※本記事は、“Java garbage collection: The 10-release evolution from JDK 8 to JDK 18” の翻訳記事です。
2022年6月17日| 19分読む
数千の拡張機能により、スループット、レイテンシおよびメモリ・フットプリントが改善
JDK 18の一般提供は、2014年3月にまだ人気のJDK 8リリース以降、10番目のリリースとなりました。この記念すべき日は、一度立ち止まって、ここに至るまでにHotSpot JVMのガベージ・コレクタに何が起こったかを確認するよい機会です。
本記事は、プレゼンテーション「ガベージ・コレクションにおけるJDK 8からJDK 18: 10リリース、2000以上の機能拡張」に基づいています。
ガベージ・コレクション、メトリックおよびトレードオフの概要
アプリケーションのアプリケーション・ヒープを管理するHotSpot JVMのコンポーネントは、ガベージ・コレクタ(GC)と呼ばれます。GCは、アプリケーション・ヒープ・オブジェクトのライフサイクル全体を制御します。アプリケーションがメモリを割り当てるときに始まり、後で最終的に再利用するためにそのメモリの回収しながら、動き続けます。
非常に高いレベルでみると、JVMのガベージ・コレクション・アルゴリズムの最も基本的な機能は次のとおりです。
- アプリケーションからのメモリの割当てリクエストに応じて、GCによってメモリが提供されます。そのメモリをできるだけ早く提供します。
- GCは、アプリケーションが再び使用することのないメモリを検出します。また、このメカニズムは効率的であるべきであり、時間をかけるべきではありません。この到達不能メモリは、一般にガベージとも呼ばれます。
-
その後、GCによって、アプリケーションにメモリが再び(できれば「時間内」、つまり迅速に)提供されます。
優れたガベージ・コレクション・アルゴリズムにはさらに多くの要件がありますが、この3つが最も基本的な要件です。ただ、これだけでは説明しきれていません。
これらの要件をすべて満たす方法は数多くありますが、残念ながら特効薬や万能アルゴリズムはありません。このため、JDKには選択できるいくつかのガベージ・コレクション・アルゴリズムが用意されています。それぞれが特定のユースケースに対して最適化されています。それらの実装は、3つの主なパフォーマンス・メトリックであるスループット、レイテンシ、メモリ・フットプリントについて、その振る舞いとアプリケーションに対する影響を一通り定めています。
- スループットは、特定の時間単位で実行できる作業量を表します。この説明では、時間単位当たりにより多くの収集作業を実行するガベージ・コレクション・アルゴリズムが望ましく、Javaアプリケーションのスループットが向上します。
- レイテンシは、アプリケーションの1回の操作にかかる時間を示します。待機時間に焦点を当てたガベージ・コレクション・アルゴリズムは、影響の大きい待機時間を最小限にしようとします。GCのコンテキストでは、主な懸念事項は、その操作が一時停止を誘発するかどうか、一時停止の範囲、および一時停止の長さです。
- GCのコンテキストにおけるメモリ・フットプリントとは、GCの適切な動作に必要なメモリが、アプリケーションのJavaヒープ・メモリ使用量に加えてどのくらい必要とするかを意味します。Javaヒープの管理にのみ使用されるデータは、アプリケーションから取り除かれます。GC (または、より一般的にはJVM)が使用するメモリの量が少ない場合、アプリケーションのJavaヒープにより多くのメモリを提供できます。
これらの3つのメトリックはつながっています。高スループット・コレクタはレイテンシに大きな影響を及ぼし(ただし、アプリケーションへの影響は最小限に抑えられます)、その逆もあります。メモリ消費を少なくするには、ほかのメトリックで最適でないアルゴリズムの使用が必要になることがあります。レイテンシが低いコレクタは、より多くの作業を同時に実行したり、アプリケーションの実行の一部として小さなステップで実行したりして、プロセッサ・リソースの使用低減を実現しています。
この関係は、図1に示すように、三角形でグラフ化され、各隅に1つのメトリックが表示されます。各ガベージ・コレクション・アルゴリズムは、メトリックのターゲットの値および最適な値に基づいて、その三角形の占有部分を決めています。
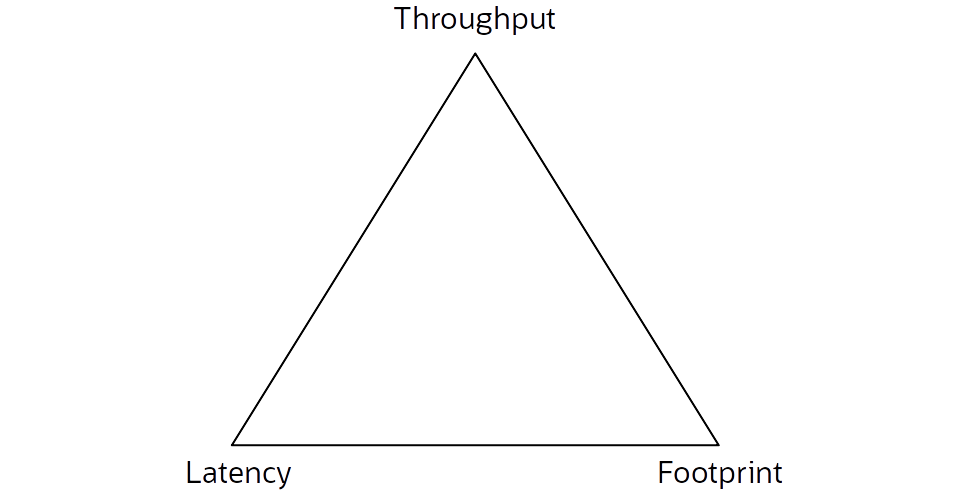
図 1. GCパフォーマンス・メトリックの三角形
ある指標に対してGCを改善しようとすると、他の指標がペナルティになることがよくあります。
JDK18 の OpenJDK GC
OpenJDKは、様々なパフォーマンス指標に焦点を当てた5つのGCの多様な組み合わせを提供します。表1に、名前、そのフォーカス領域、およびコンセプトのプロパティを実現するために使用されるコア概念の一部を示します。
表 1. OpenJDK の5つの GC
| Garbage collector 名 | フォーカス領域 | コンセプト |
| Parallel | スループット | マルチスレッド・STW(stop-the-world)・ コンパクションと世代別コレクション |
| Garbage First (G1) | バランスの取れたパフォーマンス | マルチスレッドSTW(stop-the-world)・ コンパクション、コンカレント・ライブネス、世代別コレクション |
| Z Garbage Collector (ZGC) (since JDK 15) | レイテンシ | すべてがアプリケーションと同時 |
| Shenandoah (since JDK 12) | レイテンシ | すべてがアプリケーションと同時 |
| Serial | フットプリントおよび起動時間 | シングルスレッドSTWコンパクションと世代別コレクション |
Parallel GCは、JDK 8以前のデフォルト・コレクタです。レイテンシ(一時停止)に関して最小限で、できるだけ迅速に作業を完了させようとすることで、スループットに重点を置きます。
パラレルGCは、STWの一時停止中に使用中のメモリをよりコンパクトな形式でヒープ内の他の場所に避難(つまり、コピー)することで大きなメモリ領域を解放します。STWの一時停止は、割当てリクエストが満たされない場合に発生します。その後、JVMはアプリケーションを完全に停止し、ガベージ・コレクション・アルゴリズムは、使用可能な数のプロセッサ・スレッドを使用してメモリ圧縮処理を実行し、割当てでリクエストされたメモリを割り当て、最後にアプリケーションの実行を続行します。
パラレルGCは、ガベージ・コレクションの効率を最大化する世代コレクタでもあります。生成コレクションの考え方については後で説明します。
G1 GCは、JDK 9以降のデフォルト・コレクタです。G1は、スループットとレイテンシの懸念事項のバランスをとります。パラレルGCで行われるように世代を使用してSTWの一時停止中にメモリ回収作業が実行されますが、これらの一時停止での長時間の操作を回避しようとします。
G1は、アプリケーションが複数のスレッドを使用して実行されている間に、アプリケーションと並行して時間のかかる作業を実行します。これにより、全体のスループットを犠牲にして最大一時停止時間を大幅に短縮しています。
ZGCとShenandoah GCは、スループットを犠牲にしてレイテンシに注目しています。すべてのガベージ・コレクション作業を、目立つ一時停止なしで試行します。現在、どちらも世代別ではありません。最初に、JDK 15とJDK 12で非実験的バージョンとして導入されました。
シリアルGCはフットプリントと起動時間に焦点を当てています。このGCは、STWの一時停止内のすべての作業に対して単一のスレッドのみを使用するため、パラレルGCのよりシンプルで低速なバージョンに似ています。ヒープも世代単位で編成されています。ただし、シリアルGCは複雑さを取り除いているためフットプリントと起動時間の点で優れているため、小さくて短時間動作するアプリケーションに対して特に適しています。
OpenJDKには、表1にはない別のGC Epsilonも用意されています。なぜでしょうか?Epsilonはメモリ割当てのみを許可し、回収を実行しないため、GCのすべての要件を満たしていません。ただし、Epsilonは、非常に狭い特殊なアプリケーションに有用です。
G1 GC の概要
G1 GCはJDK 6 update 14で実験的な機能として導入され、JDK 7 update 4から完全にサポートされました。G1は、JDK 9以降、その汎用性のためにHotSpot JVMのデフォルトのコレクタになっています。安定しており、成熟度も高く、非常にアクティブにメンテナンスされ、常に改善されています。この記事の続きでそれをみなさんが納得できることを願っています。
G1は、どのようにしてスループットとレイテンシの間のこのバランスを実現しますか。
1つの重要な方法は、世代別ガベージ・コレクションです。最も最近割り当てられたオブジェクトが、ほぼすぐに回収できる可能性が最も高い(つまり、すぐに「消滅する」)ことがわかります。そのため、G1および他の世代別GCは、Javaヒープを2つの領域に分割します。1つは、オブジェクトが最初に割り当てられるいわゆるyoung generationで、もう1つはyoung generationの数回のガベージ・コレクション・サイクルよりも長く生きるオブジェクトが配置されるold generation で、より少ない労力で回収できます。
young generationは、old generationよりずっと小さいことが多いです。したがって、収集の労力に加え、G1などのトレースGCでは、young generationのコレクション中に到達可能な(ライブ)オブジェクトのみが処理されるため、young generationのガベージ・コレクションに費やされる時間は一般に短く、多くのメモリが同時に回収されます。
ある時点で、寿命が長いオブジェクトはold generationに移動されます。
したがってold generationがいっぱいになるとガベージを集めメモリを回収する必要があります。old generationは通常大きく、多数のライブ・オブジェクトが含まれているため、これにはかなりの時間がかかる場合があります(たとえば、パラレルGCのフル・コレクションは、young generationのコレクションよりも多くの時間がかかります)。
このため、G1は古い世代のガベージ・コレクション作業を2つのフェーズに分割します。
- G1は、まずJavaアプリケーションの実行と並列でライブ・オブジェクトをトレースします。これにより、old generationのメモリの回収に必要な作業の大部分がガベージ・コレクションの一時停止から移動されるため、レイテンシが短縮されます。実際のメモリの回収は、一度にすべて実行すると、大規模なアプリケーション・ヒープでは非常に時間がかかります。
- したがって、G1は、old generationのメモリを段階的に回収します。ライブ・オブジェクトのトレース後、次のいくつかの通常のyoung generationのコレクションで、G1はyoung generation全体に加えてold generationの小さく分割した部分も詰め込んで、メモリを時間をかけて回収します。
old generationを段階的に回収することは、オブジェクト・グラフを介したトレースが不正確であることや、段階的ガベージ・コレクションのサポート・データ構造を管理するための時間と領域のオーバーヘッドが原因で、このすべての作業を一度に実行することよりも少し非効率的です。ただし、一時停止に要する最大時間が大幅に短縮されます。大まかなガイドとして、段階的なガベージ・コレクションの一時停止の時間は、young generationのメモリのみを回収する場合とほぼ同じです。
また、MaxGCPauseMillis コマンドライン・オプションを使用して、これらのタイプのガベージ・コレクションの一時停止時間の目標値を設定できます。G1は、この値を下回る時間を保持しようとします。この期間のデフォルト値は200ミリ秒です。これは、アプリケーションに適している場合とそうでない場合がありますが、最大限のガイドです。G1は、可能な場合は一時停止時間をその値より低く保ちます。そのため、一時停止時間を改善しようとする場合の最初の試みは、MaxGCPauseMillis の値を減らすことです。
JDK 8 から JDK 18 への進捗
OpenJDKのGCを紹介したので、最近の10つのJDKリリースでGCの3つのメトリック(スループット、レイテンシ、メモリ・フットプリント)に対して行われた改良について詳しく説明します。
G1のスループット向上: スループットとレイテンシの改善を示すために、この記事では SPECjbb2015ベンチマークを使用します。SPECjbb2015は、スーパーマーケット企業内の複数の処理の組み合わせをシミュレートすることでJavaサーバーのパフォーマンスを測定する一般的な業界ベンチマークです。ベンチマークには2つのメトリックがあります。
- maxjOPS は、システムが提供できるトランザクションの最大数。これはスループット・メトリックです。
- criticaljOPS は、10ミリ秒から100ミリ秒までの応答時間など、複数のサービスレベル契約(SLA)のスループットを測定します。
この記事では、JDKリリースのスループットとレイテンシに対する実際の一時停止時間の改善を比較するためのベースとして、maxjOPSを使用します。criticaljOPS値は一時停止時間によって誘発される待機時間の代表ですが、そのスコアに寄与する他のソースがあります。一時停止時間を直接比較すると、この問題を回避できます。
図 2は、JDK 11およびJDK 18のJDK 8に対してグラフ化された16 GB Javaヒープでのコンポジット・モードのG1のmaxjOPS結果を示しています。ご覧のとおり、スループット・スコアは、次のJDKリリースに移動するだけで大幅に増加します。JDK 8と比較して、JDK 11はそれぞれ約5%、JDK 18は約18%向上しました。簡単に言うと、次のJDKでは、より多くのリソースが使用可能になり、アプリケーションの実際の作業に使用されます。
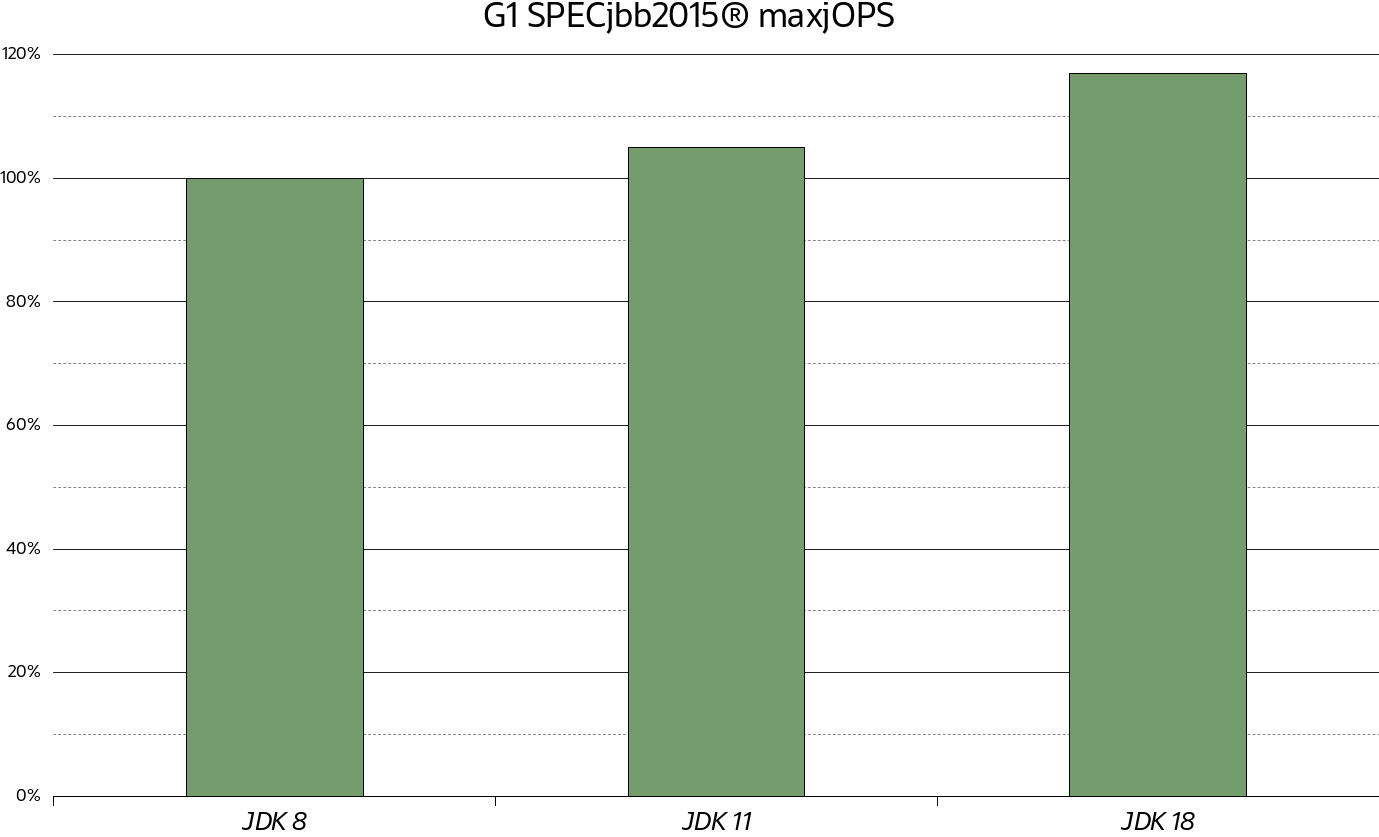
図 2. SPECjbb2015 maxjOPSで測定したG1スループット向上率
以下の考察では、これらのスループット向上を、特定のガベージコレクションの変更に起因させることを試みます。しかし、ガベージコレクションの性能、特にスループットは、コードのコンパイルなど他の一般的な改善にも非常に適しているため、ガベージコレクションの変更がすべての上昇の要因ではありません。
JDK 9の初期の重要な改良点の1つは、G1がold generationのコレクションをできるだけ遅く、遅延して開始する方法です。
JDK 8では、G1がold generationのコレクションのためにライブオブジェクトの同時トレースを開始する時刻を、ユーザーが手動で設定する必要がありました。この時刻があまりに早く設定されると、JVMは回収作業を開始する前に、old generationに割り当てられたすべてのアプリケーションヒープを使用しないことになります。欠点として、これではold generationのオブジェクトが回収可能になるまでの時間が短くなってしまいます。そのため、G1では、より多くのデータがまだ生きているため、活性度を分析するためにより多くのプロセッサ資源を必要とするだけでなく、old generationのメモリを解放するために必要以上の作業を行うことになります。
また、old generationのコレクションの開始時刻を遅く設定しすぎると、JVMのメモリ不足でフル・コレクションが非常に遅くなるという問題もありました。JDK 9以降、G1はold generationのトレースを開始する最適なポイントを自動的に判断し、現在のアプリケーションの動作に適応するようになりました。
JDK 9で実装されたもう一つのアイデアは、G1が自動的にold generationに配置した大きなオブジェクトを、他のold generationよりも高い頻度で回収しようとすることに関連するものです。世代の利用と同様に、これはGCが潜在的に非常に高い利得を持つ「選びやすい」仕事に集中するもう一つの方法です-結局のところ、大きなオブジェクトは多くのスペースを取るので、大きなオブジェクトと呼ばれます。いくつかの(確かにまれな)アプリケーションでは、これはガベージコレクションの数と総休止時間において、G1がスループットでパラレルGCに勝るほど大きな削減をもたらすことさえあります。
一般的に、すべてのリリースは、同じ作業を実行しながら、ガベージコレクションの一時停止を短くする最適化を含んでいます。これは、スループットの自然な向上につながります。この記事で挙げることができる多くの最適化がありますが、レイテンシの改善に関する次のセクションで、そのいくつかを指摘します。
パラレルGCと同様に、G1はJDK 14の Javaヒープへの割り当てのためにNUMA(NUMA-Aware Memory Allocation) を意識して対応できるようになりました。それ以来、メモリアクセス時間が不均一な複数のソケットを持つコンピュータ、つまり、メモリがコンピュータのソケットにある程度専用化されており、一部のメモリへのアクセスが遅くなる可能性がある場合、G1は局所性を利用しようとします。
NUMA を意識した場合、G1 GC は、(1 つのスレッドまたはスレッドグループによって)1 つのメモリノードに割り当てられたオブジェクトは、ほとんど同じノード上の他のオブジェクトから参照されると想定しています。したがって、オブジェクトがyoung generationにとどまっている間は、G1は同じノード上にオブジェクトを保持し、old generationのノードに長寿命のオブジェクトを均等に分散して、アクセス時間のばらつきを最小にします。これは、並列GCが実装しているものと同様です。
もうひとつ、ここで指摘しておきたい改善点は、一般的でない状況に適用されるものです。最も顕著なのは、おそらくフルコレクションでしょう。通常、G1は人間工学的に内部パラメータを調整することで、フルコレクションを防ごうとしています。しかし、極端な条件下ではこれが不可能で、G1 は一時停止中にフルコレクションを実行する必要があります。JDK 10までは、実装されたアルゴリズムはシングルスレッドであったため、非常に遅くなっていました。現在の実装は、Parallel GCのフルガベージコレクション処理と同程度です。まだ遅いので避けたいところですが、かなり良くなっています。
パラレルGCのスループット向上:パラレルGCといえば、図3は、先に使用したのと同じヒープ構成で、JDK 8からJDK 18までのmaxjOPSスコアの改善を示しています。ここでも、JVMを代用するだけで、Parallel GCでも、2%という控えめな値から、10%前後の嬉しいスループット向上が得られています。G1に比べて改善幅が小さいのは、パラレルGCの絶対値が高いところからスタートしたため、得るものが少なかったからです。
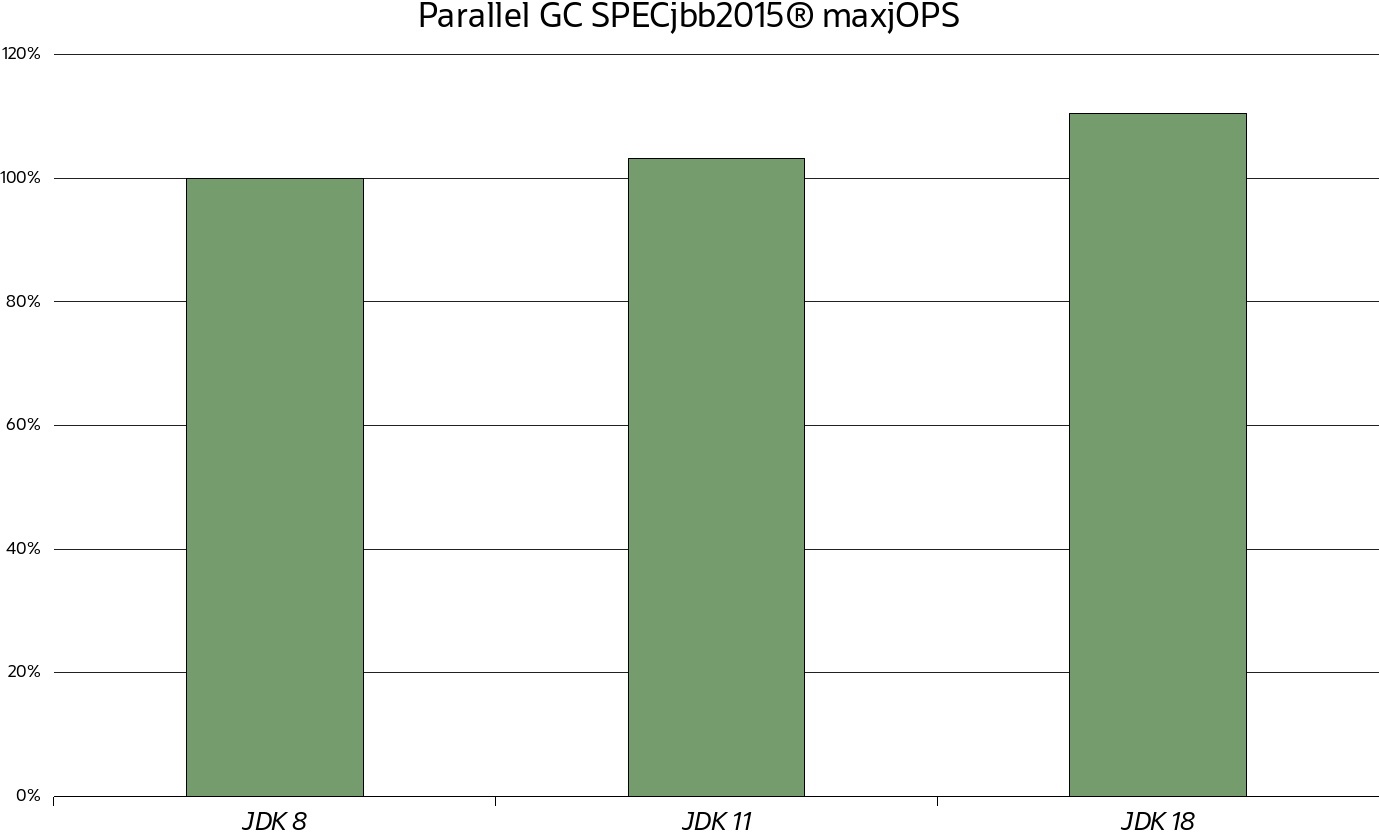
図 3. SPECjbb2015 maxjOPSで測定したパラレルGCのスループット向上
G1のレイテンシ改善: HotSpot JVM GCのレイテンシ改善を実証するため、このセクションでは、SPECjbb2015ベンチマークを使用して負荷を固定し、次に一時停止時間を測定しています。Javaヒープサイズは16GBに設定されています。表2は、デフォルトの一時停止時間目標200ミリ秒における、異なるJDKバージョンの平均一時停止時間、99パーセンタイル(P99)一時停止時間、および同じ区間内の相対合計一時停止時間をまとめたものです。
表 2. デフォルトの一時停止時間200msによる待ち時間の改善
| JDK 8, 200 ミリ秒 | JDK 11, 200 ミリ秒 | JDK 18, 200 ミリ秒 | |
| 平均 (ミリ秒) | 124 | 111 | 89 |
| P99 (ミリ秒) | 176 | 111 | 111 |
| 相対的収集時間 (%) | n/a | -15.8 | -34.4 |
JDK 8の一時停止は平均で124ミリ秒、P99の一時停止は176ミリ秒です。JDK 11では、平均一時停止時間が111ミリ秒に短縮され、P99は134ミリ秒に一時停止されます。合計支出は15.8%短縮されます。JDK 18は、これに対してさらに大幅に改善され、平均で89ミリ秒、P99の一時停止時間が104ミリ秒になるため、ガベージ・コレクションの一時停止時間が34.4%短縮されます。
一時停止時間目標を50ミリ秒に設定してJDK 18実行を追加するように実験を拡張しました。これは、200ミリ秒の-XX:MaxGCPauseMillisのデフォルトが長すぎると任意に決定したためです。G1は、平均して一時停止時間の目標に達し、P99ガベージ・コレクションの一時停止に56ミリ秒かかりました(表3を参照)。全体として、一時停止に費やされた合計時間は、JDK 8に比べてほぼ(0.06%)増加しませんでした。
つまり、JDK 8 JVMをJDK 18 JVMに置き換えることによって、同じ一時停止時間の目標に対して潜在的な増加したスループットで平均休止が大幅に減少するか、G1で一時停止時間の目標(50ミリ秒)を一時停止にほぼ同じスループットにほぼ対応する同じ合計時間に維持できます。
表 3.一時停止時間目標を50ミリ秒に設定することによるレイテンシの改善
| JDK 8, 200 ミリ秒 | JDK 11, 200 ミリ秒 | JDK 18, 200 ミリ秒 | JDK 18, 50 ミリ秒 | |
| 平均 (ミリ秒) | 124 | 111 | 89 | 44 |
| P99 (ミリ秒) | 176 | 134 | 104 | 56 |
| 相対的収集時間 (%) | n/a | -15.8 | -34.4 | +0.06 |
表3の結果は、JDK 8以降多くの改善によって実現されました。一番注目すべきものはこちら。
レイテンシの短縮にかなり大きな貢献は、old generationの一部を収集するために必要なメタデータの削減でした。いわゆる記憶されたセットは、データ構造自体が改善されることと、必要のない情報を保存および更新しないことの両方によって大幅に切り捨てられました。今日のコンピュータ・アーキテクチャでは、管理するメタデータの削減は、メモリ・トラフィックが大幅に減少するため、パフォーマンスが向上します。
記憶されたセットに関連するもう1つの側面は、現在避難しているヒープの領域を指す参照を見つけるアルゴリズムが、並列化により有効になるように改善されているという事実です。G1は、そのデータ構造をパラレルに調べ、内部ループの重複を除外するのではなく、記憶された設定の重複を個別にフィルタ処理し、残りの部分の処理をパラレル化するようになりました。これにより、ステップの効率が向上し、パラレル化が大幅に簡単になります。
さらに、これらの記憶されたエントリの処理は、不要なコードを切り捨て、一般的なパスを最適化するために十分に検討されています。
JDK 8より後のJDKでは、一時停止中のタスクの実際の並列化が改善されています。フェーズをパラレルにするか、不要な同期ポイントを回避するために小さいシリアル・フェーズから大きいパラレル・フェーズを作成することによって、変更はパラレル化を改善しようとしました。スレッドが機能しなくなった場合は、他のスレッドから盗む作業を探すときに、作業のバランスを改善するために、大量のリソースがパラレル・フェーズで費やされています。
ところで、後のJDKは、よりまれな状況に目を向け始め、そのうちの1つは避難障害です。オブジェクトのコピー先領域がなくなった場合、ガベージ・コレクション中に退避障害が発生します。
ガベージ・コレクションはZGCで一時停止します:アプリケーションでガベージ・コレクションの一時停止時間がさらに短い場合、表4は、以前に使用したワークロードと同じレイテンシ重視のコレクタZGCとの比較を示しています。これは、G1の前半に示された一時停止時間およびZGCを示す右端の列を示しています。
表 4. G1レイテンシと比較したZGC レイテンシ
| JDK 8, 200 ミリ秒, G1 | JDK 18, 200 ミリ秒, G1 | JDK 18, 50 ミリ秒, G1 | JDK 18, ZGC | |
| 平均 (ミリ秒) | 124 | 89 | 44 | 0.01 |
| P99 (ミリ秒) | 176 | 104 | 56 | 0.031 |
ZGCは、一時停止時間目標をミリ秒未満にするという約束を果たし、すべての回収作業をアプリケーションに対して同時に進めます。ガベージ・コレクション・フェーズのクローズを提供するいくつかのマイナーな作業のみが一時停止を必要とします。予想どおり、これらの一時停止は非常に小さくなります。この場合、ZGCが提供しようとしている推奨ミリ秒範囲をはるかに下回っていてもかまいません。
G1のフットプリントの改善:この記事で確認される最後のメトリックは、G1ガベージ・コレクション・アルゴリズムのメモリ・フットプリントの進展状況です。ここでは、アルゴリズムのフットプリントは、その機能を提供するために必要なJavaヒープ外の追加メモリ量として定義されます。
G1では、Javaヒープ・サイズに依存する静的データに加えて、Javaヒープのサイズの約3.2%を占めます。多くの場合、追加のメモリの他の主要な消費は、世代別ガベージ・コレクション、特にold generationの増分ガベージ・コレクションを可能にするセットが記憶されます。
G1の記憶されたセットを強調するアプリケーションの1つのクラスは、オブジェクト・キャッシュです。オブジェクト・キャッシュは、新しくキャッシュされたエントリを追加および削除する際に、ヒープのold generation内の領域間の参照を生成することがよくあります。
図4は、このようなオブジェクト・キャッシュを実装するテスト・アプリケーション上のJDK 8からJDK 18へのG1ネイティブ・メモリ使用状況の変更を示しています。キャッシュされた情報を表すオブジェクトは、大きいヒープから最近使用されていない方法で問合せ、追加および削除されます。この例では、20 GBのJavaヒープを使用し、JVMのネイティブ・メモリ・トラッキング(NMT)機能を使用してメモリ使用量を確認します。
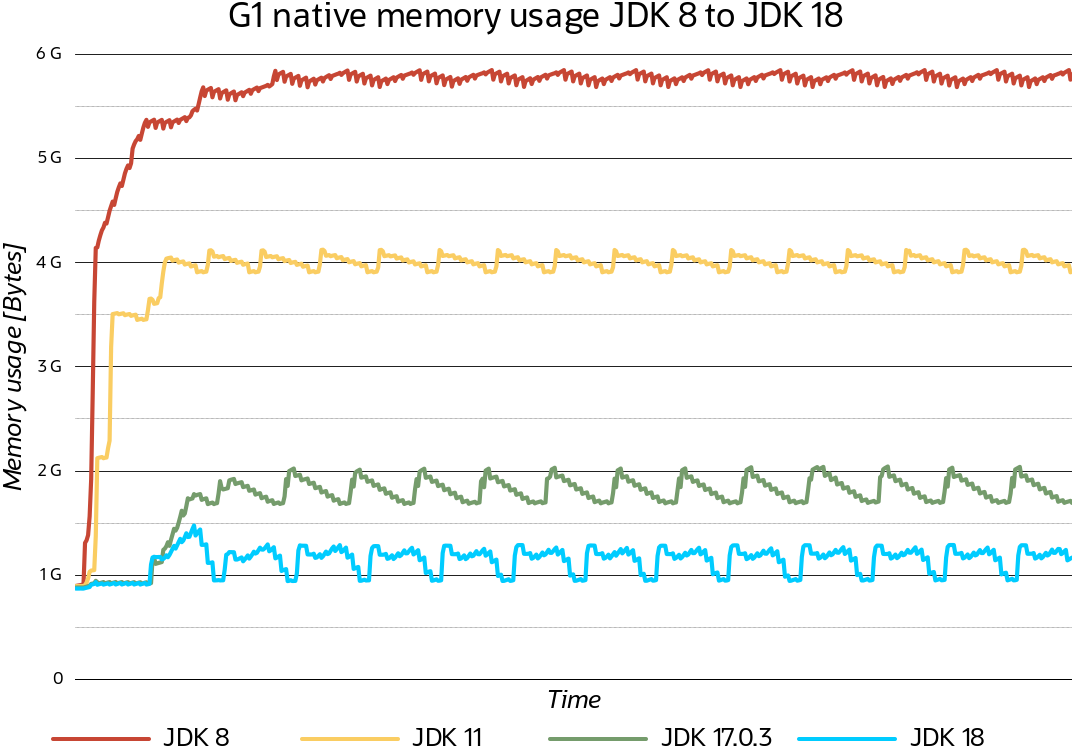
図 4. G1 GCのネイティブ・メモリ・フットプリント
JDK 8では、短いウォームアップ期間の後、G1ネイティブ・メモリ使用量は、ネイティブ・メモリの約5.8 GBに定着します。JDK 11は、ネイティブ・メモリ・フットプリントを約4 GBに削減し、JDK 17はそれを約1.8 GBに改善し、JDK 18はガベージ・コレクションのネイティブ・メモリ使用量の約1.25 GBに定着しました。これは、JDK 8のJavaヒープのほぼ30%から、JDK 18の追加メモリ使用量の約6%への余分なメモリ使用量の削減です。
前の項で示したように、これらの変更に関連するスループットまたはレイテンシに特定のコストはありません。実際、G1 GCが保持するメタデータを減らすことで、他のメトリックがこれまで改善されました。
JDK 8からJDK 18へのこれらの変更の主な原則は、ガベージ・コレクション・メタデータを非常に厳密な必要に応じて維持することであり、必要なときに必要なもののみを維持することでした。このため、G1は、このメモリを同時に作成および管理し、可能なかぎり迅速にデータを解放します。JDK 18では、このメタデータの表現と格納の強化が、メモリ・フットプリントの改善に大きく貢献しました。
図4は、後のJDKリリースでG1によって、安定した状態の操作のピークの山と谷の違いを確認することによって、オペレーティング・システムにメモリを戻す際の積極性がステップごとに増加したことも示しています。最後のリリースでは、G1はこのプロセスを同時に実行することも示されています。
ガベージ・コレクションの未来
将来何が保持されているか、およびガベージ・コレクションを改善する多くのプロジェクトを予測することは困難ですが、特にG1では、次の開発の一部が今後HotSpot JVMで終了するかもしれません。
アクティブに作業中の問題の1つは、ネイティブ・コードでJavaオブジェクトが使用されている場合にガベージ・コレクションをロック・アウトする必要がなくなることです。ガベージ・コレクションをトリガーするJavaスレッドは、ネイティブ・コードで他の領域がJavaオブジェクトへの参照を保持しないまで待機する必要があります。最悪の場合、ネイティブ・コードによってガベージ・コレクションが数分ブロックされる場合があります。これにより、ソフトウェア開発者がネイティブ・コードを使用しないことを選択し、スループットに悪影響を与える可能性があります。JEP 423で提示された変更(G1の領域固定)により、これはG1 GCの非問題になります。
スループット・コレクタであるパラレルGCと比較して、G1を使用するもう1つの既知の短所は、スループットへの影響です。ユーザーは、極端な場合、10%から20%の範囲の差異を報告します。この問題の原因は知られており、G1 GCの他の品質を損なうことなく、この欠点を改善する方法に関するいくつかの提案があります。
最近では、一時停止時間が決まり、特に、ガベージ・コレクションの一時停止での作業配分の効率は依然として最適より低くなっています。
現在注目すべき点の1つは、G1の最大のヘルパー・データ構造の半分であるマーク・ビットマップを削除することです。G1アルゴリズムには2つのビットマップが使用されており、これは、現在どのオブジェクトが存在し、G1によって参照を安全に同時に検査できるかを判断するのに役立ちます。現在の拡張要求は、これらのビットマップのいずれかの目的を他の方法で置き換えることができることを示します。これにより、G1メタデータはJavaヒープ・サイズの固定の1.5%ですぐに削減されます。
ZGCとShenandoah GCを世代に変える活動が進んでいる。多くのアプリケーションでは、これらのGCの現在の単一世代設計は、スループットと再利用の適時性に関してあまりにも多くの欠点があり、多くの場合、より大きなヒープ・サイズが必要になります。
まとめ
この記事では、JDK 8からJDK 18までのHotSpot JVMガベージ・コレクション・アルゴリズムの改善が、パフォーマンス・インジケータ(スループット、レイテンシおよびメモリ・フットプリント)の3つすべてが非常に改善したことを示しています。すべての新しいJDKリリースは、JEPのこのような改善を明示的に指摘していなくても、具体的な改善をもたらしています。将来もこのような状態が維持される可能性が高いので、最新の情報を入手し、無償の改善を楽しんでください!
これらすべての大幅な改善を長期にわたり可能にした多くのOpenJDKコントリビュータに感謝します。