※本記事は、“Parallel streams in Java: Benchmarking and performance considerations” の翻訳記事です。
2022年4月26日| 13分読む


コードを書き直すことなくシーケンシャルなストリームをパラレル実行できるStream API
 [ 編集注:本記事は、Oracle Pressから刊行予定のJava SE 11/17認定ガイドを抜粋要約したものです。]
[ 編集注:本記事は、Oracle Pressから刊行予定のJava SE 11/17認定ガイドを抜粋要約したものです。]
Stream API は、Javaに新しいプログラミング・パラダイムをもたらしました。すなわち、ストリームを使って宣言的な方法でデータを処理できるようになりました。これは、処理をどのように行うかではなく、値に何をするかで表現できるということです。さらに重要なことは、このAPIを使うとデータのパラレル処理を行うマルチコア・アーキテクチャを活用できる点です。ストリームには、2つの種類があります。
- シーケンシャル・ストリームは、ストリーム・パイプラインが1つのスレッドで実行されるとき、(forループのように)要素が逐次的に処理されるストリームです。
- パラレル・ストリームは、複数のサブストリームに分割され、複数のスレッドで実行されるストリーム・パイプラインの複数のインスタンスによって並列に処理されます。その途中結果を組み合わせることで、最終的な結果を生成します。
パラレル・ストリームを作成する唯一の方法は、コレクションに対して直接 Collection.parallelStream() メソッドを呼び出すことです。
既存ストリームのシーケンシャル・モードとパラレル・モードを切り替えるには、中間操作としてそれぞれ BaseStream.sequential() および BaseStream.parallel() を呼び出します。ストリームは、終端操作が開始されたストリームの実行モードに応じて、シーケンシャルまたはパラレルに実行されます。
Stream APIでは、コードを書き直すことなく、シーケンシャルなストリームをパラレル実行することができます。パラレル・ストリームを使う主な理由は、実行モードにかかわらず同じ結果(少なくとも、互換性のある結果)が得られることを保証しつつ、パフォーマンスを向上させるためです。Stream APIはその目的を達成するうえで非常に役立ちますが、ストリーム・パイプラインをパラレル実行する際に避けるべきわなについて理解しておくことが重要です。
パラレル・ストリームの使用
パラレル・ストリームの作成:既存ストリームに対して parallel() メソッドを呼び出すと、実行モードをパラレルに設定することができます。また、Collectionインタフェースの parallelStream() メソッドを使うと、コレクションをデータソースとしてパラレル・ストリームを作成することができます。パラレル・ストリームのデータ分割やスレッド管理はAPIとJVMが行ってくれるので、パラレル実行に必要なコードはこれだけです。他のストリームと同じく、パラレル・ストリームも、それに対して終端操作が呼び出されるまで実行されることはありません。
ストリーム・インタフェースの isParallel() メソッドを使うと、ストリームの実行モードがパラレルかどうかを確認することができます。
パラレル・ストリームの実行:Stream APIのストリームは、シーケンシャルまたはパラレルに実行できます。つまり、すべてのストリーム操作はシーケンシャルまたはパラレルに実行できます。シーケンシャル・ストリームは、1つのCPUコアで動作する1つのスレッドで実行されます。ストリームの要素は、同じスレッドで実行されるストリーム操作によって1つのパスで逐次的に処理されます。
パラレル・ストリームは、1台のコンピュータにおける複数のCPUコアで動作する別々のスレッドで実行されます。ストリームの要素はサブストリームに分割され、複数のスレッドで実行されるストリーム・パイプラインの複数のインスタンスによって処理されます。その後、各サブストリームを処理した部分的な結果がマージされ(組み合わされ)、最終的な結果が生成されます。
パラレル・ストリームでは、Fork/Joinフレームワークを使った並列タスク実行が行われます。このフレームワークは、サブストリームをパラレル実行するために必要なスレッド管理をサポートしています。パラレル・ストリームの実行時に使われるスレッドの数は、コンピュータのCPUコアによって決まります。
パフォーマンスに影響する要因
ストリームをパラレル実行すればパフォーマンスが向上するという保証はありません。このセクションでは、パフォーマンスに影響する可能性があるいくつかの要因に注目します。
一般的に、CPUコアの数(つまり、パラレル実行できるスレッドの数)を増やせば、パフォーマンスは向上します。ただしこれには、データのサイズによって決まる上限があります。処理するデータがなくなれば、一部のスレッドがアイドル状態になる可能性があるからです。CPUコアの数を増やせば、あるところまではパフォーマンスが向上します。しかし、ストリームをパラレル実行すべきかどうかを決めるうえで考慮すべき要因はこれだけではありません。
パラレル処理の総コストには、パラレル実行の設定の起動コストが必ず含まれます。起動時点で、このコストがシーケンシャル実行のコストとすでに同程度であれば、パラレル実行してもパフォーマンス的なメリットはあまりありません。
ストリームをパラレル実行すべきかどうかを決めるうえで重要になる可能性があるのは、次に示す3つの要因の組合せです。
- データ・サイズが十分大きい:ストリームのサイズがパラレル処理に釣り合うだけ十分に大きい必要があります。そうでない場合は、シーケンシャル処理を使うべきです。ストリームのサイズが小さすぎると、パラレル実行の起動コストがあまりにも高価となることがあります。
- ストリーム操作で重い計算を行う:ストリーム操作で行う計算が少ない場合、ストリームのサイズがその少なさを補うほど大きくないと、パラレル実行に釣り合いません。ストリーム操作で重い計算を行う場合、ストリームのサイズはさほど重要ではなく、パラレル実行によってパフォーマンスが向上する可能性があります。
- ストリームを簡単に分割できる:ストリームをサブストリームに分割するコストがサブストリームを処理するコストより大きい場合、パラレル実行する意味はないかもしれません
。ArrayListやHashMap、あるいは単純な配列などのコレクションは効率的に分割することができます。逆にもっとも分割効率が悪いのは、LinkedListやI/Oベースのデータソースです。
ベンチマークのすすめ
強く推奨したいのは、パラレル実行にメリットがあるかどうかを判断するためにベンチマークを行う(パフォーマンスを測定する)ことです。リスト1に、ストリームの実行前後にシステム・クロックを読み取る簡単なプログラムを示します。このプログラムを使うと、ストリームのパフォーマンスがどの程度かを把握することができます。
リスト1:シーケンシャル・ストリームとパラレル・ストリームのパフォーマンスを計測するベンチマーク
import java.util.function.LongFunction;
import java.util.stream.LongStream;
/*
* ストリームを使って1からnまでの数値を合計する実行時間を
* 計測するベンチマーク
*/
public final class StreamBenchmarks {
public static long seqSumRangeClosed(long n) { // (1)
return LongStream.rangeClosed(1L, n).sum();
}
public static long paraSumRangeClosed(long n) { // (2)
return LongStream.rangeClosed(1L, n).parallel().sum();
}
public static long seqSumIterate(long n) { // (3)
return LongStream.iterate(1L, i -> i + 1).limit(n).sum();
}
public static long paraSumIterate(long n) { // (4)
return LongStream.iterate(1L, i -> i + 1).limit(n).parallel().sum();
}
public static long iterSumLoop(long n) { // (5)
long result = 0;
for (long i = 1L; i <= n; i++) {
result += i;
}
return result;
}
/*
* nをパラメータとして渡し、関数パラメータfuncを適用する。
* 関数を100回実行した平均時間(ミリ秒)を返す。
*/
public static <R> double measurePerf(LongFunction<R> func, long n) { // (6)
int numOfExecutions = 100;
double totTime = 0.0;
R result = null;
for (int i = 0; i < numOfExecutions; i++) { // (7)
double start = System.nanoTime(); // (8)
result = func.apply(n); // (9)
double duration = (System.nanoTime() - start)/1_000_000; // (10)
totTime += duration; // (11)
}
double avgTime = totTime/numOfExecutions; // (12)
return avgTime;
}
/*
* それぞれのサイズのストリームに対して、可変長引数 funcs で渡された関数を実行する。
*/
public static <R> void xqtFunctions(LongFunction<R>... funcs) { // (13)
long[] sizes = {1_000L, 10_000L, 100_000L, 1_000_000L}; // (14)
// それぞれのサイズのストリームに対して ...
for (int i = 0; i < sizes.length; ++i) {
System.out.printf("%7d", sizes[i]); // (15)
// ... 可変長引数 funcs で渡された関数を実行する
for (int j = 0; j < funcs.length; ++j) { // (16)
System.out.printf("%10.5f", measurePerf(funcs[j], sizes[i]));
}
System.out.println();
}
}
public static void main(String[] args) { // (17)
System.out.println("Streams created with the rangeClosed() method:");// (18)
System.out.println(" Size Sequential Parallel");
xqtFunctions(StreamBenchmarks::seqSumRangeClosed,
StreamBenchmarks::paraSumRangeClosed);
System.out.println("Streams created with the iterate() method:"); // (19)
System.out.println(" Size Sequential Parallel");
xqtFunctions(StreamBenchmarks::seqSumIterate,
StreamBenchmarks::paraSumIterate);
System.out.println("Iterative solution with an explicit loop:"); // (20)
System.out.println(" Size Iterative");
xqtFunctions(StreamBenchmarks::iterSumLoop);
}
}
このプログラムの出力の一例を図1に示します。この結果は、本記事の以降の部分で随時参照します。
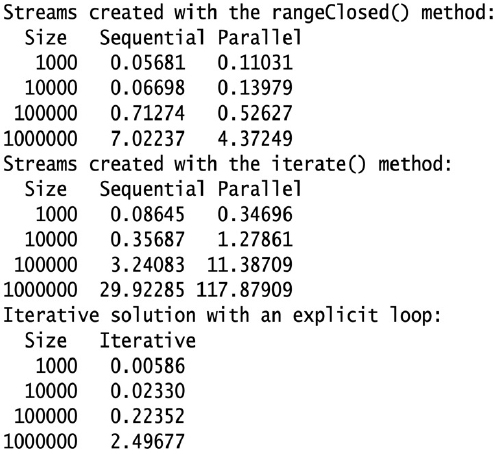
図 1. ベンチマーク・プログラムからの出力
リスト1の StreamBenchmarksクラスには、(1)から(5)の行に5つのメソッドが定義されています。これらのメソッドは、1からnまでの値の合計を計算しますが、それぞれ異なる方法で計算しています。そのそれぞれのメソッドを、4つの異なるnの値を使って実行します。つまり、合計する値の数がストリームのサイズになります。
このプログラムは、それぞれのメソッドと、異なるnの値の組合せについてのベンチマーク結果を表示します。もちろん、結果は変動することがあります。結果には多くの要因が影響する可能性があるためで、もっとも大きな要因はコンピュータに搭載されているCPUコアの数です。
それでは、結果を詳しく見ていくことにしましょう。
行(1)と行(2)のメソッド: 行(1)の seqSumRangeClosed() メソッドと行(2)の paraSumRangeClosed() メソッドは、 rangeClosed() メソッドで作られたストリームを、それぞれシーケンシャルとパラレルで計算します。
return LongStream.rangeClosed(1L, n).sum(); // シーケンシャル・ストリーム ... return LongStream.rangeClosed(1L, n).parallel().sum(); // パラレル・ストリーム
終端操作 sum() は、重い計算ではない点に注意してください。
値の数が100,000に近づくと、パラレル・ストリームの方が優れたパフォーマンスを発揮し始めます。パラレル・ストリームのパフォーマンスの方がよくなるのは、ストリームのサイズがかなり大きくなってからです。値の範囲は rangeClosed() メソッドの引数で定義していますが、開始値と終了値が明示されているので、効率的にサブストリームに分割できることに注意してください。
行(3)と行(4)のメソッド:行(3)のseqSumIterate() メソッドと行(4)のparaSumIterate()メソッドは、iterate() メソッドで作られたストリームを、それぞれシーケンシャルとパラレルで返します。
return LongStream.iterate(1L, i -> i + 1).limit(n).sum(); // シーケンシャル ... return LongStream.iterate(1L, i -> i + 1).limit(n).parallel().sum(); // パラレル
ここで iterate() メソッドが作成しているのは無限ストリームですが、 limit() 中間操作を使い、nの値に応じてストリームを切り捨てています。値の数が増えると、どちらのストリームでもすぐにパフォーマンスが低下します。
ただし、すべての場合で、シーケンシャル・ストリームよりもパラレル・ストリームの方がパフォーマンスは悪くなります。 iterate() メソッドで生成される値はストリームが実行されるまでわからず、limit() 操作もステートフルなので、パラレル・ストリームの場合、値をサブストリームに分割する処理は非効率になります。
行(5)のメソッド:行(5)のiterSumLoop() メソッドは、forループを使って合計を計算します。forループを使った合計の計算は、すべてのnの値で、ストリームを使った計算のパフォーマンスを上回っています。つまり、ストリームを使って数列の合計を計算すると、大きなオーバーヘッドが発生するということです。
リストのその他の部分:それ以外の、リスト1において主要な部分について説明します。
行(6)の measurePerf() メソッドと行(13)の xqtFunctions() メソッドは、パラメータとして渡された関数のベンチマークを作成します。
measurePerf() メソッドでは、行(8)でシステム・クロックを読み取り、行(9)で関数パラメータfuncを適用しています。システム・クロックは、行(9)での関数の適用が完了した後の行(10)でも読み取っています。行(10)で計算した実行時間が、関数の実行時間になります。
関数 func を適用すると、 LongFunction インタフェースを実装したラムダ式またはメソッド参照が評価されます。リスト1では、 StreamBenchmarks クラスの行(1)から行(5)のメソッドを呼び出すメソッド参照が関数パラメータ funcを実装しており、その実行時間が計測されます。
副作用とその他の要因
望みどおりの結果になるパラレル・ストリームを効率的に実行するには、特定の副作用を起こさないストリーム操作(とその動作パラメータ)が必要です。
非干渉動作:ストリーム操作の動作パラメータは、シーケンシャル・ストリームとパラレル・ストリームの両方において非干渉であるべきです。ストリーム・データソースで並列実行が認められている場合を除き、ストリーム・パイプラインの実行中にストリーム操作でデータソースを変更してはいけません。
ステートレス動作:ストリーム操作の動作パラメータは、シーケンシャル・ストリームとパラレル・ストリームの両方においてステートレスであるべきです。ラムダ式として実装される動作パラメータは、ストリーム・パイプラインの実行中に変化する可能性がある状態に依存してはいけません。ステートフルな動作パラメータが存在すると、ストリームが一意に決まらず、不正確な結果になる可能性もあります。動作パラメータがステートレスであれば、結果は常に同じになります。
パイプラインのストリーム操作の動作パラメータから共有の状態にアクセスするのは、よい方法ではありません。その理由は、パイプラインを並列実行すると、グローバルな状態にアクセスしたときに競合状態になる可能性があるからです。一方で、スレッド・セーフティを確保するために同期コードを使うと、パラレル化の目的が損なわれることがあります。共有の状態をカプセル化するには、3つの引数がある reduce() メソッドや collect() メソッドを使うソリューションの方がよいかもしれません。
distinct(), skip(), limit(), sorted() の中間操作はステートフルです。これらをパラレル・ストリームで実行すると、パフォーマンスのオーバーヘッドが増えることがあります。このような操作は、データに対して複数回操作を行ったり、大規模なデータのバッファリングが必要になったりする可能性があるからです。
順序付けと終端操作:順序付けされたストリームに対して出現順を保持する操作を行うと、実行がシーケンシャルかパラレルかによらず、常に同じ結果が得られます。しかし、順序付けされていないストリームを繰り返し実行すると、シーケンシャルかパラレルかによらず、異なる結果になる可能性があります。
順序付けされたパラレル・ストリームで要素の出現順を保持すると、パフォーマンスが低下する可能性があります。順序付けされたパラレル・ストリームに対し、unordered()中間操作を呼び出して順序付けの制約を取り除くと、ストリームのパフォーマンスが改善する可能性があります。
順序付けされていないパラレル・ストリームに対し、ステートフルな中間操作である distinct(), skip(), limit() を使うと、順序付けされているパラレル・ストリームよりもパフォーマンスが向上する可能性があります。
distinct()操作では、重複値が初めて出現した際にバッファリングする必要はなくなり、すべてをバッファリングするだけでよくなるskip()操作では、最初のn個の要素をスキップするのではなく、どのn個の要素をスキップしても構わないlimit()操作では、最初のn個の要素の後だけでなく、どのn個の要素の後でストリームを切り捨てても構わない
終端操作 findAny()は、あえて非決定的であり、ストリームのどの要素が返されるかはわかりません。これは特にパラレル・ストリームに適しています。
forEach() 終端操作は出現順を無視しますが、forEachOrdered() 終端操作は順番を保持します。一方、 sorted() ステートフル中間操作は、パラレル・パイプラインで実行されているかどうかにはよらず、特定の出現順を強制します。
数値のオートボクシングとアンボクシング:Stream APIでは、オブジェクトのストリームと数値のストリームの両方が許可され、相互変換もサポートされています。そのため、可能な場合には数値ストリームを選択することで、オブジェクト・ストリームのオートボクシングとアンボクシングのオーバーヘッドを回避することができます。
まとめ
本記事で見てきたように、パラレル実行のメリットをフル活用するには、一定のルールに従ってストリーム・パイプラインを構築し、パラレル化を後押しする必要があります。まとめると、パラレル・ストリームを使うメリットが最大限に発揮されるのは、以下の条件が満たされるときです。
- ストリーム・データソースが十分なサイズであり、ストリームを容易にサブストリームに分割できる
- ストリーム操作に有害な副作用がなく、パラレル化に釣り合うだけ重い計算である