rubric-based ratings for open-ended refinement and follow-up when automated metrics are insufficient. [3]
How it differs from “just summarization”
Generic summarization may drop key instructions or constraints. Our approach aims to maintain a structured “memory state” that is updated over time, with emphasis on identifying and retaining key user instructions, constraints, and decisions, while condensing supporting or repetitive context. Recent turns remain verbatim, and older turns are compacted repeatedly into this memory to help the model can stay consistent without carrying the full transcript every turn.
How is it different from “RAG”
Retrieval (for example, storing chat history in a memory store and fetching relevant snippets with RAG) can help control prompt length, but it typically adds runtime moving parts (embedding/indexing, query formulation, retrieval calls, and re-ranking) which can introduce additional latency and operational complexity. It can also miss important multi‑turn dependencies when the “right” context is distributed across several turns or depends on conversational ordering. OCI‑STM takes a complementary approach by maintaining an updated, compact conversation state directly.
Multi‑turn chat is quickly becoming a default interface for working with AI. OCI‑STM is designed to help multi‑turn experiences scale more smoothly by keeping conversations more on‑track and efficient as they grow, while aiming to preserve the key context the model needs across turns.
——–
Get started today to try out this feature and more.
- Learn more about OCI Enterprise AI
- Learn more about OCI Generatie AI
——–
[1] Singh, Jyotika, et al. ‘MT-OSC: Path for LLMs That Get Lost in Multi-Turn Conversation’. arXiv [Cs.CL], 2026, https://doi.org/10.48550/ARXIV.2604.08782.
[2] Levy, Mosh, et al. ‘Same Task, More Tokens: The Impact of Input Length on the Reasoning Performance of Large Language Models’. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Association for Computational Linguistics, 2024, pp. 15339–15353, https://doi.org/10.18653/v1/2024.acl-long.818.
[3] Laban, Philippe, et al. ‘LLMs Get Lost In Multi-Turn Conversation’. arXiv [Cs.CL], 9 May 2025, https://doi.org/10.48550/arXiv.2505.06120. arXiv.
[4] Liu, Nelson F., et al. ‘Lost in the Middle: How Language Models Use Long Contexts’. Transactions of the Association for Computational Linguistics, vol. 12, MIT Press, Feb. 2024, pp. 157–173, https://doi.org/10.1162/tacl_a_00638.





