Introduction
TimesTen Scaleout is an In-Memory relational database with primary keys and foreign keys. TimesTen Scaleout is also a distributed database so you need mechanisms to automatically distribute the data across the various database shards. The challenge is how best to distribute table rows across a set of database shards to give the best read and write performance for your workloads while minimizing space and being highly available.
Data distribution is extremely important for distributed databases as it has a large impact on performance. For disk based databases like MySQL, PostgreSQL and Oracle, tuning SQL is all about creating execution plans which minimizes disk IO. For single instance [Classic] TimesTen In-Memory Database, disk IO should not be in the critical path, so SQL tuning is all about creating execution plans with good joins and indexes. For Oracle TimesTen Scaleout, tuning SQL is all about minimizing the number of network messages and the amount of data sent in each message.
TimesTen Scaleout data distribution is defined delaratively as artifacts of tables and global indexes. This means that developers do not need to care about where the data is or care about data consistency across shards. Instead developers just need to write SQL queries and DML as if it were a single instance database with normal COMMIT/ROLLBACK ACID transactions.
This approach makes things simple for developers and as a result of this, much of the responsibility for database performance is focused on optimal data distribution methods and indexing. There are various space/time trade-offs which will be covered later.
TimesTen Scaleout 22.1 enables four different kinds of data distribution which enable DBAs and/or developers to optimally place data for many different use cases:
- Distribute by Hash
- Distribute by Reference
- Duplicate Distribution
- Global Indexes
This blog describes the different types of data distribution with examples of their use.
Replicasets and Dataspaces
TimesTen Scaleout uses specific terminology for shards and copies of shards. This replicaset and dataspace terminology is used when describing the distribution methods.
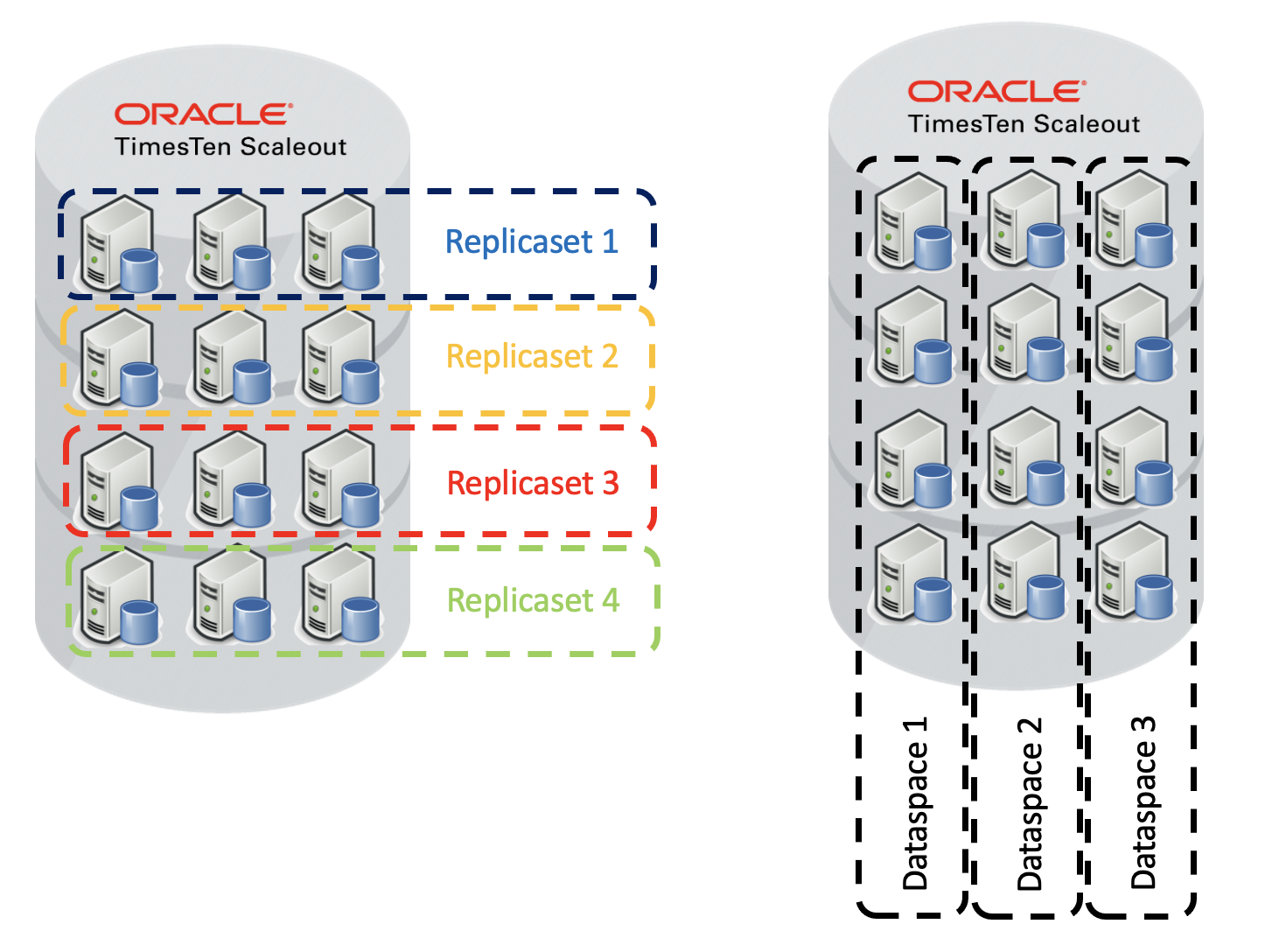
In the above picture, there are 4 shards and 3 copies of each shard:
- All of the copies of a shard are called a replicaset. Each copy is called an element
- A dataspace contains a single copy of each shard. Dataspaces should be independent for availability purposes [eg in a different rack with independent power supplies, or in different data centers / availability zones]
Distribute by Hash
The simplest data placement mechanism is distribute by hash. With this method, the rows of a table are spread as evenly as possible across all of the shards in the database. TimesTen Scaleout 22.1 allows up to 64 shards and there can be up to five copies of each shard.
Distribute by hash is really about mapping a set of rows to a set of shards.
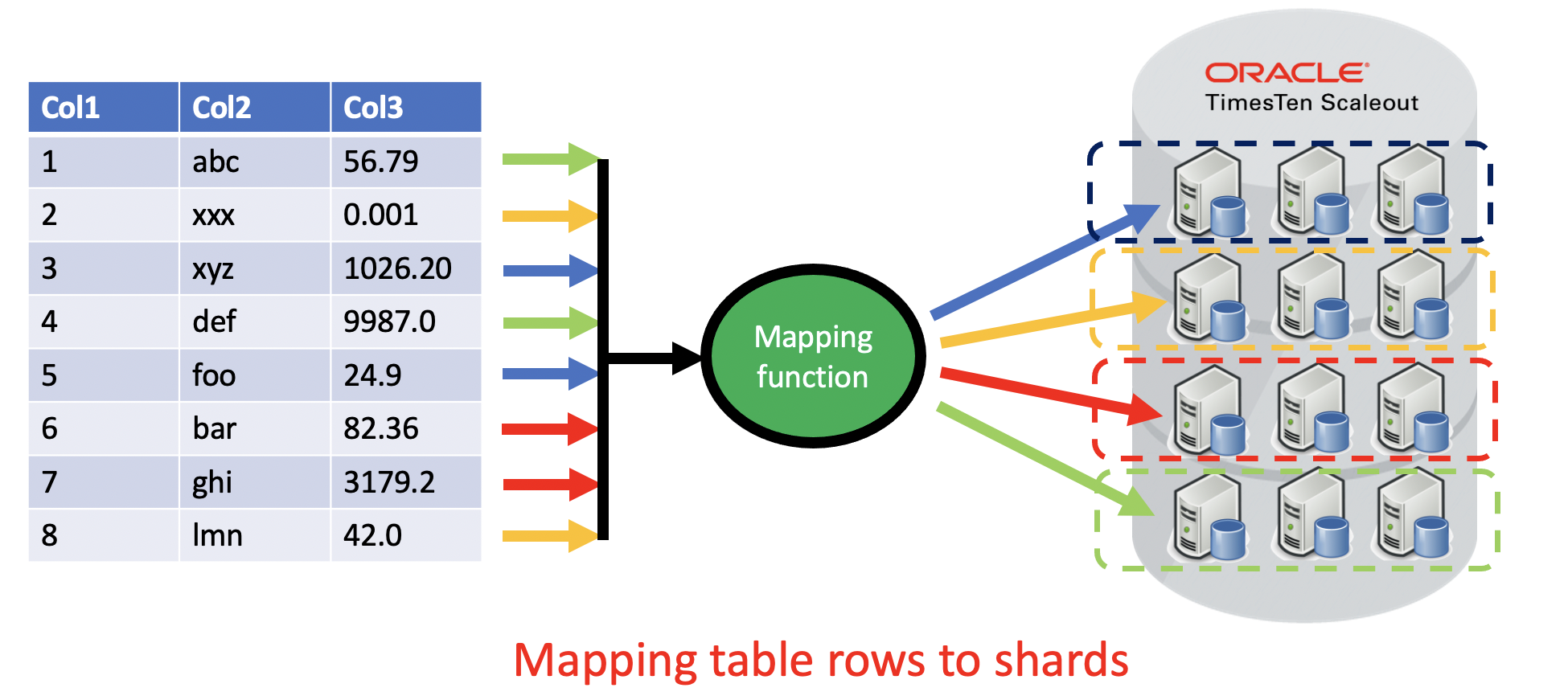
An internal TimesTen Scaleout consistent hash is used to as the mapping function. By default, the primary key for the table is used as the distribution key (ie the input to the consistent hash).

In the above example, the DEPT table has a range [B+tree] index. The primary key index type [eg hash or range] is independent of the distribution method [ie hash, reference or duplicate].
Customers can also choose to define their own set of columns as the distribution key.
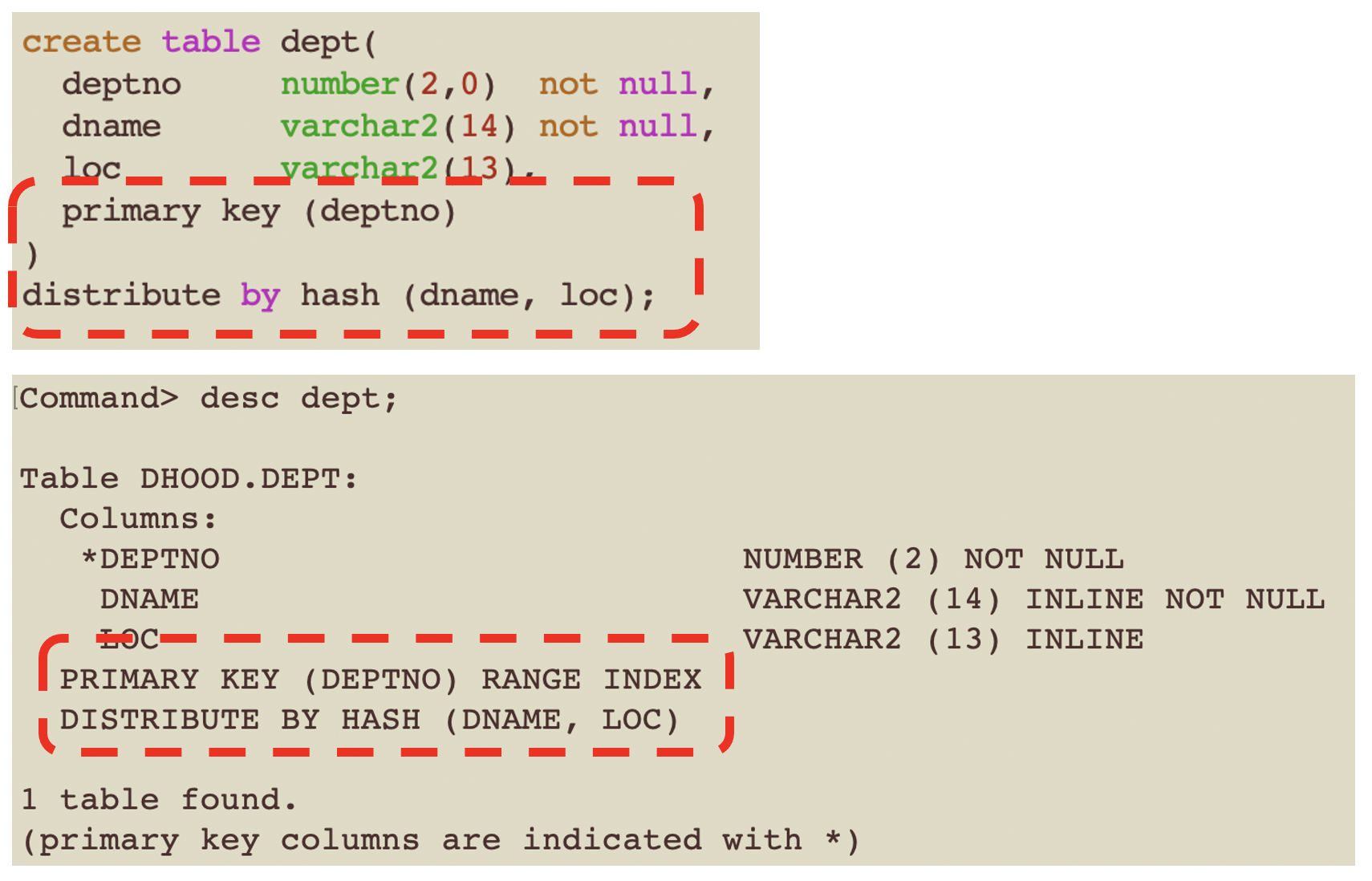
When a tables does not have a primary key or an explict distirbution key, then an internal row identifier is used instead.
When not using the primary key for the disribution key, care must be taken to avoid data skew. To maximize performance and simplify capacity planning, you want to have about the same amount of data in each shard. An example of data skew is using the USA state rather than a social security number as the distribution key. This would result in the shard for California having far more data for people than for the state of Nevada.
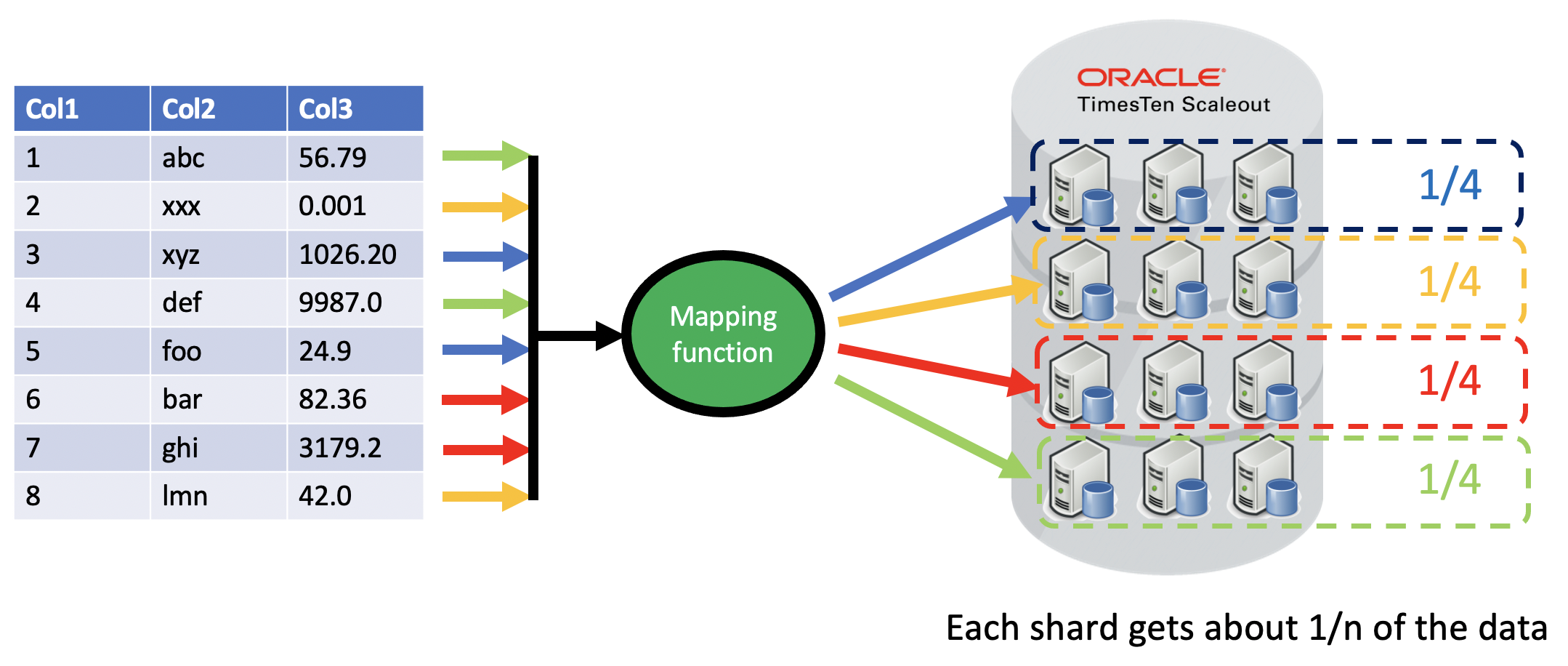
When using distribute by hash [with an even distribution] for a TimesTen Scaleout database with n shards, there is about a 1/n probability that a row of interest exists on the shard that you are connected to. As an optimization, when there is more than one copy of each shard, the execution plan will use the element in the current dataspace as the other other elements in that replicaset may be in remote data centers or remote availability zones.
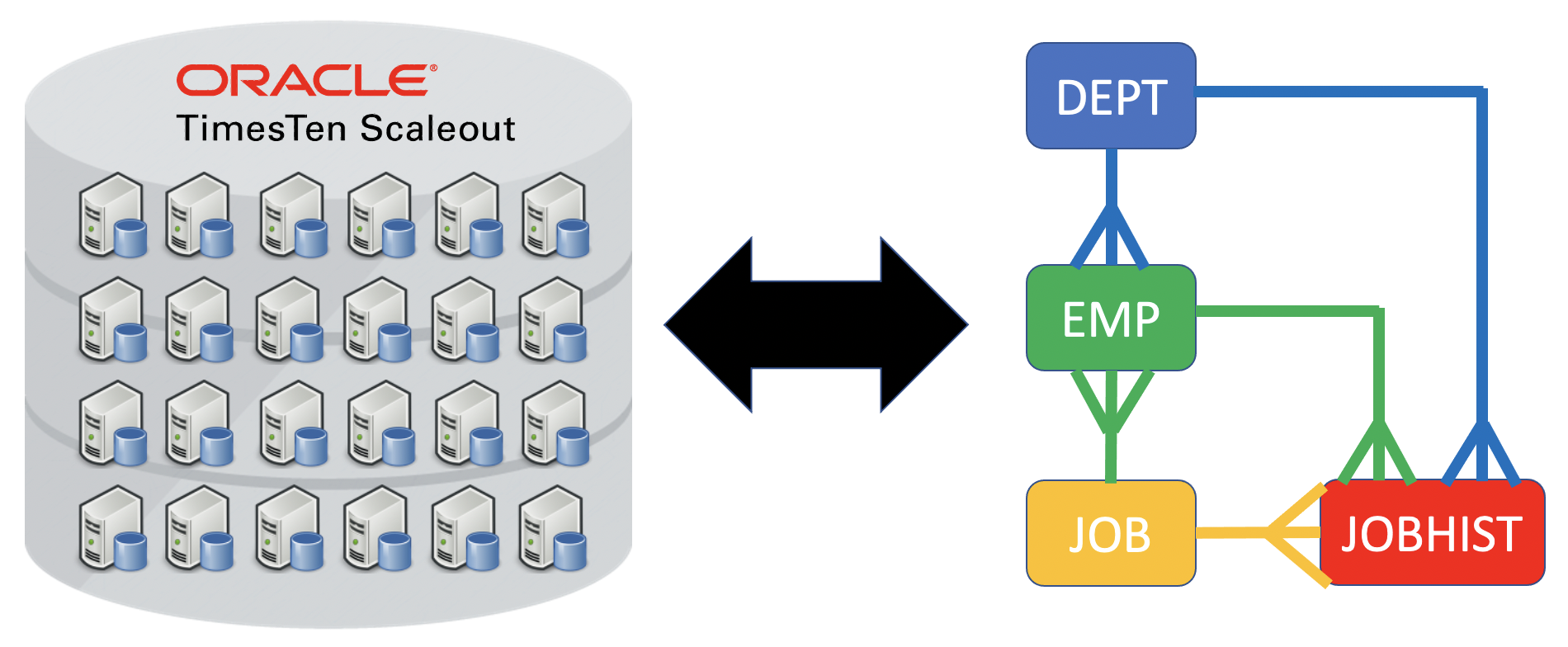
Distribute by Reference
One of the most common things that you do with a relational database is joins between tables. In single instance TimesTen, joins tend to be very fast as all tables are in memory on the same machine. Joins between two or more tables using distribute by hash in TimesTen Scaleout can be inefficient as it is unlikely that the rows needed for the join conditions are all on the same machine. When the rows are not on the same machine, TimesTen Scaleout will transparently resolve this via network messages, however these network messages can become the bottleneck.
A simple solution for fast joins is to use distribute by reference.
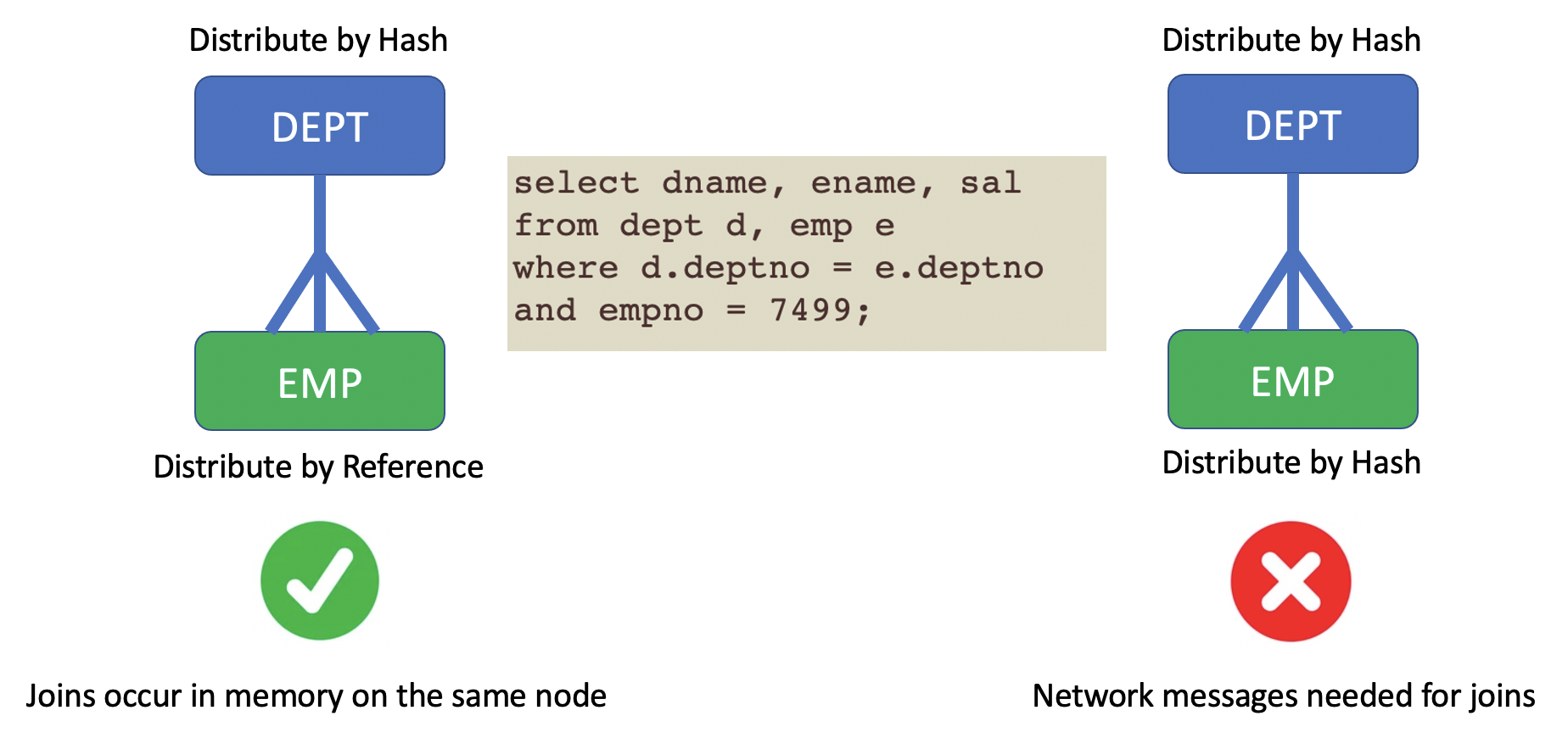
When you use distribute by reference, the child table uses one of its foreign keys as the distribution key rather than the primary key. This means that all of the child rows will reside on the same shard as their parent row. This means that a join on the PK / FK will occur in memory on the same machine. This means that these PK / FK joins can be very fast.
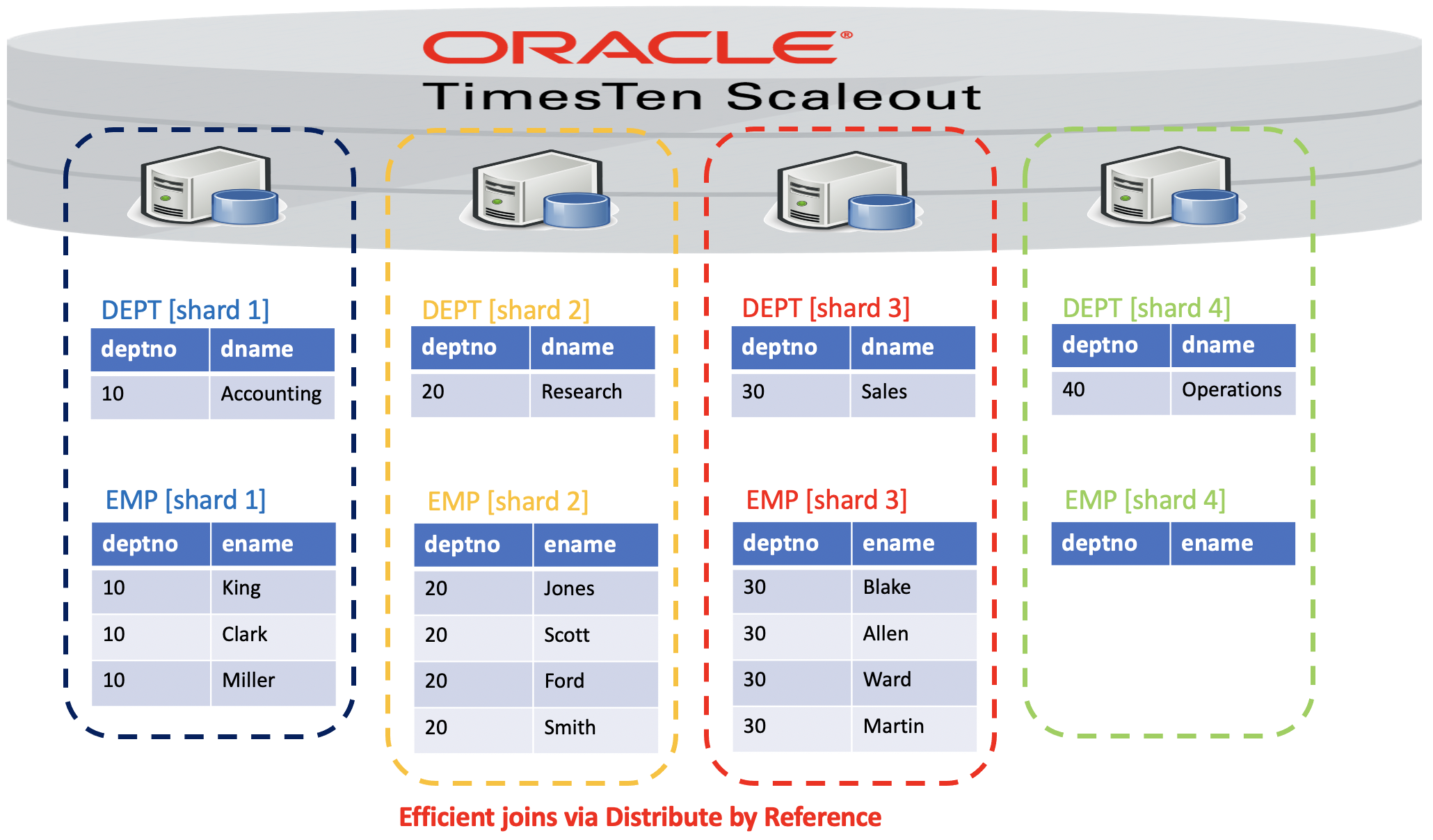
In the above example:
- In DEPT, the parent row for DEPTNO=10 is in shard 1. In EMP, all three child rows which have DEPTNO=10 are also in shard1
- In DEPT, the parent row for DEPTNO=20 is in shard 2. In EMP, all four child rows which have DEPTNO=20 are also in shard2
- In DEPT, the parent row for DEPTNO=30 is in shard 3. In EMP, all four child rows which have DEPTNO=30 are also in shard3
- In DEPT, the parent row for DEPTNO=40 is in shard 4. In EMP, there are no child rows which have DEPTNO=40 in shard4
- The number of child rows may not be the same in each shard:
- This is data dependent. eg some ORDERS may have more line items than anothers
- Given lots of parent & child rows, this tends to average out across all shards
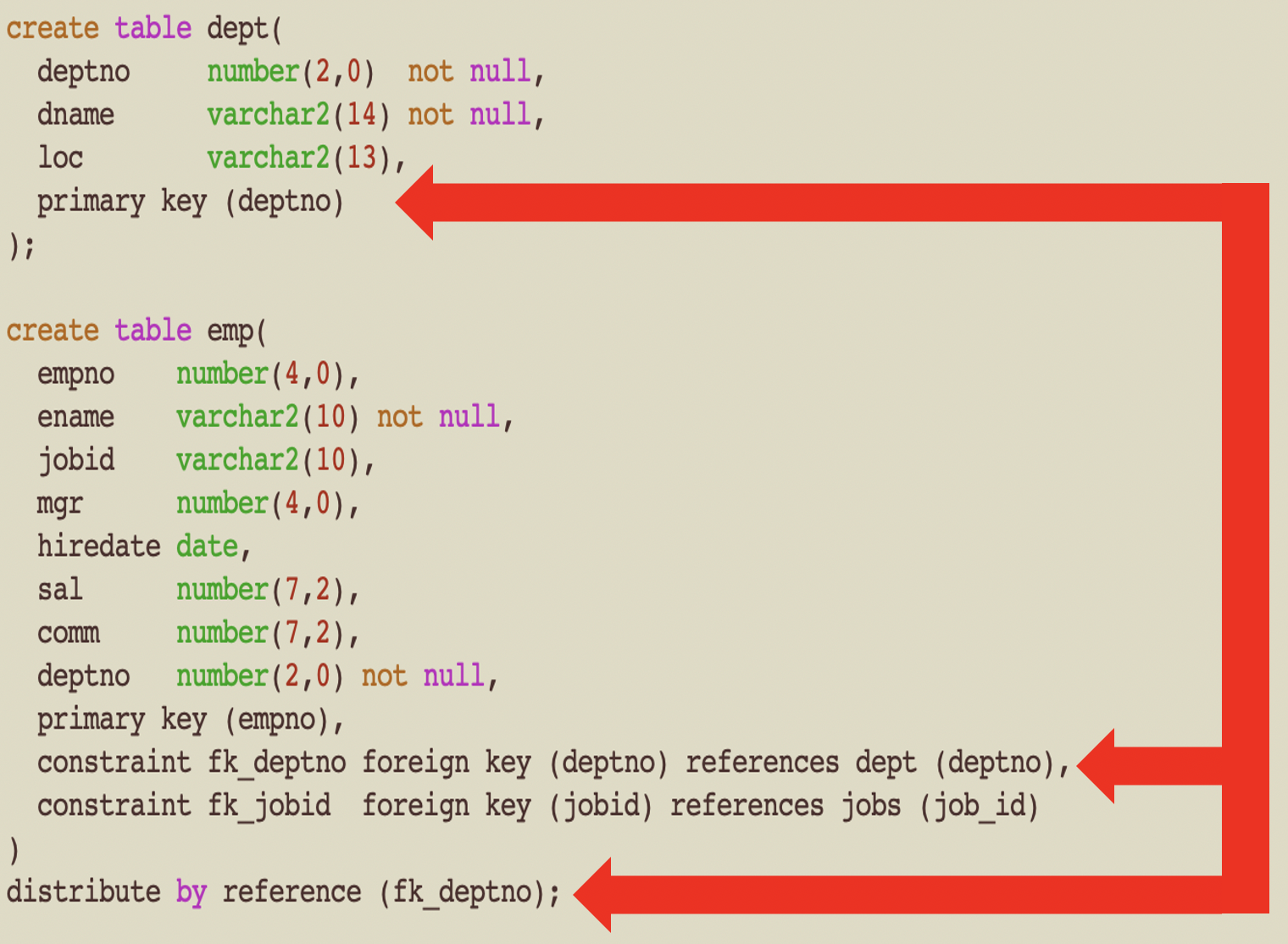
In the above example, there are two foreign Keys. Only one foreign key can be used for distribute by reference.

As an example of of the sort of performance that you can get with joins which use distribute by reference:
- A customer had over 10 billion rows in two tables which had a parent child replationship
- A join between these tables [with a complex where clause] returned a multi-row resultset and executed in 0.3 milliseconds using TimesTen Scaleout
- This query scanned over 10 TB of data in 0.3 milliseconds
- This was over 30 times faster than the previous system
- The Oracle TimesTen Scaleout database for this customer had 12 shards and two copies of each shard [12×2] for a database with about 60 billion rows
Duplicate Distribution
If a child table has multiple foreign keys, which foreign key should be used for distribute by reference?
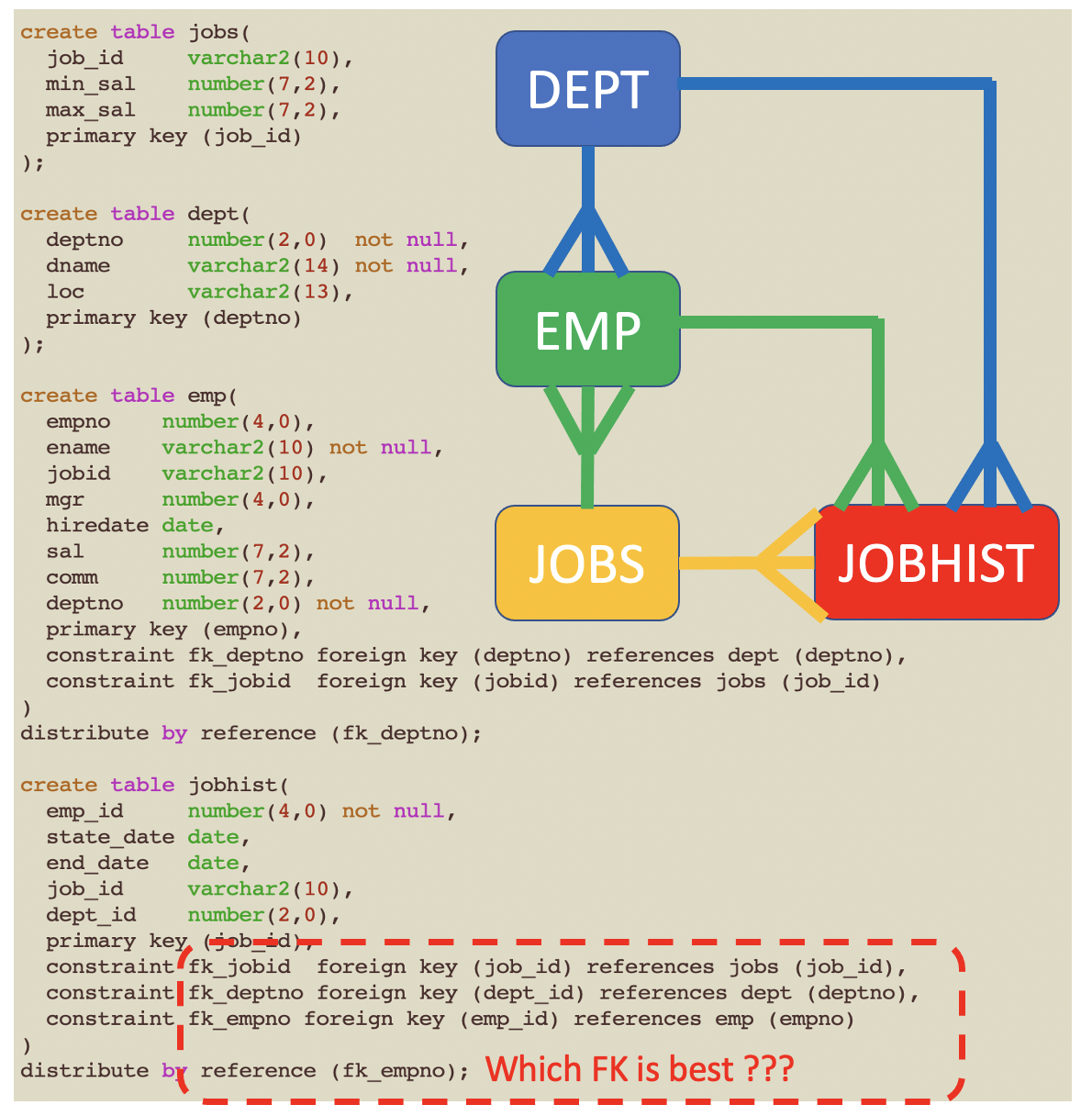
In the example above for the JOBHIST table:
- If JOBHIST used the fk_jobid for distribute by reference, it would have fast joins with JOBS, but slower joins with EMP and DEPT
- If JOBHIST used the fk_deptno for distribute by reference, it would have fast joins with DEPT, but slower joins with EMP and JOBS
- If JOBHIST used the fk_empno for distribute by reference, it would have fast joins with EMP, but slower joins with JOBS and DEPT
If a table is joined by many different tables, [and/or does not use FKs,] then you have the choice of using duplicate for the distribution method.
With the duplicate distribution method, an entire copy of the table exists on every shard. This is a classic space/time trade-off. The duplicate table will take up more space, but it can have fast joins as the duplicate table enables in-memory joins on any element. Duplicate distributions are slower for SQL INSERT, UPDATE and DELETE statements as the writes need to occur on every shard and every copy of the shard in the database [ie on every element].
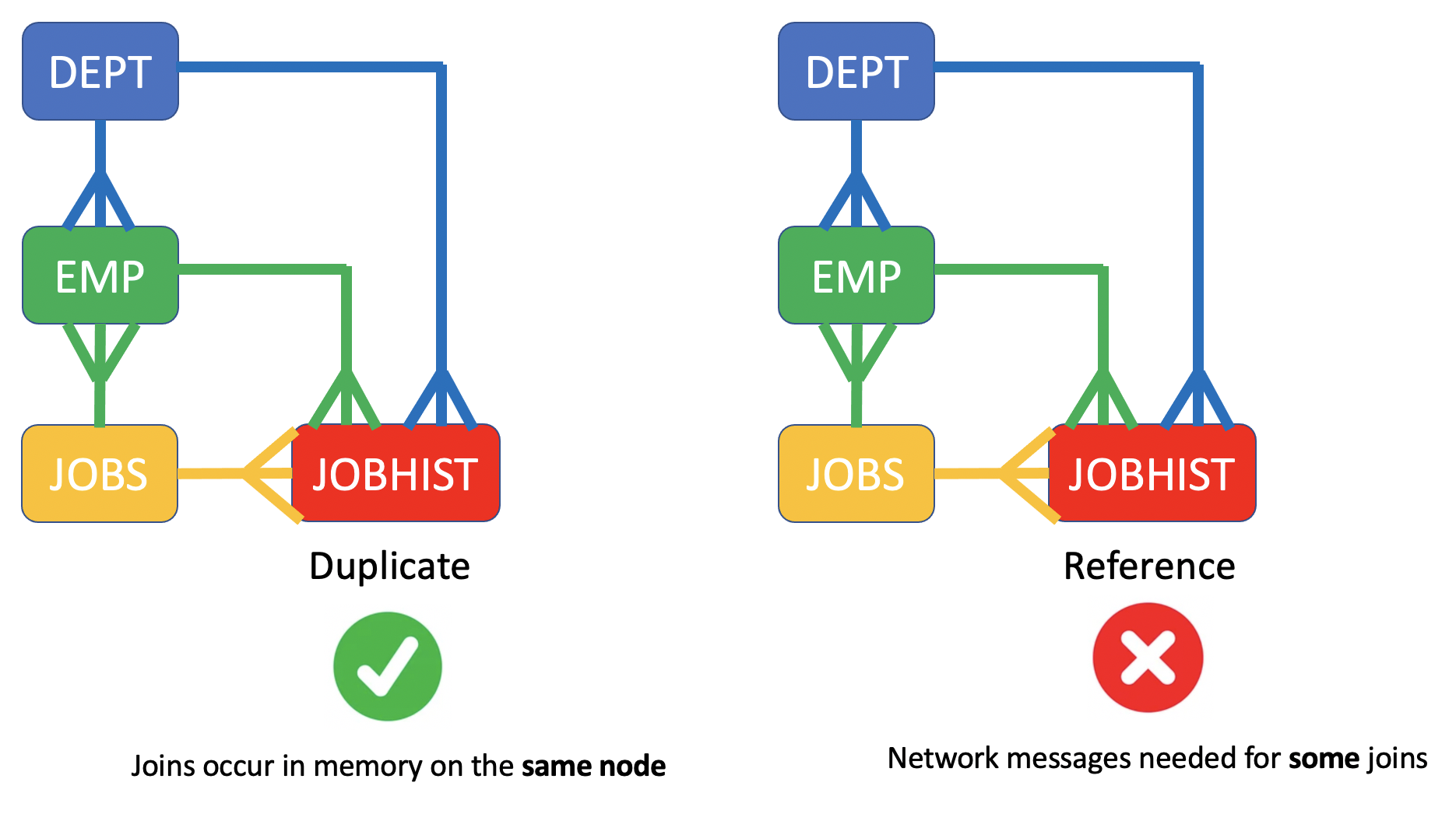
The following shows the syntax for duplicate distribution on the JOBHIST table.

Global Indexes
There are other cases to consider:
- What if you need to do joins that are not based on the primary key or foreign key?
- What if you need to do unique constraint checks on non PK / FK columns?
- What if you need to do joins which include a pre-fix of the table distribution key?
- What if you need to do joins which include a subset of the table distribution key?
These are the cases where global indexes can help. Global indexes transparently create a materialized view for columns of interest and use distribute by hash for those columns.
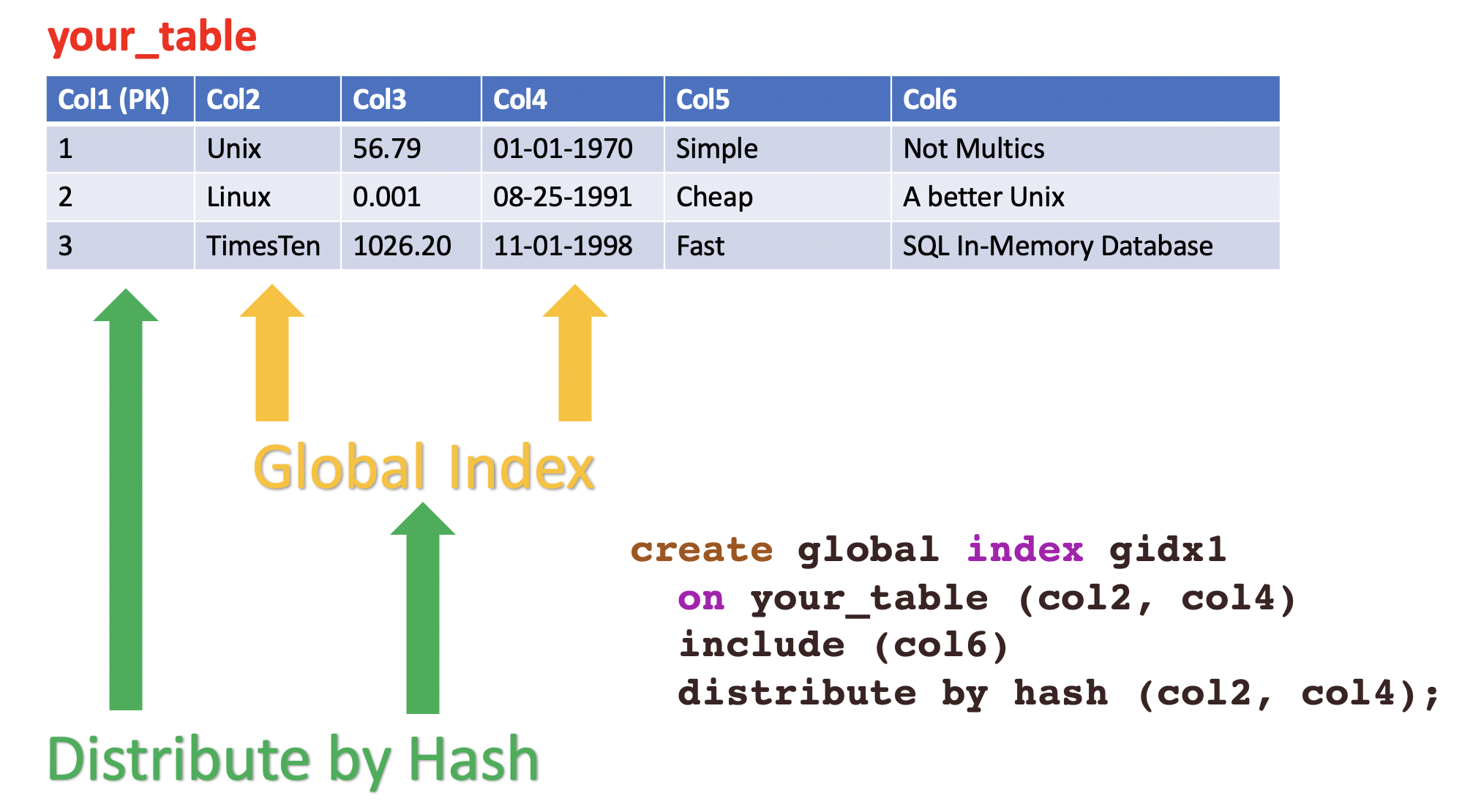
This is another classic space/time trade-off. The global indexes takes up more space, but can significantly speed up data access.

The TimesTen Scaleout query optimizer will automatically use the global index if the columns of interest are covered by the global index.
You can have up to 32 columns per global index for the distribution key and up to 1000 columns in the include list.
You can have up to 500 local or global indexes per table.
You can add global indexes to tables which are distributed by hash, reference or duplicate.
Summary
Efficient data distribution is critical for fast data accss and joins in TimesTen Scaleout.
TimesTen Scaleout declaratively defines data distributions in DDL.
How the data is distributed is transparent to developers. Developers just need to write familiar SQL DML and queries with joins.
There are three main types of data distribution:
- Distribute by Hash
- Distribute by Reference
- Duplicate Distribution
All tables need to be distributed by either hash, reference or duplicate.
In addition to the table distribution method, global indexes enable fast non PK/FK access via distribute by hash for the columns of interest.
Disclaimer: These are my personal thoughts and do not represent Oracle’s official viewpoint in any way, shape, or form.
