Introduction
Your choice of database character set is important for several reasons:
- Changing the Oracle database character set usually requires creating a new database and the data conversion can be non trivial
- Runtime translation of character set data can be expensive and data loss could occur given bad choices
- Due to company mergers and the rise of popular web based systems, the need for international, multilingual databases has increased

If you have the choice, always use the Unicode character set AL32UTF8 and avoid UTF8:
- Oracle UTF8 does not fully implement Unicode UTF-8 and is not recommended for new databases
- Oracle AL32UTF8 fully implements Unicode UTF-8
- Oracle AL32UTF8 is a superset of Oracle UTF8
- AL32UTF8 has the best feature support for the Oracle database
The Oracle Database supports multilingual appliations with country specific languages, dates, times, money, number and calendar conventions. This is achieved via Oracle Database Globalization support using the Oracle NLS [National Language Support] runtime library [NLSRTL].
The origins of the many different character sets that the Oracle database supports are complex. Older computer hardware, operating systems and versions of the Oracle database used to constrain the choices for database charcacter set. Since Oracle 7, your choices for the database charcter set have increased. Since Oracle 12.2, the default and recommened database character set has been AL32UTF8.
This blog looks at the past and present of character sets, Unicode, universal character sets and your choices for the Oracle database character set.
Some character encoding pre-history
Historically computers had very limited language support. EBCDIC [Extended Binary Coded Decimal Interhange Code] has been used on IBM 360 mainframes since 1963 and the ASCII [American Standard Code for Information Interchange] standard was first published in 1963.
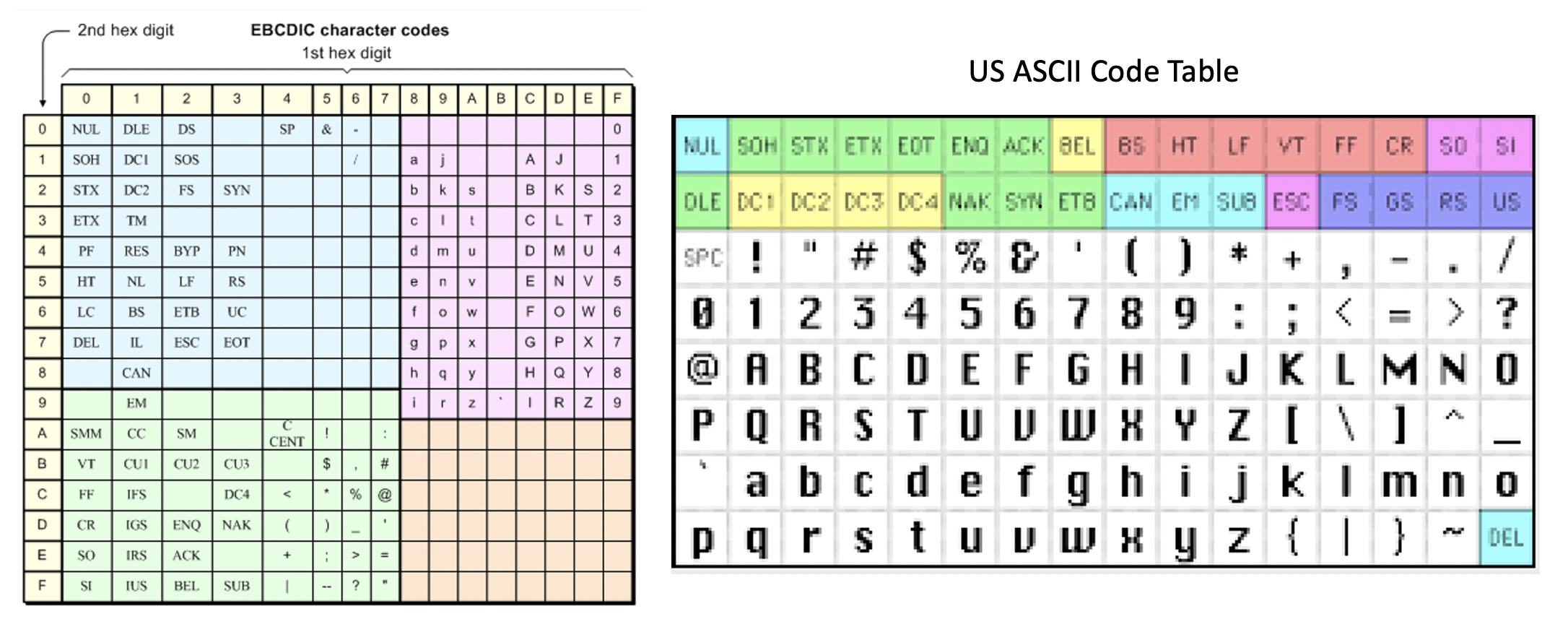
These character encodings were both created in the USA and were based on the English alphabet. From the 1950s to mid 1970s, puch cards were mainly used as inputs to [mainframe] computers. The ability to cram alpha-numeric encondings into 6 and eventually 8 bits was critical as those computers had such limited main memory.
While EBCDIC and ASCII are still supported today, they are not very useful for most of the world’s top 20 languages:
| Language | Speakers | Characters |
|---|---|---|
| English | 1.3 billion | < 128 |
| Mandarian Chinese | 1.1 billion | Thousands |
| Hindi | 600 million | < 128 |
| Spanish | 543 million | < 128 |
| Standard Arabic | 274 million | < 128 |
| Bengali | 268 million | < 128 |
| French | 267 million | < 128 |
| Russian | 258 million | < 128 |
| Portugese | 258 million | < 128 |
| Urdu | 230 million | < 128 |
| Indonesian | 199 million | < 128 |
| Standard German | 135 million | < 128 |
| Japanese | 126 million | Thousands [Kanji] |
| Marathi | 99 million | < 128 |
| Telugu | 96 million | < 128 |
| Turkish | 88 million | < 128 |
| Tamil | 85 million | < 128 |
| Yue Chinese | 85 million | Thousands |
| Wu Chinese | 82 million | Thousands |
| Korean | 82 million | < 128 |
NRCS and dumb terminals
In 1983, to avoid the cost of creating separate [dumb] terminals for each country, Digital Equipment Corportation invented NRCS [National Replacement Character Set] for the VT-200 [green screen] terminals. NRCS enabled different 8 bit character sets to be used on the same terminal hardware. The NRCS showed that many languages can be encoded in 7 bits [128 characters] or 8 bits [256 characters]. These NCRS encoded terminals for mini-computers were popular and by 1987, over one million of these ‘dumb’ terminals had been sold.

ISO/IEC 8859
The success of NRCS on VT-200 style terminals lead to the ISO/IEC 8859 set of standards for 8 bit character encodings. These standards were desgined for character encoding, not to make the characters look pretty for typography.
| Part | Name | Description |
|---|---|---|
| Part 1 | Latin-1 Western European | Includes Danish, Dutch, Emglish, Faerorse, Finnish, French, German, Icelandic, Irish, Italian, Norwegian, Portuguese, Rhaeto-Romanic, Scottish Gaelic, Spanish |
| Part 2 | Latin-2 Central European | Includes Bosnian, Polish, Croatian, Czech, Slovak, Slovene, Serbian and Hungarian |
| Part 3 | Latin-3 South European | Includes Turkish, Maltese and Esperanto |
| Part 4 | Latin-4 North European | Includes Estonian, Latvian, Lithuanian, Greenlandic and Sami |
| Part 5 | Latin/Cryllic | Includes Belarusian, Bulgarian, Macedonian, Russian, Serbian and Ukrainian |
| Part 6 | Latin/Arabic | Includes the most common Arabic language characters |
| Part 7 | Latin/Greek | Includes modern Greek and some ancient Greek languages |
| Part 8 | Latin/Hebrew | Includes modern Hebrew |
| Part 9 | Latin Turkish | Mostly ISO/IEC 8859-1 with Turkish letters replacing the infrequently used Icelandic letters |
| Part 10 | Latin-6/Nordic | A rearrangement of Latin-4 |
| Part 11 | Latin/Thai | Includes the characters needed for the Thai languge |
| Part 12 | Latin/Devanagari | The encoding for Devanagari was abandoned in 1997 |
| Part 13 | Latin-7 Baltic-Rim | Includes some missing charcaters from Latin-4 and Latin-6 |
| Part 14 | Latin-8 | Includes the Gaelic and Breton langages |
| Part 15 | Latin-9 | A modifiction of ISO/IEC 8859 that replaces some symbols with €, Š, š, Ž, ž, Œ, œ, and Ÿ |
| Part 16 | Latin-10 | Includes Albanian, Croatian, Hungarian, Italian, Polish, Romanian, Slovene, Finnish, French, German, and Irish Gaelic |
The various ISO-IE 8859 standards meant that computers could enter, store, retrieve and display characters in many different local languages. The problem was that these standards were largely incompatable when it came to data exchange as it is hard to define the translation or mapping between these diffrent character encodings.
IBM PC with MS-DOS and code pages
IBM PC compatable computers running MS-DOS used ISO/IEC 8858 derived characters sets. The original IBM PC used Code page 437 [DOS Latin US].

These IBM PC compatable computers could also load different code pages to enable various character sets, but with limits in the color and fonts.
What was really needed was a ‘universal way to represent all character encodings’. One of the challenges was that 8 bits was not enough to represent the huge number of Japanese, Korean, Manadarin, Yue or Wu chinese characters. This means that you may need more than one byte [8 bits] to encode a character and more sophisicated hardware than dumb terminals to render these [non ASCII] characters.
The birth of Unicode
Microcomputers with ‘high resolution’ bit-mapped displays from Xerox PARC, Apple and Microsoft enabled the display or rendering of complex characters.
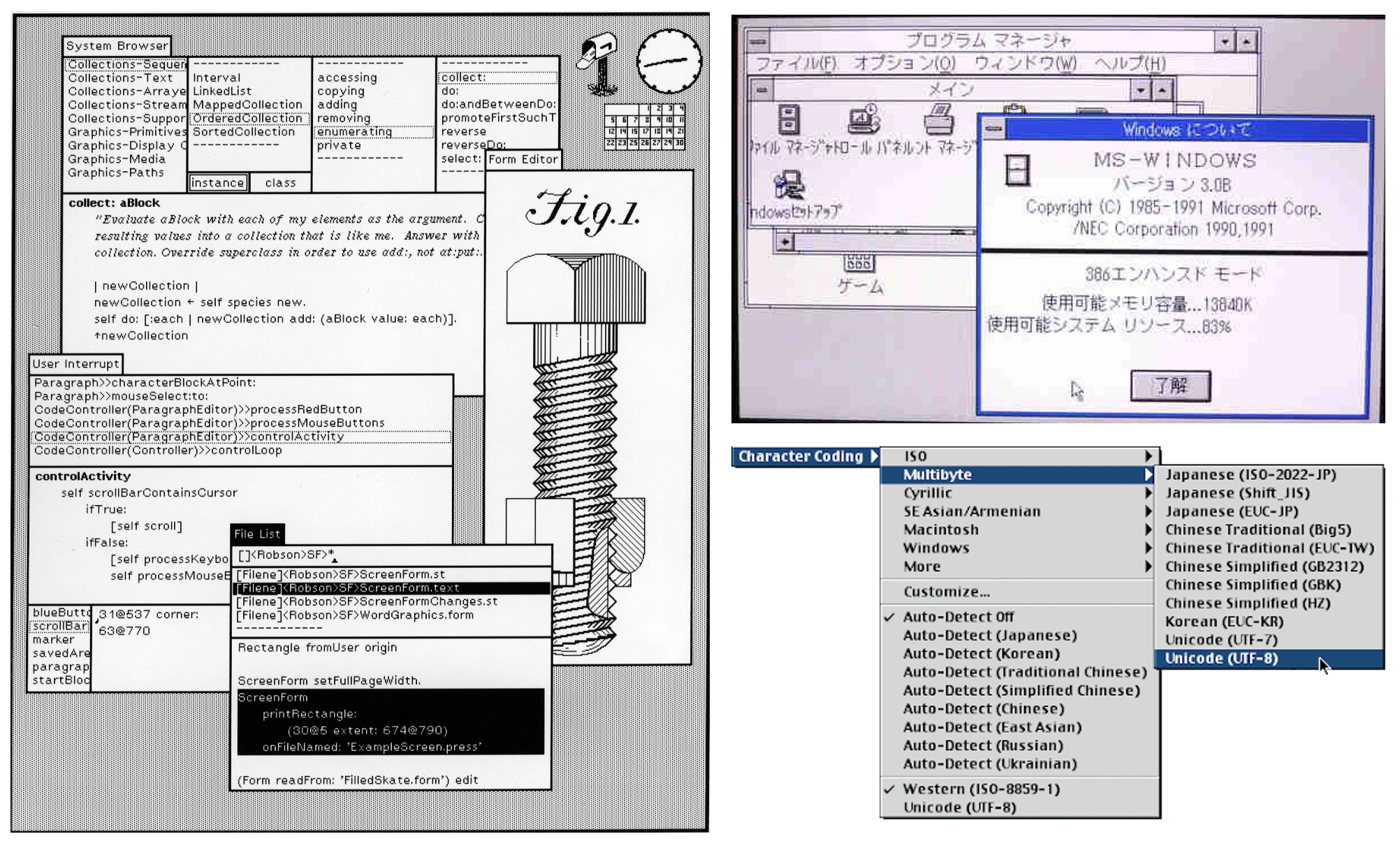
Represenitives from Xerox PARC and Apple started investigating a universal character set in 1987. By 1988 a document called Unicode 88 described a model which used 16 bits to represent the character encoding for modern languages. With more input from RLG [Research Libraries Group], Sun Microsystems and NeXT, the newly formed Uniccode consortium published the first Unicode standard in 1991. By the end of 1991 there were about 61 million IBM compatable PCs, 7 million Apple Macintosh and about two thousand Xerox Alto computers.
The Unicode Standard
Unicode is focused on the [numberic] encoding of characters [graphemes] rather than the various renderings [glyphs] of those characters.
The Unicode standard defines Unicode Transformation Formats (UTF): UTF-8, UTF-16, and UTF-32. In China, GB18030 is widely used and fully implements Unicode although it is not an official Unicode standard.
![]()
Even though Unicode started as a 16 bit encoding, the first 256 encodings used the same 8 bits codes as ISO/IEC 8859-1 [Latin-1] to make it simple to convert existing western text into Unicode.
Unicode UTF-8
UTF-8 has variable width encoding and can support 1,112,064 character points.
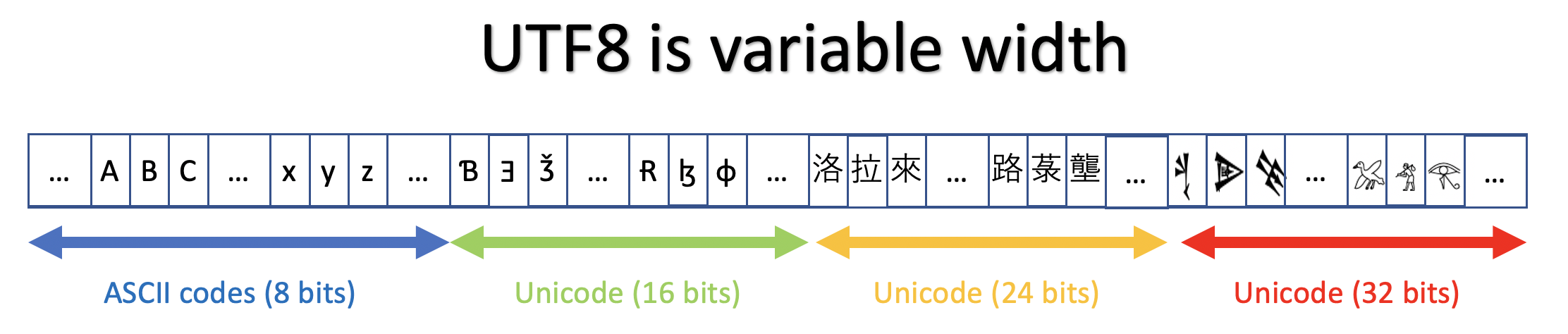
To minimize space, UTF-8 can use 1-4 bytes to encode a character. The first 128 characters in Unicode are a singe byte and correspond to the same ASCII byte encodings.

UTF-8 is widely used and is part of the specification for HTTP headers, IANA, HTML, CSS and XML.
Unicode UTF-16
UTF-16 is variable length, using one or two 16 bit code units to encode 1,112,064 characters.

UTF-16 is used internally by Java, JavaScript and Microsoft Windows.

Unicode UTF-32
UTF-32 is a fixed length character using four bytes (32 bits) for each Unicode code point.

Unicode Transformation Formats (UTF) are a space time trade off:
- UTF-8 minimizes space, but it is more complex to find the offsets of character encodings as the width is variable
- UTF-16 tends to use more space than UTF-8, but the offsets for character encodings are still tricky
- UTF-32 uses the most space [four bytes] per character encoding, but finding the offsets of character encodings is trivial
Eventual dominance of Unicode
UTF-8 has been the most common HTML encoding since 2008 and now accounts for 97.5% of all web pages.
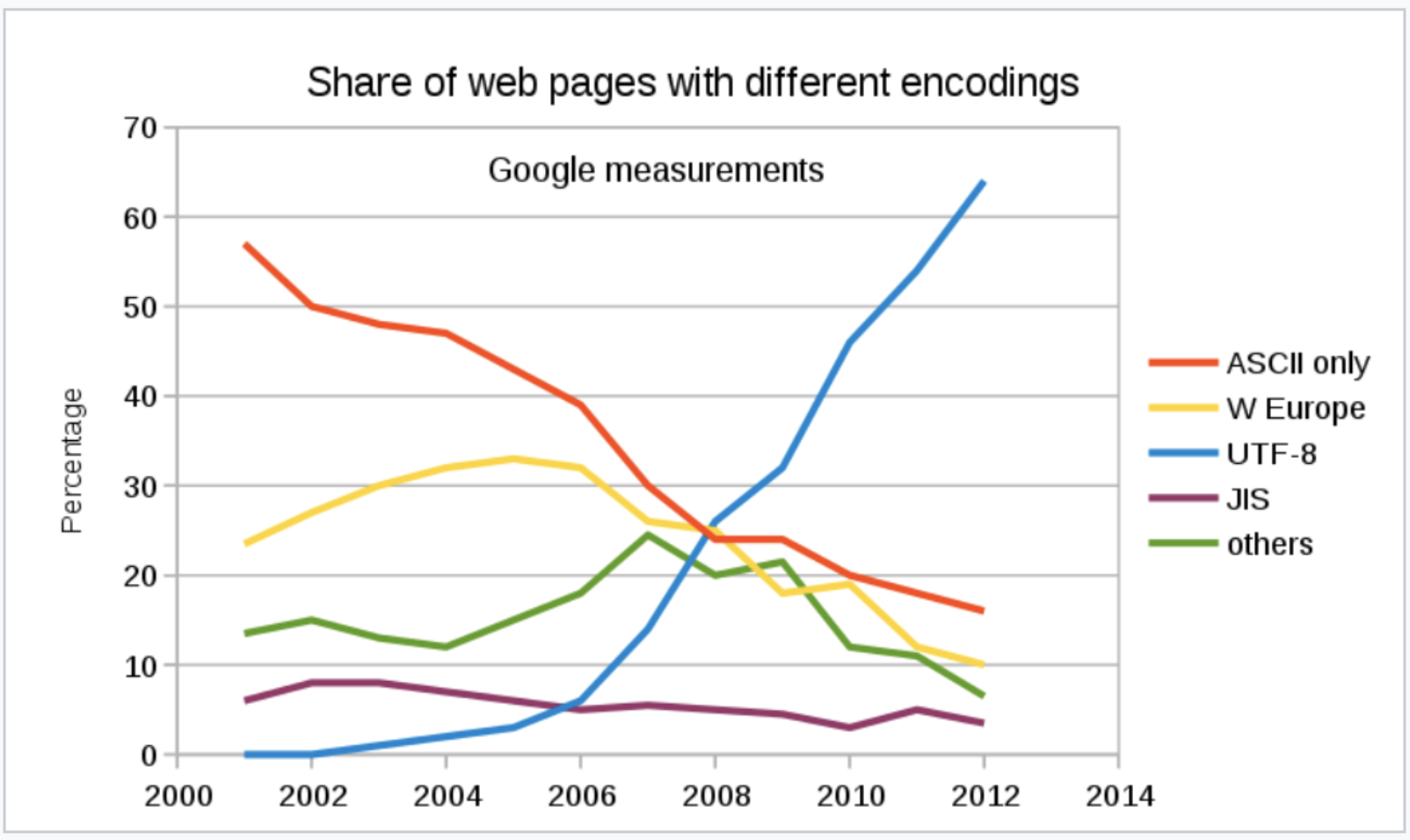
Although Java, JavaScript, Python and MS Windows use UTF-16, more recently there has been a move towards UTF-8 in MS Windows, Go, Rust, Swift, C++ and Julia.
Unicode Character sets in the Oracle Database
The Oracle Databse has supported five different Unicode database character sets.
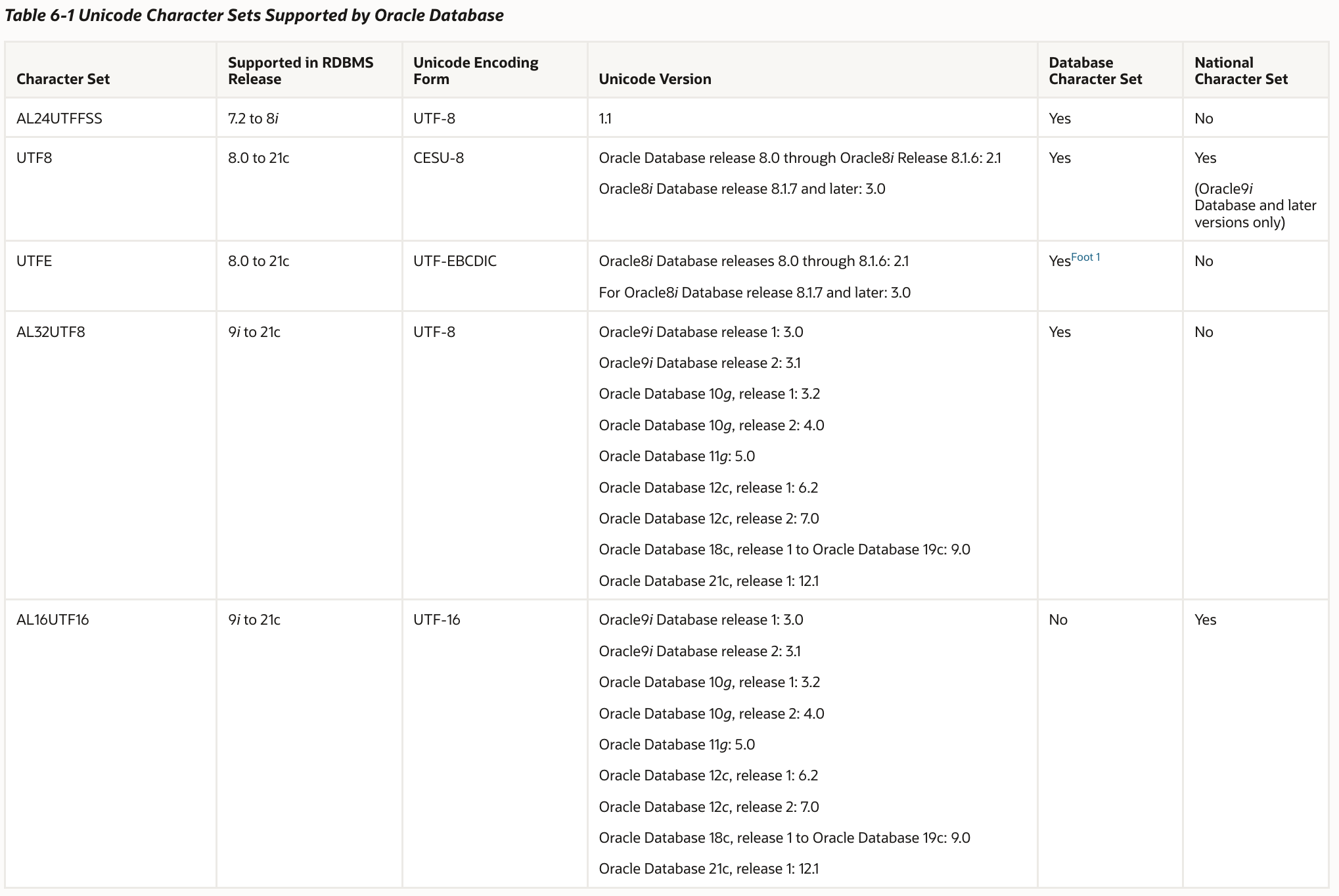
Things to note about Unicode support in the Oracle Database:
- AL16UTF16 is NOT a supported database character set. It is only supported as a National Character Set for non Unicode database character sets
- AL24UTFFS is no longer supported
- UTF8 only supports Unicode 3.0 and does not support the supplimental characters for Japanese and Chinese characters sets
- UTFE is only useful if the system is EBCDIC based
- This leaves AL32UTF8 as the Unicode database of choice
How Unicode data is stored in an Oracle Database
The Oracle Database uses the following encoding for UTF-8:
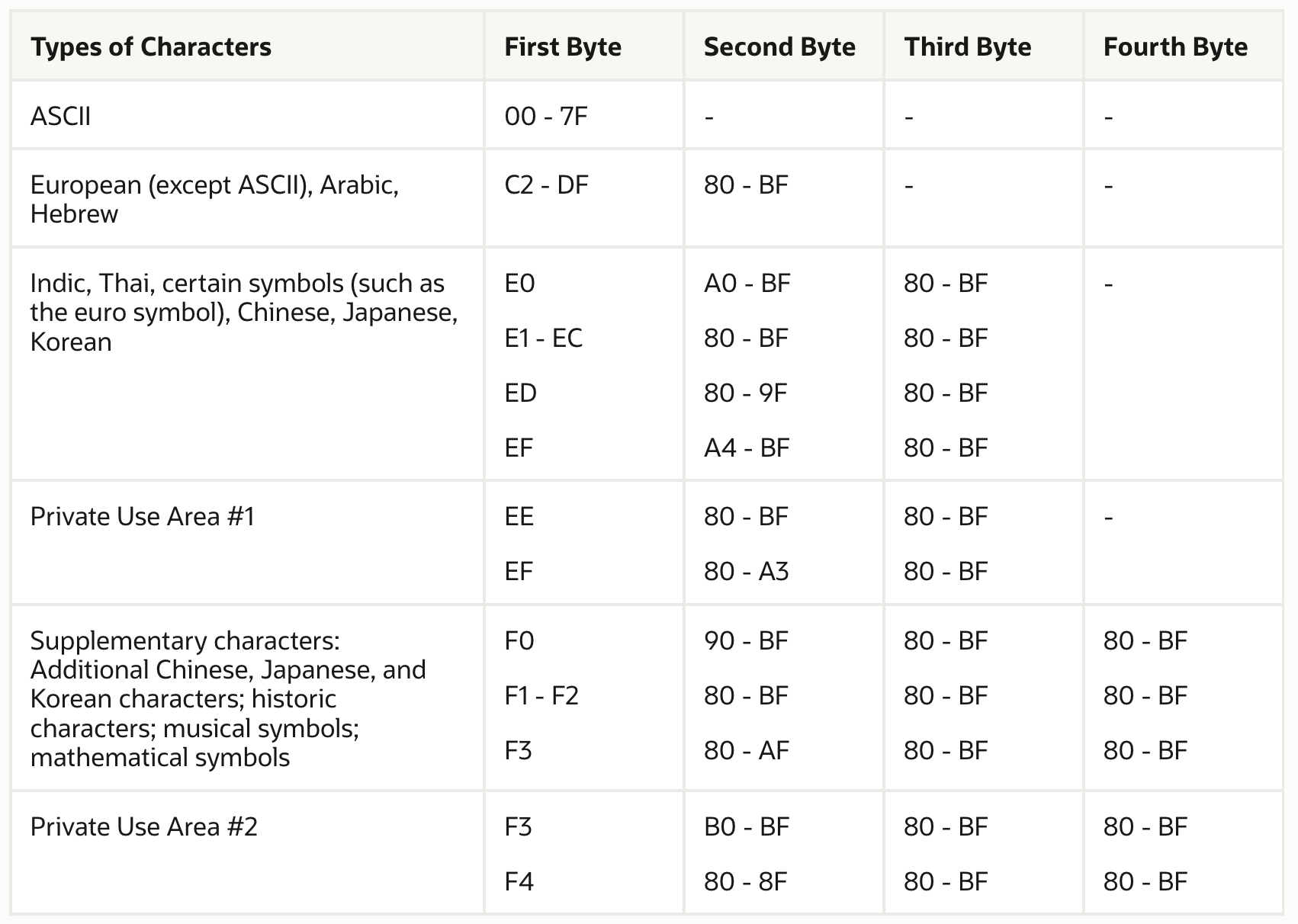
Comments on Oracle UTF-8 encoding:
-
ASCII characters use 1 byte
-
European (except ASCII), Arabic, and Hebrew characters require 2 bytes
-
Indic, Thai, Chinese, Japanese, and Korean characters as well as certain symbols such as the euro symbol require 3 bytes
-
Characters in the Private Use Area #1 require 3 bytes
-
Supplementary characters require 4 bytes
-
Characters in the Private Use Area #2 require 4 bytes
-
The AL32UTF8 character set supports 1-byte, 2-byte, 3-byte, and 4-byte values
-
The UTF8 character set supports 1-byte, 2-byte, and 3-byte values, but not 4-byte values
-
AL32UTF8 is a superset of UTF8 as it can support 4-byte values
Choosing an Oracle Database Character set
The character encoding scheme used by the database is defined as part of the CREATE DATABASE statement. All SQL CHAR data type columns (CHAR, CLOB, VARCHAR2, and LONG), including columns in the data dictionary, have their data stored in the database character set. In addition, the choice of database character set determines which characters can name objects in the database. SQL NCHAR data type columns (NCHAR, NCLOB, and NVARCHAR2) use the national character set.
Oracle Database uses the database character set for:
-
Data stored in SQL
CHARdata types (CHAR,VARCHAR2,CLOB, andLONG) -
Identifiers such as table names, column names, and PL/SQL variables
-
Entering and storing SQL and PL/SQL source code
Consider the following questions when you choose an Oracle Database character set for the database:
-
What languages does the database need to support now?
-
What languages will the database need to support in the future?
-
Is the character set available on the operating system?
-
What character sets are used on clients?
-
How well does the application handle the character set?
-
What are the performance implications of the character set?
-
What are the restrictions associated with the character set?
Recommended character set
Oracle recommends using Unicode for all new system deployments. Migrating legacy systems to Unicode is also recommended. Deploying your systems today in Unicode offers many advantages in usability, compatibility, and extensibility. Oracle Database enables you to deploy high-performing systems faster and more easily while utilizing the advantages of Unicode. Even if you do not need to support multilingual data today, nor have any requirement for Unicode, it is still likely to be the best choice for a new system in the long run and will ultimately save you time and money as well as give you competitive advantages in the long term.
- AL32UTF8 is a superset of UTF8
- AL32UTF8 is a universal characterset
- It can represent all known language character encodings
- AL32UTF8 is space efficient
- ASCII uses one byte for storage
- European, Arabic and Hebrew use two bytes for storage
- Indic, Thai and common Chinese, Japanese and Korean use three bytes for storage
- Additional Chinese, Japanese, Korean and historic languages use four bytes
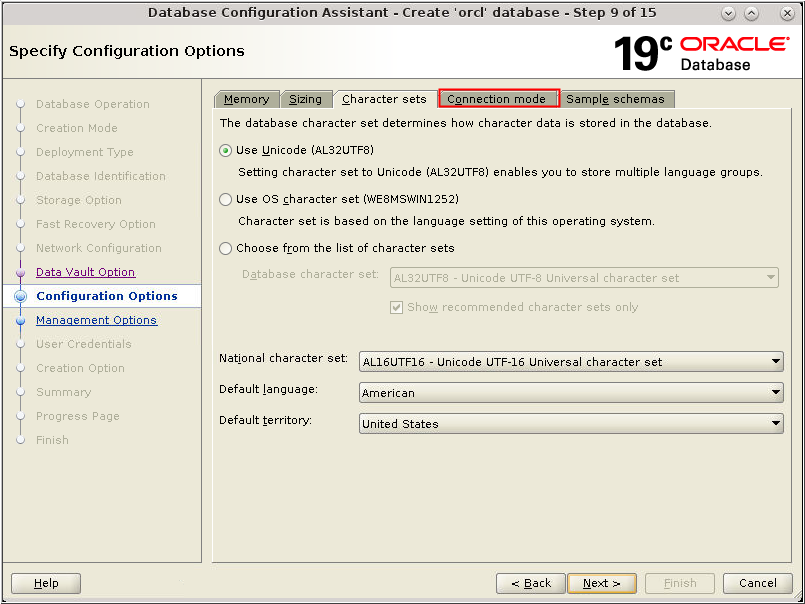
When you create an Oracle database, you must choose both the National Character Set and Character Set.
- Choose AL32UTF8 as the database character set
- Choose AL16UTF16 as the national character set
- Choose your default language as appropriate
- Choose your default territory as appropriate
Summary
- There are many choices for the Oracle Database character set
- Your hardware, operating system and data will constrain your choices for the database character set
- Unicode is now the dominant character set encoding
- Unicode UTF-8 is the dominant encoding for HTML
- AL32UTF8 is the best supported Unicode encoding for the Oracle Database character set
- AL32UTF8 is a default database charcter set since 12.2
- AL32UTF8 is the recommended Oracle database character set
Disclaimer: These are my personal thoughts and do not represent Oracle’s official viewpoint in any way, shape, or form.
