※本記事は、Beda Hammerschmidtによる”Introducing Oracle Autonomous JSON Database for application developers“を翻訳したものです。
August 13, 2020
オラクルは本日、シンプルなNoSQL APIを備えた、使いやすくコスト効果の高いJSONデータベースを探している開発者向けに、新しいクラウド・サービスとして、Oracle Autonomous JSON Databaseの提供開始を発表しました。このOracle Autonomous JSON DatabaseにはMongoDBのコア機能がすべて揃っているうえ、高パフォーマンス、シンプルなエラスティシティ、フルACID対応、完全なSQLの機能性といった特徴も備えています。
{JSONを踏まえて}
JSONは非常に人気の高いデータフォーマットです。もともとはJavaScriptのオブジェクトをシリアライズ化するフォーマットとしてスタートしましたが、その後Webアプリケーションの事実上のメッセージ・フォーマットとなり、現在はデータベース層を含む多くの新しいアプリケーションのメインのデータ・モデルとなっています。
|
|
開発者が JSONを好む理由は、これが動的なスキーマに対応しているため、スキーマの変更が容易であるという点にあります。データを正規化して表と列による固定のリレーショナルスキーマにしなくても、JSONドキュメントを使用すれば、データ層の柔軟性を獲得できるため、アプリケーションの変更においても便利だからです。
{これを使いやすくします}
オラクルでは当初からJSONのメリットとその必要要件を特定していました。2014年、Oracle DatabaseはまずSQL/JSONのエンタープライズクラスの実装を実現しました。これはオラクルによるオープン・スタンダードで、以来、他の多くの商用データベース製品やオープンソースのデータベース製品に採用されてきました。
![[!--$CEC_DIGITAL_ASSET--]CONTDC594836EBC640D0994FAB239E17E482[/!--$CEC_DIGITAL_ASSET--]](/wp-content/uploads/sites/138/2025/11/json_table_combined.png)
SQLは分析や複雑なレポーティングに適した優れた言語ですが、多くの開発者が重視しているのは、JSONデータとのやり取りをシンプルかつ柔軟に実施することです。そこでオラクルは、JavaやJavaScript、Pythonといった一般的なプログラミング言語用にSODA(Simple Oracle Document Access)というネイティブでオープンソースのドキュメント・ストアAPIを追加することにしました。これにより、オラクルでJSONとSODAにてアプリケーションを開発することは、MongoDBなどのNoSQLのデータベースにて開発することと同じくらい簡単になりました。
| soda create cities; soda get cities -f {“county”:“Fulton”} |
さらにオラクルのJSONに対するデータベース・イノベーションは続き、JSONアプリケーション開発者に自律機能によるあらゆるメリットを提供するOracle Autonomous JSON Databaseを本日発表に至りました。
{自律をリード}
しかもオラクルは、JSONクラウド・サービスを一から構築したわけではありません。Oracle Autonomous JSON Databaseは Oracle Autonomous Database を基盤として構築されています。そのためこのサービスでは、新しいデータベースを数分でプロビジョニングしたり、アプリケーションを中断することなくスケール・アップやスケール・ダウンを実施したり、オンラインでデータベースにパッチを適用したり、ポイント・イン・タイム・リカバリにて自動バックアップを実行したり、障害復旧機能を利用したりすることができ、また高度なセキュリティ機能も用意されています。自律型データベースの目標は管理作業をゼロにすることであるため、開発者はデータベースのセットアップや管理業務ではなく、アプリケーション自体に時間を費やすことができます。
{自律型クラウド・サービスを提供}
JSONドキュメントは、ネイティブのツリー指向のバイナリ・フォーマットにて、Autonomous JSON Databaseに保存されています。このネイティブのJSONフォーマットは、高速での読み取り(線形スキャンを回避)と部分アップデート(REDO/UNDOのログサイズの縮小)向けに、高度に最適化されています。その結果、待機時間の短いCRUD操作と常に完全なACID(マルチドキュメントのトランザクションを含む)の両立、アプリケーション開発のネイティブ・ドキュメントAPIとアプリケーションの完全なSQLサポートの両立、ネイティブJSONストレージとスケーラブルかつパラレルなインメモリ・クエリーの最適化の両立を実現する、妥協のないドキュメント・データベースが誕生することとなりました。
Oracle Autonomous JSON Databaseには、以下のとおり、成熟度で劣っているNoSQLデータベースにはない豊富なアプリケーション機能が用意されています。
|
|

{手頃な価格}
Oracle Autonomous JSON Databaseは驚くほど 低コストです。このサービスは、アプリケーション開発者がオラクル上で新しいJSONアプリケーションを構築することを意図して設計されており、開発者は非常に手頃な価格でこの自律型データベースのすべての機能を利用することができます。Oracle Autonomous JSON Databaseのコストは同等のMongoDB Atlasより30%低く、MongoDB AtlasがM60ティアの専用クラスタで時間当たり3.95ドルなのに対し、Oracle Autonomous JSON Databaseは8つのOCPUで時間当たり2.74ドルとなっています。しかもOracle Autonomous JSON Databaseはエラスティックで、決まったハードウェア型に依存していないため、使用するOracle Autonomous JSON Databaseに合わせてCPUの数を選択できます。そのため実際のコストは、MongoDB Atlasよりさらに低くなる可能性があります。 またOracle Autonomous JSON Databaseのコストには、バックアップおよびBIツールへのシンプルな接続性が含まれていますが、MongoDB Atlasの場合は、どちらも追加費用が必要になります。
{…しかもスケーラブルで高速}
Oralce Autonomous JSON Databaseでは、多くの機能があるからといってパフォーマンスを犠牲にしているわけではありません。それどころか、(上述のコスト比較の際の条件にて)MongoDB Atlasと比較しても、さまざまなワークロード・タイプおよびコレクション・サイズにて一貫してその2倍のスループットを実現しています。MongoDB Atlasの測定結果は、業界標準のYCSBベンチマークを用いてMongoDBによって測定されたもので、こちらのページで公開されています。
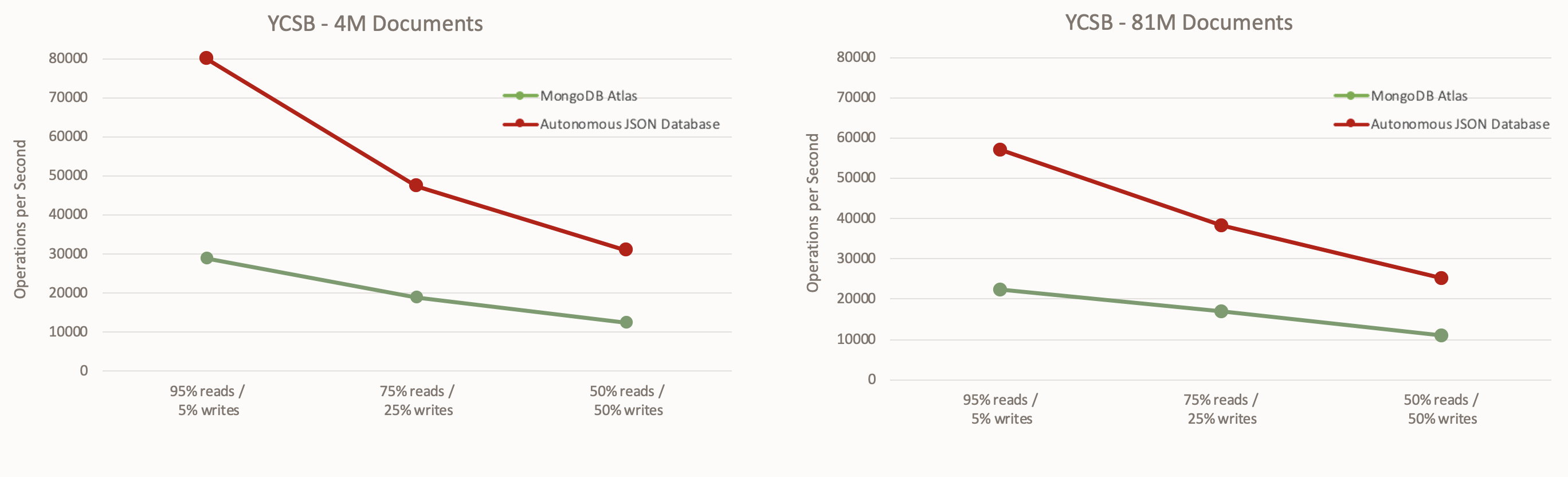
Oracle Autonomous JSON Database(8 OCPU)とMongoDB Atlas(M60)との比較
業界標準のYahoo Cloud Serving Benchmark(YCSB)
出典:2020年8月12日時点のMongoDBの測定結果(https://www.mongodb.com/atlas-vs-amazon-documentdb/performance )
{ぜひお試しください!}
Oracle Autonomous JSON Databaseは、無償のOracle Cloudトライアル・アカウントにてお試しいただけます。こちらからご登録ください。
Oracle Autonomous JSON DatabaseとOracle Cloudの無償ティアに関する情報
Oracle Autonomous JSON DatabaseはAutonomous Databaseファミリーに属しています。自動化、ライフサイクル管理、セキュリティ、可用性、スケーラビリティ、エラスティシティのためのすべてのコア機能に加え、自律型データベースのその他のサービスもすべて揃っています。
Oracle Cloudの無償ティアにてOracle Autonomous JSON Databaseを試してみたい場合は、まずはOracle Autonomous Transaction Processingから始めることをお勧めします。そのうえでシステムを拡張または本番環境に移行する準備が整ったら、無償ティアのOracle Autonomous Transaction ProcessingをOracle Autonomous JSON Databaseの有償版に直接移行させます。
なお、Oracle Autonomous JSON Databaseに移行せずに、Oracle Autonomous Transaction Processingの無償版の機能だけを使用していく方法はありません。無償ティアのデータ・サイズの上限は20GBで、Oracle Autonomous JSON Databaseでも同様に20GBの非JSONデータをサポートしています。
{AUTONOMOUS JSONとMONGODB ATLASの比較}
Oracle Autonomous JSON DatabaseがMongoDB Atlasより優れている点はコストと速度だけではありません。その他にも以下のようにさまざまなメリットがあります。
| Autonomous JSON Database | MongoDB Atlas | |
| 最大ドキュメント・サイズ | 32 MB | 16 MB |
| ドキュメントの最大ネストレベル | 1024レベル | 100レベル |
| コレクション当たりのインデックス数 | 無制限 | 64 |
| 複合インデックス・フィールド | 無制限 | 32 |
| フル・ドキュメント・インデックス | JSON検索インデックス | X |
| サーバー側の関数 | 関数、プロシージャ、トリガー | 非推奨* |
| マルチ・ドキュメント・トランザクション | 常にACID | 明示的なAPIコールにてリクエストされた場合のみACID |
| トランザクション継続時間 | 無制限 | デフォルトで60秒 |
| トランザクション・サイズ | 無制限 | 最大1000ドキュメント* |
| 集約可能なデータ・サイズ | 無制限 | 100MB RAM + 明示的allowDiskUse param |
| サーバーレス自動スケーリング | ✓ | X |
| JSONドキュメントへのSQLアクセス | ✓ | X |
| 包括的なセキュリティ (例:Oracle Virtual Private Database、 Oracle Data Redaction、カスタム・データベース・ロール) |
✓ | X |
| コスト | $2.74 / 時間 | $3.95 / 時間 |
* MongoDBのドキュメントに基づく推奨:リンク1、 リンク2
{AJDから始めるには:ステップ・バイ・ステップ}
Oracle Cloudにログインし、左側のメニューにある「Autonomous JSON Database」を選択します。
![[!--$CEC_DIGITAL_ASSET--]CONT0B06D1BC613D4A27BC160F59E47B0F14[/!--$CEC_DIGITAL_ASSET--]](/wp-content/uploads/sites/138/2025/11/step1-1.png)
この画面が開いたら、青色のボタンをクリックしてデータベースを作成します。
![[!--$CEC_DIGITAL_ASSET--]CONT1BDC598344EB48C896D18468AE54A91F[/!--$CEC_DIGITAL_ASSET--]](/wp-content/uploads/sites/138/2025/11/step2-1.png)
データベース名(および表示名)を入力し、「JSON」が選択されていることを確認します。
![[!--$CEC_DIGITAL_ASSET--]CONT75E6359608724541B2CAE1EAB78BFDDA[/!--$CEC_DIGITAL_ASSET--]](/wp-content/uploads/sites/138/2025/11/step3-1.png)
同じ画面にて「管理者用」パスワードを設定します。このパスワードは後で必要になります。
![[!--$CEC_DIGITAL_ASSET--]CONT451613D179B845E5BB64B48386BDCD93[/!--$CEC_DIGITAL_ASSET--]](/wp-content/uploads/sites/138/2025/11/step4.png)
「Create Autonomous Database」をクリックすると、新しいインスタンスがプロビジョニングされていることを確認できます。
![[!--$CEC_DIGITAL_ASSET--]CONTDA2653CAFF1642EBAC52B3F50C35B0A9[/!--$CEC_DIGITAL_ASSET--]](/wp-content/uploads/sites/138/2025/11/step5-1.png)
これには数分もかかりません。画面が更新され、緑色のロゴが表示されれば、このサービスは利用可能です。
![[!--$CEC_DIGITAL_ASSET--]CONTF463D68AD8A74899B84DE60B2C000AA9[/!--$CEC_DIGITAL_ASSET--]](/wp-content/uploads/sites/138/2025/11/step6-1.png)
「Tools」をクリックし、「SQL Developer Web」を選択します。
![[!--$CEC_DIGITAL_ASSET--]CONT8323B46DCC3D40FD8C416DDAD0FEC160[/!--$CEC_DIGITAL_ASSET--]](/wp-content/uploads/sites/138/2025/11/step7-1.png)
ここで「管理者用」パスワードを入力します。
![[!--$CEC_DIGITAL_ASSET--]CONTB8CB2F16BD4E49C1B6FD3B906AFC8C82[/!--$CEC_DIGITAL_ASSET--]](/wp-content/uploads/sites/138/2025/11/step8.png)
Webコンソールが開き、SQLおよびSODAコマンドを入力できるようになります。SODAとは’Simple Oracle Document Access’の略で、コレクションにJSONドキュメントを保存するためのシンプルなドキュメント・ストア・インタフェースになります。’soda help’と入力すれば、sodaコマンドをまとめて確認できます。
![[!--$CEC_DIGITAL_ASSET--]CONTDA754BBBB9E1403EA22C0E6837A6A85D[/!--$CEC_DIGITAL_ASSET--]](/wp-content/uploads/sites/138/2025/11/step9-1.png)
以下のように入力して’cities’というコレクションを作成し、2つのJSONドキュメントを保存します。なお、この2つのドキュメントには少し違いがあります。最初のレコードは、1つの市が1つの郡にしか属していないことを前提としています。しかし1つの市が複数の郡に属している場合もあります。そのため2つめのドキュメントでは配列を使用しています。次のコマンドを実行し、コレクションを作成して、2つのドキュメントを挿入してみましょう。
| soda create cities; |
これで、コレクションに問合せをして、検索/フィルタ条件に一致するドキュメントを見つけられるようになりました。オラクルではこれを’Query By Example’または略してQBEと呼んでいます。最初のQBEでは、’Fulton’郡にある市を検索しています。
| soda get cities -f {“county”:“Fulton”}
|

2つめのQBEでは、人口が25万人以上のすべての市を検索しています。この場合、両方のドキュメントが選択されます。
| s oda get cities -f {“population”:{“$gt”:250000}} |

これらの例では、コンソールを使用してSODAコマンドを入力しました。しかし一般的には、プログラミング言語にて直接SODAを使用することになるでしょう。オラクルには、Java、JavaScript(nodeJS)、Python、REST、Pl/Sql、ODPI-C用のSODAドライバがあるからです。 またJSONデータはOracle Databaseに保存されているため、SQLを使用して同じデータにアクセスすることも可能です。まずはコレクションを見てみましょう。
| describe cities;
|

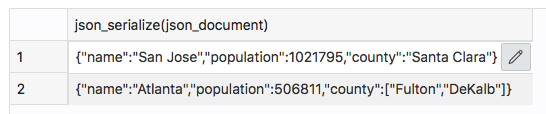
ご覧のとおり、JSONコレクションには標準的なテーブルが使用されています。JSONデータは、高速での読み取りと部分アップデートに最適化されたバイナリ表現にて保存されています。これをJSON文字列に変換するには、JSON_SERIALIZEを使用します。
| select JSON_Serialize(JSON_Document) from cities;
|
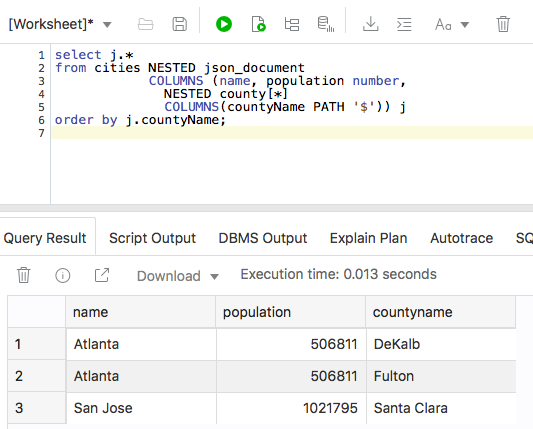
JSON_Tableでは、JSONデータをネスト解除して、リレーショナル列および行に反映させることが可能です。なお、1つの市が2つの郡に属しているため、2つのJSONドキュメントからは3つの行が生成されます。
| select j.* from cities NESTED json_document
|
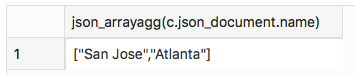
関係表現からJSONに戻す場合も、同様に簡単です。1つ(または複数の)JSON関数をクエリーに追加するだけです。以下の例では、すべての都市名の配列を生成しています。
| select JSON_ArrayAgg(c.json_document.name) from cities c; |
詳細は、Oracle Autonomous JSON Databaseにてご確認ください。
