※本記事は、Eric J. Brunoによる”Streaming analytics with Java and Apache Flink“を翻訳したものです。
Flinkの組込み複合イベント処理エンジンを使ってリアルタイム・ストリーミング分析を行う方法
著者:Eric J. Bruno
2020年7月6日
IoTとエッジ・アプリケーションの登場により、一部のアナリティクス・アプローチやフレームワークで、ミニバッチ処理を使ったリアルタイム近似分析が行われるようになっています。この手法では、発生するレイテンシによって制限が生じる可能性があります。本記事では、ミニバッチによるアプローチのメリットについて説明するとともに、Apache Flinkフレームワークとミニバッチを使ってデータ・ストリームに対しステートフルな計算を行う方法を提案します。ここでの目的は、Flinkの組込み複合イベント処理(CEP)エンジンを使ってこのようなリアルタイム・ストリーミング分析を行うことです。
ストリーム分析処理
アプリケーションは、連続データ・ストリームからイベントを受け取る際、そのイベントに即座に反応する必要があります。しかし、バッチ処理のアプローチでは、データを収集して格納し、ある時点でデータの収集をやめてから、収集したデータに対して分析を実行します。その後、次のバッチを処理して集計しますが、反復処理を行ってもコンテキストは保持されます(図1参照)。この収集時間がかなり短い場合を、一般的にミニバッチ処理と呼びます。
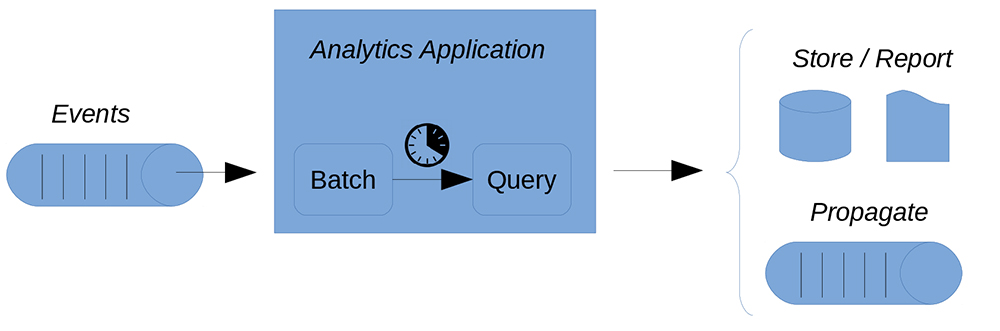
図1:ストリーミング・データのミニバッチではレイテンシが発生するため、制限につなが可能性がある
ライブ・データに対するバッチ処理には、いくつかの困難が伴います。たとえば、バッチ間隔(すなわち、いつ収集をやめるか)の決定、レイテンシの制御、ストレージの管理などです。レイテンシが発生するのは、データが繰り返し収集、保存される際に、データを読み込む処理が遅延するからです。さらに、大量のデータを保存した場合、費用がかかることや、パフォーマンスが損なわれることもあります。このような課題を回避するための代替案について考えてみます。
リアルタイム分析にFlinkを使用するメリット
データは傷みやすいものです。データがもっとも価値を持つのは、生成されたときや取り込まれたときです。残念なことに、ミニバッチ処理によるレイテンシがデータの価値に悪影響を与える可能性もあります。対照的に、真のストリーム分析では複数の継続的なデータ・ストリームを扱うため、結果の検査、データのフィルタリングや集計、トレンドやパターンの検出、結果の予測、フォーカスのレベルのリアルタイム変更が可能です(図2参照)。
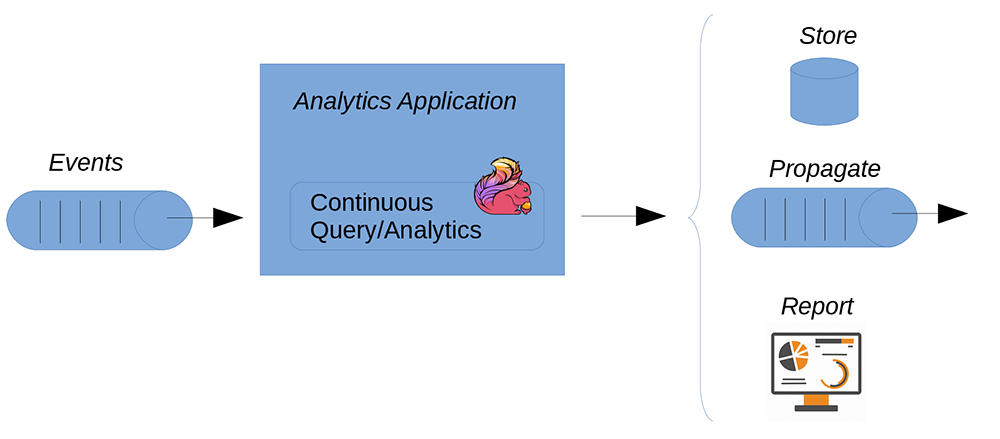
図2:ストリーミング・データの真のリアルタイム処理では、レイテンシが限られるため、データの価値が維持される
ストリーム分析を行うことで、履歴データの分析で得られる以上の知見を自動的に得ることができます。とりわけ、ストリーム分析は、予知保全、アルゴリズム取引、医療分野でのスマート看護、工場における生産ライン監視などの多くのユースケースで活用されています。一例として、筆者が執筆した「ヘルスケアIoTソリューションにおける複合イベント処理(英語)」という記事をご覧ください。
Flinkフレームワークでは、バッチ化することなく、ストリーミング・データのリアルタイム処理を行います。さらに、ストリーミング・データと履歴データ・ソース(データベースなど)を組み合わせて、集計したデータに対して分析を行うこともできます。筆者の意見では、Flinkが持つ特に強力な機能は、CEPのサポートです。CEPは、イベント駆動の分析アプリケーションの構築にうってつけです。
ストリーミング・データのCEP
ほとんどの場合、リレーショナル・データベースとファイルシステムは、リアルタイムでのストリーミング・データ処理を行うためではなく、静的データを格納するために使用されます。CEPでは、受信するイベントのストリームを1つまたは複数のパターンとマッチングさせることで、この問題に対処します。この処理はリアルタイムで行われるため、アプリケーションでは遅延なしで、ノイズの多いデータの除去、トレンドの検出や、しきい値追跡を行うことができます。CEPで扱えるデータ・ストリームは1つだけではなく、さまざまなタイプのストリームが混在しても構いません。また、CEPでは変換、集計、フィルタリング、相関もサポートしています。たとえば、CEPシステムでは、1つまたは複数のデータソースやデバイスからのデータ・ストリームの処理と、データベースに格納されたデータを組み合わせることもできます(図3参照)。

図3:末端から末端までのストリームベースによるクエリー処理の概要
一致シーケンスのすべてのイベントをシステムで確認したら、クエリーで定義されているように、結果がリアルタイムで伝播します。
Flink APIの内部
Flinkには、一般的なデータ処理のユースケース用のいくつかのライブラリを備えています。通常、それらのライブラリはAPIに埋め込まれており、他のライブラリに組み込むことができます。
- DataSet API:これは、バッチ処理アプリケーションやデータ変換用のコアAPIで、状態処理機能が組み込まれています。
- DataStream API:このAPIでは、ステートフル・ストリーミング・アプリケーションをサポートし、データ・ストリームと時間の両方を入力として使います。
- FlinkCEP:FlinkのCEPライブラリでは、イベントのパターンを定義するAPIが提供されます。FlinkのDataStream APIと統合されているため、パターンはDataStreamsで評価されます。
- Flink Graph API:このライブラリはGellyとも呼ばれており、スケーラブルなグラフ処理と分析のためのものです。GellyはDataSet APIを使って実装されており、このAPIと統合されています。複数の組込みアルゴリズムが提供されます。
本記事では、主にDataStream APIとFlinkCEP APIに着目します。
Flink CEPエンジン
オンライン・マニュアルによれば、Apache Flinkは規模を問わないストリーミング分析を実行できるように設計されています。アプリケーションは複数のタスクへと並列化され、分散されてクラスタで実行されます。Flinkの非同期な増分アルゴリズムによって、「厳密に1回」という状態の整合性が保証されるとともに、レイテンシが最低限に抑えられます。また、組込みのWSO2のCEPエンジンが埋め込まれたオープンソースのCEPライブラリが組み込まれているため、Flinkは柔軟であり、さまざまな種類のストリームを扱うことができます。
それでは、CEPワークフローの例を見てみます。FlinkCEP APIを使用して、監視する条件をまず定義します。次に、温度データなどのデータのストリームに対して、定義した条件のうち1つまたは複数を適用します。リスト1のコードでは、この処理を始めています。
リスト1:FlinkのDataStreamで、ネットワークのソケット接続からデータをキャプチャする
DataStream<String> deviceRawStream = env.socketTextStream( host, port );
DataStream<TemperatureEvent> inputEventStream =
deviceRawStream.map(
new MapFunction<String, TemperatureEvent>() {
@Override
public TemperatureEvent map(String value) throws Exception {
TemperatureEvent evt =
new TemperatureEvent(deviceid, new Integer(value));
return evt;
}
}
);
リスト1のコードでは、ソケットベースのDataStreamを定義し、(MapFunctionを使って)受信データの値をTemperatureEventオブジェクトにマッピングすることで、2つ目のDataStreamを作成しています。次に、上記で定義したイベント・ストリームを基に、CEPを使って、値がしきい値以下である温度データをすべて除去します(リスト2参照)。
リスト2:CEPは、ノイズの多いデータや不要なデータを除去する場合に役立つ
IterativeCondition<TemperatureEvent> tempThresholdCondition =
new IterativeCondition<TemperatureEvent>() {
@Override
public boolean filter(
TemperatureEvent event,
IterativeCondition.Context<TemperatureEvent> ctx) throws Exception {
return event.getTemperature() >= TEMPERATURE_THRESHOLD;
}
};
さらに、ある時間枠の中で温度のしきい値を少なくとも2回超えた場合、警告するようにCEPパターンを定義します(リスト3参照)。
リスト3:FlinkCEPを使ってパターンを定義し、任意のDataStreamに適用する
Pattern<TemperatureEvent, ?> warningPattern =
Pattern.<TemperatureEvent>begin("first")
.subtype(TemperatureEvent.class)
.where(tempThresholdCondition1)
.next("second")
.subtype(TemperatureEvent.class)
.where(tempThresholdCondition2)
.within(Time.seconds(20));
最後に、リスト4に示すように、PatternStream(DataStreamから導出)と、別のDataStreamを定義します。このDataStreamが、除去後の温度データがパターンの条件に一致した場合に生成される実際の警告を表します。今回の場合、この条件は、ある時間枠の中でしきい値を超えた2つの温度測定値として定義されています。
リスト4:定義された条件に基づくパターンに一致するDataStreamを定義する
PatternStream<TemperatureEvent> temperaturePatternStream =
CEP.pattern( inputEventStream.keyBy("deviceId"),
warningPattern);
DataStream<TemperatureWarning> warnings = temperaturePatternStream.select(
(Map<String, List<TemperatureEvent>> pattern) -> {
TemperatureEvent first = (TemperatureEvent) pattern.get("first").get(0);
TemperatureEvent second = (TemperatureEvent) pattern.get("second").get(0);
return new TemperatureWarning(
first.getDeviceId(),
(first.getTemperature() + second.getTemperature()) / 2);
}
);
warnings.print();
PatternStreamでは、デバイスIDに基づいて単純にDataStreamからデータを選択し、警告パターンを適用しています。コードでは次に、データベースのSELECT文と同じように、PatternStreamから選択し、それぞれの警告イベントを構成する2つのTemperatureEventオブジェクトを取り出しています。結果となる温度データはそれら2つの温度の平均をとったもので、TemperatureWarningオブジェクトが新しい警告DataStreamの一部として発行されます。この例では、アプリケーションがそれぞれの警告イベントをコマンドラインに書き出します。
Temperature Warning! Device 1 average temperature is above threshold: 101.5 Temperature Warning! Device 1 average temperature is above threshold: 103.0
それでは、この例を進化させて複数のデバイスを扱うようにし、すべてのデバイスを対象にして算出する平均温度(フェデレーション平均温度)を計算してみます。
フェデレーション分析の例
次に説明する例では、先ほどの例のように、すべてのデバイス(つまり、建物内のオフィスごとに1つ)の温度測定値を平均するソリューションを構築します。さらに、すべてのオフィスの温度を平均した別のストリームを作成したうえで、建物全体の温度を算出します。図4は、それらのストリームを結合して作成するパイプラインの概要です。この図の各「Temp Zone」(温度ゾーン)が、建物内のオフィスを表します。
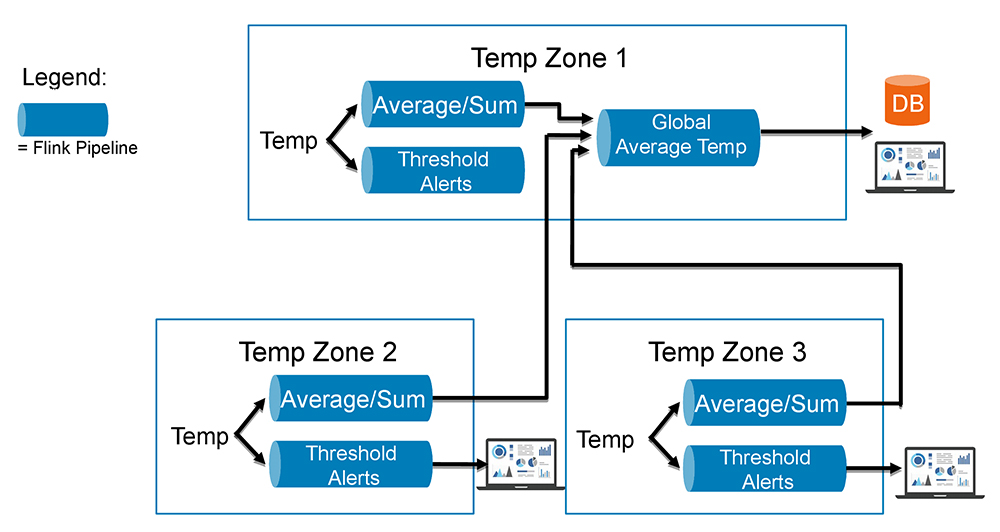
図4:Apache Flinkを使ってストリームのパイプラインを作成する
次に、Flinkを使って経時的にデータを集計し、平均を生成する例を見てみます(図5参照)。
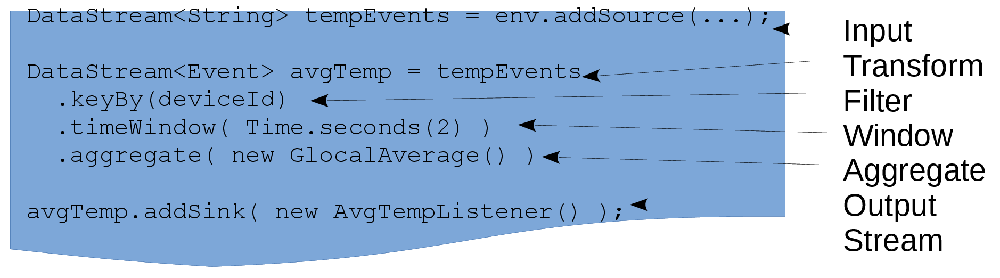
図5:ストリーミングされるデータのクエリーの構造
この例は、以下のことがどれほど簡単にできるかを示しています。
- ワークフローにクエリーを追加する
- データを変換する
- 発生するオペレーションに関する、時間ベースのウィンドウやトリガーベースのウィンドウ(たとえば、ストリームのデータ項目の可用性)を作成する
- データの集計やグループ化をサポートする
- 結果をストリームとして生成して、必要に応じ、ワークフローの一部として次のクエリーで使用する
データの変換
データのストリームを使って行う有意義なこととして、よく挙げられるのがデータの変換です。Flinkでは、オブジェクトへのデータ・マッピング、データのフィルタリング、データに対する演算を行う、さまざまな変換オペレータとユーザー定義関数をサポートしています。変換では、Stringを解析して整数にする、データをコレクションに追加するといったシンプルな処理や、受信する値の集計や平均の計算といった、やや複雑な処理が可能です。ここで必要なのは、まさにこの平均です。
データを集計するために、FlinkのSingleOutputStreamOperatorを定義します。名前からわかるように、これは単一のデータ・ストリームを処理します。一方、JoinOperatorでは複数のストリームを扱います。今回の場合は、リスト1のinputEventStreamオブジェクトを受け取り、集計を行います(リスト5参照)。
リスト5:受信するFlinkデータ・ストリームを変換する
SingleOutputStreamOperator<Tuple3<Integer, Long, Double>> aggregateProcess =
inputEventStream.keyBy( value -> value.getDeviceId() )
.window(GlobalWindows.create())
.trigger(CountTrigger.of(1))
.aggregate(new Aggregation());
まず、ストリーム・セレクタを定義し、特定のデバイスの値を取得しています。次に、イベントのウィンドウに対して変換をトリガーしています。この場合の対象は、受信するすべての新しいイベントです。または、複数イベントのウィンドウを定義してデータ・セットを処理することもできます。さらに、AggregateFunctionインタフェースには入力オブジェクト、アキュムレータ、タプルが必要です。
このアプリケーションでは、3つのフィールドがあるTuple3を使います。このタプルには、デバイスID、温度測定値を受信した回数、すべての温度測定値の合計が含まれます。データを受信したとき、FlinkではAggregationクラスのaddメソッドを呼び出します(リスト6参照)。
リスト6:温度データを集計するAggregateFunction
public class Aggregation implements
AggregateFunction< TemperatureEvent,
AverageAccumulator,
Tuple3<Integer, Long, Double>> {
public AverageAccumulator add(TemperatureEvent evt, AverageAccumulator acc) {
acc.key = evt.getDeviceId();
acc.sum += evt.getTemperature();
acc.count++;
return acc;
}
//…
}
アキュムレータ・クラス(前述)とシリアライザを定義する必要があります。シリアライザでは、JavaのOutputStreamにどうデータを書き込み、InputStreamからどうデータを読み取るのかを定義します。リスト7は、集計したデータをNATS.ioでどのようにパブリッシュする(シリアライズする)かを示しています。具体的には、リスト5のaggregateProcessオブジェクトでFlinkのSinkを定義しています。
リスト7:Flinkのカスタム集計処理の結果をパブリッシュする
// このストリームをNATS.ioのPub/Subでパブリッシュする
aggregateProcess.addSink(
new AggregateStreamPublisher(
pubSubServerAddr,
pubSubServerPort,
"AggregateTemp"+deviceId) );
次は、このデータをフェデレーション・ワークフローでどのように使うかについて詳しく見ていきます。
分散した温度データの受信
分散したデータに対応するために、各オフィスに配置されたデバイスの温度データの平均および集計は、NATSioPubSubConnectorプロジェクト(コードはこちらから参照できます)で実装されたFlinkのpub/subプラグインを通じ、NATS.ioメッセージ・ブローカを使って送信します。受信にはカスタムFlinkソースを使います。ワークフローはFederatedAverageTemperatureクラスを使って実装されており、最初に各温度ゾーンに対してNATS.ioリスナーを設定しています(リスト8参照)。
リスト8:温度ゾーンに対してNATS.ioのpub/subリスナーを設定する
private void monitorAverageAndAggregateTemperature(
StreamExecutionEnvironment env ) throws Exception {
NATSMessageSchema<String> schema = new NATSMessageSchema<>();
PubSubDeserializationSchemaImpl<String> deserializer =
new PubSubDeserializationSchemaImpl<String>(schema);
// デバイス1の「集計温度」ストリームに接続
SourceFunction<String> aggTemp1PubSubSource = PubSubSource
.newBuilder()
.withDeserializationSchema(deserializer)
.withProjectName("project")
.withSubscriptionName("AggregateTemp"+ZONE_ID_1)
.withServer(PUB_SUB_HOST_ADDR)
.withport(PUB_SUB_HOST_PORT)
.build();
まず、NATSMessageSchemaカスタム・オブジェクトを作成しています。このオブジェクトは、NATS.ioメッセージをシリアライズおよびデシリアライズする方法をFlinkに知らせるために使用します。次に、NATS.ioサーバーからパブリッシュされたメッセージをリスニングするためのPubSubSourceカスタム・オブジェクトを作成しています。その際に、サーバーのアドレスおよびポートとともに、リスニングするサブスクリプション名(AggregateTemp1など)を指定しています。この設定が完了したら、次の手順としてFlinkのDataStreamを作成します。このDataStreamでは、リスト9のようにして、パブリッシュされた集計温度データを受け取ります。
リスト9:ゾーンの集計温度データのFlink DataStream
DataStream<String> device1AggregateRawStream =
env.addSource(aggTemp1PubSubSource).returns(Types.STRING);
DataStream<AggregateTemperatureEvent> device1AggregateStream =
device1AggregateRawStream.map(new MapFunction<String,
AggregateTemperatureEvent>() {
@Override
public AggregateTemperatureEvent map(String value) throws Exception {
AggregateTemperatureEvent evt =
new AggregateTemperatureEvent(ZONE_ID_1, value);
return evt;
}
}
);
device1AggregateRawStreamは生データを含むDataStreamオブジェクトで、String型の温度値のストリームです。device1AggregateStreamは、その値を入力として使って作成するDataStreamオブジェクトで、AggregateTemperatureEvent型のオブジェクトを発行します。このデータ・フローが各ゾーンに1つずつ作成されます。
最後に、各ゾーンから受信したデータからフェデレーション平均温度(すなわち、建物の温度)を作成するために、各温度ゾーンのDataStreamを組み合わせ、ゾーンの数に基づく移動「ウィンドウ」を使って全体平均を計算します。たとえば、20の温度ゾーンがある場合、ウィンドウ数を20に設定し、最新の20ゾーンの測定値を受信するまで待機してから全体平均を計算し、次の20の測定値を待機します。今回は、例の説明と実行を容易にするため、2つの温度ゾーンだけを使っています(リスト10参照)。
リスト10:全体平均温度を計算するために、すべてのデータのDataStreamを結合する
// すべての温度ゾーン(デバイス)のデータ・ストリームを結合
DataStream<AggregateTemperatureEvent> unionStream = device1AggregateStream
.union(device2AggregateStream)
.keyBy( value -> value.getDeviceId() );
// すべてのゾーン(デバイス)の温度データに集計を適用
DataStream<GlobalAverageTemperatureEvent> globalAverageStream = unionStream
.countWindowAll(2, 2) // based on number of zones (devices)
.aggregate(new GlobalAverage());
globalAverageStream.print();
最初のDataStream結合処理では、温度測定値をデバイスIDごとにまとめています。2つ目の結合処理では、スライディング・ウィンドウを使って、各ゾーンのデータを受信するまで待機しています。リスト10のウィンドウは、アプリケーションにおいて、2つのゾーンの測定値を受信するたびに、受け取った2つのゾーンの最新測定値を使ってデータを集計することを示しています(実際には、個々のストリームに対応するタイムアウト・ハンドラを追加し、既知の最新の測定値をそのまま使ってもよいでしょう。そうすることで、すべての温度ゾーン全体の適切な平均値となることが保証されます)。この出力を図6に示します。
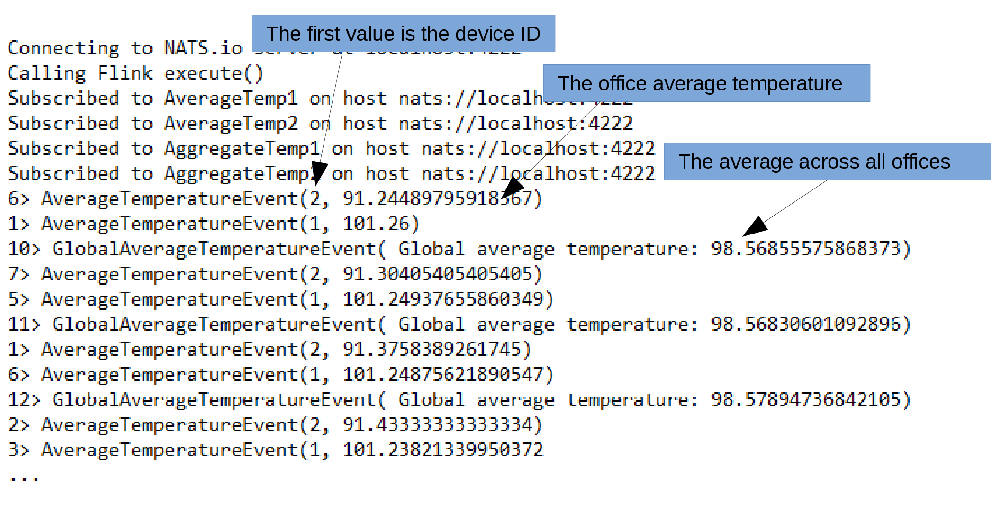
図6:集計アプリケーションからの出力
注:すべてのゾーンの温度測定値から本当の全体平均を得るための計算では、ゾーンごとに集計した温度データ(測定回数と、すべての測定値の合計)を使用して平均を生成します。そのため、全体平均は、単純にゾーンごとの平均温度の平均をとったものとは微妙に異なります(それよりも正確です)。
サンプルのフェデレーション温度アプリケーションを実行する
このサンプルFlinkアプリケーションを実行するために必要な最初の手順は、Apache Flinkをダウンロードしてインストールすることです。Apache Flinkは、Windows、macOS、Linuxのすべてで問題なく動作します。次に、Flinkのインストール場所のbinディレクトリにあるシェル・スクリプト(~/flink-1.10.0/bin/start-cluster.sh)を実行してFlinkを起動します。Flinkを停止する場合、UNIXではstop-cluster.shスクリプトを実行します。Windowsでは、Flinkの起動時に開いた2つのコマンド・ウィンドウを閉じます。Flinkの実行について詳しくは、こちらのチュートリアルを参照してください。
今回の例には、4つのプロジェクト/アプリケーションが含まれています(こちらからダウンロードしてください)。
- TempSource:デバイスの温度データをシミュレートした連続ストリームを生成する
- NATSioPubSubConnector:パターンに従うことで、Flinkベースの分析がNATS.ioのpub/subトピックをサブスクライブできるようにするApache Flinkコネクタ
- FlinkAverageTemperature:1つのデバイスから温度データのストリームを受け取り、移動平均を計算し、すべての温度の集計を追跡し、NATS.ioを使って結果をpub/subトピックにパブリッシュするApache Flinkアプリケーション
- FederatedAverageTemp:各温度ゾーンのデータをサブスクライブし、すべてのゾーンの全体平均を計算するApache Flinkアプリケーション
温度ゾーンは、2つの個別のコンテナとして実行することも、2つの個別のVMとして実行することも、実際のコンピュータで実行することもできます。ただし、各コンテナ、VM、コンピュータで専用のFlinkインスタンスを実行する必要があることに注意してください。さらに、NATS.ioブローカをいずれかの場所で実行する必要があります。また、それぞれのサンプル・アプリケーション(FlinkAverageTemperatureおよびFederatedAverageTemp)は、実行するノードのIPアドレスを使って更新する必要があります。以下に、温度ゾーン1の詳細な手順を示します。
- NATS.io Dockerコンテナを起動する(nats.ioでダウンロード可能)
sudo docker run -p 4222:4222 -ti nats:latest -m 8222 - Flinkを起動する
/home/<user>/flink-1.10.0/bin/start-cluster.sh - Flinkタスクのエグゼキュータのログを監視する
tail -f \ flink-1.10.0/log/flink-<username>-taskexecutor-0-<computername>.out - 温度をシミュレートしたデバイスを起動する
java -jar TempSource/target/TempSource-1.0-SNAPSHOT.jar port 9091 - Flinkの平均温度パイプライン・アプリケーションを起動する
flink run FlinkAverageTemp/target/FlinkAverageTemp-1.0.jar \ host <datazone1-IP> port 4222 deviceid 1
温度ゾーン2についても同じ手順を実行します。ただし、手順1は除きます(実行する必要があるNATS.ioインスタンスは、ネットワークで1つのみです)。このFlinkワークフローからの出力は図7のようになります。

図7:温度ゾーン2のFlinkワークフローからの出力
次に、温度ゾーン1に戻り、フェデレーション平均温度(全体平均温度)を生成するFlinkアプリケーションを実行します。IDEから実行しても、次のコマンド(すべて1行で入力)を実行しても構いません。
> java -classpath NATSioPubSubConnector-1.0-SNAPSHOT.jar -jar \ FederatedAverageTemp-1.0.jar host <NATS.io-Host-IP>
すべての手順が正しければ、図6のように出力されます。
まとめ
Flinkには、バッチとリアルタイムでストリーム・データ処理を行うための機能が多数搭載されているため、本記事だけではとても説明しきれません。提供されている機能には、セーブポイントによる組込みフォルト・トレランス、高可用性、分散とスケーリング、組込み済みの統合機能、パフォーマンス・チューニングがあります。他のフレームワークとは異なり、Flinkのバッチ処理はリアルタイム・ストリーミングをベースに構築されています(その逆ではありません)。
また、Java、Scala、Pythonなどの複数の言語をサポートし、FlinkMLによるAIワークフローにも対応しています。今後のFlinkのロードマップには、機械学習パイプラインのサポートや、ストリーム、イベントベース、およびバッチ処理の各アプリケーション向けAPIの統合、ストリーム処理のパフォーマンスの継続的な改善、Flinkアプリケーションのデプロイの簡略化、エコシステムの拡大など、さまざまなことが含まれています。Flinkを使用しサポートする企業は増加しているため、このコミュニティへの参加もぜひ検討してください。
 |
Eric J. BrunoDellのアドバンスト・リサーチ・グループに所属。主にエッジや5Gを扱う。大規模分散ソフトウェアの設計、リアルタイム・システム、エッジ/IoTを専門とするエンタープライズ・アーキテクト、開発者、アナリストであり、およそ30年にわたって情報テクノロジー・コミュニティで活躍している。Twitterのフォローは@ericjbrunoから。 |
