※ 本記事は、Praveen Kumar Pedda Vakkalam, ADEEL AMINによる”Understanding the Performance of OCI Block Volume with Oracle Cloud VMware Solution Standard Shapes”を翻訳したものです。
2024年8月21日
1年前、Oracle Cloud VMware SolutionのStandardシェイプを導入することで、パブリック・クラウドでスケーラブルなVMwareソリューションの展望を変革しました。このイノベーションにより、ユーザーは、Oracle Cloud Infrastructure(OCI)のBlock Volume Serviceをプライマリ・ストレージ・ソリューションとして使用して、コンピューティングからストレージを独立して拡張できるようになりました。この分離により、特定のワークロード需要に基づいてパフォーマンスをfine-tuneする柔軟性と能力が向上しました。
最近、OCI Block Volume Serviceは、お客様に追加のコストをかけることなく、サービスにおけるいくつかの機能強化を発表しました。このブログ投稿では、OCI Block Volumeによるこれらの機能強化により、Oracle Cloud VMware Solutionにおける標準シェイプ・クラスタのパフォーマンスを大幅に強化する方法について詳しく説明します。ボリューム・パフォーマンス・ユニット(VPU)が、VMware仮想マシン・ファイル・システム(VMFS)データストア内のデータ転送速度にどのように影響するかを確認します。
OCI Block Volumeによるパフォーマンスの向上
OCI Block Volume for Oracle Cloud VMware Solutionを使用すると、ユーザーに次の主な利点があります:
- 高速で信頼性の高いパフォーマンス: OCI Block Volumesは、NVMe SSDを使用して、サービス・レベル合意(SLA)によって保証された優れたパフォーマンスを実現します。この構成により、最も要求の厳しいワークロードでもスムーズで一貫した操作が保証されます。
- 常時利用可能なデータ: ブロック・ボリュームは、コンピュート・インスタンスが終了しても存続する永続ストレージを提供し、ESXiホスト管理を簡素化します。新しいホストを起動し、ブロック・ボリュームをアタッチして、データ移動なしで情報にアクセスします。
- 高い耐久性: ブロック・ボリュームは優れた耐久性を実現するために構築されており、データのコピーを複数格納して、データ損失のリスクを最小限に抑えます。フォルト・トレランスのために、より多くのストレージをスコープ指定する必要はありません。バックアップは、この設定によって置き換えられるわけではありません。可用性ドメインの障害に対処するために、VMwareワークロードの適切なバックアップを常に取ることをお薦めします。
- 高いコスト効率: OCI Block Volumeで使用するストレージに対してのみ支払います。また、Block Volumeの自動チューニングでは、ワークロードのニーズに基づいてパフォーマンス制限を設定し、IOPSを調整できるため、コスト削減につながり、ピーク時のワークロードを簡単に満たすことができます。
- 信頼できるセキュリティ: データ暗号化(保存中および転送中)により、アプリケーションの最高レベルのセキュリティが保証されます。OCI Block Volumeは、サポートされているベア・メタル・インスタンスの堅牢なAES-256暗号化標準を使用して、すべてのデータを暗号化します。
- 容易なスケーリング: ダウンタイムなしで必要に応じてストレージ容量を増やし、業務をスムーズに実行できるようにします。
- ESXiリソースを解放: OCI Block Volumeは、ストレージ・タスクを処理することで、ESXiホストがコア・コンピューティングのニーズに集中できるようにします。
重要な考慮事項
OCI Block Volumesには大きなメリットがありますが、次の点に注意してください:
- パフォーマンス共有: VMware環境では、ボリュームのマルチアタッチを実行してVMFSデータストアを作成します。ブロック・ボリュームのパフォーマンスは、接続されているすべてのESXiホスト間で共有されます。ブロック・ボリューム・パフォーマンスのSLAは、低コスト・レベルではなく、バランス・レベル、高パフォーマンス・レベルおよび超高パフォーマンス・レベルにのみ適用されます。
- インスタンス・パフォーマンスへの影響: 基礎となるコンピュート・インスタンスの最大IOPSおよびスループットにより、アタッチされたブロック・ボリュームのパフォーマンスを抑えることができます。これには、UHPアタッチメントと非UHPアタッチメントを組み合せると、合計IOPSおよびスループットが制限されるUltra High Performance (UHP)用に構成されたボリュームが含まれます。
- 可用性ドメイン・アクセス: ブロック・ボリュームには、同じ可用性ドメイン内のインスタンスのみがアクセスできます。マルチ可用性ドメイン・クラスタ構成では、複数の可用性ドメインに分散したVMFSデータストアを作成できません。
- ボリュームのアタッチとデタッチ: ブロック・ボリュームは、読取り/書込み共有可能として構成されていないかぎり、複数のインスタンスに同時にアタッチすることはできません。異なる構成の新しいインスタンスに削除または再アタッチする前に、すべてのインスタンスからボリュームをデタッチする必要があります。
- UHPボリュームのデバイス・パス: UHPボリュームを使用するVMwareサービスではデバイス・パスは重要ではありませんが、メニューからデバイス・パスを選択する必要があります。回避策として、ボリュームを最初にバランス型または高パフォーマンスとしてデプロイしてから、アタッチした後にVPUレベルをUHPに上げることができます。
OCI Block Volumeサービスの概要と、それがVMware環境内のVMFSデータストアに与える影響について理解できたので、ブロック・ボリュームのパフォーマンスを見てみましょう。
VPUとOCI Block Volumesによるパフォーマンスの最適化
Oracle Cloud VMware Solutionのstandardシェイプは、OCI Block Volumes for VMFSデータストアを使用します。最適なパフォーマンスを得るには、適切なVPUレベルを選択することが重要です。StandardシェイプのESXiホストは、最大32個のブロック・ボリュームに接続でき、各ブロック・ボリュームには0から120までのVPUレベルがあります。統合管理クラスタでは、管理データストアに1つのアタッチメントが使用されるため、最大31個のデータ・ボリュームを使用できます。しかし、VPUの仕組みやブロック・ボリュームの最大値がどのように役割を果たすかを十分に理解することは、パフォーマンス要件を満たしながらコストの最適な価値を引き出すための適切なバランスを見つけるために非常に重要です。
ニーズに合わせて適切なVPUを選択
この項では、次のVPUレベルとそのパフォーマンス特性を確認します:
| 柔軟なパフォーマンス・レベル | ボリューム・パフォーマンス単位 (VPUs) | IOPS per GB | Max IOPS per volume | Size for Max IOPS (GB) | KBPS per GB | Max MBPS per volume |
|---|---|---|---|---|---|---|
| Balanced | 10 | 60 | 25,000 | 417 | 480 | 480 |
| Higher Performance (HP) | 20 |
75 |
50,000 |
667 |
600 |
680 |
| Ultra High Performance (UHP) | 30 to 120 |
90 to 225 |
75,000 to 300,000 |
883 to 1,333 |
720 to 1,800 |
88 to 2,680 |
次の要因を考慮してください:
- VPU: VPUレベルが高いほど、IOPSおよびスループット機能が大幅に向上します。ただし、VPUレベルでは、ブロック・ボリュームのIOPSまたはスループットの可能性が判断されますが、両方が同時に実行されるとはかぎりません。
- ワークロードの重視: ランダム読取り(データベースなど)を重視するワークロードの場合は、高いIOPSを優先します。大規模なファイル転送などの順次ワークロードの場合は、スループットに優先順位を付けます。
- ベア・メタル・インスタンスの制限: ESXiクラスタのパフォーマンス全体のスケーラビリティを理解するには、ベア・メタル・インスタンスの最大パフォーマンス制限(この例ではBM.Standard3.64またはBM.Standard.E4.128)を考慮してください。
最大ブロック・ボリューム・パフォーマンスの理解
VPUはパフォーマンスの主要な決定要因ですが、次の要因は、Oracle Cloud VMware Solutionクラスタの最大達成可能なパフォーマンスにも影響します:
- ESXiホストのパフォーマンス制限: BM.Standard3.64やBM.Standard.E4.128のような個々のESXiホストのIOPSの最大容量は1,300,000で、スループットは6,000MB/sです。これらの制限を超えるボリュームを割り当てても、パフォーマンスは向上しません。
- UHPボリューム: クラスタに十分なホスト(たとえば、6つのESXiホスト)がある場合、VPU 120ボリュームをアタッチすると、ボリュームによって提供される最大300,000の結合IOPSを達成できます。
- ブロック・ボリュームIOPS制限: ブロック・ボリュームをESXiホストにアタッチする各アタッチメントの最大IOPS制限は50,000です。たとえば、VPU 120ボリュームがある3ノードのBM.Standard3.64クラスタを考えてみます。アタッチメントが3つあると、ボリューム自体が最大300,000 IOPSを配信できる場合でも、アタッチメントの観点から達成可能な最大IOPSは150,000です。ただし、6つのESXiホストでは、各アタッチメントが50,000 IOPSに達し、VPU 120ボリュームの可能性を最大限に活用できます。
VPUを使用してこれらの要因を理解することで、Oracle Cloud VMware Solution環境内の特定のワークロードのパフォーマンスを最適化するために、OCIブロック・ボリュームを戦略的に構成できます。これにより、OCIブロック・ボリュームをVMFSとして最大限に活用できます。
実際のワークロードのシミュレーション
OCIブロック・ボリュームのパフォーマンス機能をOracle Cloud VMware Solution Standardシェイプで紹介するために、次の仕様で実際のアプリケーション・シナリオを模倣した包括的なテスト環境を構成しました:
- ハードウェア: 3つのBM.Standard3.64ホスト(それぞれ64個のOCPUが有効)。
-
ストレージ: 2つのテスト・セットを実施しました。1つは統合大容量で、もう1つは同じサイズの31ブロック・ボリュームとVPUの分散環境です。
- 統合テスト用: ベースライン・パフォーマンスを確立するために、1つの大容量(32TB、最大ボリューム・サイズ可能)でテストを実行し、テスト間でVPUレベルを10から50に変更しました。
- 配布テスト用: 31個のブロック・ボリュームをホストに接続しました。各ボリュームには、特定のテストに応じて、VPU 10または20のいずれかがありました。ボリューム当たり1.43TBのサイズで、vCenter内のVMFSデータストア・クラスタの合計容量は44.33TBに達しました。
- 仮想マシン:
- 統合テスト用: 合計165台のVMをデプロイし、それぞれが2つのvCPUs、12 GBのRAM、10台のディスクで構成されており、それぞれが32 TBボリューム内に収まるように15 GBのサイズになっています。
- 配布テスト用: 合計155のVMをデプロイし、31のボリュームに均等に分散しました。CPUとRAMの構成は同じままですが、20 GBのディスクをわずかに大きくして、より大きなデータストア・クラスタを埋めることにしました。
-
これは、310-330 vCPUs、1860-1980 GBのRAM、および24.2-30.2 TBのストレージまで、大規模なテスト・ワークロードに変換されます。
- ワークロード・シナリオ: ワークロード・シナリオには、次のような様々な読取り/書込みミックスとブロック・サイズが含まれ、実際のパターンをシミュレートします:
- 一般的なデータベース操作のように、読取りと書込みが混在するオンライン・トランザクション処理(OLTP)を使用したデータベース・ワークロード。
- 主に読取りが多いアクセス・パターンを持つデータ・ウェアハウス・アプリケーション
- 大量の書込み操作を含むバッチ処理シナリオ
- 次のワークロード・シナリオでパフォーマンスを評価しました:
- ブロック・サイズ: 4K, 8K, 16K, 128K
- Read-Write mix: 70/30, 100/0, 0/100
各テストは30分間実行されました。これらの多様なワークロード・シナリオをテストすることで、OCI Block VolumeのパフォーマンスがOracle Cloud VMware Solutionのstandardシェイプのさまざまな条件下でどのようにスケーリングされるかを包括的に理解することができました。
フォーカスしたパフォーマンス: 分析されたテスト結果
テスト環境を調査し、VPUの仕組みを理解したので、テスト結果を詳しく見ていきましょう。この項では、Oracle Cloud VMware Solutionのstandardシェイプを使用した、様々な条件でのOCIブロック・ボリュームのパフォーマンスを分析します。
統合テスト
最初に、様々なVPUレベル(10 – 50)で構成された単一の大規模なブロック・ボリューム(OCIブロック・ボリュームの最大サポート・サイズである32TB)を使用したテストを実行しました。次の図は、前述したように、様々なワークロードの異なるVPUレベルでのデータストアのパフォーマンスを示しています。
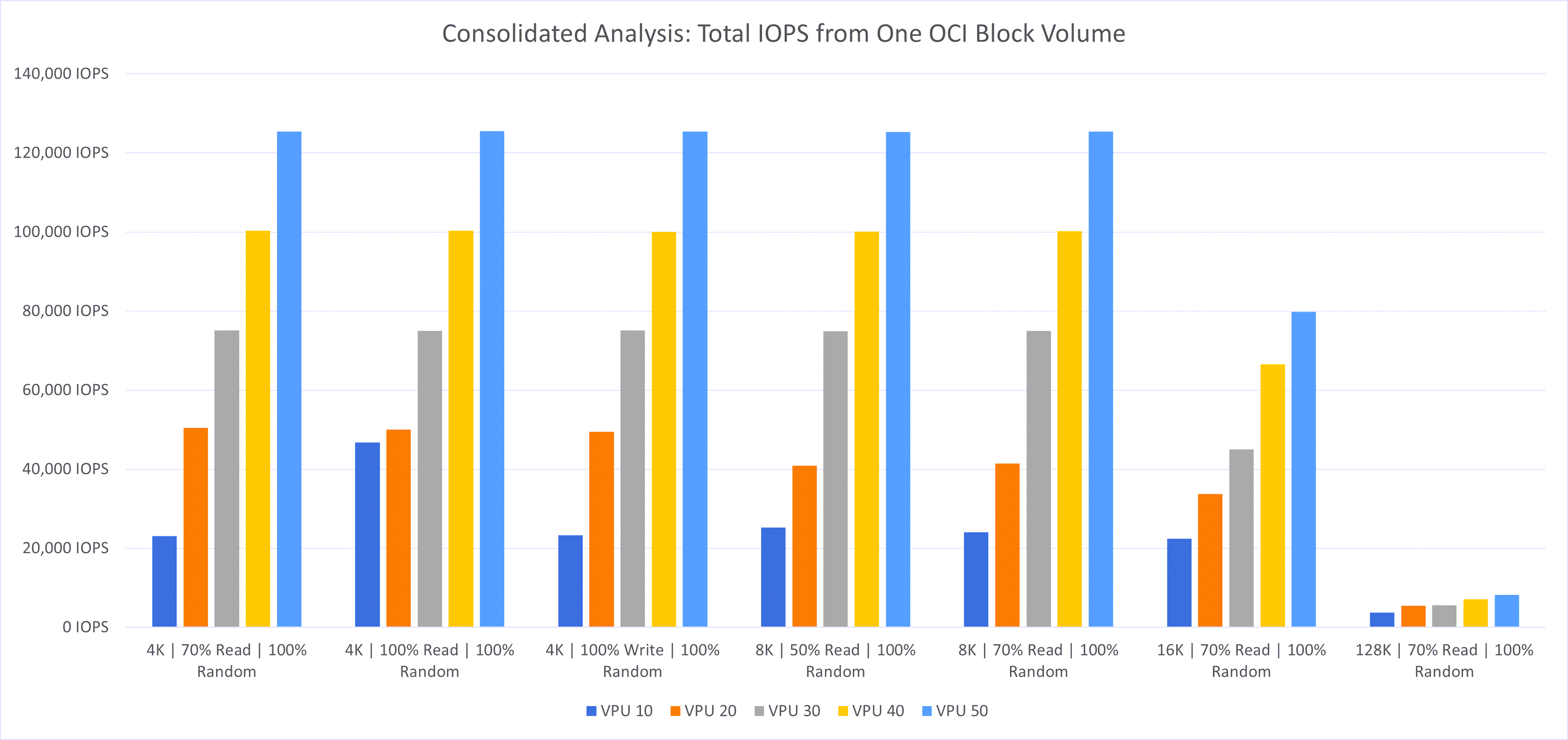
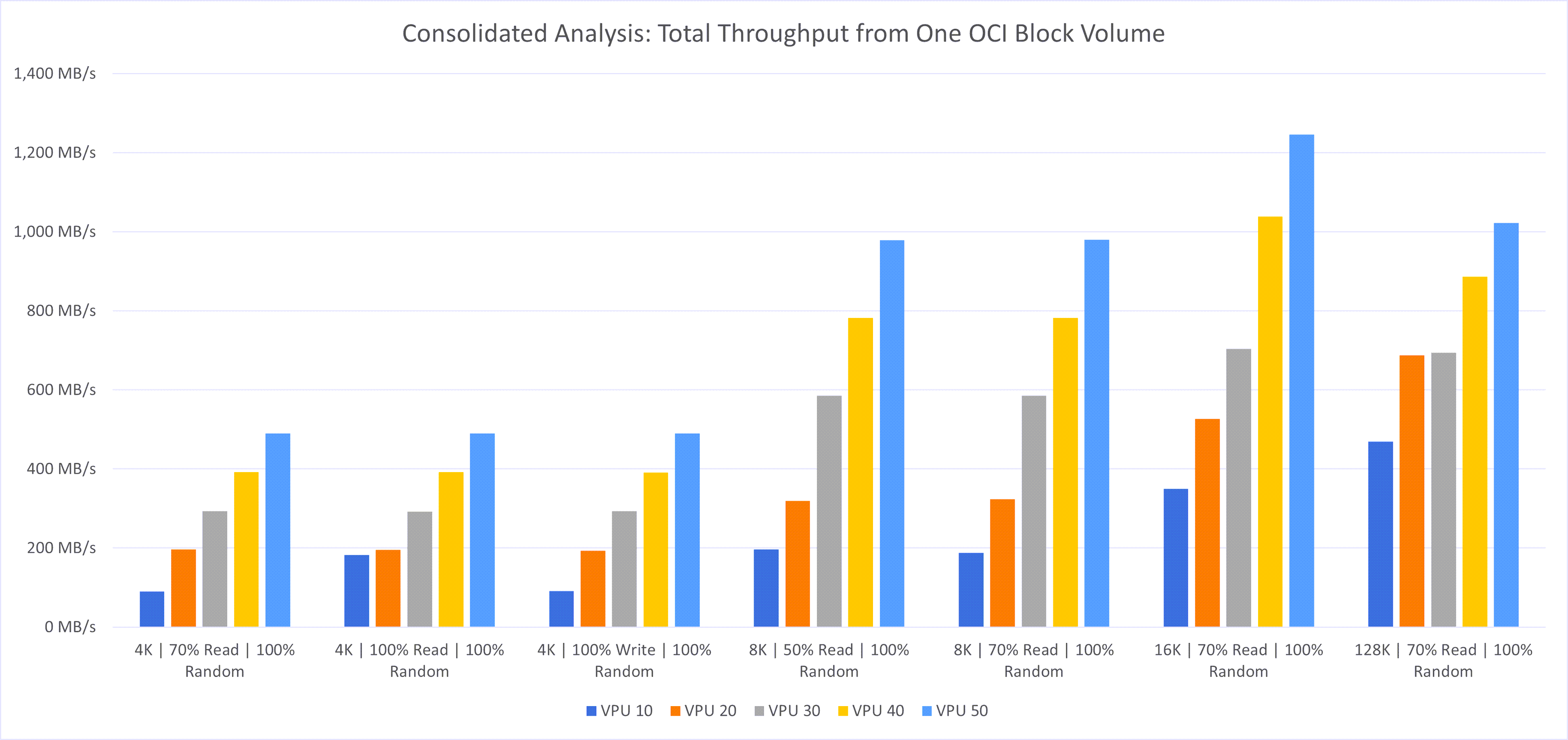
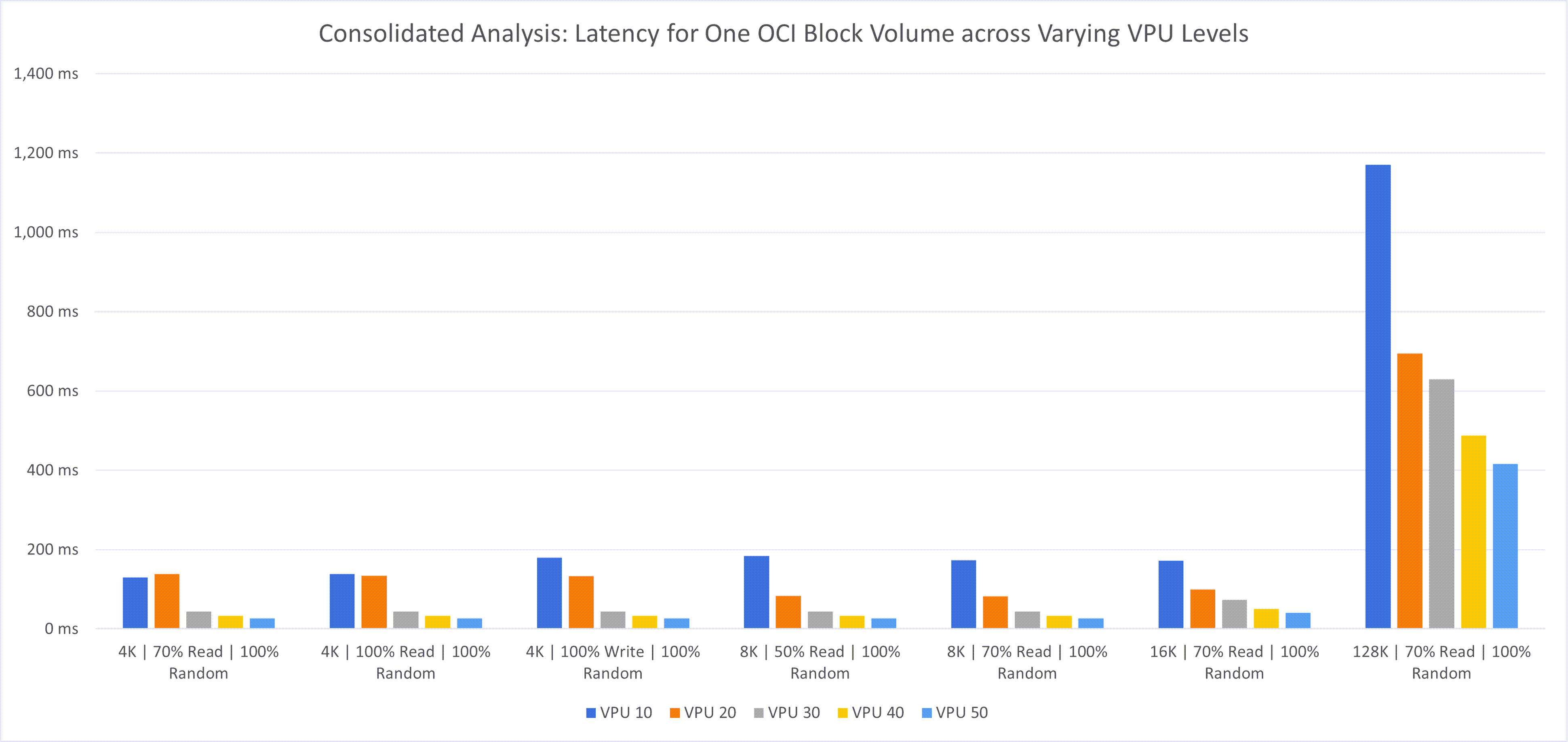
次の観察がありました:
- VPUの影響: 予想どおり、データストアのパフォーマンスは、基礎となるブロック・ボリュームのパフォーマンスまたは選択されたVPU (IOPSおよびスループット)と相関しています。この相関関係により、VPUがパフォーマンスに大きく影響することが確認されます。
- ワークロードの影響: パフォーマンスはワークロード・タイプによって異なります。データベースなどのランダム読取りを重視したワークロードではIOPSが高くなり、大きなファイル転送などの順次ワークロードではスループットが向上しました。
- レイテンシ: この単一のOCIブロック・ボリュームに165台のVMがある場合、レイテンシは特に高くなります。VPUボリュームが大きいほどレイテンシは低くなりますが、分散テスト結果の次の項で示すように、複数のボリュームにVMまたはワークロードを分散することで最適なパフォーマンスを実現できます。
配布テスト
複数のOCIブロック・ボリュームに支えられたVMFSデータストア・クラスタのパフォーマンスを理解するために、31個のブロック・ボリュームをクラスタにアタッチすることで、いくつかのスケーラビリティ・テストを実施しました。これは、管理データストアに1つのボリュームが使用されるため、標準シェイプ・クラスタで可能なアタッチメントの最大数です。次の図に、テストとその結果を示します:
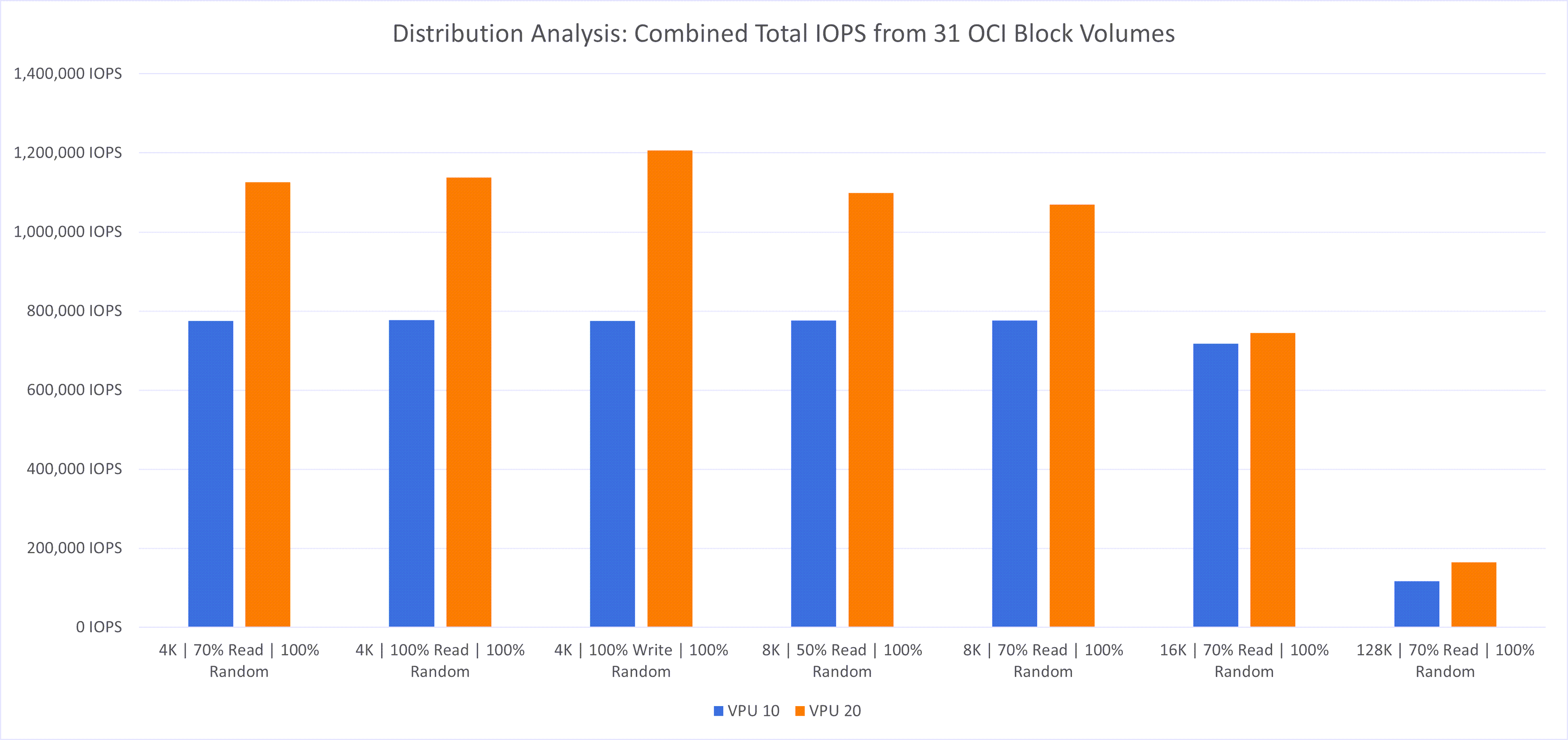
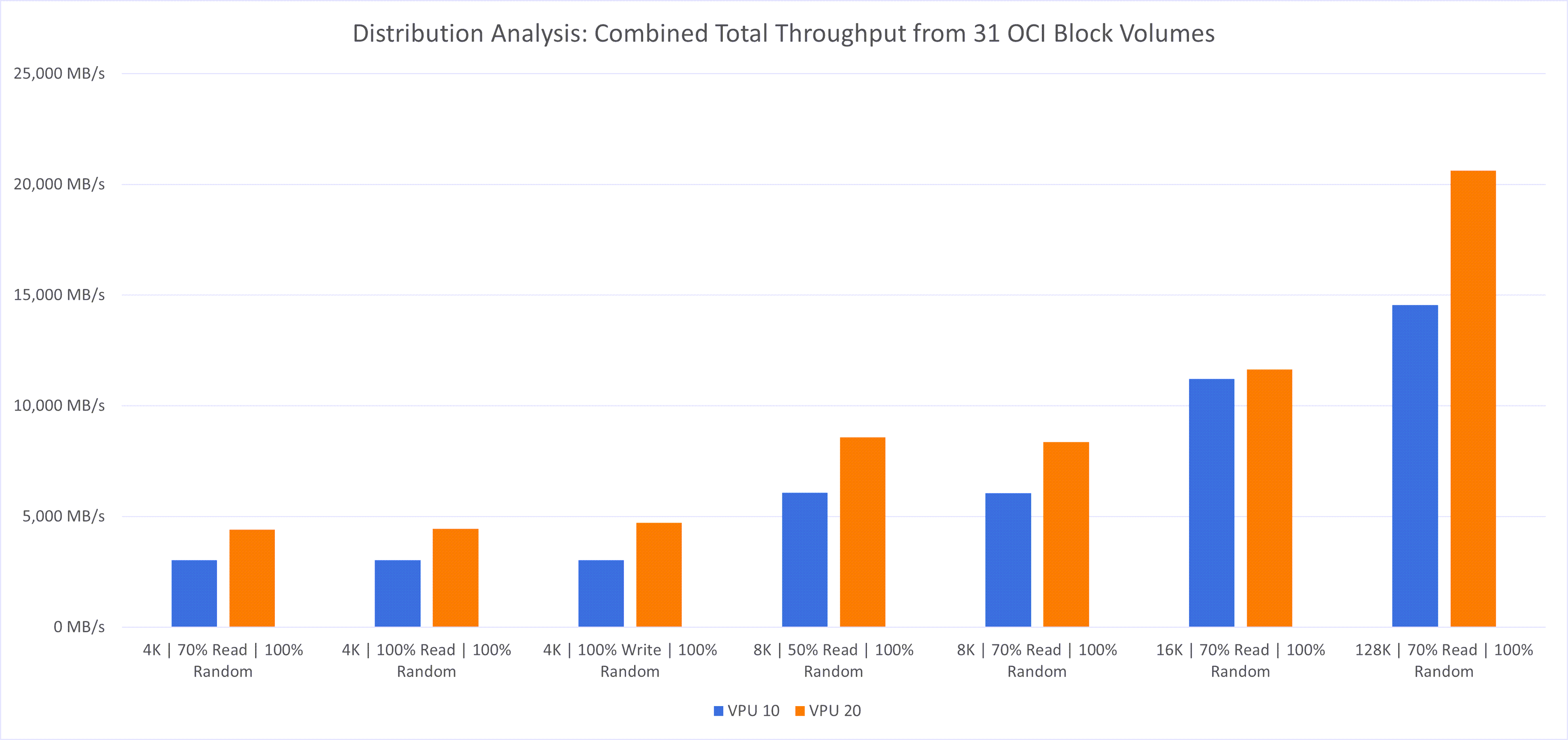
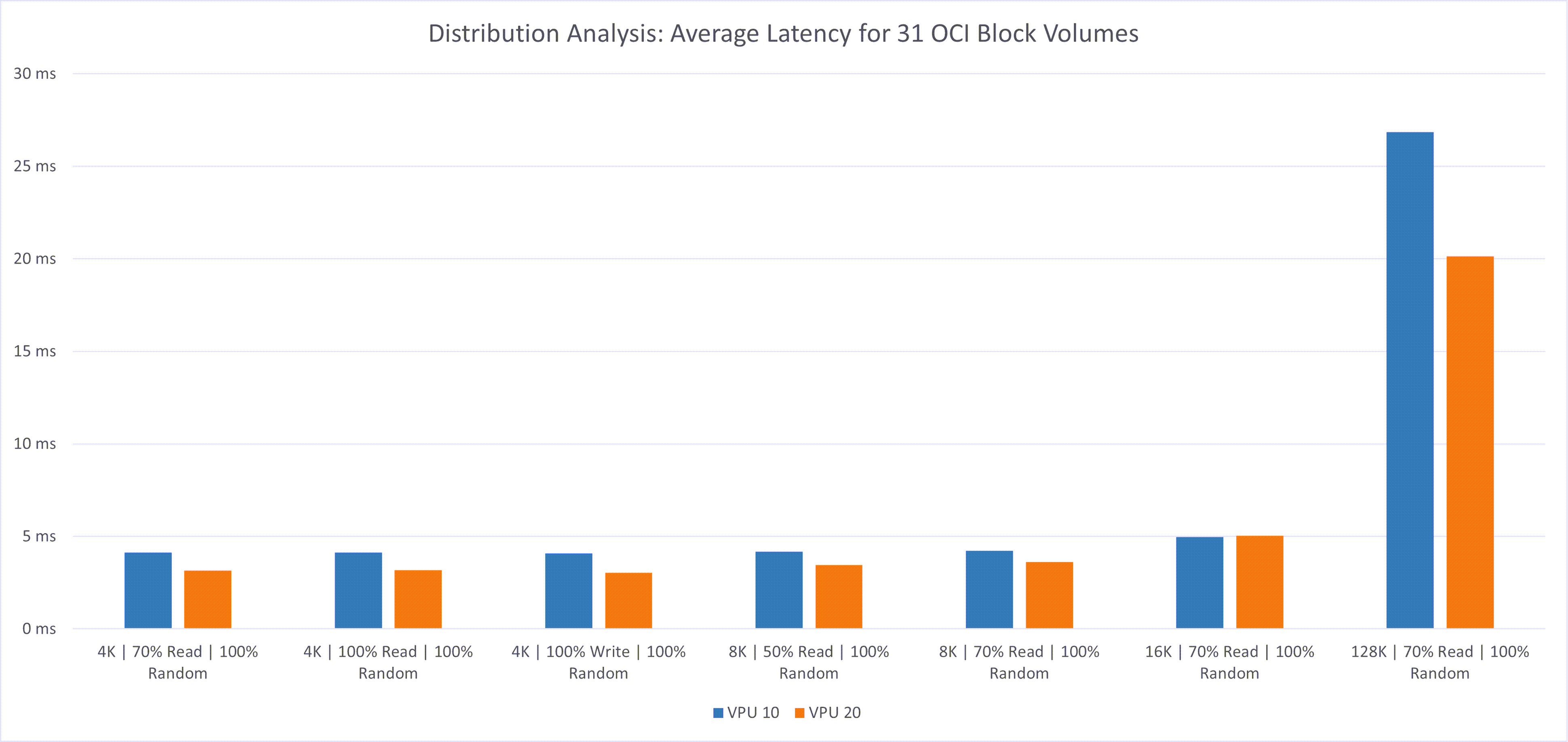
次の観察がありました:
- IOPSとスループットの向上: 複数の小さいブロック・ボリュームを組み合せてデータストア・クラスタを構築すると、累積IOPSを最大限に高めることができます。32TBのVPU 10ブロック・ボリュームを1つ使用すると、最大25,000のIOPSおよび480MB/秒のスループットを実現できます。スケーラビリティ・テストで示されているように、複数のVPU 10ボリュームに同様の量のストレージを分散させると、最大775,000 IOPSおよび14,800 MB/sスループットの合計パフォーマンスを達成できます。
- VPUのスケーリング: VPUレベルを20に上げると、パフォーマンスがさらに向上します。オラクルのテストでは、VPU 20を使用すると、パフォーマンスを合わせると、約130万のIOPSと約20,000MB/sのスループットに達する可能性があります。
- レイテンシの削減: 複数のボリュームにワークロードを分散することで、レイテンシが大幅に削減されました。音量2msから5msまでの平均遅延を観測し、システムの全体的なパフォーマンスと応答性を向上させます。
- ベア・メタル・コンピュート制限: VPUスケーリングはデータストア・クラスタのパフォーマンスを向上させますが、ベア・メタル・コンピュート・インスタンスの最大機能を考慮して、クラスタの真のスケーリングの可能性を理解することが不可欠です。ブロック・ボリュームのパフォーマンス機能をコンピュート・インスタンスの制限に適切に位置合せすることで、最適なパフォーマンスが得られ、ボトルネックが回避されます。
ストレージのスケーリング方法
ストレージを効果的にスケーリングするには、それぞれ約2 TBのボリュームから始めて、複数のバランスのとれたボリュームまたはVPU 10のボリュームを設定することをお薦めします。このアプローチにより、データストア・クラスタ・レベルですべてのボリュームのパフォーマンスを集約できます。ストレージのニーズが高まるにつれて、ボリュームをさらに追加し、最初は最大25から28個のボリュームまでスケーリングできます。スペア・アタッチメントは将来の拡張用に予約されています。この段階では、OCIの基盤となるブロック・ボリュームのサイズをシームレスに増やし、vCenterのデータストア容量を拡張して、データストア・クラスタの全体的な容量を増やすことができます。
ボリュームをスケール・アップできますが、スケール・ダウンは許可されません。総容量の削減が必要な場合は、Broadcomによる VMwareの公式ドキュメントに従って、一部の未使用のボリュームを正常にマップ解除できます。パフォーマンスを向上させるために、基礎となるボリュームのVPUを均一にスケーリングすることもお薦めします。たとえば、あるシナリオでは、約200万のIOPSを実現するために、6ノード・クラスタのパフォーマンスをスケーリングしました。
次の図に、テストとその結果を示します:
- クラスタは、VMFSデータストア・クラスタを作成するために20ボリュームのVPU 120がアタッチされた6つのBM.Standard3.64ホストで構成されています。
- 合計400台のVMでテストを実施し、それぞれに15 GBの10台のディスクを搭載しています。
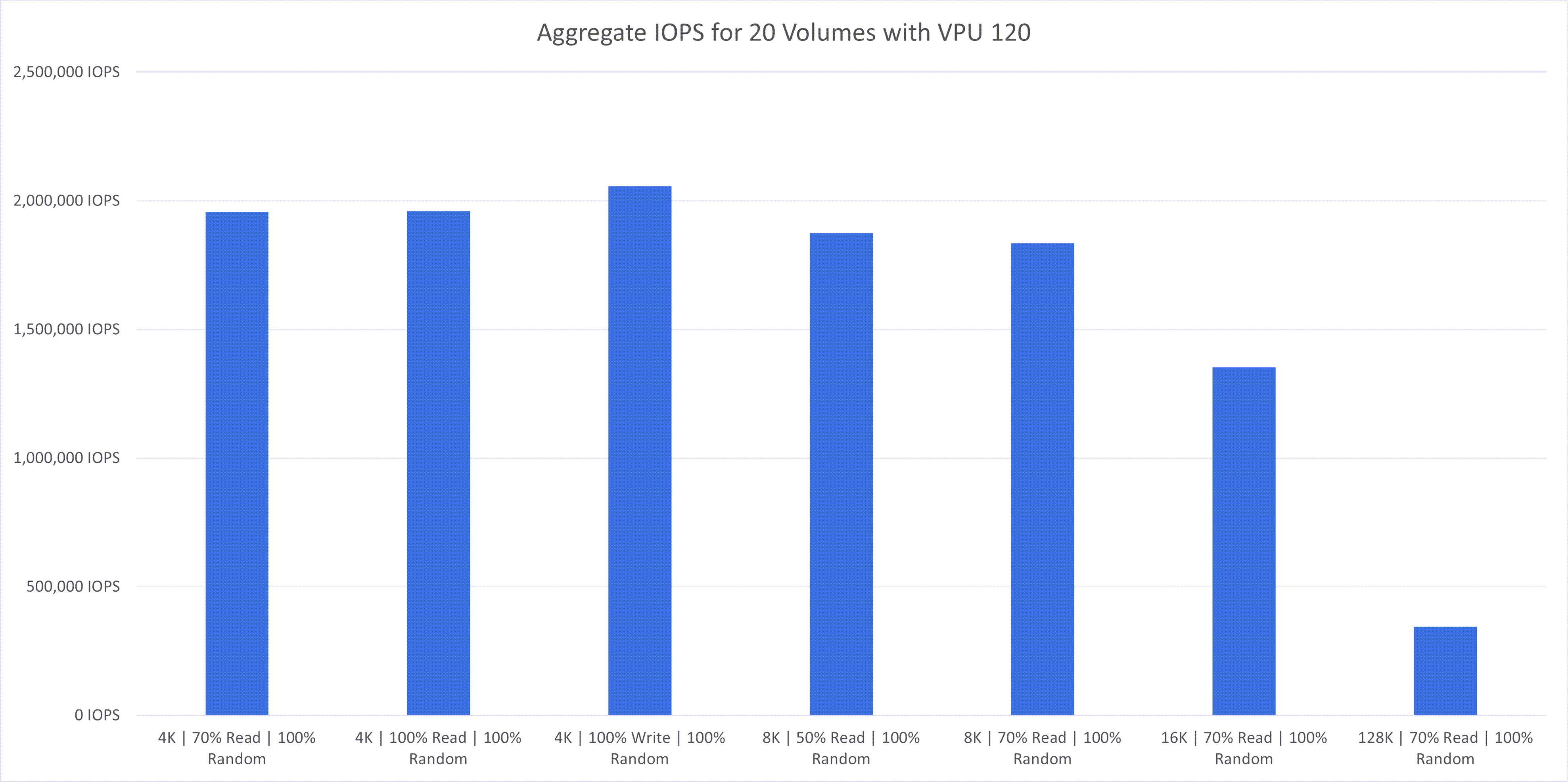
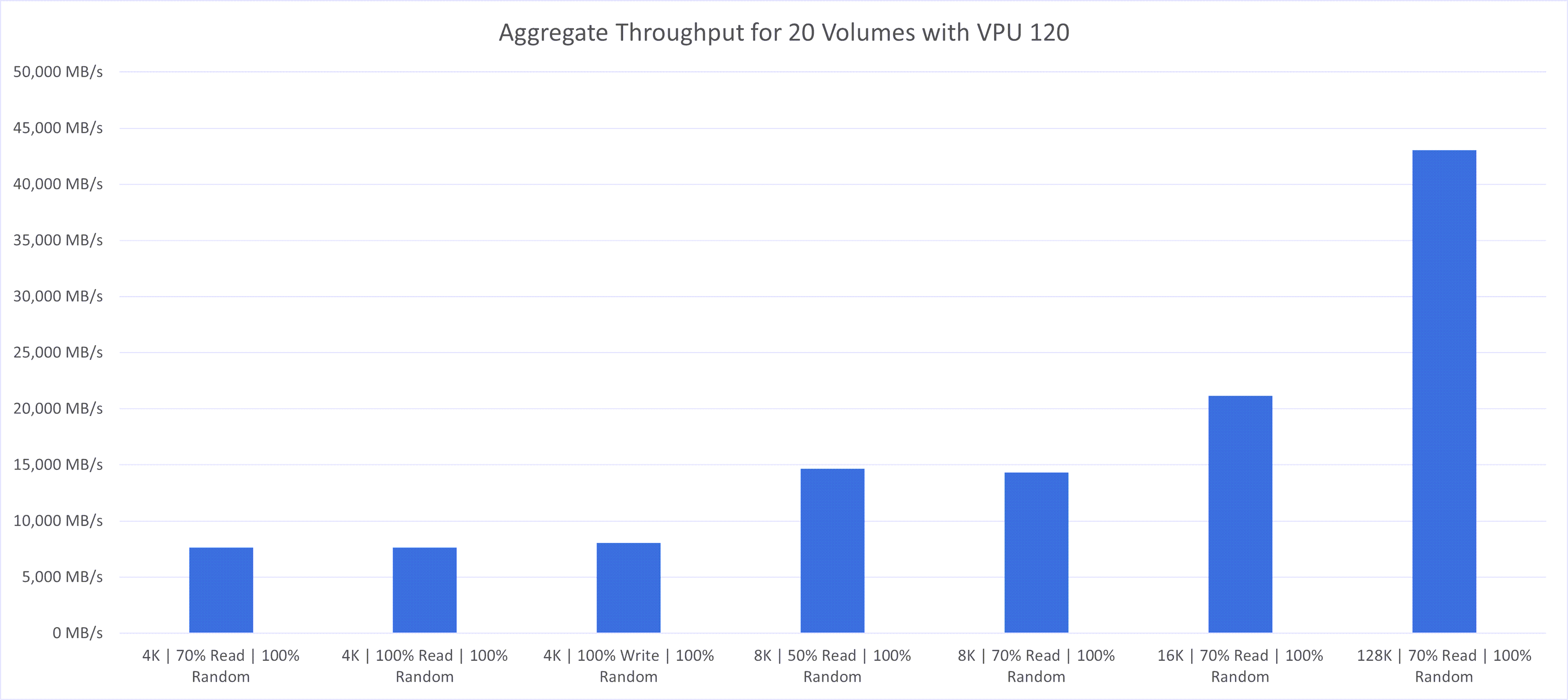
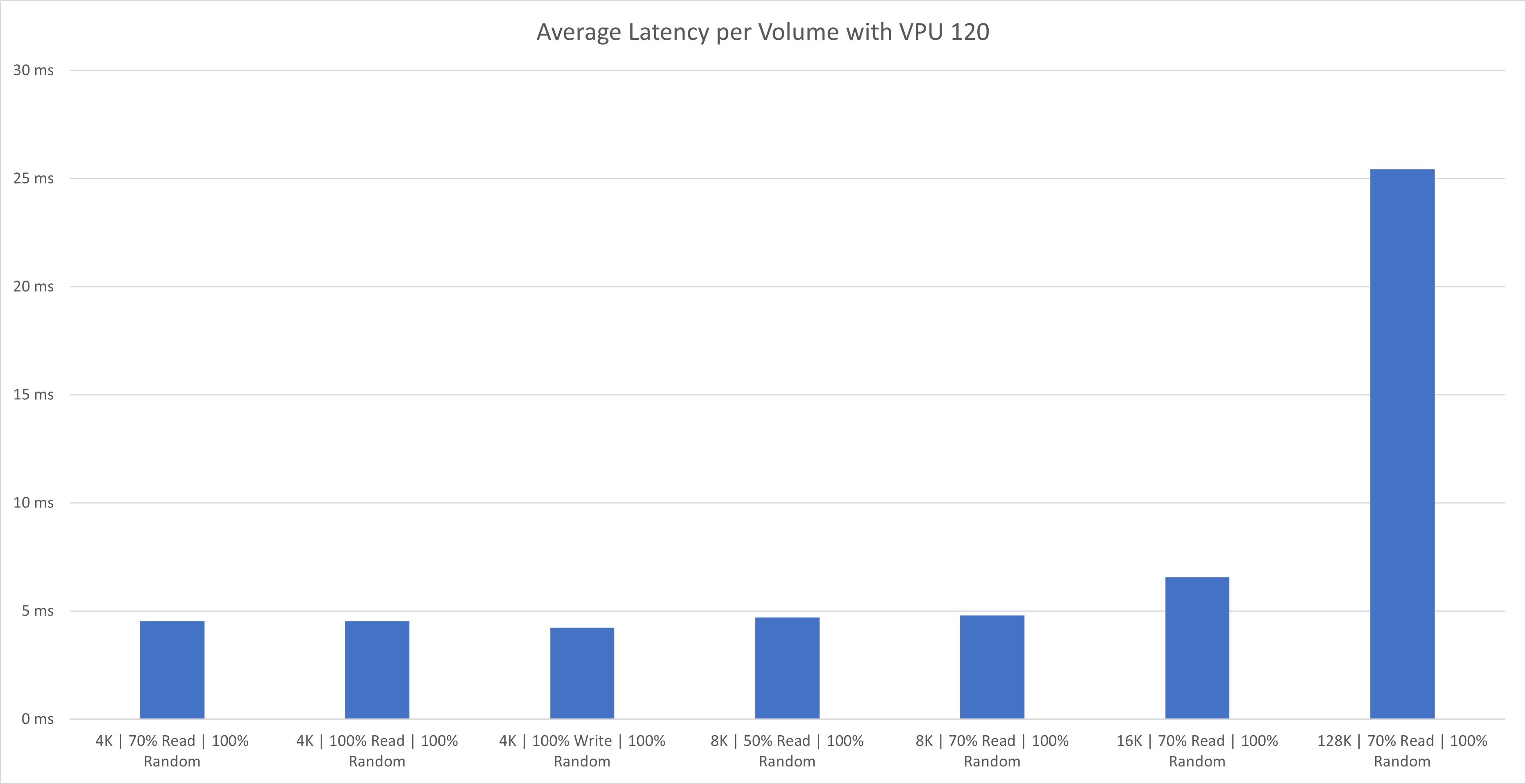
様々なワークロード・タイプの結果は、次の主な観測結果を示しています:
- スループットおよびIOPS: 約43,000MB/sの累積スループットを達成し、最大で約53,000MB/sのボリュームを実現しました。達成された200万のIOPSは、適切なワークロード計画とクラスタ内のホストの増加により、最大600万台に達する可能性があります。
- レイテンシ: 4Kブロック・サイズの場合、400台のVMすべてについてデータストア・クラスタ・レベルで観測されたレイテンシの平均は3-4ミリ秒です。
- パフォーマンス・メトリック: この設定はラボ環境にあり、完全な本番負荷ではありませんでした。ただし、ボリュームが増えると、より高いパフォーマンスを実現できます。特に、パフォーマンス・メトリックは、20個のブロック・ボリュームすべてにわたって累積されます。
知識を行動に
このブログ投稿では、Oracle Cloud VMware Solution環境で最適なパフォーマンスを実現するためにOCI Block Volumesを構成する際に、情報に基づいた意思決定を行うために必要なインサイトを提供しています。重要なのは、特定のワークロード需要に基づいて適切なVPUレベルを選択することです。アプリケーションで頻繁なランダム読取りが必要な場合は、より高いIOPSに優先順位を付けます。順次ワークロードの場合は、スループットの最大化に重点を置きます。このアプローチは、ピーク・パフォーマンスを達成するだけでなく、コストを効果的に管理します。必要な合計パフォーマンスを常に複数のブロック・ボリュームに分散してください。たとえば、約100万のIOPSを実現するには、次のアプローチを検討します:
- 統合: たとえば、8ボリュームのVPU 50 (それぞれ125,000 IOPSを提供する)をアタッチすると、100万のIOPSに到達します。
- 配布: VPU 10ボリュームとVPU 20ボリューム(約25ボリューム)を組み合せて、100万のIOPSを実現するなど、ワークロードを複数のボリュームに分散します。
次の理由から、統合よりも配布を優先する必要があります:
- 低レイテンシ: 統合により、すべてのワークロード・アクティビティが少数のボリュームに集中するため、ボトルネックが発生し、読取り/書込み待機時間が長くなる可能性があります。配布はワークロードのバランスをとり、レイテンシを低く保ちます。
- コスト最適化: 最大IOPSの合計と必要な容量は同じですが、ワークロードを低いVPUボリュームに分散すると、コスト優位性が得られます。
要するに、配布は、100万のIOPSのような同じパフォーマンスを提供し、潜在的にレイテンシが向上し、コストが削減されます。基礎となるブロック・ボリュームのサイズが正しく設定され、ワークロードが分散されると、高パフォーマンスで信頼性が高く、スケーラブルなブロック・ストレージが提供されます。これらの要因により、要求の厳しいワークロードや、VMware環境でのミッションクリティカルなアプリケーションのシームレスな運用に最適です。
展望
OCIブロック・ボリュームとOracle Cloud VMware Solutionの未来は有望であり、さらに強力な機能と機能を提供することを目的とした継続的なイノベーションが実現しています。ストレージ・エクスペリエンスをさらに強化できるエキサイティングなアップデートをお楽しみください。
まだ質問がありますか? OCIエキスパートがお手伝いします。今すぐオラクルにお問い合せいただき、特定のストレージ・ニーズについて検討し、Oracle Cloud Infrastructure Block VolumeサービスがOracle Cloud VMware Solution環境を強化する方法をご確認ください。
