※本ページは、”Exadata AI Smart Scan Deep Dive“の翻訳です。
Oracle Database 23aiでは、AIベクトル・データを既存のビジネス・データとともに格納および処理し、組織が既存のAIドリブンなアプリケーションを補強したり、新しいAIドリブンなアプリケーションを作成したりできるようにするための、大幅な新しい人工知能(AI)機能が導入されました。この機能をAI Vector Searchと呼びます。Exadataは、ストレージ・サーバー自身にアルゴリズムを埋め込み、データベース・サーバーからストレージサーバーに処理をオフロードすることで、Oracle Databaseの処理を最適化する長い歴史を持っています。このオフロード機能は、Exadataの基本的な機能であり、最新世代のX11Mで最大500 GB/秒の分析スキャン・スループット(ストレージ・サーバー当たり)を提供する多くの最適化の1つです。
データが「ベクトル化」されるか、既存のデータを拡張するために追加のベクトル・データが追加される場合、ベクトル・データの量は通常非常に大きくなります。参照ベクトルに最も近い’k’が検索されているAI検索の性質上、サマリーまたはレポートを提供するために大量のデータをスキャンする分析クエリと同様に、すべてのベクトルがスキャンおよび比較される可能性は非常に高くなります。ストレージサーバーへのオフロード処理は、分析ワークロードの場合と同様にAIベクトル検索にも適用されます。このファミリは、Exadata上のAIベクトル検索: AI Smart Scanのオフロード最適化と呼ばれます。AI Smart Scanは、複数の機能を組み合わせることで、あらゆる規模のAIワークロードを加速します。
この投稿では、Exadata System Software 25ai Release 25.2までのExadata上の独自のAI機能について説明します。この投稿は、追加機能がリリースされた際に引き続き更新する予定です。
次のビデオでは、すべてのAIスマート・スキャン機能の概要を確認できます。
概要
詳しく知る前に、AIスマートスキャンの簡単な概要から始めましょう。前述したように、AIスマート・スキャンは、処理をデータベース・サーバーからストレージ・サーバーにオフロードすることで、ExadataでのAIベクトル検索問合せを高速化する一連の機能です。
AIスマート・スキャンは、既存のExadataスマート・スキャン機能に基づいて構築され、多くのユーザーがAIクエリを同時に実行できます。重要なことは、AIスマート・スキャンがトランザクション実行パターンを念頭に置いて、さらに最適化されていることです。通常、AIワークロードは、複数の繰り返しの処理や精製処理が行われる可能性があるため、数秒以内に迅速に実行する必要があります。AIワークロードにはより多くのOLTP実行パターンがありますが、大量のデータを処理するため、Exadataスマート・スキャンはこれらのワークロード用に最適化されました。
AIスマート・スキャンは自動的かつ透過的に機能するため、ソースコードの変更は必要ありません。ベクトル・データ処理をExadataストレージ・サーバーにプッシュダウンします。これにより、Exadataは、オンプレミス、ExaDB-C@C、ExaDB-D、ExaDB-XS、Autonomousのいずれであっても、デプロイメント内のすべてのストレージ・サーバー間でAIベクトル検索をパラレル化できます。これにより、ベクトル距離計算やTop-Kフィルタリング(つまり、最も近いベクトルのKの検索)などの後続の最適化が、データが存在する場所で実行され、結果のみがさらなる処理のためにデータベース・サーバーに戻されます。その結果、Exadata上のAIワークロードは、Exadata System Software 24ai(24.1)で最大30倍高速に実行できます。
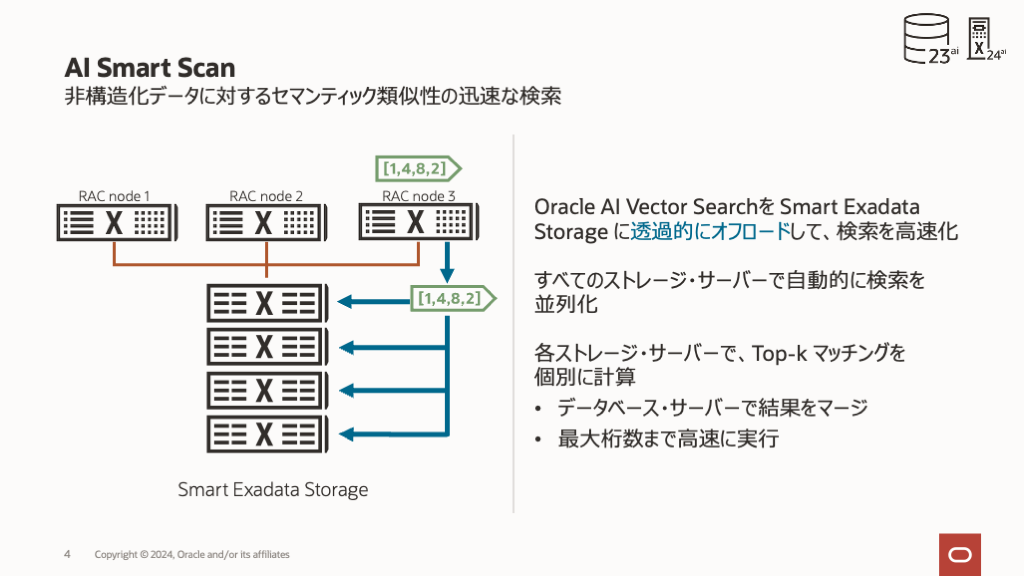
AI Vector Searchのコアでは、データベースに格納されているベクトルと参照ベクトルの間の距離を比較します。格納されたベクトルが参照ベクトルとセマンティックに(意味的に)似ているほど、そのベクトルは近くなります。AIスマート・スキャンでは、ベクトル距離SQL関数(vector_distance())がストレージ・サーバーにオフロードされるため、この重要な計算のためにベクトルをデータベース・サーバーに送信する必要がなくなります。
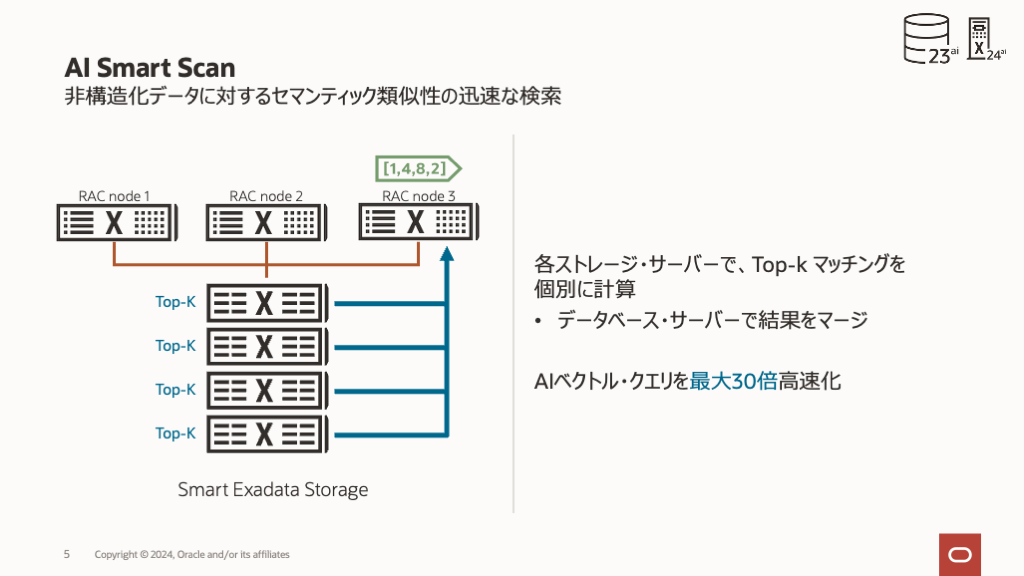
ストレージ・サーバーでベクトル距離を計算すると、それぞれのストレージサーバーがそれぞれのTop-K (最も類似した)ベクトルを追跡でき、データベース・サーバーでの最終処理の前にデータを効率的にストレージサーバーでフィルタリングできます。
最後に、AI Vector Searchは、多数のベクトル形式といくつかのインデックス作成をサポートしています。AIスマート・スキャンは、ディスクに最適化されたネイバー・パーティション・ベクトル索引(Inverted File Flatとも呼ばれる)やIVF_Flat索引など、サポートされているすべてのベクトル形式の処理を自動的かつ透過的にオフロードします。
ベクトル距離計算とtop-k
AIベクトル検索では、データベースに格納されているベクトルを参照ベクトルと比較します。Exadata以外の環境(Oracle以外のデータベースを含む)では、参照からの距離を計算するために、データベースに格納されている各ベクトルをデータベースに送信する必要があります。Exadataでは、Oracleはベクトル距離計算をストレージ・サーバーにオフロードできるため、データベース・サーバーにベクトル・データを送信する必要がなくなります。これにより、データベース・サーバーとストレージサーバー間のネットワーク・トラフィックが減少し、OLTP、分析、その他のAIワークロードなどの他の処理のためにデータベース・サーバーのCPUが解放されます。距離の比較をオフロードすると、Exadataは、環境に応じて、複数のストレージ・サーバーおよび数十から数百または数千のコア間で作業をパラレル化することができます。
ストレージ・サーバー上のベクトル距離を計算すると、各ストレージ・サーバーがそれぞれのtop-kベクトルを追跡することもできます。「top-k」とは何でしょうか? Top-kはパラメータで、SQLに”FETCH APPROXIMATE k ROWS ONLY”として埋め込まれ、参照ベクトルに最も近い一致または最も類似する一致の数を定義します。たとえば、10のtop-kは、問合せの参照ベクトルに最も類似した10個のベクトルを返します。Top-kを計算すると、AIスマート・スキャンはストレージ・サーバーでのデータをフィルタできます。各ストレージ・サーバーはそれぞれのtop-kを追跡し、データベース・サーバーに返されるデータの量をさらに削減するために使用します。
Exadata System Software 25aiでは、AIスマート・スキャンがTop-Kを追跡して、Exadataに固有の機能であるフィルタリング効率をさらに最適化して向上させました。アダプティブ・Top-Kフィルタリングと呼ばれ、AIスマート・スキャンはデータの各チャンク(ディスク・リージョン)を読み取るため、最も近いまたは最も類似したベクトルの実行中のTop-Kリストを保持します。この最適化により、AIスマート・スキャンのセッションは、実行中の最上位リストにあるベクトルよりも近いベクトルのみデータベース・サーバーに戻ります。たとえば、実行中のTop-kリストに、ストレージ・サーバー上のデータの50%など、最も類似した10個のベクトルが含まれている場合、さらに近いベクトルのみがデータベース・サーバーに送信されます。アダプティブ・Top-Kフィルタリングの結果は、他のストレージ・サーバーからの結果とマージするためにデータベース・サーバーに送信されるデータでデータ・フィルタリングを最大4.7倍大幅に削減し、データベース・サーバーが実行する必要がある処理を大幅に削減します。
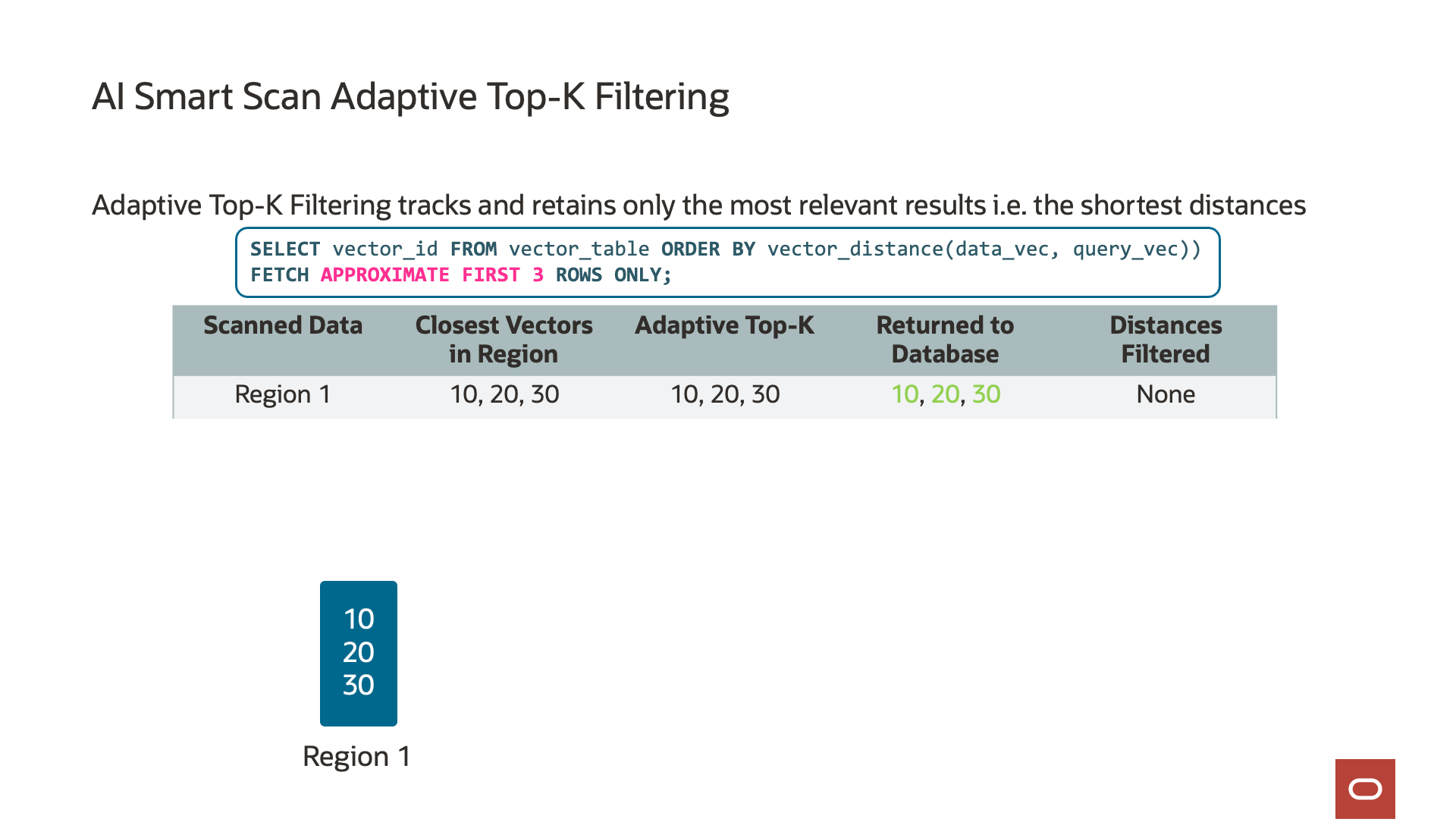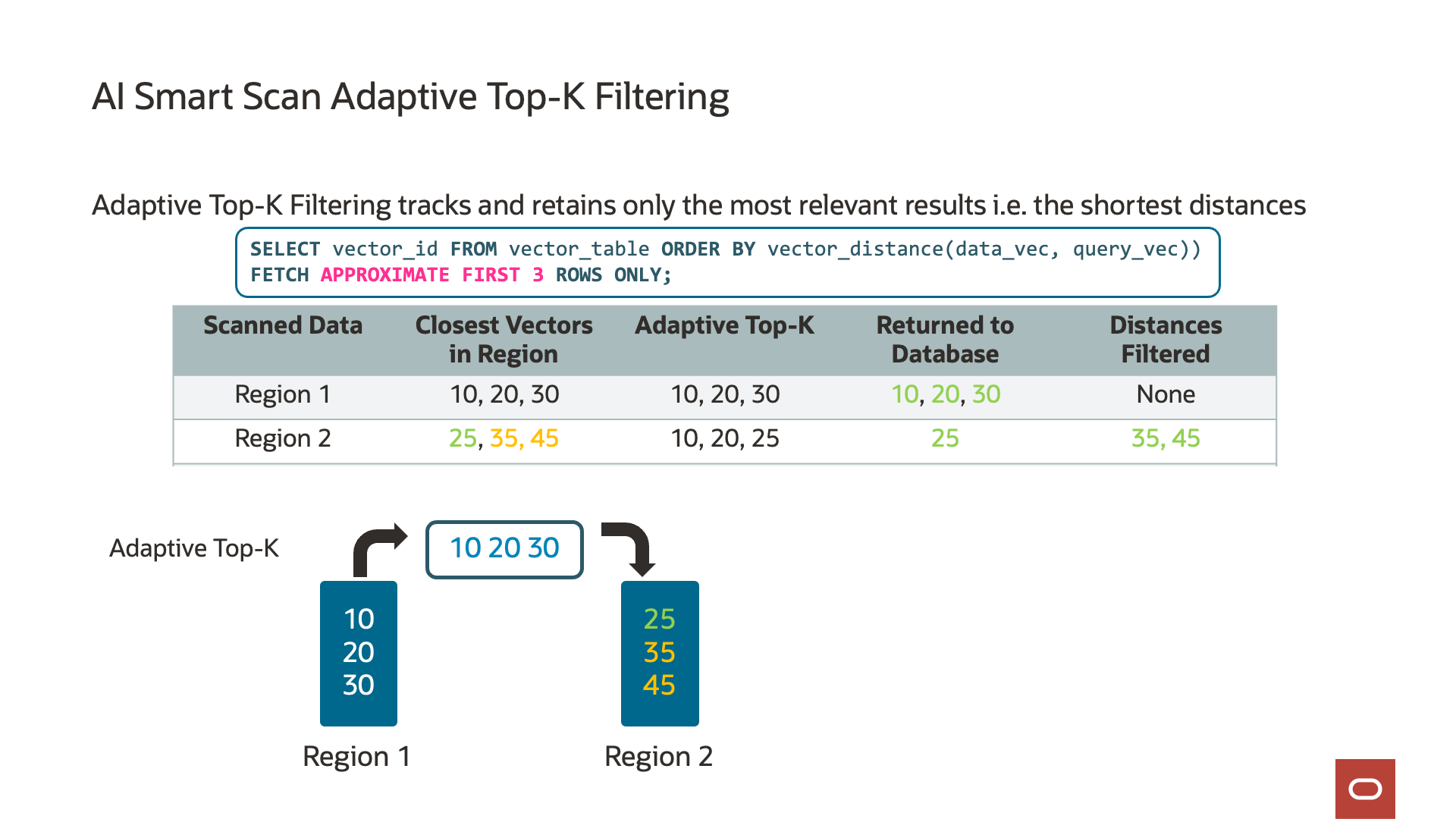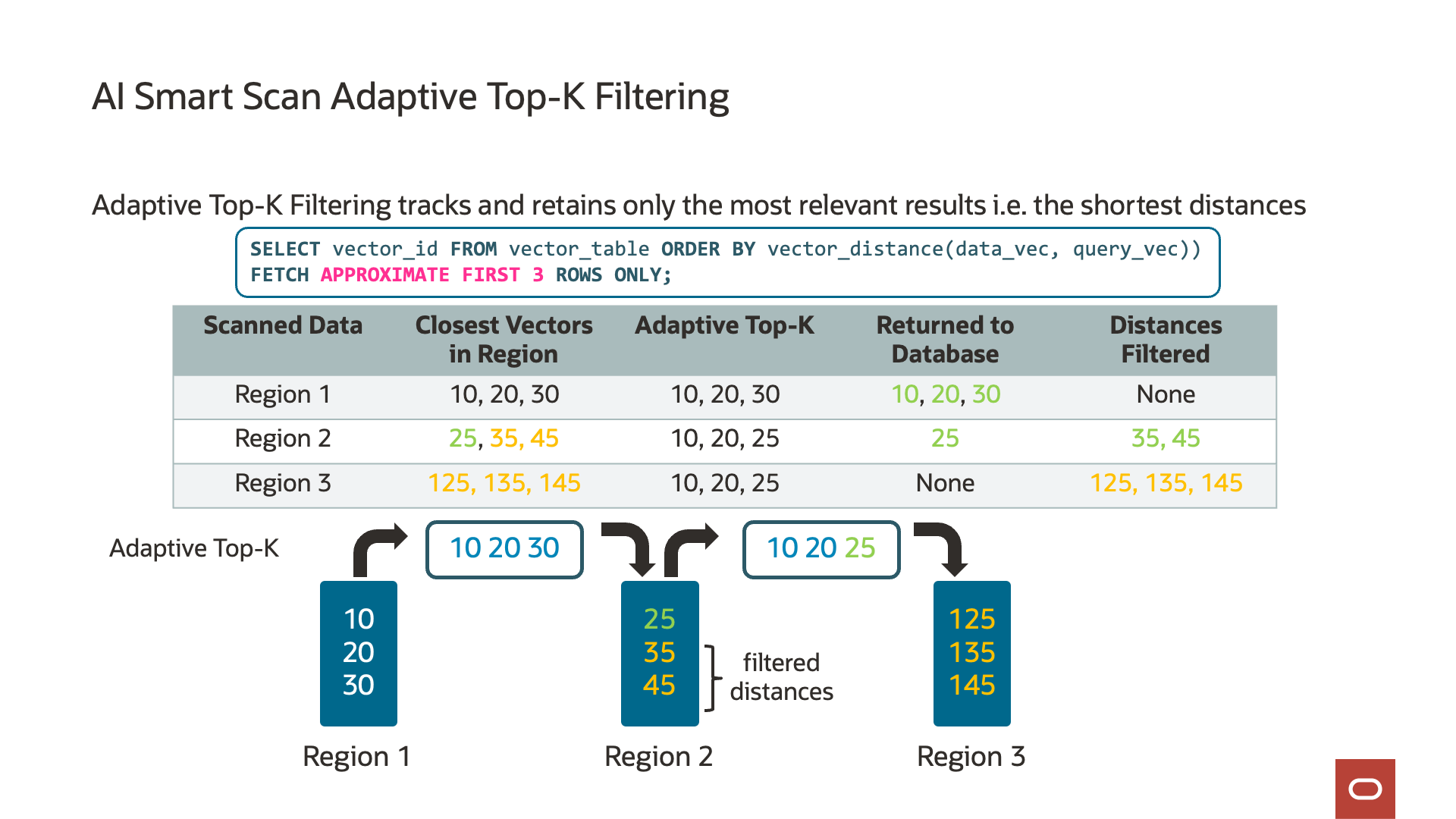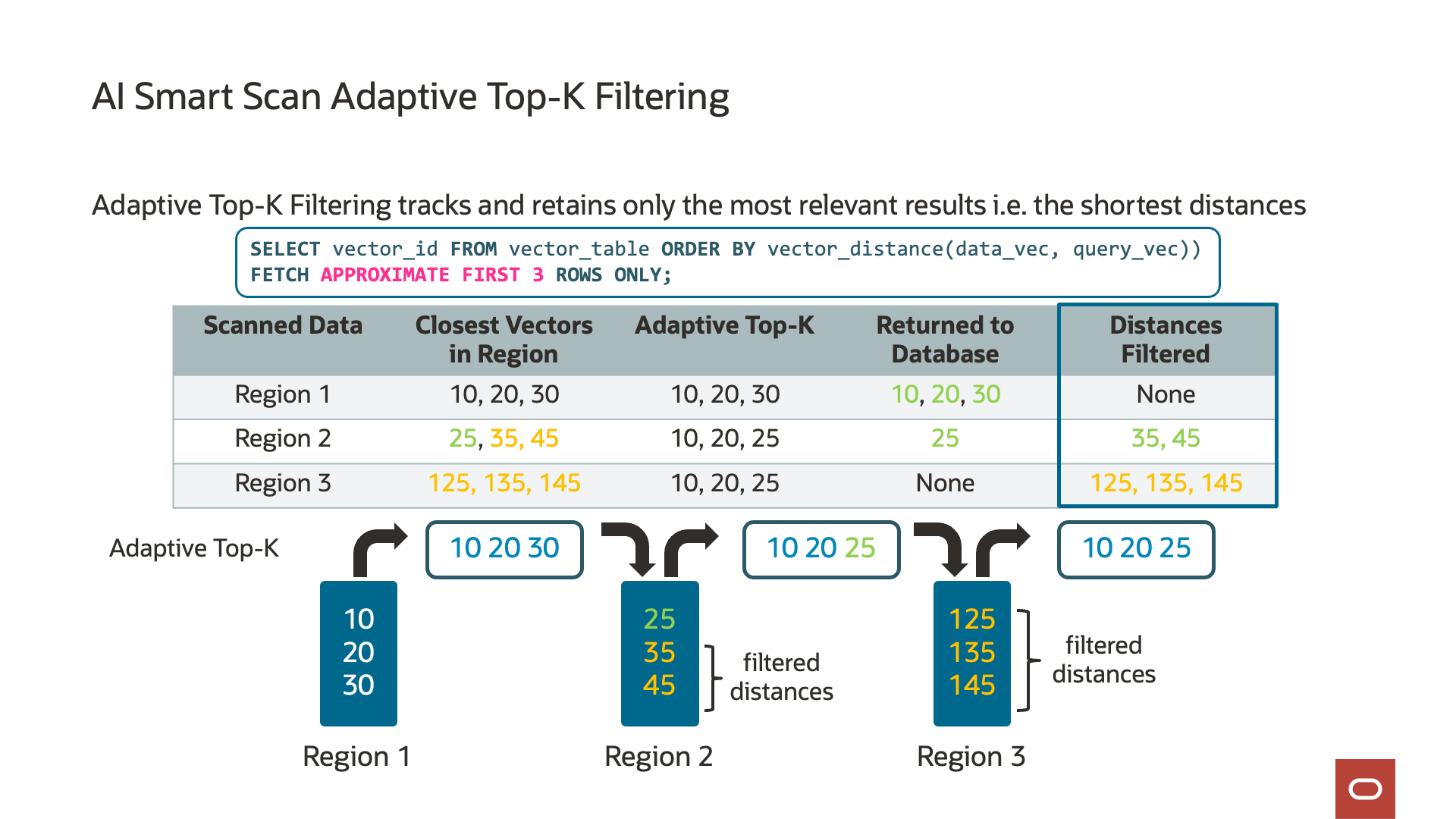
ベクトル距離計算に戻ると、多くの場合、格納されたベクトルと参照ベクトルの間の距離は、問合せまたはアプリケーションでは必要ありません。ただし、距離が使用され、データベース・サーバーに戻す必要がある場合があります。AIスマート・スキャンでは、再計算のために格納されたベクトルをデータベース・サーバーに送信するのではなく、計算された距離が仮想列として自動的に送信されます。これは、実行中のTop-kリストの結果にのみ適用され、ベクトルをストレージ・サーバーからデータベース・サーバーに転送したり、データベース・サーバーで距離を再計算する必要がなくなります。これにより、クエリーが最大4.6倍高速化され、データベースに戻されるデータが最大24倍削減されます。
ベクトル・ディメンション・フォーマット
Oracle Database AI Vector Searchには、様々なデータ・パターンやワークロード・パターンに役立つ、様々なベクトル・ディメンション形式が用意されています。ディメンションの形式は、INT8、FLOAT32 (デフォルト)、FLOAT64、BINARYに対応しています。また、ベクトルはDENSE(デフォルト)またはSPARSEのいずれかになります。AIスマート・スキャンでは、4つのディメンション形式すべてをサポートし、すぐに利用できるDENSE(密)ベクトルとSPARSE(疎)ベクトルの両方をサポートしています。しかし、なぜベクトル形式が重要なのでしょうか? これは、埋め込むデータ、埋込みモデル、および結果ベクトルの使用方法によって異なります。これらの質問に対する回答に関係なく、ベクトル・データをExadata上のOracleに格納すると、AIスマート・スキャンでスキャンできます。しかし、これまで説明してきたように、データを迅速にスキャンできるよりも優れています。ベクトル形式の選択に慎重な場合、追加のメリットを得ることができます。
例を挙げると、フォーマットを指定しない場合、ベクトルのデフォルトのディメンション書式はFLOAT32です。これはベースライン形式であり、AIスマート・スキャンの初期導入時にクエリーを最大30倍高速なことを測定した際のフォーマットです。使用している埋込みモデルでINT8フォーマットのディメンションがサポートされている場合、ベクトルは同等のFLOAT32ベクトルと比較して最大4倍小さくなり、クエリーは最大8倍速くなります。BINARYベクトルはさらに効率的で、FLOAT32と比較して最大で32倍小さく、クエリーが最大で32倍高速です。
この時点で、「精度」という用語を議論することが重要です。精度は、問合せの全体的な正確性を測定します。この場合のクエリは、AI Vector Searchクエリで表示される「FETCH APPROX FIRST k ROWS ONLY」で示されているように、類似性を検索しています。これらすべての要因を考慮すると、ベクトルの格納方法を選択する際に、ディメンション・フォーマットの精度が重要になります。FLOAT32とINT8はどちらも96%の精度を誇り、BINARYは92%を超えています。ただし、INT8はFLOAT32より4倍小さく、クエリー速度が8倍速いことに注意してください。BINARYは32倍より小さく、クエリーが最大32倍高速です。ユース・ケースによっては、より速く、より小さいベクトルは、精度がわずかに低下することの価値がある場合があります。

最後に、SPARSEベクトルには通常、可能なディメンションの数が非常に多くありますが、多くの場合、これらのディメンションのわずかな割合のみが値を割り当てています。SPLADEやBM25などのモデルを埋め込むことによって生成されたSPARSEベクターは、キーワードまたは語彙ベースのAIワークロードに特化しています。たとえば、Exadataドキュメントにこれらのモデルのいずれかが埋め込まれており、ディメンションの合計数が30,000 (それぞれがキーワードに対応)に設定されている場合、ゼロ以外の各ディメンションは、そのキーワードの出現回数を表します。埋込みモデルによって値が割り当てられていないディメンションは、ベクトルに格納されません。ゼロ以外の値ディメンションのみを保存すると、そのようなベクトルのサイズが大幅に削減され、AIスマート・スキャン問合せが高速化されます。

AIベクトル類似性検索とリレーショナル・ビジネス・データの組み合わせ
Oracle Databaseは長い間、マルチモデル・データベースでした。近年では、多くのスタイルのデータとワークロードを同時および組み合せて格納および処理できるため、コンバージド・データベースとして記述されています。AI Vector Searchは、ベクトル類似性検索を既存のOracleデータと組み合せることで、この戦略の典型的な例となります。
たとえば、施設検索アプリケーションでは、郵便番号(zipcode)、価格(price)、施設の写真の説明を埋め込むベクトル(description_vector)、およびその他の関連データを格納する表を使用できます。
CREATE TABLE houses (id NUMBER, zipcode NUMBER, price NUMBER, description CLOB, description_vector VECTOR(1024, FLOAT32));
このデータを効率的に問い合せるには、description_vector列に索引を作成します。ベクトルに適用可能な索引には、主に2つのタイプがあります。Hierarchical Navigable Small World (HNSW)索引、Neighbor Partition Vector索引またはInverted File Flat (IVF_FLAT)索引とも呼ばれるインメモリー・ネイバー・グラフのベクトル索引。3番目のタイプであるハイブリッド・ベクトル索引などです。これらの索引構造の詳細は、AIベクトル検索のドキュメントを参照してください。
AIスマート・スキャンは、ネイバー・パーティション・ベクトル(IVF_FLAT)索引と透過的に連携して、クエリーを高速化します。
この例では、description_vector列にネイバー・パーティション・ベクトル索引が作成されます。
CREATE VECTOR INDEX house_idx ON houses (description_vector) ORGANIZATION NEIGHBOR PARTITIONS;
この表を問い合せるには、次のようなSQLを実行します。
SELECT price FROM houses t WHERE price < 2000000 AND zipcode = 94065 ORDER BY VECTOR_DISTANCE(description_vector, :query_vector) FETCH APPROX FIRST 10 ROWS ONLY;
この問合せでは、houses表の参照ベクトルに最も類似した10のプロパティを検索し、価格(price)は指定された金額を下回る家、指定された郵便番号内(zipcode)の家を問い合わせています。裏ではどのような処理が実行されているのか。実行計画を見てみましょう。
-------------------------------------------------------------------------------------------------------- | Id | Operation | Name | -------------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | | 1 | VIEW | | | 2 | NESTED LOOPS | | | 3 | VIEW | VW_IVPSR_11E7D7DE | |* 4 | COUNT STOPKEY | | | 5 | VIEW | VW_IVPSJ_578B79F1 | |* 6 | SORT ORDER BY STOPKEY | | | 7 | NESTED LOOPS | | | 8 | VIEW | VW_IVCR_B5B87E67 | |* 9 | COUNT STOPKEY | | | 10 | VIEW | VW_IVCN_9A1D2119 | |* 11 | SORT ORDER BY STOPKEY | | | 12 | TABLE ACCESS STORAGE FULL | VECTOR$VIDX_IVF$32281_32286_0$IVF_FLAT_CENTROIDS | | 13 | PARTITION LIST ITERATOR | | |* 14 | TABLE ACCESS STORAGE FULL | VECTOR$VIDX_IVF$32281_32286_0$IVF_FLAT_CENTROID_PARTITIONS | | 15 | TABLE ACCESS BY USER ROWID | HOUSES | --------------------------------------------------------------------------------------------------------
この実行計画の主要なエントリは、ID 12、14、15です。12および14は、ベクトル検索をExadataストレージ・サーバーにオフロードし、house_idx索引をスキャンするためにAIスマート・スキャンが使用されていることを示しています。ネイバー・パーティション・ベクトル索引は、ベクトル・エントリ(この例では”VECTOR$VIDX_IVF$32281_32286_0$IVF_FLAT_CENTROID_PARTITIONS”)を格納するパーティション表と、各パーティション(VECTOR$VIDX_IVF$32281_32286_0$IVF_FLAT_CENTROIDS)の重心またはアンカー・ベクトルを表す別の表で構成されます。
AI類似性検索では性能のためにベクトル索引が使用されますが、価格(price)および郵便番号(zipcode)でフィルタリングすると、追加のI/Oが発生します。実行計画のID15は、追加のI/O(特に単一ブロック読取り)がhouse表に対して実行されることを示しています。
DB 23.7 RU(2025年1月リリース)の新機能では、以前に作成したベクトル索引に追加の列を含めることができます。この機能は、ネイバー・パーティション・ベクトル索引に含まれる列(Included Column)と呼ばれ、前の例で確認された追加のI/Oの問題を解決します。
索引を再作成し、price列およびZIPcode列を含めることで、問合せに対して単一ブロック読取りを完全に回避できます。
CREATE VECTOR INDEX house_idx ON houses(description_vector) INCLUDE (price, zipcode) ORGANIZATION NEIGHBOR PARTITIONS;
改訂されたEXPLAIN PLANは、より合理化されたクエリの実行を明らかにし、houseテーブルに対する ACCESS BY USER ROWID が排除されています。
---------------------------------------------------------------------------------------------------------- | Id | Operation | Name | ---------------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | | 1 | VIEW | | | 2 | VIEW | VW_IVPSR_11E7D7DE | |* 3 | COUNT STOPKEY | | | 4 | VIEW | VW_IVPSJ_578B79F1 | |* 5 | SORT ORDER BY STOPKEY | | | 6 | NESTED LOOPS | | | 7 | VIEW | VW_IVCR_B5B87E67 | |* 8 | COUNT STOPKEY | | | 9 | VIEW | VW_IVCN_9A1D2119 | |* 10 | SORT ORDER BY STOPKEY | | | 11 | TABLE ACCESS STORAGE FULL | VECTOR$VIDX_IVF$32281_32305_0$IVF_FLAT_CENTROIDS | | 12 | PARTITION LIST ITERATOR | | |* 13 | TABLE ACCESS STORAGE FULL | VECTOR$VIDX_IVF$32281_32305_0$IVF_FLAT_CENTROID_PARTITIONS | ----------------------------------------------------------------------------------------------------------
ベクトル索引に追加の含まれる列(Included Column)が含まれると、AIスマート・スキャンのオフロード機能と組み合せて、最大3倍問合せを高速化できます。

まとめ
この記事では、AI Vector SearchをExadataストレージ・サーバーにオフロードおよび高速化するExadata AIスマート・スキャンの基礎、さらに処理するためにデータベース・サーバーに送信されるデータの量を迅速かつ効率的に削減するAdaptive Top-K Filtering、BINARYおよびSPARSEベクトルなど、多くのことを取り上げています。最適化により、クエリを高速化し、ストレージ使用量を削減し、高精度を維持します。AI Smart Scanが計算された距離をデータベース・サーバーに戻し、事前計算を回避し、ネットワーク・トラフィックを削減します。最後に、不要なI/Oを排除し、クエリを高速化するために、ネイバー・パーティション・ベクトル索引にビジネス・データを含めます。これは、Oracle DatabaseとExadataのAI機能の始まりにすぎません。リリース時に追加機能が追加されますので、再度更新を確認してください。
