本記事はAleks Seovićによる“Refactoring Java, Part 3: Simplifying legacy code” を翻訳したものです。
Coherence CEアプリケーションをKubernetesクラスタにプッシュし、そのスケーリングと管理を行う方法
著者:Aleks Seović
2021年1月15日
Oracle Coherenceは、分散キャッシュ製品として当初登場し、その後インメモリ・データ・グリッドへと進化を遂げました。Java EEアプリケーションのパフォーマンスとスケーラビリティの改善に不可欠なツールとして、大規模プロジェクトで広く使われています。このツールは、複数のJVMやマシン、場合によってはデータセンターに分散され、スケーラビリティ、並列性、耐障害性を兼ね備えたjava.util.Map実装と考えてください。
2020年夏、オラクルはこの製品のオープンソース版であるCoherence Community Edition(CE)をリリースしました。
本シリーズの第1回の記事では、Coherence CEに格納したTo Doリストのタスクを管理できるREST APIを実装しました。第2回の記事では、ReactベースのWebフロントエンドと、JavaFXベースのデスクトップ・クライアントを構築しました。
シリーズ最終回となる本記事では、このプロジェクトのパッケージ化とデプロイ、そして運用の側面について説明します。その一環として、既存のデモにスケール・アウト、永続化、監視、エンド・ツー・エンドのリクエスト・トレースのサポートを追加して、実稼働品質のアプリケーションにする作業を行います。図1にアプリケーションのUIを示します。
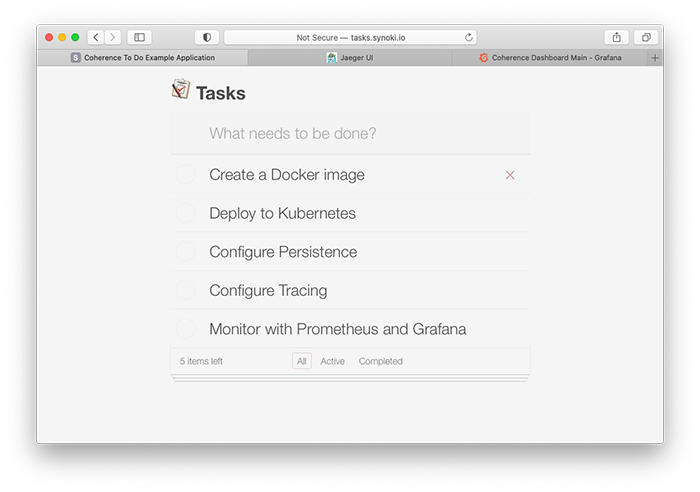
図1:サンプルTo Doリスト・アプリケーションのユーザー・フレンドリなインタフェース
Docker イメージの作成
アプリケーションをKubernetesにデプロイするため、最初にアプリケーションのDockerイメージを作成します。オラクルは、最新バージョンのCoherence CEのビルド済みDockerイメージを提供しています。このイメージはGitHubのDockerレジストリからダウンロードすることができます。ただし、このイメージが役立つのは主に、基本機能のみを必要とし、サーバーサイドのカスタム・コードを使わないテストや簡易デモです。それ以外の用途(今回のTo Doリスト・アプリケーションを含みます)に使用する場合は、カスタムのDockerイメージを作成する必要があります。
重要な点は、Spring BootやMicronaut、Helidonなどの一般的な軽量フレームワークと同じように、Coherence CEも単なるライブラリであり、Java SEアプリケーションやマイクロサービスに埋め込んで使うものであることです。その意味で、Coherence CEのデータ管理サービスは、前述の軽量アプリケーション・フレームワークを使って実行できる埋込みのHTTPサービスやgRPCサービスに似ています。表現を変えれば、別のサーバーを実行してアプリケーションから接続するわけではないということです。アプリケーション自体が、Coherence CEクラスタ・メンバーです。
軽量Java SEアプリケーションのDockerイメージをビルドする方法はいくつかあります。Spring Bootなどの一部のフレームワークでは、そのための専用ツールまで提供されています。しかし、筆者がこれまで使用した中で、通常のJavaアプリケーションのイメージをビルドするもっとも簡単な方法は、Jib Mavenプラグインです。このプラグインでは、POMファイルの内容に基づいて、必要な依存性すべてをパッケージ化してくれます。Dockerfileや起動スクリプトを書く必要はありません。さらに、さまざまな種類の依存性(外部、プロジェクト)が異なるイメージ・レイヤーにパッケージ化されることで、イメージのサイズが小さくなり、プロセスのビルド時間が短縮されます。今回作成したようなHelidon/Coherence CEアプリケーションとの相性も抜群なので、このプラグインを使用します。
最初の手順として、POMファイルでJibプラグインを構成します。この構成はMavenビルドの都度行うのではなく、Dockerイメージをビルドしたいときだけ明示的にアクティブ化する必要があるMavenプロファイルで行います。
<profiles>
<profile>
<id>docker</id>
<build>
<plugins>
<plugin>
<groupid>com.google.cloud.tools</groupid>
<artifactid>jib-maven-plugin</artifactid>
<version>2.6.0</version>
<configuration>
<from>
<img alt="" src="null" />
gcr.io/distroless/java:11
</from>
<to>
<img alt="" src="null" />${project.artifactId}
<tags>
<tag>${project.version}</tag>
</tags>
</to>
<container>
<ports>
<port>1408</port>
<port>7001</port>
</ports>
</container>
<containerizingmode>packaged</containerizingmode>
</configuration>
<executions>
<execution>
<goals>
<goal>dockerBuild</goal>
</goals>
<phase>package</phase>
</execution>
</executions>
</plugin>
</plugins>
</build>
</profile>
</profiles>
この構成により、ベース・イメージとして「distroless」Java 11イメージを使用した、Mavenビルド・アーティファクト(この場合はtodo-list-server)と同じ名前およびバージョンのイメージを作成します。また、ポート1408(gRPC用)と7001(アプリケーションが使用するRESTエンドポイント用)を公開します。
これでJibプラグインが構成されたので、ローカルでDockerイメージをビルドするのは、簡単な2段階の手順になります。まず、次のコマンドを実行し、アプリケーションをビルドしてそのアーティファクトをローカルのMavenリポジトリにインストールする必要があります。
$ mvn clean install
インストールが済むと、次のコマンドを実行してイメージをビルドすることができます。
$ mvn package -Pdocker
重要な警告:必ず、Dockerデーモンをローカルで実行してください。実行されていない場合、上記の手順は失敗します。
すべてがうまくいけば、Mavenログに次のように出力されるはずです。
[INFO] --- jib-maven-plugin:2.6.0:dockerBuild (default) @ todo-list-server ---
[INFO]
[INFO] Containerizing application to Docker daemon as todo-list-server, todo-list-server:1.0.0-SNAPSHOT...
[INFO] Using base image with digest: sha256:b25c7a4f771209c2899b6c8a24fda89612b5e55200ab14aa10428f60fd5ef1d1
[INFO]
[INFO] Container entrypoint set to [java, -cp, /app/classpath/*:/app/libs/*, io.helidon.microprofile.cdi.Main]
[INFO]
[INFO] Built image to Docker daemon as todo-list-server, todo-list-server:1.0.0-SNAPSHOT
次のコマンドを実行して、イメージが作成されたことを確認することもできます。
$ docker images | grep todo-list-server
出力は次のようになります。
todo-list-server 1.0.0-SNAPSHOT 584a44a8539b 50 years ago 260MB
todo-list-server latest 584a44a8539b 50 years ago 260MB
なお、アプリケーションをリモートKubernetesクラスタで実行しようとしている場合は、ここで上記のイメージに適切なタグを付け、KubernetesクラスタがアクセスできるDockerリポジトリにプッシュすることができます。この操作には、通常のDockerツールを使用します。ローカルKubernetesクラスタでアプリケーションを実行したいだけなら、すでに準備は整っているはずです。
ローカルでDockerイメージを実行し、http://localhost:7001/にアクセスすると、テストを行うことができます。この点は、前回までの記事でIDEやコマンドラインから実行したときと同じです。たとえば、次のようにします。
$ docker run -p 7001:7001 todo-list-server
ターミナル・ウィンドウにおなじみのログが出力され、見覚えのあるUIが表示されて、タスクの作成、編集、完了を行うことができるはずです。
Kubernetes へのアプリケーションのデプロイ
Coherence CEアプリケーションをKubernetesにデプロイする、格段に容易な(そして推奨される)方法は、その目的で設計されたGoベースのアプリケーションであるCoherence Operatorを使うことです。
Coherence Operatorでは、Coherenceをデプロイするためのカスタム・リソース定義(CRD)を定義します。この定義によって、正確なCoherenceクラスタの構成、スケーリング、管理全般がとても簡単になります。
たとえば、Coherence Operatorでは、Coherenceクラスタ・メンバー間の相互検出が可能なヘッドレス・サービス、公開したい外部エンドポイント用のサービス、Coherenceメンバーが完全に初期化されてリクエストを受け取る準備ができているかどうかを確認するReadinessプローブなど(その他にも多数あります)が自動構成されます。つまり、KubernetesでCoherenceを実行する必要がある場合は、Coherence Operatorを使用すべきだということです。
Coherence Operatorをインストールする一番簡単な方法は、KubernetesのHelmパッケージ・モニターを使うことです。
最初の手順として次のコマンドを実行し、ローカルのHelm構成にCoherence Helmリポジトリを追加します。
$ helm repo add coherence https://oracle.github.io/coherence-operator/charts
$ helm repo update
次の手順はCoherence Operatorのインストールです。この手順は、Helm 2またはHelm 3のどちらを使っているかによって異なります。Helm 2を使っている場合は、次のコマンドを実行します。
$ helm install --name coherence-operator coherence/coherence-operator
Helm 3を使っている場合は、--nameフラグを省略できます。たとえば、次のようにします。
$ helm install coherence-operator coherence/coherence-operator
Coherence Operatorがインストールされると、インストール完了を示すメッセージが表示されます。次のコマンドを実行し、その下に示すような内容が出力されることを確認して、インストールを検証することもできます。
$ kubectl get deployments
NAME READY UP-TO-DATE AVAILABLE AGE
coherence-operator-controller-manager 1/1 1 1 31d
Coherence Operatorが稼働すると、To Doリスト・アプリケーションをデプロイする準備は完了です。最初の手順は、Coherenceのデプロイに使うYAMLファイルを次のような内容で作成することです。
apiVersion: coherence.oracle.com/v1
kind: Coherence
metadata:
name: todo-list
spec:
replicas: 1
image: todo-list-server:latest
application:
type: helidon
jvm:
memory:
heapSize: 2g
ports:
- name: grpc
port: 1408
- name: http
port: 7001
serviceMonitor:
enabled: true
このリソースについて説明します。
apiVersion属性とkind属性の値は、Coherence OperatorでインストールされたカスタムCRDを参照しており、Coherence Operatorによる上記のCoherenceデプロイメント・リソースの処理をトリガーします。metadata/name属性は、前項以外で唯一の必須情報です。このCoherenceデプロイのKubernetesの識別子として使われます。spec/cluster属性によって上書きされない場合は、Coherenceクラスタの名前としても使われます。
spec要素に含まれるその他の属性の内容は、名前からすぐにわかるはずです。
replicas属性では、起動するCoherenceクラスタ・メンバーの数を定義しています。image属性では、先ほど作成したDockerイメージを使うことをKubernetesに伝えます(イメージにタグを付けてDockerリポジトリにプッシュした場合は、ここを適切に書き換える必要があります)。jvm/memory/heapSize属性では、各クラスタ・メンバーの初期ヒープ・サイズと最大ヒープ・サイズを2 GBに設定することをCoherence Operatorに伝えます。application/type属性では、これがHelidonアプリケーションであることをCoherence Operatorに伝えます。その結果、各クラスタ・メンバーを起動する際に、通常のスタンドアロンCoherenceデプロイに使われるDefaultCacheServerクラスではなく、デフォルトのHelidonメイン・クラスが使われるようになります。- 最後に、このリソースではポート1408と7001を公開し、gRPCとHTTP/RESTのエンドポイントをそれぞれ提供します。その際、Kubernetesサービス
todo-list-grpcとtodo-list-http(これらのサービス名は、Coherenceデプロイ名にポート名を追加するというデフォルトのサービス・ネーミング規則に基づいています)がそれぞれ使用されます。また、サービス・モニターを有効化し、HTTPポートを通して各クラスタ・メンバーから指標を取得することをPrometheusに伝えます。
Coherence Operatorをインストールし、先ほどの内容のapp.yamlファイルを準備すると、次のコマンドを実行してアプリケーションをインストールできるようになります。
$ kubectl apply -f java/server/src/main/k8s/app.yaml
coherence.coherence.oracle.com/todo-list created
先ほどのCoherenceデプロイメント・リソースに基づき、Coherence Operatorによって実際に作成されたものを確認してみましょう。
まず、次のコマンドを実行すると、Coherenceデプロイ自体の詳細を確認できます。
$ kubectl get coherence
NAME CLUSTER ROLE REPLICAS READY PHASE
todo-list todo-list todo-list 1 1 Ready
上記の出力は、デプロイ名、クラスタ名、ロールがすべてデフォルトのtodo-listであることを示しています。また、クラスタには準備完了のメンバーが1つ存在します。次のコマンドを使って、このCoherenceデプロイの裏にあるものを確認してみましょう。
$ kubectl get all
NAME READY STATUS RESTARTS AGE
pod/todo-list-0 1/1 Running 0 8m52s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S)
service/todo-list-grpc ClusterIP 10.96.13.213
1408/TCP
service/todo-list-http ClusterIP 10.96.89.213
7001/TCP
service/todo-list-sts ClusterIP None
7/TCP
service/todo-list-wka ClusterIP None
7/TCP
NAME READY AGE
statefulset.apps/todo-list 1/1 8m52s
おわかりのように、Coherenceデプロイのバックエンドとしてステートフル・セットが存在します。そのため、クラスタ・メンバーに対応した、信頼できる永続ストレージを構成できるようになっています。実際の構成は後ほど行います。
Coherence Operatorで作成された4つのKubernetesサービスも存在します。最初の2つは期待したとおりのもので、デプロイメント・リソースに基づいており、各クラスタ・メンバーが提供するgRPCエンドポイントとHTTPエンドポイントにアクセスできるようにしています。残りの2つは、Coherence Operatorで自動作成されたヘッドレス・サービスで、ステートフル・セットのメンバーと、新しいメンバーがCoherenceクラスタに参加できるようにするWell-Knownアドレス(WKA)リストを追跡するものです。少なくとも現時点では、この2つの追跡サービスが存在することは無視して構いません。
Coherence クラスタのスケーリング
この時点で、ステートフル・セットのポッドは1つだけです。しかし、次のコマンドでクラスタをスケーリングすると、そうではなくなります。
$ kubectl scale coherence todo-list --replicas 10
coherence.coherence.oracle.com/todo-list scaled
追加される9つのメンバーが起動してクラスタに参加するまでに1~2分ほどかかるかもしれません。しかし、いったんすべてが稼働してしまえば、次のコマンドを実行して同様の出力を確認できるはずです。
$ kubectl get coherence
NAME CLUSTER ROLE REPLICAS READY PHASE
todo-list todo-list todo-list 10 10 Ready
$ kubectl get all
NAME READY STATUS RESTARTS AGE
pod/todo-list-0 1/1 Running 0 46m
pod/todo-list-1 1/1 Running 0 2m56s
pod/todo-list-2 1/1 Running 0 2m55s
pod/todo-list-3 1/1 Running 0 2m55s
pod/todo-list-4 1/1 Running 0 2m55s
pod/todo-list-5 1/1 Running 0 2m55s
pod/todo-list-6 1/1 Running 0 2m55s
pod/todo-list-7 1/1 Running 0 2m55s
pod/todo-list-8 1/1 Running 0 2m55s
pod/todo-list-9 1/1 Running 0 2m55s
NAME READY AGE
statefulset.apps/todo-list 10/10 46m
そうです。Coherenceではステートフルなワークロードをステートレスなワークロードと同じように簡単にスケーリングできるというのはこのことです。上記のポッド10個それぞれでは、着信するRESTやgRPCのリクエストに対応するだけでなく、アプリケーションが管理するデータのおよそ10分の1を保存します。
ここでのポイントは、出力を一定程度は管理できる状態を維持するために、スケーリング後のノード数を10にとどめた点です。使用しているKubernetesクラスタに十分な容量がある限り、メンバー数を100や500、あるいは1,000へと容易にスケーリングすることができます。なお、Kubernetesではノードあたりのポッド数が100に制限されているので、その制限を決して超えないようにする必要がある点に注意してください。つまり、大きなCoherenceクラスタを実行するには、かなり大きなKubernetesクラスタが必要になります。
それぞれのメンバーを大きくしてスケールアップを実現することも可能です。たとえば、メンバーのヒープ・サイズを2 GBから20 GBに変更すれば、メンバー数を変えることなく、クラスタのストレージ容量を10倍に増やすことができます。
データ・ストレージと処理のニーズとのバランスをとるために、さまざまなクラスタのサイズと各メンバーのサイズを試すことができます。メンバーの数が増えるほど、HTTPやgRPCのリクエストの負荷が分散されるJVMの数も増えます。一方、各メンバーが大きくなるほど、そこに保存できるデータも多くなります。
ただし、トレードオフについて理解しておくことも重要です。クラスタが大きくなる(メンバーの数が増える)ほど、消費するリソースや、作成されて収集される監視データが増加し、管理が困難になりがちです。
しかしその一方で、クラスタが小さすぎる場合(たとえば、メンバー数が2~4で、それぞれが大量のデータを保持している場合)に1つのメンバーが停止すると、フェールオーバーして残りのメンバーでデータを均等化し直すための時間が非常に長くなる可能性があります。データセットの3分の1をフェールオーバーして均等化し直すには、データセットの13分の1を対象にするよりもはるかに高いコストがかかります。
アプリケーションへのアクセス
これでアプリケーションは稼働しました。しかし、どうすればこのアプリケーションにアクセスできるでしょうか。一番簡単な方法は、Kubernetesのポート・フォワードを使って、ローカルのポートを、作成したHTTPサービスとgRPCサービスに転送することです。簡単なテストを行う場合は、この方法で十分です。たとえば、次のようにします。
$ kubectl port-forward service/todo-list-http 7001:7001
$ kubectl port-forward service/todo-list-grpc 1408:1408
どちらのコマンドでもターミナルがブロックされるので、別のターミナル・ウィンドウまたはタブで実行する必要があります。バックグラウンドで実行することもできますが、出力を確認できなくなるので、お勧めしません。また、Kubernetesによって転送された接続にはかなり頻繁に切断されるという性質があるので、切断された場合に再接続が必要となる可能性があることを覚えておいてください。
上記のポート・フォワードを行うと、以前に使ったものと同じローカルのエンドポイントを通して、JavaFXクライアントからWebフロントエンドへのアクセスとgRPCエンドポイントへのアクセスの両方が可能になるはずです。
実稼働環境のアプリケーションを実行するうえで、ポート・フォワードを行うべきではないことは明らかです。代わりに使う方法は、Ingressコントローラを通じてアプリケーションを公開することでしょう(通常は、コントローラの前にロードバランサを配置します)。
これを厳密にどう行うかは、本記事の範囲外です。とは言え簡単に紹介すると、NginxでKubernetesクラスタ用のIngressコントローラを構成している場合、次のような定義を使って、HTTPとgRPC両方のエンドポイント用のIngressを作成することができるはずです。
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: http-ingress
spec:
rules:
- host: tasks.seovic.com
http:
paths:
- backend:
serviceName: todo-list-http
servicePort: 7001
---
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: grpc-ingress
annotations:
nginx.ingress.kubernetes.io/backend-protocol: "GRPC"
spec:
rules:
- host: grpc.tasks.seovic.com
http:
paths:
- backend:
serviceName: todo-list-grpc
servicePort: 1408
構成を完了するには、上記ホスト(実際には、所有するドメイン名を使います)が、Ingressコントローラの前にあるロードバランサを指すように、DNSのAレコードを作成する必要があるでしょう。
再起動しても失われないデータ永続化の構成
ここまでで、複数のVMやマシン、場合によってはクラウドの可用性ゾーンやドメインにわたってデプロイされた、メンバー数10のクラスタが稼働しました。これにより、個々のメンバーだけでなく、可用性ゾーンやドメインの全体の障害にも耐性があるアプリケーションが実現します。その理由は、Coherenceではデフォルトの動作として、データのプライマリ・コピーからできるだけ遠いところにバックアップを作成するからです。可用性ゾーンA、B、Cにわたるクラスタがある場合、ゾーンAのメンバーが所有するプライマリ・コピーのバックアップは、ゾーンBまたはCに格納されます。これは、Kubernetesでゾーンを表すメタデータが適切に構成されている限り、全自動で行われます。
ただし、アプリケーションのデータがメモリにのみ格納され、利用できるのはクラスタが稼働している間のみである点は変わりません。クラスタ全体をシャットダウンすれば、すべてのデータが失われます。特に、本記事の例のようなTo Doリスト・アプリケーションでは、このような動作が望ましいということはめったにありません。
クラスタが再起動してもデータが失われないようにする方法は2つあります。
- リレーショナル・データベースやキーバリュー・ストアのような永続データストアにデータを自動的に書き込み、必要に応じてロードします。これはCoherenceキャッシュ・ストア・メカニズムによって確かに実現できますが、外部データストアのセットアップが必要になるため、今回のアプリケーションでは理想的とは言えません。作成したステートフル・アプリケーションのメリットとシンプルさが一部失われてしまうことになります。
- Coherenceの永続化を有効にし、永続ディスク・ボリュームを、デプロイのバックエンドとなるステートフル・セット内の各ポッドにアタッチするようアプリケーションを構成します。こうすることで、Coherence自体がすべてのデータを、クラウド・プロバイダが管理するディスク・ボリュームに永続化するようになります。再起動時、このディスク・ボリュームは正しいポッドに再アタッチされます。こちらがこのプロジェクトに最適な方法なので、詳しく説明します。
Coherenceの永続化を有効にし、クラウド・プロバイダに対し、ディスク・ボリュームをステートフル・ポッドにアタッチするように指示するため、app.yamlファイルに次の内容のcoherenceセクションを追加します。
spec:
# insert before jvm section
coherence:
persistence:
mode: active
persistentVolumeClaim:
storageClassName: "oci-bv"
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 50Gi
この構成により、Coherenceの永続性モードがactiveになります。デフォルトはon-demandで、その場合、データが変更されるたびにディスクに書き込まれます。また、Coherence Operatorに対し、oci-bv(OCI Block Volume)ストレージ・クラスを使って各クラスタ・メンバーに50 GBの永続ボリューム・ストレージを割り当てるように指示する設定も含まれています。
注:この例では、アプリケーションをOracle Container Engine for Kubernetesで実行しています。ストレージ・クラスにoci-bvを指定したのはそのためです。別のクラウド・プロバイダを使用している場合は、ストレージ・クラス名を適切に変更する必要があります。
永続化は、クラスタ全体に影響を与える数少ない機能の1つで、実行時に変更することはできません。そのため、上記の変更を適用するには、次のようにしてアプリケーションを再デプロイする必要があります。
$ kubectl delete -f java/server/src/main/k8s/app.yaml
coherence.coherence.oracle.com "todo-list" deleted
$ kubectl apply -f java/server/src/main/k8s/app.yaml
coherence.coherence.oracle.com/todo-list created
再度すべてが稼働したら、(唯一の)クラスタ・メンバーに対してPersistentVolumeClaim(PVC)が作成されたことを確認できます。たとえば、次のようにします。
$ kubectl get pvc
NAME STATUS VOLUME CAPACITY STORAGECLASS
persistence-volume-todo-list-0 Bound csi-… 50Gi oci-bv
同様に、クラスタをメンバー数10にスケーリングし直すと、次に示すように、それぞれのメンバーにも50 GBのPVCがアタッチされているはずです。
$ k scale coherence todo-list --replicas 10
coherence.coherence.oracle.com/todo-list scaled
$ kubectl get pvc
NAME STATUS VOLUME CAPACITY STORAGECLASS
persistence-volume-todo-list-0 Bound csi-… 50Gi oci-bv
persistence-volume-todo-list-1 Bound csi-… 50Gi oci-bv
persistence-volume-todo-list-2 Bound csi-… 50Gi oci-bv
persistence-volume-todo-list-3 Bound csi-… 50Gi oci-bv
persistence-volume-todo-list-4 Bound csi-… 50Gi oci-bv
persistence-volume-todo-list-5 Bound csi-… 50Gi oci-bv
persistence-volume-todo-list-6 Bound csi-… 50Gi oci-bv
persistence-volume-todo-list-7 Bound csi-… 50Gi oci-bv
persistence-volume-todo-list-8 Bound csi-… 50Gi oci-bv
persistence-volume-todo-list-9 Bound csi-… 50Gi oci-bv
次のコマンドを実行すると、ポッドがPVCをマウントしたことを検証できます。
$ kubectl describe pod todo-list-0
そして、「Mounts:」セクションに永続ボリューム・マウントが表示されていることを確認します。
/coherence-operator/persistence from persistence-volume (rw)
「Volumes:」セクションには、対応するボリューム定義が表示されます。
persistence-volume:
Type: PersistentVolumeClaim
ClaimName: persistence-volume-todo-list-0
ReadOnly: false
実際に永続化が期待どおりに動作しているかどうかを確認する一番簡単な方法は、いくつかのタスクを作成して一部を完了させた後、次のコマンドを使ってクラスタをメンバー数0にスケールダウンすることです。
$ k scale coherence todo-list --replicas 0
これにより、すべてのメンバーが事実上シャットダウンされ、Coherenceデプロイのすべてのポッドが終了します。すべてのポッドが終了したことを確認したら、クラスタをメンバー数10にスケーリングし直し、UIを更新します(先ほどのシャットダウンで接続が切断されている可能性が高いので、再度ポート・フォワードを行う必要があるかもしれません)。すべてのデータが、クラスタをシャットダウンする前とまったく同じように表示されるはずです。
YAMLを少し変更して永続化を有効にすることで、耐久性のあるステートフルなアプリケーションができました。このアプリケーションは、ステートレスなアプリケーションと同じ手軽さで、数百のJVM、メンバー、ポッドにスケーリングすることができます。
監視とトレースの構成
アプリケーションが稼働し、簡単にスケール・アウトやスケールアップを行って負荷の増加に対応できるのはありがたいことです。しかし、このアプリケーションは複雑な分散システムのままです。アプリケーションの内部で起きていることを監視し、避けられない問題が発生した場合はその問題に対処できることが必要です。
Coherenceでは、監視を行うための仕組みがいくつか提供されています。
- Java Management Extensions経由およびOpenMetrics対応のHTTPエンドポイント経由で公開される指標の監視:Prometheusなどのツールによる監視が可能
- 組込みのGrafanaダッシュボード:上記の指標の視覚化が可能
- OpenTracingによる情報のトレース:システムでの個々のリクエストの流れを細かく把握できるため、パフォーマンスのボトルネックを理解して修正することが可能
最初の2つには後ほど触れるので、ここでは主に3つ目のトレースについて解説します。
Oracle Coherenceコア開発チームでの筆者の同僚で、CoherenceのOpenTracingサポートの大半を実装したRyan Lubkeが、すばらしい一連の記事を書いており、そこでOpenTracingの動作の仕組みや、他の技術との統合方法について説明しています。ぜひお読みいただきたいと思いますが、Helidonアプリケーションに関する部分についてポイントをまとめたいと思います。これにより、多くのことが少しだけシンプルになります。
HelidonとCoherenceでは、どちらもそのままの状態でOpenTracingをサポートしています。アプリケーションを少し変更するだけで、OpenTracingが有効になります。
まず、トレース情報公開の対象とするサービスの名前を指定します。これを行うのは簡単です。サーバー・プロジェクトのMETA-INF/microprofile-config.propertiesファイルに次の行を追加します。
service.name=Tasks
また、使用したいOpenTracingライブラリへの依存性を追加する必要もあります。HelidonはZipkinとJaegerの両方をサポートしていますが、今回のアプリケーションでは後者を選択しました。Jaegerを有効化するために、次のようにしてPOMファイルに依存性を1つ追加します。
<dependency>
<groupid>io.helidon.tracing</groupid>
<artifactid>helidon-tracing-jaeger</artifactid>
</dependency>
アプリケーション側で行うことはこれだけです。以上2つのささいな変更により、HelidonアプリケーションがすべてのRESTリクエストをCoherenceに到達するまでずっとトレースするようになり、Helidonが開始した既存のトレースにCoherence用のスパンが単純に追加されます。
上記の変更を行うと、アプリケーションを再ビルドし、再パッケージ化してDockerイメージを作成することができますが、デプロイする前に、Kubernetesのデプロイメント・リソースに次の変更を行う必要があります。
spec:
# insert before 'application' section
env:
- name: TRACING_HOST
value: "jaeger-collector"
- name: JAEGER_SAMPLER_TYPE
value: "const"
- name: JAEGER_SAMPLER_PARAM
value: "1"
実際に必要なものは、最初の環境変数TRACING_HOSTだけです。この環境変数では、Jaegerクライアントがトレース情報を公開する場所を指定します。
その他2つの環境変数は、Jaegerクライアントのデフォルト動作を変更し、リクエストの一部のサンプルだけではなく、リクエストの都度トレース情報を公開するようにするためのものです。これは実稼働環境で行うものではありませんが、アプリケーションでトレースのサポートのデモを行う場合には大変便利です。
最後に必要なのは、トレース情報の公開先として使用できるJaegerインスタンスが稼働しているようにすることです。Jaegerのセットアップは本記事の範囲外ですが、こちらの手順に従うと、KubernetesクラスタにJaeger Operatorをインストールすることができます。インストールが済んだら、アプリケーション用のJaegerインスタンスを作成します。この操作は、次のコマンドを実行するだけで簡単に行うことができます。
$ kubectl apply -f java/server/src/main/k8s/jaeger.yaml
Ingressコントローラを使っている場合は、jaeger-queryサービス用のIngressの構成も必要です。次のようにしてください。
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: jaeger-ingress
spec:
rules:
- host: jaeger.seovic.com
http:
paths:
- backend:
serviceName: jaeger-query
servicePort: 16686
Jaegerが稼働している状態で最新バージョンのアプリケーションをデプロイし、いくつかのタスクを作成、完了、削除すると、内部で何が行われているかをJaegerのUIで確認することができます。 たとえば、あるGET /api/tasksリクエストのトレース(図2参照)からは、Java API for RESTful Web Services(JAX-RS)のToDoResource.getTasksメソッドが呼び出され、10のCoherenceメンバーすべてに並列に問合せが行われて、タスクのリストが取得されたことがはっきりとわかります。
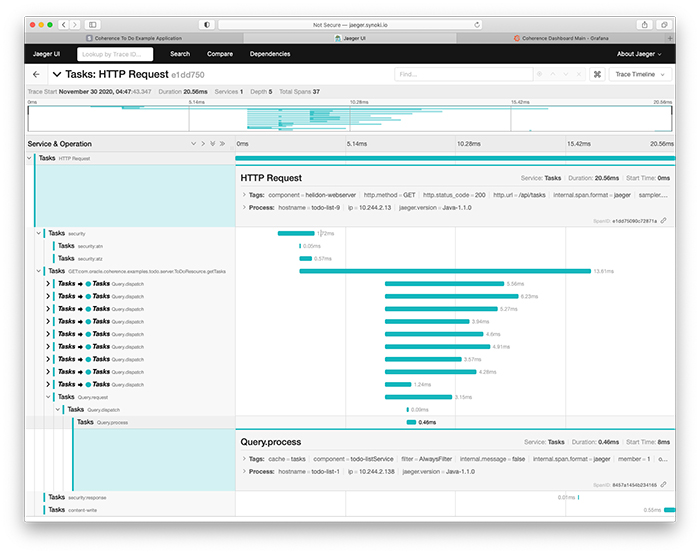
図2:すべてのタスクについての問合せ
図3では、POST /api/tasksリクエストによって新しいタスクが作成されると、ToDoResource.createTaskメソッドが呼び出され、新しく作成されたTaskのプライマリ所有者に対してPutリクエストが送信され、バックアップ・メンバーと永続ストア(ディスク)に並列に書き込みが行われていることが確認できます。
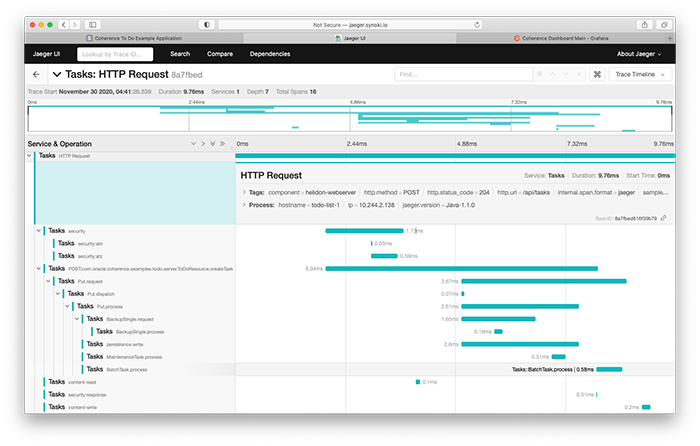
図3:タスクの作成
PUT /api/tasks/:idリクエストでタスクを更新した際に取得した同様のトレース(図4)もご覧ください。ToDoResource.updateTaskメソッドが呼び出され、エントリ・プロセッサを使ってプライマリ・メンバー(所有者)のタスクが更新されています。その後、プライマリ・メンバーは、Putリクエストの場合と同じように、バックアップと永続ストアを並列に更新しています。
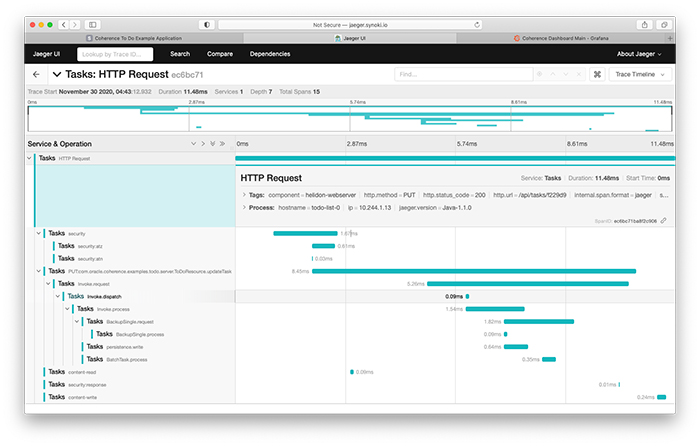
図4:タスクの更新
ご覧のように、REST APIエンドポイントからCoherenceの最深部とも言えるディスクの書込みまでの全域において、逐次的または並列にコードを実行し、場合によっては多数となるクラスタ・メンバーが対象となります。このレベルの可視性があれば、パフォーマンスの問題のトラブルシューティングを大いに簡略化することができます。この点は賛同していただけるでしょう。複雑な分散システムの内部で何が起こっているかを視覚化する場合にも役立ちます。また、起こっていると予想することが実際に起こっていると確かめることもできます。
個人的には、このレベルで内部動作の可視性が得られるプロダクトはあまり見たことがありません。
Prometheus と Grafana による監視
トレースは、システムでのリクエストの流れを把握し、パフォーマンスのボトルネックを正確に特定する場合に優れた手段となりますが、全体像を提供するものでないのは明らかです。たとえば、さまざまなキャッシュやマップの格納データ量、個々のクラスタ・メンバーやサービスの全般的な健全性、リクエストの頻度、データの増加率など(その他にも多数あります)、システム全体の健全性を正確に把握するためや、スケーリングなどに関して判断できるようにして長期にわたりシステムを良好に動作させるために確認が必要となる可能性があることについては、何もわかりません。
こういったことを把握するには、各時点における多数の指標を定期的に取得し、長期にわたって分析する必要があります。これはまさに、Prometheusなどの時系列データベースや、Grafanaなどの監視ダッシュボードが設計された理由です。PrometheusとGrafanaのセットアップについては、とても本記事で取り上げることはできませんが、WebにはPrometheus Operatorを使って両方を構成する際に役立つリソースが数多くあります。なお、PrometheusのServiceMonitorを有効化することを忘れないでください。Coherenceではこれを使ってPrometheusを構成し、Coherenceの各クラスタ・メンバーの/metricsエンドポイントからデータを収集するからです。
重要な注:Prometheusの稼働後にアプリケーションをデプロイしないと、アプリケーションを削除して再デプロイしない限り、PrometheusがCoherenceメンバーからの指標収集を開始しない場合があります。
Coherenceの監視ダッシュボードをGrafanaにインポートする方法については、Coherence Operatorドキュメントの手順にも従う必要があります。
すべてが稼働してからGrafanaにログインしてCoherenceのメイン・ダッシュボードを開くと、図5のような画面が表示されるはずです。
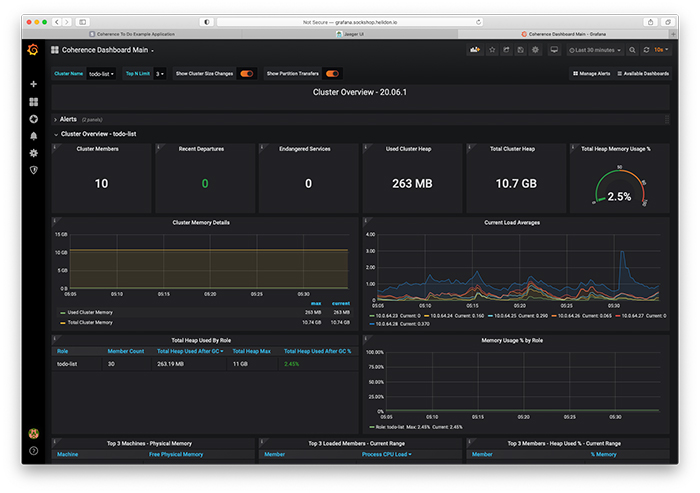
図5:Grafanaのクラスタ概要ダッシュボード
このダッシュボードでは、クラスタ・メンバーの合計数、クラスタ全体およびメンバーの役割ごとのヒープ使用状況、メンバーの平均負荷に加え、最近クラスタを離脱したメンバーの数や、危険な状態のサービス(バックアップされていないサービス)があるかどうかを一目で確認することができます。
「Cluster Members」ボックスをクリックすると、メンバーのサマリーを示すダッシュボードが開き、さらにメンバーの名前をクリックすると、個々のメンバーのダッシュボードを確認することができます。たとえば、todo-list-0メンバーのメンバー詳細ダッシュボードは、図6のようになります。
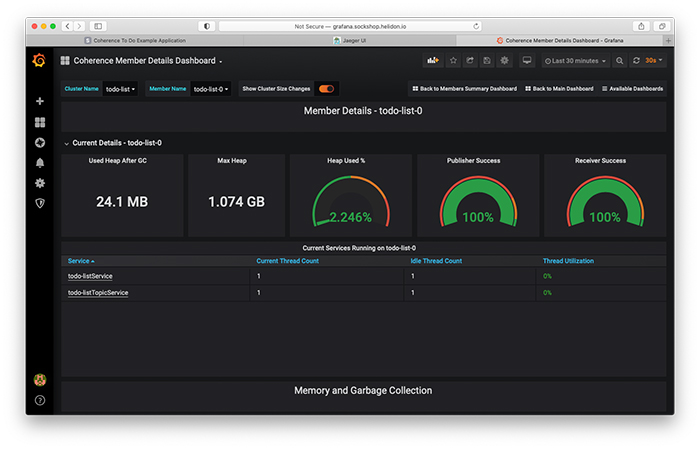
図6:todo-list-0のメンバー詳細ダッシュボード
メンバー詳細ダッシュボードでは、そのメンバーのヒープ使用状況、スレッド使用状況、ガベージ・コレクション情報のほか、パブリッシャとレシーバの成功率(このメンバーと他のメンバーとの間におけるネットワークの質を示し、100 %に近いほど良好となります)を確認することができます。
図7のサービス・サマリー・ダッシュボードでは、Coherenceの各サービスの状態を確認できます。
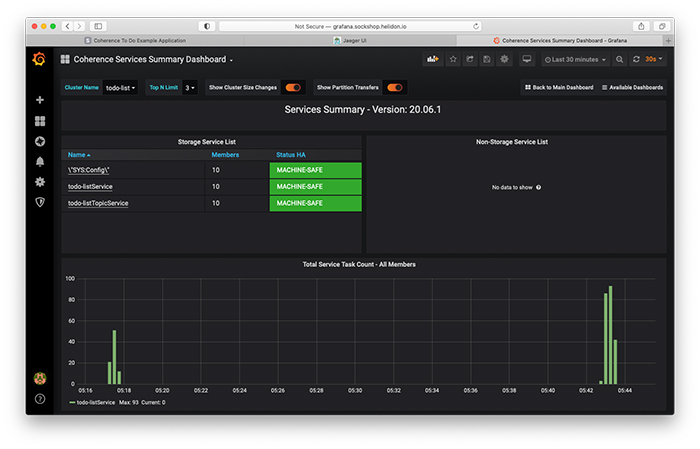
図7:サービス・サマリー・ダッシュボード
図7では、一番注視すべきアプリケーション・サービスであるtodo-listServiceが10のメンバーすべてで動作しており、MACHINE-SAFE状態になっています。これは、Kubernetesクラスタで6台の仮想マシンのどれが失われても、データが喪失しないことを表しています。タスク実行の時間分布に注目すると、もっとも高負荷となったタイミングを確認することもできます。
「todo-listService」リンクをクリックすると、このサービスのサービス詳細ダッシュボード(図8)が表示されます。
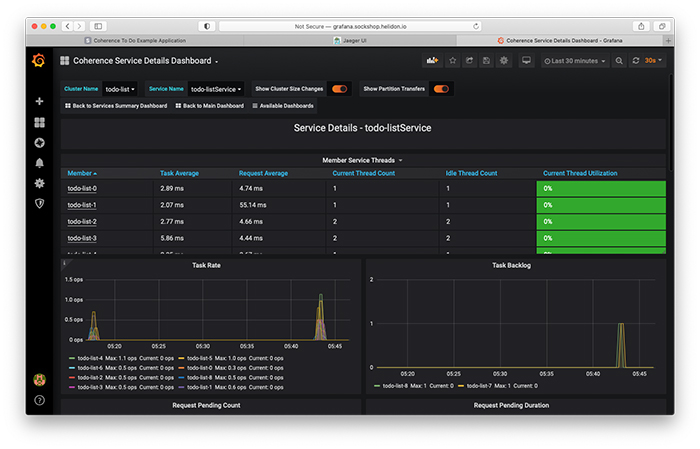
図8:サービス詳細ダッシュボード
メンバーごとに、サービスの平均タスク時間および平均リクエスト時間、スレッド使用状況に関する情報、タスクの頻度およびバックログを確認することができます。
キャッシュ詳細ダッシュボード(図9)には、管理対象となっているタスクの合計数、タスクが使用しているメモリの量、インデックスのサイズ(存在する場合)が表示されます。また、問合せの所要時間に関する情報、キャッシュで使用されたメモリ量の時間変化、クラスタ・メンバー間におけるエントリの分散およびアクセスの状況も確認できます。
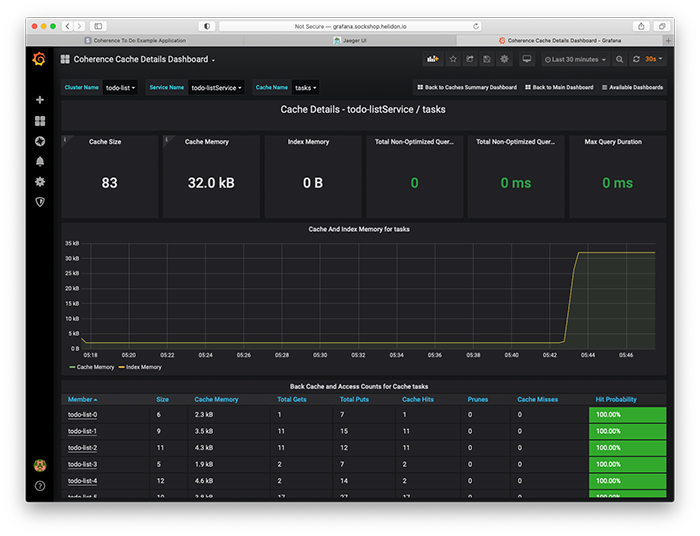
図9:キャッシュ詳細ダッシュボード
最後の永続化サマリー・ダッシュボード(図10)では、アプリケーションで管理されているデータが使用しているディスク領域や、利用可能なディスク領域の容量を確認できます。
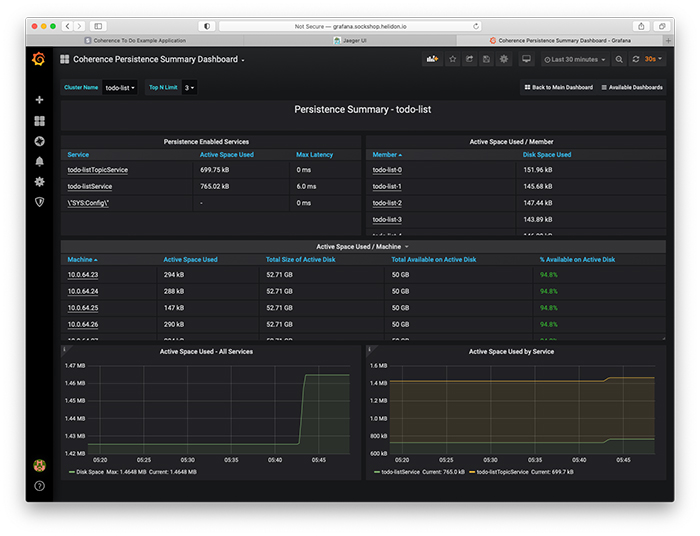
図10:永続化サマリー・ダッシュボード
Coherenceで提供されているダッシュボードはこれだけではありませんが、ここでは今回のアプリケーションにとって特に便利なものを紹介しました。ほぼすべてのアプリケーションにとってもおそらく便利であるため、親しんでおく価値があります。
おわかりのように、こういったツールでは、そのままの状態でも便利な情報を数多く提供してくれます。また、必要に応じてツールをカスタマイズし、注目する情報に絞って提供されるようにすることもできます。
まとめ
本記事でこのシリーズは完結となります。正直なところ、考えていたよりも少しばかり長くなり、多岐にわたることになりました。シリーズ全体についても同じことが言えます。もともとは1本の記事にする予定でした。[編集注:驚きです。]
Oracle Coherence Community Editionが、レジリエントでスケーリングしやすいステートフルなサービスやアプリケーションを構築するうえでどれほど役立つかを理解していただければ幸いです。ご自身のアプリケーションを実装する場合は、今回のサンプル・アプリケーションのコードをガイドとして自由にお使いください。質問がある方は、直接連絡いただくか、Coherenceの公式ソーシャル・メディア・チャネルのいずれかをお使いください。すべてCoherence CEのWebサイトに掲載されています。
最後に、Coherence CEでどこまでできるかを感じていただくため、図11をお見せします。
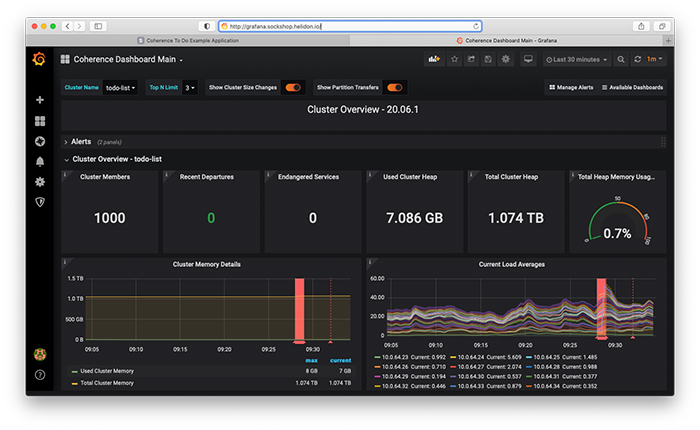
図11:メンバー数1,000のCoherenceクラスタ
悪くはないと思いませんか?
さらに詳しく
- Coherence Community Editionが登場:スケーラブルでクラウド・ネイティブなステートフル・アプリケーションの作成(パート1)
- Coherence Community Editionが登場(パート2):クライアントの構築
- Helidon:シンプルなクラウド・ネイティブ・フレームワーク
- Kubernetesを使ってみる(英語)
- OpenTracingでCoherenceの内部を見る(英語)
- Coherence Community Edition(英語)

