To help ensure that AI agents deliver effective support, it’s essential to have a data-driven understanding of how they are being used and how they are performing. Knowing the types of questions that users are asking agents, and whether these questions are answered satisfactorily, is crucial to understanding trends and enabling improvements, such as enhancing support documents that the agents depend on.
Customer Success Services has developed a proof-of-concept solution in Oracle AI Data Platform to (1) generate a word cloud of common topics from a set of user questions, (2) apply an LLM-as-a-Judge approach to see how well these questions were answered by the agents, and (3) track the daily token consumption for cost management purposes. Around 400 questions submitted to traditional RAG agents in a Fusion demo environment were analysed, as well as ~2,200 questions submitted to workflow agents built in AI Agent Studio.
Topic Cloud
Questions that users posed to agents in the Fusion environment were temporarily stored in two tables called FAI_GENAI_REQUESTS (for traditional RAG agents) and FAI_WORKFLOW_EXECUTIONS (for workflow agents), accessible via BI Publisher. Our solution necessitated the use of a pre-trained LLM to consistently categorise these questions. Therefore, we decided to develop our solution within Oracle AI Data Platform (AIDP) which has a key advantage of bringing a wide range of AI models much closer to business data, within a single unified environment.
The data was exported from BI Publisher in XLSX format, and AIDP’s drag-and-drop interface made it easy to import this XLSX file into Object Storage. From there, an ingestion pipeline cleaned and loaded this data into an Autonomous Data Warehouse (ADW). As shown in the screenshot below, this ingestion step can be scheduled to run automatically in AIDP, making it straight-forward for additional question data to be added in the future.
AIDP’s Master Catalogue automatically lists all ADW connections and tables, simplifying access to, and interrogation of, the agentic AI data. We also leveraged AIDP Workspaces to establish a restricted environment for secure analysis, configured with role-based access controls. Our solution was developed in a Python Notebook that could connect to the ADW and run queries on the data via PySpark. A pre-trained LLM was applied specifically to the user_query column of the database table with just a few lines of Python code to categorise each question into the most accurate topic. To promote consistency, we fed the LLM a prompt including any pre-existing topics, encouraging reuse over creating similar new ones, as shown in the code snippet below.
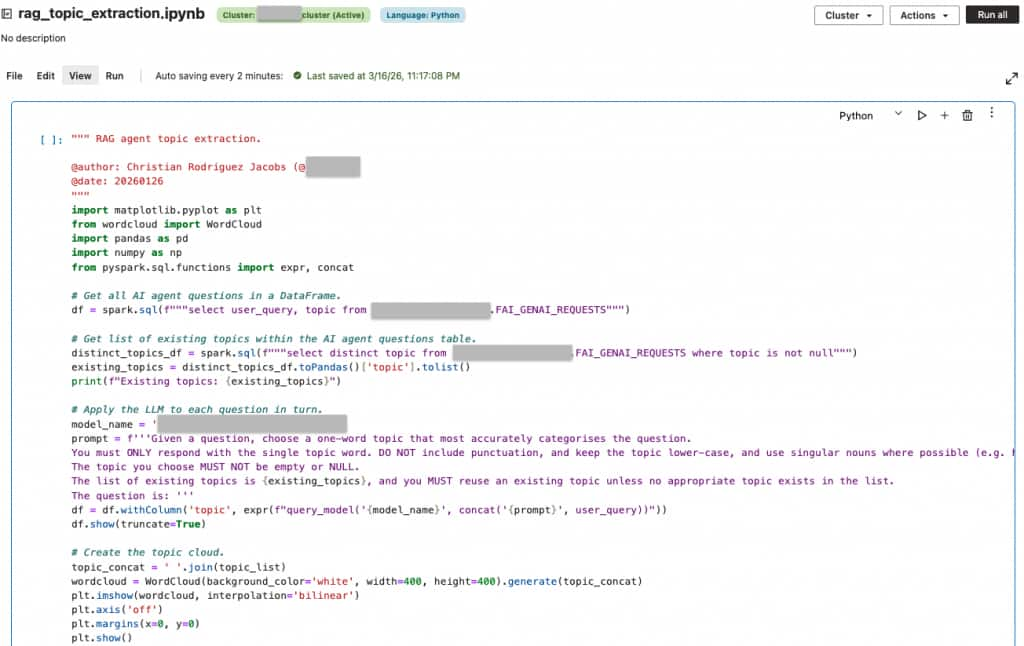
The topic cloud shown below highlights the most prominent topics extracted from the ~400 questions posed to RAG agents. We can see that the most prominent topics concern HR-related enquiries about holiday and employment, with occasional ERP-related enquiries about procurement, laptops, etc. Once in production, this visualization could become a powerful tool for stakeholders to drive data-informed decisions and trend analysis.

LLM-as-a-Judge for Quality Assurance
A second call to the pre-trained LLM independently reviews each AI response to confirm it actually answers the user’s query. This data is available in the agent_response column of FAI_GENAI_REQUESTS, accompanying the user_query column (and similarly in the execution_details column of FAI_WORKFLOW_EXECUTIONS). Building on the categorisation process, this LLM-as-a-Judge layer evaluates the quality and relevance of agent responses to assess whether they align with user intent. Currently this is a simple ‘answered/unanswered’ judgement as shown by the answered column in the tabular output below, but a more refined approach might use a range of numerical values.

Notice that we pair the LLM’s judgment with the number of source citations. Unsurprisingly, we found that questions that were not answered successfully were often not accompanied by any source references, such that the agent had nothing to base its answer on. For example, one user asked “What is Carli’s employee number?”, but the agent responded by saying it was not able to find any reference in which to look up employee numbers, thereby highlighting a gap in knowledge resources. Flagging such unanswered questions automatically might be a useful QA step to help address hallucinations or fill gaps in reference documentation to help agents successfully address a wider range of user queries.
Token Consumption Tracking
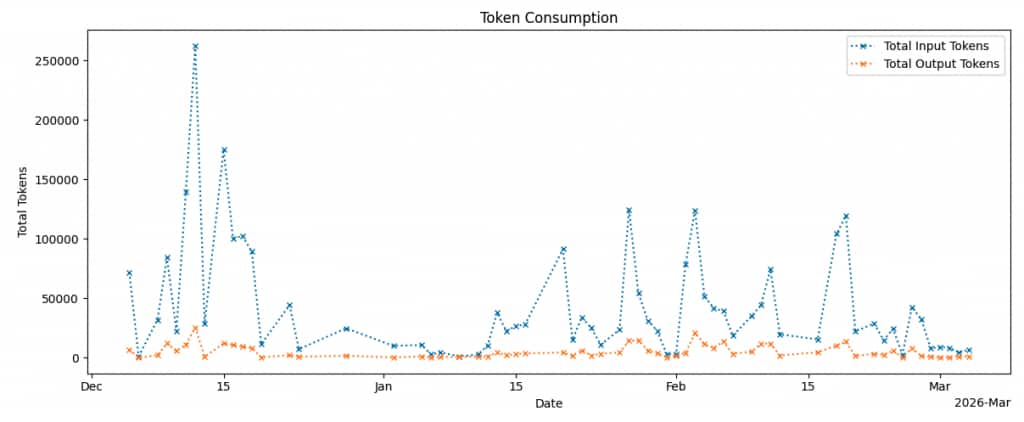
Monitoring LLM token consumption is crucial, particularly for cost management. Workflow agents in AI Agent Studio perform multi-step reasoning, with the input and output token counts being recorded in the FAI_WORKFLOW_EXECUTIONS table (specifically the LLM_REQ_INPUT_TOKEN_CNT and LLM_OUTPUT_TOKEN_CNT columns). The graph below shows the total input and output tokens consumed per day across these reasoning steps. Input token counts were typically higher than the output, likely due to the agent ingesting documents such as resumes and policy documents to summarise.
While this analysis was performed and reviewed manually in AIDP, the same data could be integrated into a reporting and alerting pipeline to notify users of unusually high token usage or when consumption is approaching a quota.
Conclusion
By leveraging Oracle AI Data Platform’s ability to bring AI models much closer to business data, we have been able to create a proof-of-concept analytics solution to extract common topics from agentic AI queries and visualise them in a compelling way. We have also been able to use AI to evaluate its own answers, thereby highlighting potential areas for improvement such as updating support documentation to expend the knowledge base the agent has access to.
Over the past few years, businesses have rapidly adopted AI solutions to stay competitive. As organisations strive to maintain momentum, it’s becoming increasingly vital to demonstrate that AI is not only functioning as intended but also delivering tangible value to users. Proof-of-concept solutions like this provide the visibility and insights needed to ensure AI agents are aligned with user needs, driving trust, and maximising ROI.
Acknowledgements
Many thanks to my colleagues Wendy Huai, Lee Sacco, Wojciech Burzynski, Magdalena Pietrzak, Ravi Panga, Siva Pratap Nellipudi and Sunilkumar Kheni for their support and useful discussions.
