※本記事は、Angie Jones による “Modern Java toys that boost productivity, from type inference to text blocks” を翻訳したものです。
古いバージョンのJavaプラットフォームを使っている開発者は損をしている
October 23, 2020
Javaは業界で特に広く使われているプログラミング言語の1つですが、長年にわたり、冗長で不活性だという不当な悪評を買ってきました。確かに、もっとも基本的なことをするために大量のコードを書かなければならないこともあります。そして確かに、Java 7、8、9のリリース間隔はそれぞれ約3年でした。ソフトウェア開発の世界で3年というのは、とてつもなく長い時間です。
ありがたいことに、その声は聞き届けられました。Javaは待望の変化を遂げ、新しいバージョンの言語仕様が6か月ごとにリリースされるようになりました。最新バージョンは、2020年9月にリリースされたJava 15です。(※編集部注:2021年3月にJava 16がリリースされています。)
Javaプラットフォームには非常に多くの機能があるので、ついていくのが難しいかもしれません。特に、アプリケーションを高速化し、書きやすくすることができる機能を見つけるのは大変でしょう。そこで本記事では、筆者が特に便利だと感じたJavaの新機能をいくつか紹介します。
ローカル変数の型推論
次の例では、Javaの規則に従い、クラスとオブジェクトの両方にわかりやすい名前を付けています。
AccountsOverviewPage accountsOverviewPage = page.login(username, password);
しかし、見ればわかるように、同じ2つの名前が繰り返されています。これは冗長で、多くの文字を入力することになります。
Javaのバージョン10では、ローカル変数の型推論が導入されました。つまり、オブジェクト、すなわち変数の型を明示的に宣言するのではなく、varキーワードを使用できるというものです。すると、代入するものからJavaが型を推論してくれます。次に例を示します。
var accountsOverviewPage = page.login(username, password);
この機能により、開発者による文字入力の手間が多少省けるとともに、言語の冗長性がいくらか減少します。
Javaが静的に型付けされた言語である点は変わらない:型推論を使っても、JavaがJavaScriptやPythonのような動的に型付けされた言語になるわけではありません。型が存在することは変わらず、型が文の右辺から推論されるだけのことです。つまり、varを使用できるのは、実際に変数を初期化する場合のみです。それ以外の場合、Javaでは型を推論できません。次の例をご覧ください。
var accountsOverviewPage; //コンバイル・エラーが発生
型推論ではグローバル変数の型は推論できない:「ローカル変数の型推論」という名前からわかるとおり、この機能はローカル変数でのみ動作します。varは、メソッド、ループ、決定構造の中で使用できます。しかし、変数を初期化している場合でも、グローバル変数でvarを使用することはできません。次のコードはエラーになります。
public class MyClass {
var accountsOverviewPage = page. login(username, password); //コンバイル・エラーが発生
}
型推論はヘッダーでは許可されない:ローカル変数の型推論をローカル構造の本体で使うことはできますが、次の例で示すように、メソッドやコンストラクタのヘッダーで使うことはできません。これは、送信する引数のデータ型をコール元が知る必要があるからです。
public class MyTests {
public MyTests(var data) {} //コンバイル・エラーが発生
}
型推論によってネーミングが今までに増して重要になっている:次の変数名とそれに続くメソッド名をご覧ください。xに対して推論されるデータ型が何になるかは、まったくわかりません。
Javaが型を知ることができるのは、getX()が返す内容に基づいて型を推論できるからです。しかし、コードを読む人は、getX()が何であるかを簡単に知ることはできません。そのため、この変数を扱うのが難しくなります。
適切な変数名を常に使うべきですが、varを使うとコンテキストの一部が削除されることになるので、ネーミングはさらに重要になります。
var x = getX();
すべてをvarにする必要はない:型推論は、一度使い始めればお気に入りの機能になるでしょう。しかし、過剰な利用は避けてください。
たとえば、次のようにvarを使っても、何の役にも立ちません。適切な理由なくコンテキストを削除することになるからです。
var numberOfAccounts = 5;
曖昧さにつながる可能性に注意する:次の宣言で推論される型は何でしょうか。
var expectedAccountIdsList = new ArrayList();
ObjectのArrayListだと思った方は、正解です。
これでも問題ない場合は多いものの、コレクションの要素に対してドット演算子(.)を使いたい場合は、Objectクラスで利用できるメソッドしか使えないことになります。
もう少し具体的な推論を行うには、代入の右辺にできる限り多くの情報を含めます。たとえば、ダイヤモンド演算子を使ってString型を指定すると、expectedAccountIdsListがStringのArrayListとして定義されるようになります。
var expectedAccountIdsList = new ArrayList<String>();
ストリームの効率を向上させる新しい操作
Java 9では、Stream APIに2つの新しい操作、takeWhileとdropWhileが導入されました。
takeWhile()操作では、コレクションのアイテムを処理し、与えられた条件(predicate)がtrueである間、そのアイテムを保持します。dropWhile()操作では、その逆となり、条件がtrueである間はコレクションのアイテムを無視します。
下記の例では、口座のリストを取得した後、takeWhile()を使って、タイプがCHECKINGである口座をすべて保持しています。ただし、コードがこのタイプでない口座に到達すると、そこで処理が終了します。
var accountsList = APIUtil.getAccounts(customerId);
var checkingAccountsList = accountsList
.stream()
.takeWhile(account -> account.type().equals("CHECKING"))
.collect(Collectors.toList());
図1に示す口座リストを対象にした場合、タイプがCHECKINGに等しいことを条件としてtakeWhile()を呼び出すと、最初の3つのエントリが保持されます。条件に一致するエントリは他にもありますが、条件を満たさなくなった時点でストリームが終了します。4つ目の要素のタイプはSAVINGSなので、この要素に到達した時点でストリームは終わりになります。
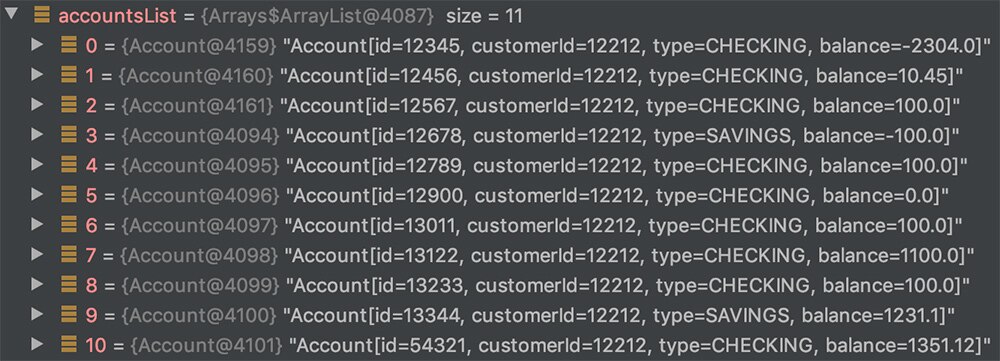
図1:銀行口座のリスト
同じように(ただし逆の状況です)、このストリームに対してdropWhile()を呼び出すと、インデックスが3~10の要素が保持されます。dropWhile()では、最初の3つのエントリを削除します。この3つは条件に一致したからです。そしてタイプがSAVINGSである4番目の要素に到達すると、ストリームが始まります。
var accountsList = APIUtil.getAccounts(customerId);
var checkingAccountsList = accountsList
.stream()
.dropWhile(account -> account.type().equals("CHECKING"))
.collect(Collectors.toList());
予測可能な結果を得るためにコレクションをソートする:条件に一致するすべての要素を収集または削除したい場合は必ず、takeWhile()またはdropWhile()を呼び出す前にストリームをソートします。たとえば、次のようにします。
var accountsList = APIUtil.getAccounts(customerId);
var checkingAccountsList = accountsList
.stream()
.sorted(Comparator.comparing(Account::type))
.takeWhile(account -> account.type().equals("CHECKING"))
.collect(Collectors.toList());
4行目のようにしてコレクションをソートすると、条件に一致するすべての要素が、期待したとおりに保持または削除されます。
takeWhileとfilterの違い:よくある質問に、「takeWhileとfilterはどう違うのか」というものがあります。この2つでは、どちらも条件を使ってストリームを絞り込みます。
違うのは、filter()操作ではコレクション全体を参照して条件に一致するすべての要素を収集するのに対し、takeWhile()では条件に一致しない要素が見つかると操作が中止され、収集プロセスが一部省かれる点です。そのため、takeWhile()の方が高速です。
並列ストリームでtakeWhileまたはdropWhileを使用する:takeWhile()またはdropWhile()を並列ストリームで使用すると、ストリームがソートされている場合でも、パフォーマンスが損なわれます。
最高のパフォーマンスを得るために、これらの操作はスタンドアロンのストリームで使用することをお勧めします。
switch式
Java 12で、switch式が導入されました。これにより、switchを使って直接値を変数に代入することができるようになっています。次の例で、変数idを初期化するために、文の右辺にswitchを使っていることに注目してください。
String id = switch(name) {
case "john" -> "12212";
case "mary" -> "4847474";
case "tom" -> "293743";
default -> "";
};
このコードは、名前がjohnであれば変数idに12212を代入することを表しています。
switch式ではcase文にコロンは必要ありませんが、代わりに矢印を使います。
switch式におけるフォールスルー:switch式にbreak文は必要ありません。switch式にはフォールスルーがないからです。これはswitch式を使うメリットの1つです。switch文でbreak文を忘れるというのはよくあるエラーで、予期しない動作につながります。switch式では、このエラーを回避できます。
しかし、1つのブロックで複数の条件値に対処した方がよいこともあります。その場合は、switch式の各条件値を、カンマで区切ったリストの形で指定します。次の例をご覧ください。
return switch(name) {
case "john", "demo" -> "12212";
case "mary" -> "4847474";
case "tom" -> "293743";
default -> "";
};
最初のケースでは、名前がjohnまたはdemoである場合に12212が返されることに注目してください。
switch式で追加のロジックを実行する:switch式の主な目的は値の代入ですが、その値を決定するための追加のロジックが必要になる場合もあるでしょう。
これを実現するために、switch式のcase文の中にコード・ブロック(波括弧で囲んだ文)を含めることができます。
ただし、switch式の最後の文はyield文である必要があります。この文では、代入する値を指定します。下記の例のjohnに対応するcase文をご覧ください。
return switch(name) {
case "john" -> {
System.out.println("Hi John");
yield "12212";
}
case "mary" -> "4847474";
case "tom" -> "293743";
default -> "";
};
switch式から例外をスローする:任意のcase文で例外をスローすることができます。
return switch(name){
case "john" -> "12212";
case "mary" -> "4847474";
case "tom" -> "293743";
default -> throw new InvalidNameException();
};
当然ですが、デフォルトのケースではフロー全体が例外によって中断されるので、値は返されません。
デフォルト以外のケースで例外をスローしても構いません。次に示すように、任意のcase文で例外をスローすることができます。
return switch(name){
case "john" -> "12212";
case "mary" -> throw new AccountClosedException();
case "tom" -> "293743";
default -> throw new InvalidNameException();
};
switch式を使うタイミング:switch 式 は言語に追加されたものであり、switch 文 を置き換えるものではありません。もちろんswitch文は引き続き使用できます。switch文の方がswitch式より適切な場合もあるでしょう。
経験則としては、値を代入するためにこの構造を使う場合はswitch式を使い、値を代入せずに条件に応じて文を呼び出す必要がある場合はswitch文を使います。
レコード
レコードは新しいタイプのクラスであり、Java 14でプレビュー機能として導入されました。レコードは、フィールドと、そのフィールドにアクセスする方法だけが必要となるシンプルなクラスに適した機能です。Accountのモデルとすることができるレコードを示します。
public record Account(
int id,
int customerId,
String type,
double balance) {}
classの代わりにrecordを使っていることに注意してください。また、クラス宣言に含まれる丸括弧内でフィールドが定義されており、その後に波括弧が続いています。
要するに、このシンプルな宣言により、丸括弧内で定義したフィールドを持つレコードが作成されます。getterやsetterを作成する必要はありません。equals()、hashCode()、toString()といった継承メソッドをオーバーライドする必要もありません。これらは、すべて自動的に行われます。
ただし、何かをオーバーライドしたい場合やメソッドを追加したい場合は、波括弧内で行うことができます。次に例を示します。
public record Account(
int id,
int customerId,
String type,
double balance
) {
@Override
public String toString(){
return "I've overridden this!";
}
}
レコードのインスタンス化:レコードは、クラスと同じようにインスタンス化することができます。次の例では、Accountがレコードの名前であり、newキーワードを使ってコンストラクタを呼び出し、すべての値を渡しています。
Account account = new Account(13344, 12212, "CHECKING", 4033.93);
レコードは不変:レコードのフィールドはfinalなので、setterメソッドは生成されません。もちろん、レコードの波括弧内にsetterを追加することはできますが、フィールドはfinalで変更することはできないので、そのようにするもっともな理由はありません。
Account account = new Account(13344, 12212, "CHECKING", 4033.93);
account.setType("SAVINGS"); //コンバイル・エラーが発生
同じ理由で、レコードをbuilderクラスとして直接使用することはできません。レコードのfinalフィールドを変更しようとすると、コンパイル・エラーになります。次の例をご覧ください。
public record Account(
int id,
int customerId,
String type,
double balance)
{
//コンバイル・エラーが発生
public Account withId(int id){
this.id = id;
}
}
アクセッサ・メソッド:レコードにはアクセッサ・メソッドがありますが、getで始まる名前ではありません。アクセッサ・メソッドの名前は、フィールド名と同じになります。下記で、account.getBalance()ではなく、account.balance()を呼び出している点に注意してください。
Account account = new Account(13344, 12212, "CHECKING", 4033.93);
double balance = account.balance();
継承はサポートされない:レコードはfinalなので、他のクラスやレコードから継承することはできません。次の例のように、レコードの宣言でextends句を使おうとすると、コンパイル・エラーになります。
public record CheckingAccount() extends Accounts {} //コンバイル・エラーが発生
レコードはインタフェースを実装可能:しかし、レコードではインタフェースを実装できます。クラスと同じように、レコードの宣言でimplementsキーワードを使用し、実装するインタフェースを指定すると、レコードの波括弧内でメソッドを実装できます。次の例をご覧ください。
public interface AccountInterface {
void someMethod();
}
public record Account(
int id,
int customerId,
String type,
double balance) implements AccountsInterface
{
public void someMethod(){
}
}
テキスト・ブロック
Java文字列で長く複雑なテキストのブロックを表現するのは、かなり面倒な作業になることがあります。次の例をご覧ください。どのようにしてすべての引用符をエスケープし、行末に改行文字を追加し、プラス記号で各行を結合する必要があるかに注目してください。
String response =
"[\n" +
" {\n" +
" \"id\": 13344,\n" +
" \"customerId\": 12212,\n" +
" \"type\": \"CHECKING\",\n" +
" \"balance\": 4022.93\n" +
" },\n" +
" {\n" +
" \"id\": 13455,\n" +
" \"customerId\": 12212,\n" +
" \"type\": \"CHECKING\",\n" +
" \"balance\": 1000\n" +
" }\n" +
"]";
Java 13で導入されたテキスト・ブロックを使うと、3つの引用符によって、長いテキストのブロックを開始および終了することができます。次の例をご覧ください。
return """
[
{
"id": 13344,
"customerId": 12212,
"type": "CHECKING",
"balance": 3821.93
},
{
"id": 13455,
"customerId": 12212,
"type": "LOAN",
"balance": 989
}
]
""";
何もエスケープする必要がないことに注目してください。フィールドは個々に引用符で囲まれたままとなり、改行も保持されます。
開始の引用符と同じ行からテキストを始めることはできない:同一行にテキスト・ブロック全体を含めることはできません。そうすると、コンパイル・エラーになります。次の例をご覧ください。
return """ Hey y'all! """; //コンバイル・エラーが発生
次の例で示すように、開始の引用符の後で改行する必要があります。下記のようにすることは認められていますが、推奨される形ではありません。
return """
Hey y'all!""";
推奨される形は、開始および終了の引用符の両方を、その間にある対象テキストとは異なる行にそれぞれ配置し、それらの引用符の位置と対象テキストの開始位置をそろえるというものです。次の例をご覧ください。
return """
Hey y'all!
""";
まとめ
本記事では、最近のバージョンのJavaで登場した、筆者お気に入りの新機能の中からほんの一部を紹介しました。おわかりのように、冗長性の回避やプログラミングの最新トレンドの採用という領域で、Java言語は確かに進化しています。愛すべきJavaに乾杯。
さらに詳しく
• varとJava 10で拡張された型推論
• Java 9で更新されたコア・ライブラリ:CollectionとStream
• Java 13のswitch式と再実装されたSocket APIの内側
• Javaにレコードが登場
• Javaにテキスト・ブロックが登場
Angie Jones:Java Champion。テスト自動化の戦略や技法を専門とする。世界中のソフトウェア・カンファレンスでの講演や指導を通して豊富な知識を発信するとともに、オンライン学習プラットフォームTest Automation Universityを主宰。革新的、独創的な思考スタイルを持つことでも知られ、米国と中国で25を超える特許を取得した発明の達人でもある。余暇には、テック業界に加わる女性やマイノリティを増やすための取り組みとして、少女向けのプログラミング・ワークショップBlack Girls Codeのボランティアとして指導に当たっている。
