Introduction

This blog is about comparing the performance of compiled languages using two simple micro benchmarks.
I am writing a series of blogs on using different languages to access Oracle databases [eg Python, Node.js, Rust and Julia]. Eventully, I want to compare the performance of these various languages accessing Oracle. I have already compared some popular language executables, language runtimes and Java for the same micro benchmarks.
The compiled languages covered in this blog are:
- Zig 0.10 and 0.11-dev
- Swift 5.7.1
- C# .NET SDK 6.0 and SDK 7.0.100 using JIT and native compilation
- Kotlin 1.7.21 and Kotlin-native 1.7.21
This blog covers the following topics:
- An overview of the compiled languages
- The two micro benchmarks that I created
- The results
- My source code for all of those languages
- How I did the builds and tests
- How I calculated the results
- Summary
This blog is not a tutorial on these computer languages. This is also not a blog on how to download and configure the language tool-chains.
Overview of these compiled languages

The following is my opinion, so act accordingly 😉
- C# [2000] was created by Microsoft, originally to compete with Java on Windows
- C# is a general purpose object oriented language that now runs on Linux, MacOS and Windows
- C# has seen widespread use in many aspects of computing
- C# uses garbage collection
- C# uses JIT compilation with the .NET runtime by default
- C# can also use AOT compilation via LLVM
- Kotlin [2011] was created by JetBrains as a better Java [and to increase sales of IntelliJ IDEA]
- Kotlin is a general purpose statically typed language that uses JIT compilation on the JVM
- Kotlin has good interoperability with Java and you can easily call Java classes from Kotlin
- Kotlin can also generation JavaScript source code or native code via LLVM
- Kotlin can be used to create mobile applications for iOS and Android, or applications for Windows, macOS, Linux, and WASM
- Kotlin uses the JVM garbage collector
- Swift [2014] was designed by Apple as a replacement language for Objective-C with tight integration for the Cocoa and Cocoa Touch frameworks
- Zig [2016] was designed to improve upon the C language as a portable mechanism for making applications, libraries and languages
- Zig is a general purpose language that uses LLVM and can also act as a compiler for C and C++ code
- Zig is a new language with a promising future
- Zig has great interoperability with C
- Zig was used to create the Bun JavaScript / TypeScript runtime
- Zig makes the standard library optional
- Zig uses manual memory management
These languages were all designed with different goals and hence they all have different strength and weaknesses.

Trying to determine which is the ‘best language’ is pointless. Your projects, existing source code, experience, tool-chains and biases will determine which language you use.
My micro benchmarks
I am not trying to state that one language compiler is better than another. There are many factors that influence which compiler that you choose to use and performance is only one of them.

I needed some trivial workloads, so I chose to use the same micro benchmarks that I used for my blog on executable and Runtime Performance:
- Calculate the Fibonacci sequence with an input of 1475, call this function one million times
- Some trivial string processing with strings. ie creating, concatenating and using substrings for strings under 2000 characters with a huge number of iterations
How valid are these results
Micro benchmarks are, by definition, only relevant to the specific workload that they cover. These workloads do not try to cover everything, they only cover what I care about. The only workload that matters to you is your workload. So compare your own workloads with your favourite languages. I have found that string processing and simple maths are important to enable fast SQL database drivers, so that is what I tested.

Results
Micro benchmarks with compiler executables [smaller is better]
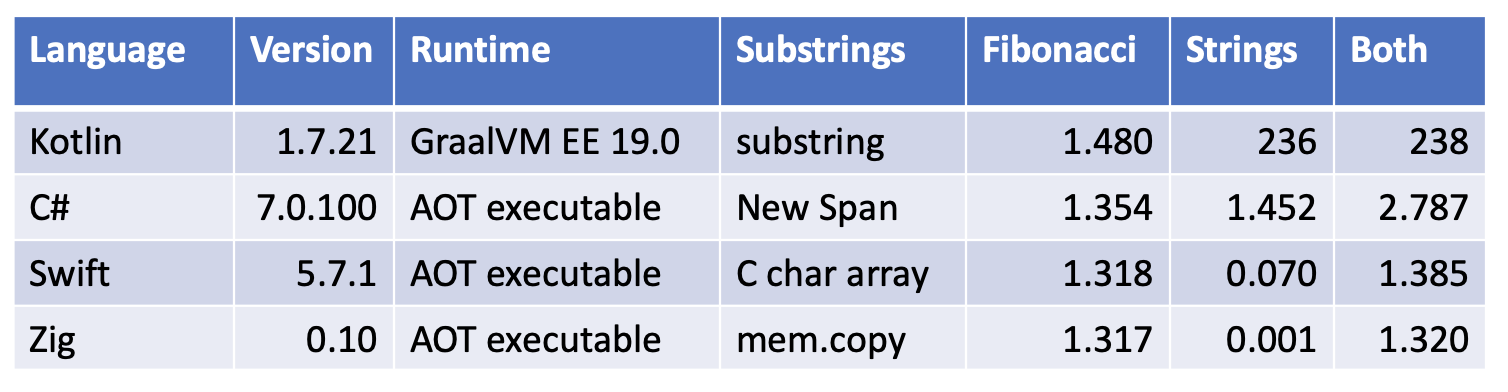
This chart shows the total execution time of my micro benchmarks for simple math and string processing:
- Zig was faster than C, C++ and Rust for the String processing
- Swift character arrays were considerably faster than using String.substring
- Swift has rich support for Strings, but made substring processing complicated via the need for index ranges rather than scalar indexes
- Surprisingly, C# Spans of Character Arrays allocated in the loops were the fastest mechanism
- Theoritically, ReadOnlySpan<char>, or String.AsSpan should have been the faster, but were not in practice
- Kotlin using JIT compilation with GraalVM Enterprise Edition was significantly faster than Kotlin-native
- Both the Kotlin JIT and native workloads seemed to be stressing garbage collection in the string processing
Top Results [smaller is better]
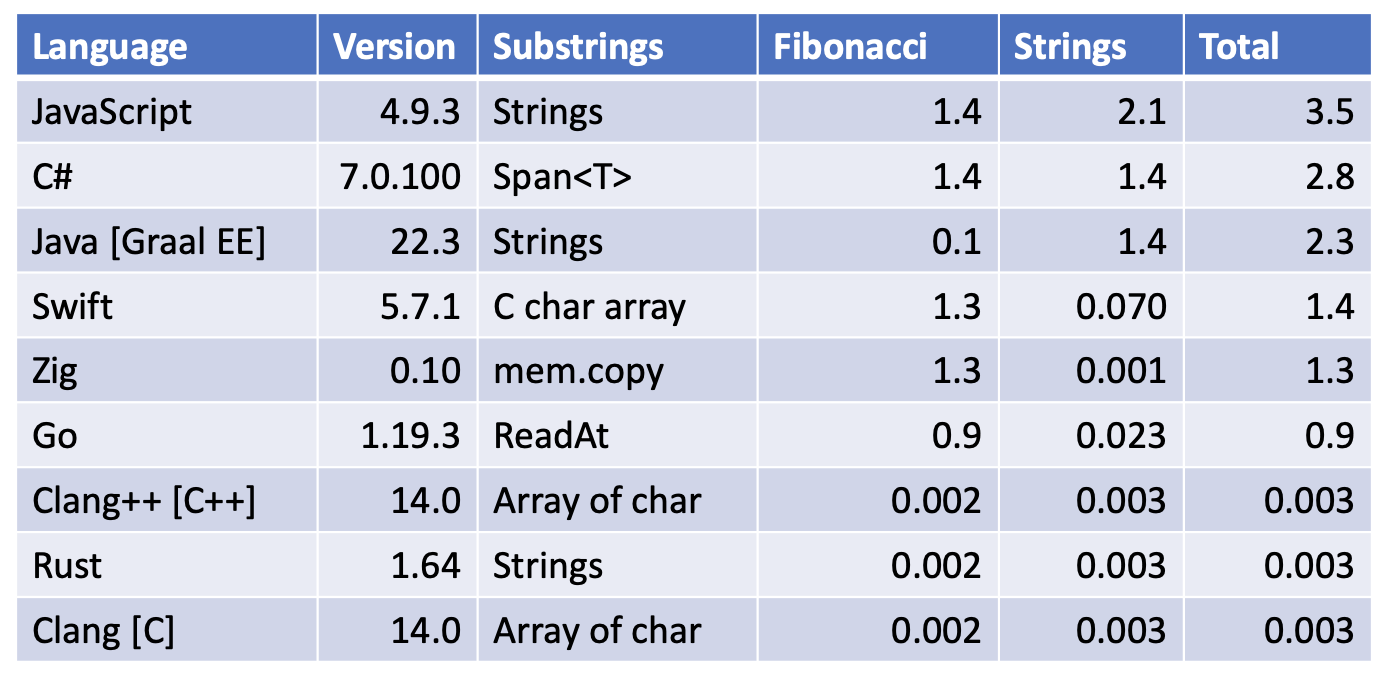
- Zig was very fast at string processing, but ‘slow’ at calling a function Fibonacci(1475) a million times
- Swift was slightly slower than Zig for both strings processing and processing the Fibonacci sequence
- The typed Kotlin compiler was considerably slower than JavaScript [which is a dynamic language] for these micro benchmarks
- 5 of the top 6 languages used LLVM
- But LLVM is not magic, a lot of effort needs to go into the development and maintenace of the compiler optimizations
- Not all languages exposed some Clang/LLVM optimizations such as -Oz
All Results [best per language]
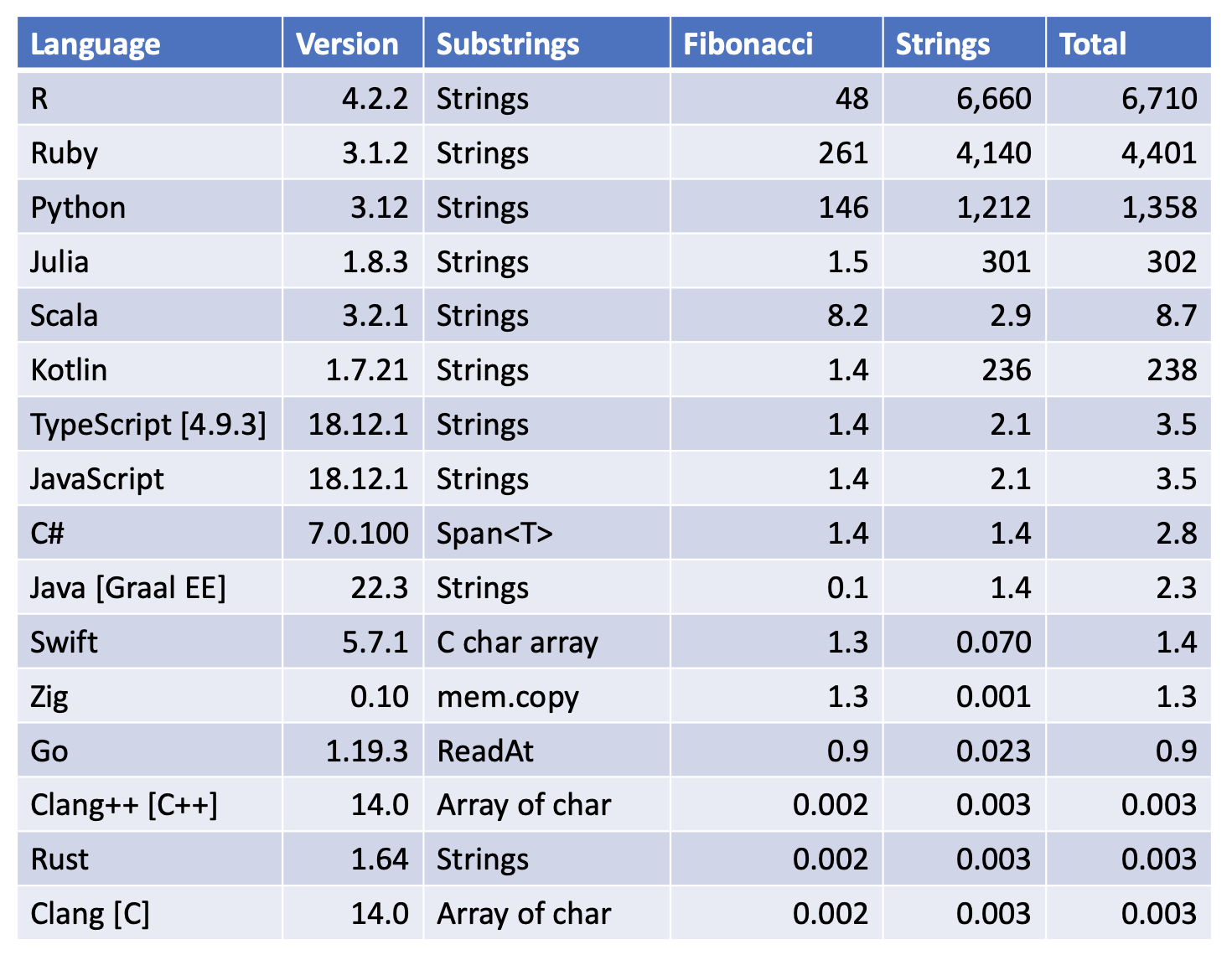
- Kotlin used the same JVM [GraalVM Enterprise Edition 22.3 ] as Java, but was significantly slower
- Kotlin using GraalVM Enterprise Edtion 22.3 was significantly faster than using OpenJDK 19.0 which took 575 seconds
- Kotlin JIT compilation was significantly faster than using native compliation which took 3,434 seconds
- Kotlin String.substring was significantly faster than using CharArray slice or sliceArray
- Maybe I was using some Kotlin ‘go slow’ configuration, but I could not figure it out why it was so slow compared to Java
- C# 7.0.100 AOT compilation was only slightly faster than C# 6.0.403 JIT compilation
- Zig gave the same performance as Clang -O3 for Fibonacci
- Clang, Clang++ and Rust all benefited from the -Oz optimization
- I was not able to benefit from the -Oz optimization in Swift, Zig or C#
- Zig 0.11-dev was no faster than Zig 0.10
Making substrings faster

- My micro benchmarks stress simple math and string handling
- The bottleneck in all of the languages was getting a substring in a loop
- This occurs in the j and k FOR loops in function long_strings
- I want to do a logical substring in these loops
- Is there a faster way of doing this in your favorite language?
- Please add you code solution to the comments section
- You want to avoid allocating objects in a loop as it is logically a slow operation
- I started with the substring methods in each language and then optimized my code where possible
- This pathelogical example is hard for any language
- Zig used memory copies and did the benchmark in 1 millisecond
- Rust used substrings and did the benchmark in 3 milliseconds
- Java used substrings and did the benchmark in 1.4 seconds
- C# used Span<Char> and did the benchmark in 1.4 seconds
- Kotlin used substrings and did the benchmark in 236 seconds
My trivial source code

The Swift Main Function

- The fibonacci function has an input of 1475 and was called one million times
- Why 1475, to avoid numeric overflow in some of the other languages that I tested this workload against
- I am using the type double [or equivalent] for all languages to avoid numeric overflow for the large numbers from the Fibonacci sequence
- Both the cstrings and long_cstrings methods are called with an input of 1475
- The strings and long_strings functions were significantly slower, so were commented out to minimize the runtime memory image and be consistent with the other language implementations
The Swift Fibonacci Function

Why am I using a double for the variables?
- The values of the Fibonacci sequence rapidly get larger
- I also implemented these micro benchmarks in many other languages
- Some of these languages had issues with integer overflow for large values in the Fibonacci sequence
- So I used the type double to be fair and consistent across all of the languages
I am not using recursion as it is against my religion.
My Swift Strings Function

- This function does some trivial operations on strings
- The operations include constructors, append, length, substring and copy
- There are three nested loops, so the operations in the inner-most loop are executed about 26 million times
- n = 1475
- The string length is 12 characters
- 1475 * 12 * 1475 = 26,107,500
- Using C arrays of chars was significantly faster than using substrings or slices
The Swift long_strings Function – Part 1
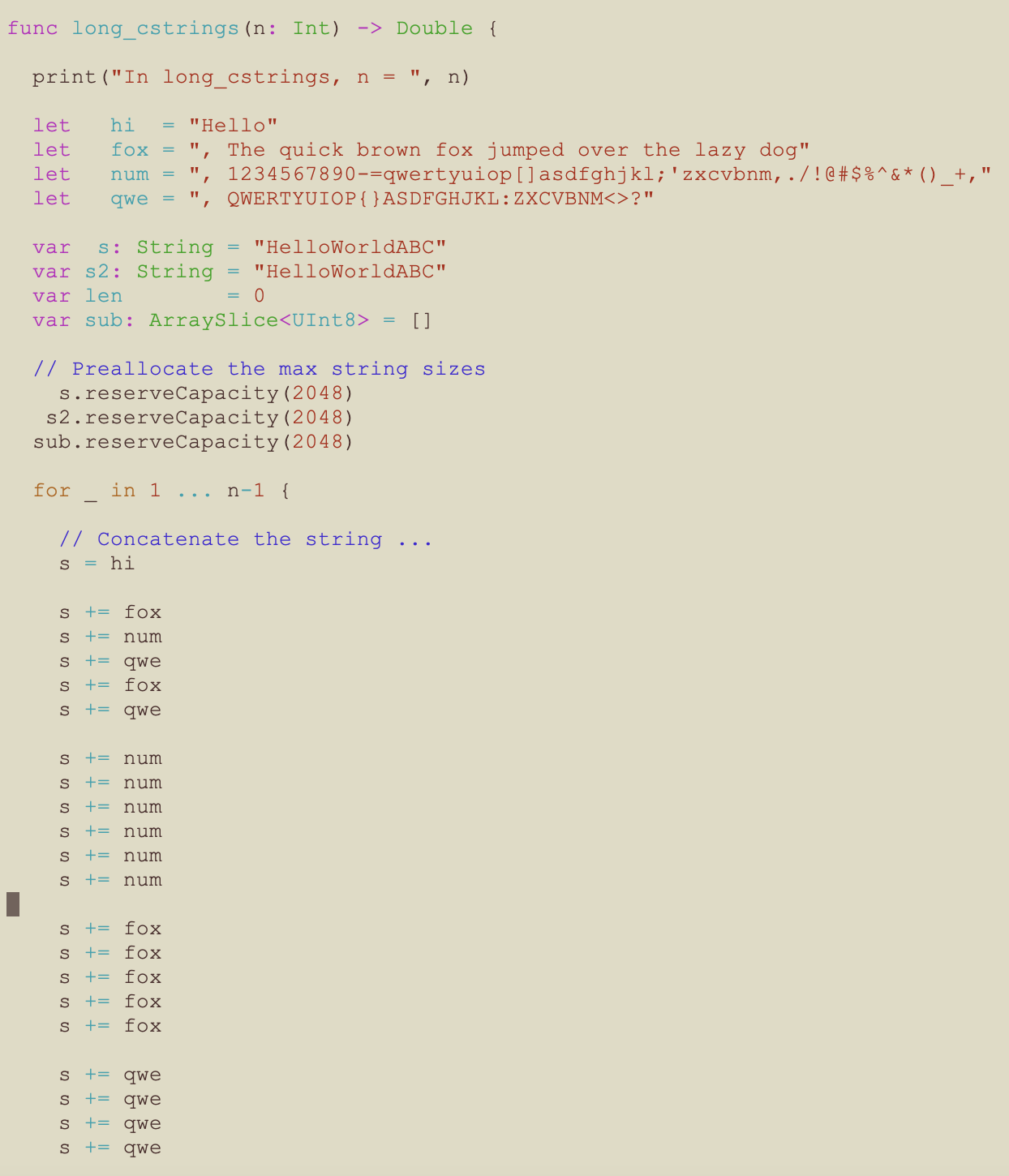
The logic for function long_strings was the same as for function strings, but there were significantly more string concatenation operations.
- The fully appended string is 1965 bytes long
- The number of iterations of the string and operations is significantly larger
- The strings are preallocated to max size to avoid dynamic growth
The Swift long_strings Function – Part 2
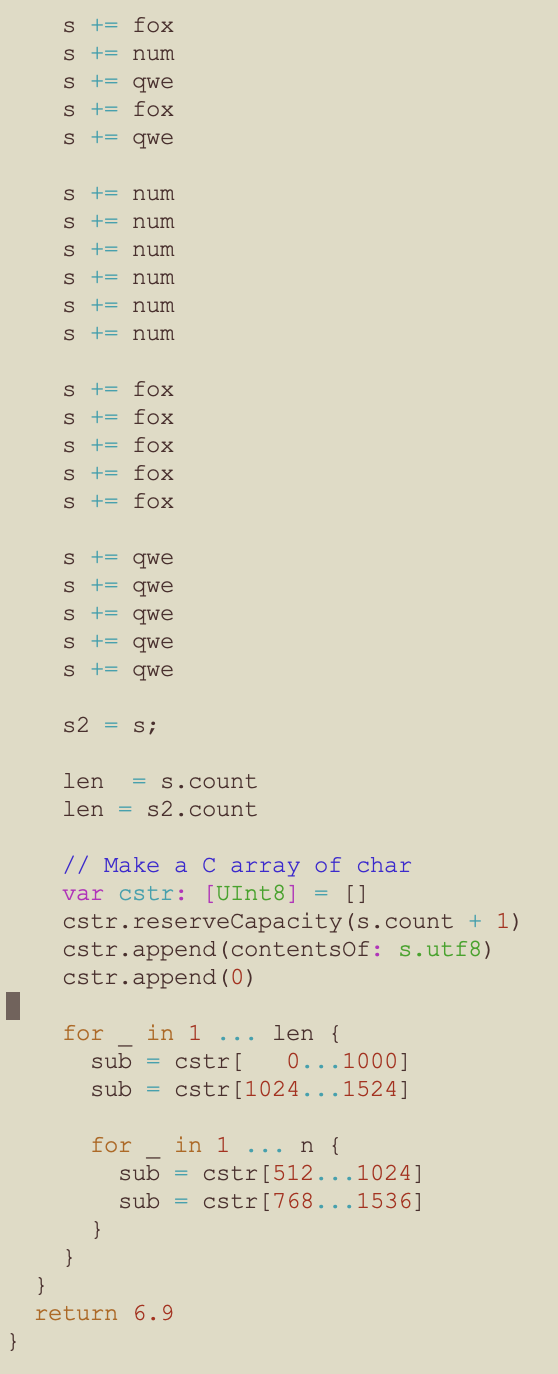
- The ‘j’ for loop iterates based on the length of the string, ie 1965 times
- The ‘k’ for loop iterates n times, ie 1475
- The outer ‘i’ for loop also iterates n times, ie 1475
- 1475 * 1965 * 1475 = 4,275,103,125 iterations
- So there are 4.2 billion iterations of the ‘k’ loop which creates strings from substrings
- Using C arrays of chars was significantly faster than using substrings or slices

The Kotlin Main Function
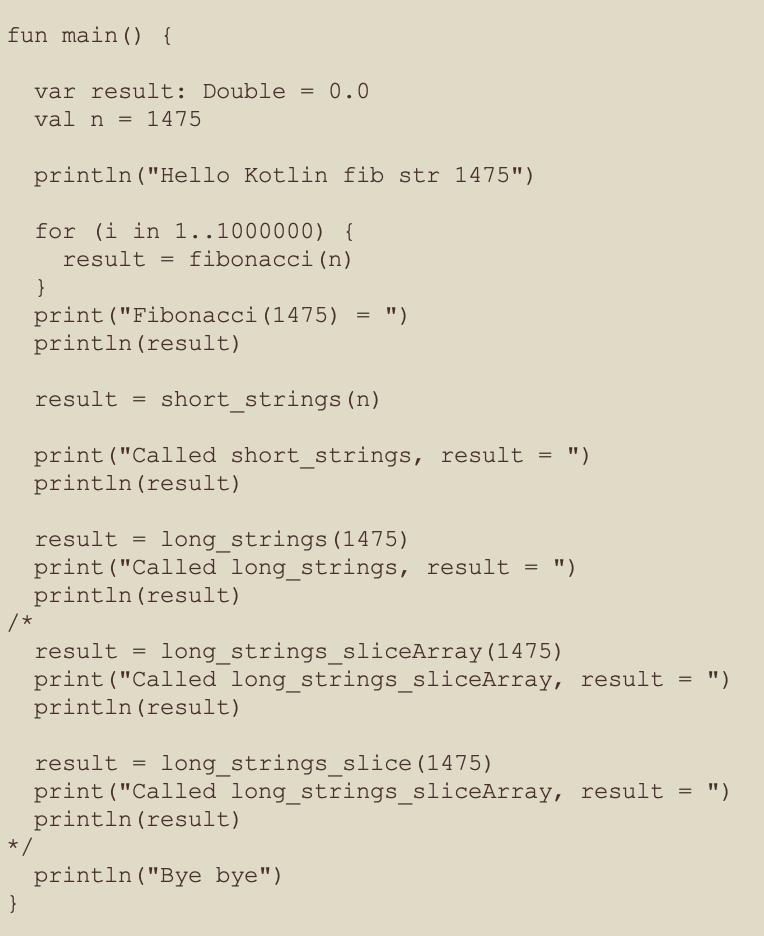
- The fibonacci function has an input of 1475 and was called one million times
- Why 1475, to avoid numeric overflow in some of the other languages that I tested this workload against
- I am using the type double [or equivalent] for all languages to avoid numeric overflow for the large numbers from the Fibonacci sequence
- Both the strings and long_strings methods are called with an input of 1475
- The both long_strings_sliceArray and long_strings_slice functions were significantly slower than the long_strings function, so were commented out
The Kotlin Fibonacci Function

Why am I using a double for the variables?
- The values of the Fibonacci sequence rapidly get larger
- I also implemented these micro benchmarks in many other languages
- Some of these languages had issues with integer overflow for large values in the Fibonacci sequence
- So I used the type double to be fair and consistent across all of the languages
I am not using recursion as it is against my religion.
My Kotlin Strings Function

- This function does some trivial operations on strings
- The operations include constructors, append, length, substring and copy
- There are three nested loops, so the operations in the inner-most loop are executed about 26 million times
- n = 1475
- The string length is 12 characters
- 1475 * 12 * 1475 = 26,107,500
- Suprisingly, the String.substring method was significantly faster than using slices or ArraySlices
- The println statement was to avoid a compiler warning
- This println did not affect the performance as it is only called once
The Kotlin long_strings Function – Part 1

The logic for function long_strings was the same as for function strings, but there were significantly more string concatenation operations.
- The fully appended string is 1965 bytes long
- The number of iterations of the string and operations is significantly larger
- Using StringBuilder was faster than using string for the concatenation operations
- The strings are preallocated to max size to avoid dynamic growth
- The StringBuilder is pre-allocate to avoid dynamic growth
The Kotlin long_strings Function – Part 2

- The ‘j’ for loop iterates based on the length of the string, ie 1965 times
- The ‘k’ for loop iterates n times, ie 1475
- The outer ‘i’ for loop also iterates n times, ie 1475
- 1475 * 1965 * 1475 = 4,275,103,125 iterations
- So there are 4.2 billion iterations of the ‘k’ loop which creates strings from substrings
- Suprisingly, the String.substring method was significantly faster than using slices or ArraySlices

The C# Main Function

- The fibonacci function has an input of 1475 and was called one million times
- Why 1475, to avoid numeric overflow in some of the other languages that I tested this workload against
- I am using the type double for all languages to avoid numeric overflow for the large numbers from the Fibonacci sequence
- Both the strings and long_strings methods are called with an input of 1475
The C# Fibonacci Function

Why am I using a double for the variables?
- The values of the Fibonacci sequence rapidly get larger
- I also implemented these micro benchmarks in many other languages
- Some of these languages had issues with integer overflow for large values in the Fibonacci sequence
- So I used the type double to be fair and consistent across all of the languages
I am not using recursion as it is against my religion.
The C# Strings Function

- This function does some trivial operations on strings
- The operations include constructors, append, length, substring and copy
- There are three nested loops, so the operations in the inner-most loop are executed about 26 million times
- n = 1475
- The string length is 12 characters
- 1475 * 12 * 1475 = 26,107,500
- The C# strings substring method is really slow compared to C
- The C# Span technique method was significantly faster than using C# substrings
The C# long_strings Function – Part 1

The logic for function long_strings was the same as for function strings, but there were significantly more string concatenation operations.
- The fully appended string is 1965 bytes long
- The number of iterations of the string and operations is significantly larger
The C# long_strings Function – Part 2

- The ‘j’ for loop iterates based on the length of the string, ie 1965 times
- The ‘k’ for loop iterates n times, ie 1475
- The outer ‘i’ for loop also iterates n times, ie 1475
- 1475 * 1965 * 1475 = 4,275,103,125 iterations
- So there are 4.2 billion iterations of the ‘k’ loop which logically creates strings from substrings
- Using C# Span was significantly faster than using Substring or CopyTo for the concatenation operations

The Zig Main Function

- The fibonacci function has an input of 1475 and was called one million times
- Why 1475, to avoid numeric overflow in some of the other languages that I tested this workload against
- I am using the type f64 [double] for all languages to avoid numeric overflow for the large numbers from the Fibonacci sequence
- Both the strings and long_strings methods are called with an input of 1475
The Zig Fibonacci Function

Why am I using a f64 [double] for the variables?
- The values of the Fibonacci sequence rapidly get larger
- I also implemented these micro benchmarks in many other languages
- Some of these languages had issues with integer overflow for large values in the Fibonacci sequence
- So I used the type f64 [double] to be fair and consistent across all of the languages
I am not using recursion as it is against my religion.
The Zig Strings Function

- This function does some trivial operations on strings
- The operations include constructors, append, length, substring and copy
- There are three nested loops, so the operations in the inner-most loop are executed about 26 million times
- n = 1475
- The string length is 12 characters
- 1475 * 12 * 1475 = 26,107,500
- Zig does not have an explicit String type
- The C strncpy function is like a wrapper to C memcpy functions
- The Zig mem.copy operations needed for the logical substrings operations are equivalent to memcpy functions in C
- I assume that the C strncpy() ‘overhead’ [comapred to memcpy] is why Zig was faster than C for the string processing?
The Zig long_strings Function – Part 1
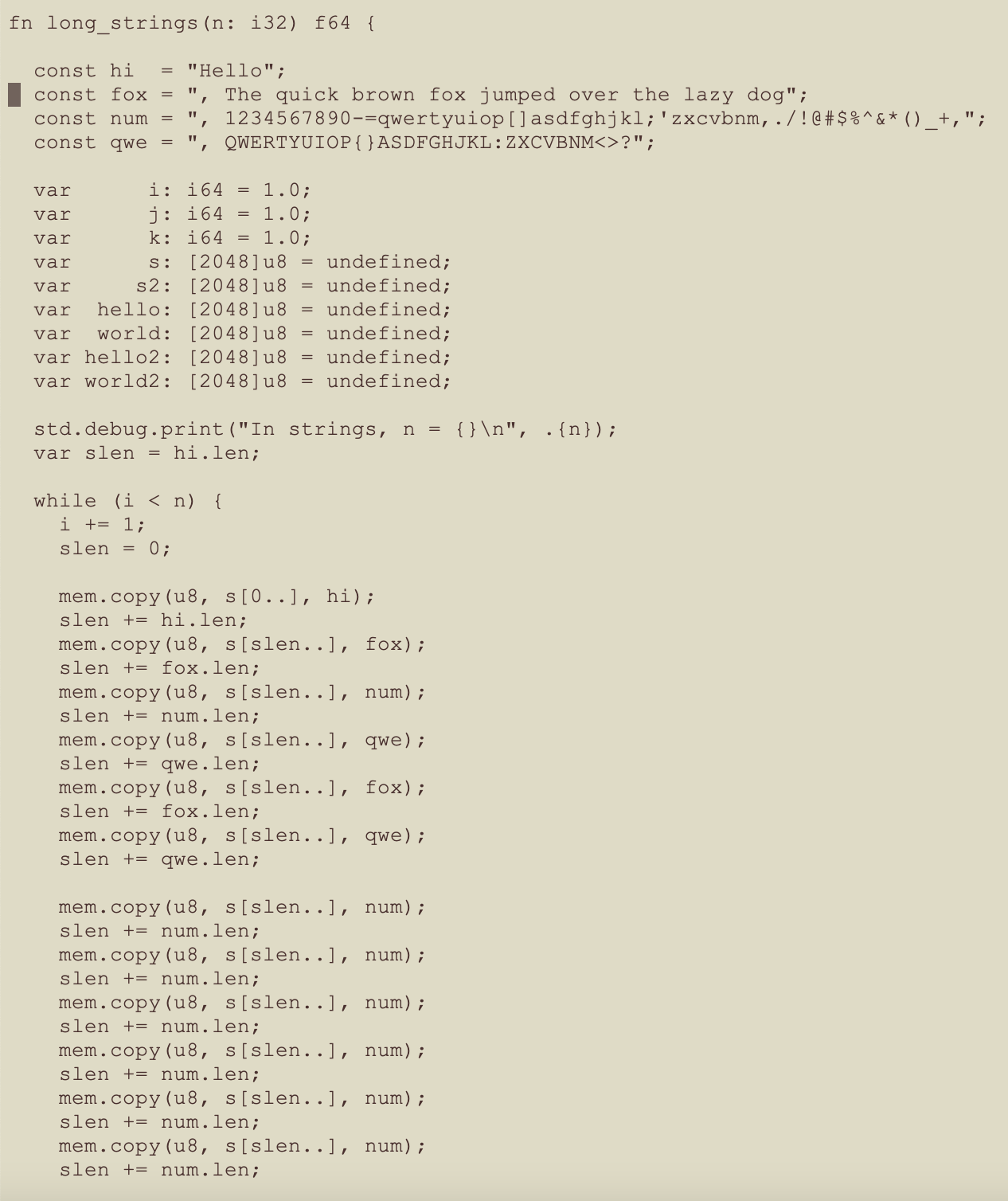
The logic for function long_strings was the same as for function strings, but there were significantly more string concatenation operations.
- The fully appended string is 1965 bytes long
- The number of iterations of the string and operations is significantly larger
The Zig long_strings Function – Part 2

- The ‘j’ for loop iterates based on the length of the string, ie 1965 times
- The ‘k’ for loop iterates n times, ie 1475
- The outer ‘i’ for loop also iterates n times, ie 1475
- 1475 * 1965 * 1475 = 4,275,103,125 iterations
- So there are 4.2 billion iterations of the ‘k’ loop which logically creates strings from substrings
- The Zig mem.copy function does the equivalent of a substring [strncpy] operation
- There are two screen shots of mem.copy operations missing
- All of the mem.copy operations needed to create the string ‘s’ to the length of 1964 characters were used in the micro benchmarks
My environment
I repeated these tested on two different machines:
- Oracle Linux 8.6 on Oracle Cloud. 4 OCPU with 128 GB RAM
- Ubuntu 22.04 on Oracle Cloud. 4 OCPU with 128 GB RAM
- As these were VMs, to avoid the risk of a noisy neighbor, I repeated the tests many times over three days
- My micro benchmarks were not doing any disk nor network IO. Instead they were CPU bound for a single threaded workload.
- As measured by ‘top‘, the VIRT and RSS memory was stable for the duration of the tests and there was 128 GB of RAM
How I built and ran each test
For Zig
- zig build-exe src/main.zig -O ReleaseFast
- time ./main
For Swift
- swift build -c release
- time ./.build/x86_64-unknown-linux-gnu/release/fib
For C#
- dotnet publish –configuration Release –runtime linux-x64
- time bin/Release/net7.0/linux-x64/native/fibStrCS
For Kotlin
- kotlinc fib.kt
- time kotlin FibKt.class
How I calculated the results
On three different days, I did the following:
- Run the tests for each runtime 10 times using the Linux time command until I got stable results
- I eliminated the highest and lowest results
- I took the average of the remaining eight results
- The Linux time command gives a resolution of 1 millisecond
- The fastest test took 1 millisecond
- This meant that the cost of starting and stopping the Zig process was a significant factor in the measurement
- I did not care exactly how fast the Zig function was as it was faster than C, C++ and Rust
- ie using gettimeofday was overkill
- I cared more about why my Kotlin and C# code were so much slower
- There was always some variation between the runs, however the relative performance was always the same
Summary
- Based on my micro benchmarks, Zig, Swift and C# all gave acceptable performance [but I was hoping for faster results]
- I do not know why Kotlin was so slow
- I hope that the language and compiler experts for these languages can share their optimizations for these micro benchmarks
Disclaimer: These are my personal thoughts and do not represent Oracle’s official viewpoint in any way, shape, or form.
