※ 本記事は、David Allanによる”Multi-Cloud: Copying Data from Azure Data Lake to Oracle’s OCI Object Storage using OCI Data Flow“を翻訳したものです。
2023年6月29日
今日のデジタル環境では、組織が複数のクラウド・プロバイダと連携して、各プラットフォームが提供する最高の機能と性能を活用していることがよくあります。このマルチクラウド・アプローチにより、企業はワークロードを分散し、コストを最適化して、ベンダー・ロックインを回避できます。このブログ投稿では、OCI Data Flowを使用してAzure Data LakeからOracleのOCIオブジェクト・ストレージにデータをコピーし、マルチクラウド・アーキテクチャのパワーを紹介する実際のシナリオについて説明します。
まず、アーキテクチャの主要なコンポーネントについて理解しましょう。:
1. Azure Data Lake: ビッグ・データ処理用に設計された、Microsoft Azureのスケーラブルでセキュアなクラウドベースのストレージ・システム。企業は、大量のデータを様々な形式で保存および分析できます。
2. Oracle OCIオブジェクト・ストレージ: Oracle Cloud Infrastructureのオブジェクト・ストレージ・サービス。スケーラビリティと耐久性に優れたクラウドベースのストレージ・ソリューションを提供します。さまざまなデータ処理テクノロジーを使用して、膨大な量のデータを保存、処理、分析できます。
3. OCI Data Flow: OCI Data Flowは、Oracle Cloud Infrastructureが提供する完全管理型のサーバーレス・データ処理サービスです。これにより、基礎となるインフラストラクチャを管理することなくApache Sparkアプリケーションを実行できるため、データ変換および処理に最適な選択肢となります。一般的なオープンソースのビッグ・データ処理フレームワークであるApache Sparkは、サーバーレス方式でデプロイできます。
Azure Data LakeからOCIオブジェクト・ストレージへのデータのコピー
次に、OCI Data Flowを使用してAzure Data LakeからOCIオブジェクト・ストレージにデータをコピーするステップバイステップのプロセスについて説明します。:
ステップ1: Azure Data Lakeアクセスの構成:
Azure Data Lakeからデータを読み取るための適切なアクセス権と権限があることを確認してください。Azure Storage AccountやAzure AD認証などの必要な資格証明を設定して、接続を確立します。自分の環境では、デモが情報にアクセスするためのサービス・プリンシパルを作成します。次に、データにアクセスするための特定のロールを構成しました。
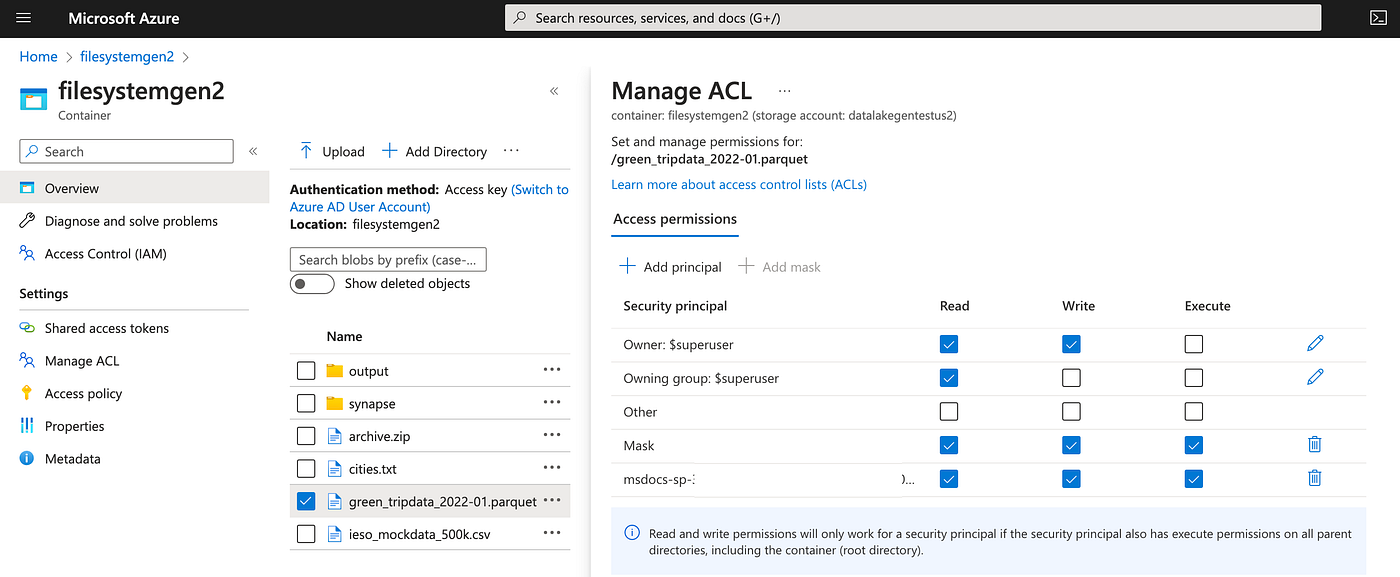
Azureサービス・プリンシパルは、Data LakeなどのAzureリソースにアクセスするためのアプリケーション、ホスト・サービスおよび自動ツールで使用するために作成されたアイデンティティです。アクセスは、サービス・プリンシパルに割り当てられたロールによって制限され、アクセス可能なリソースとアクセス可能なレベルを制御できます。
Azure Data Lakeにアクセスするには、Azure Data Lake Storage Gen2と互換性のある Hadoop Filesystemドライバを使用します。これは、スキーム識別子abfs (Azure Blob File System)によって認識されます。ABFSドライバは、他のHadoop Filesystemドライバと一貫して、Data Lake Storage Gen2対応アカウント内のファイルおよびディレクトリに対処するためにURI形式を使用します。
次に、aData Lake Storage Gen2対応のアカウントで簡潔さと完全性のURLを定義する最も詳細な方法を使用します。短縮URI構文は次のとおりです。:
abfs[s]://<file_system>@<account_name>.dfs.core.windows.net/<path>/<file_name>
- スキーム識別子:
abfsプロトコルがスキーム識別子として使用されます。末尾にsを追加すると(abfss)、ABFS Hadoopクライアント・ドライバでは、選択された認証方法に関係なく、常にTransport Layer Security (TLS)が使用されます。 - ファイル・システム: ファイルとフォルダを保持する親の場所。これは、Azure Storage Blobサービスのコンテナと同じです。
- アカウント名: 作成時にストレージ・アカウントに指定された名前。
- パス: ディレクトリ構造のスラッシュ区切り(/)表現。
- ファイル名: 個々のファイルの名前。ディレクトリをアドレス指定する場合、このパラメータはオプションです。
URLを簡略化するオプションについては、Azureのドキュメントを確認してください。
ステップ2: OCIオブジェクト・ストレージの設定:
Oracle Cloud InfrastructureでOCオブジェクト・ストレージにバケットを作成し、OCI Data Flowアプリケーションからこのバケットにデータを書き込むために適切なポリシーを設定します。これは、データの宛先として機能します。
ステップ3: Sparkアプリケーションの準備:
任意のプログラミング言語(Scala、Pythonなど)を使用してSparkアプリケーションを開発し、Azure Data Lakeからデータを読み取ります。Azure Blob Storageコネクタまたは適切なライブラリを利用して、Azure Data Lakeとやり取りし、必要なデータを取得します。次に、ABFSSを使用してAzureに接続します(ここでは、OCI Data Flowで使用されるライブラリ・バージョンを確認できます)。クライアント・シークレットはOCI Vaultに格納され、そこにシークレットを格納します。コードに追加した残りのプロパティ(Azure storage_account_name、container_name、client_idなど、bucket_nameなどのOCIプロパティとともに)パラメータ化できます。
from __future__ import print_function
import sys
import os
from random import random
from operator import add
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
def get_authenticated_client(token_path, client, file_location=None, profile_name=None):
"""
Get an an authenticated OCI client.
Example: get_authenticated_client(token_path, oci.object_storage.ObjectStorageClient)
"""
import oci
if not in_dataflow():
# We are running locally, use our API Key.
if file_location is None:
file_location = oci.config.DEFAULT_LOCATION
if profile_name is None:
profile_name = oci.config.DEFAULT_PROFILE
config = oci.config.from_file(file_location=file_location, profile_name=profile_name)
authenticated_client = client(config)
else:
# We are running in Data Flow, use our Delegation Token.
with open(token_path) as fd:
delegation_token = fd.read()
signer = oci.auth.signers.InstancePrincipalsDelegationTokenSigner(
delegation_token=delegation_token
)
authenticated_client = client(config={}, signer=signer)
return authenticated_client
def get_password_from_secrets(token_path, password_ocid):
"""
Get a password from the OCI Secrets Service.
"""
import base64
import oci
secrets_client = get_authenticated_client(token_path, oci.secrets.SecretsClient)
response = secrets_client.get_secret_bundle(password_ocid)
base64_secret_content = response.data.secret_bundle_content.content
base64_secret_bytes = base64_secret_content.encode("ascii")
base64_message_bytes = base64.b64decode(base64_secret_bytes)
secret_content = base64_message_bytes.decode("ascii")
return secret_content
def in_dataflow():
"""
Determine if we are running in OCI Data Flow by checking the environment.
"""
if os.environ.get("HOME") == "/home/dataflow":
return True
return False
def get_delegation_token_path(spark):
"""
Get the delegation token path when we're running in Data Flow.
"""
if not in_dataflow():
return None
token_key = "spark.hadoop.fs.oci.client.auth.delegationTokenPath"
token_path = spark.sparkContext.getConf().get(token_key)
if not token_path:
raise Exception(f"{token_key} is not set")
return token_path
def load_from_azure():
oci_namespace="..."
oci_bucket="..."
storage_account_name="..."
client_id="..."
PASSWORD_SECRET_OCID="ocid1.vaultsecret.oc1....."
directory_id="..."
container_name="..."
file="cities.txt"
spark = SparkSession.builder.appName("Azure to OCI") \
.config("fs.azure.createRemoteFileSystemDuringInitialization", "false")\
.config("fs.azure.account.auth.type."+storage_account_name+".dfs.core.windows.net", "OAuth")\
.config("fs.azure.account.oauth.provider.type."+storage_account_name+".dfs.core.windows.net", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider")\
.config("fs.azure.account.oauth2.client.id."+storage_account_name+".dfs.core.windows.net", client_id)\
.config("fs.azure.account.oauth2.client.endpoint."+storage_account_name+".dfs.core.windows.net", "https://login.microsoftonline.com/"+directory_id+"/oauth2/token") \
.getOrCreate()
token_path = get_delegation_token_path(spark)
client_secret = get_password_from_secrets(token_path, PASSWORD_SECRET_OCID)
spark.conf.set("fs.azure.account.oauth2.client.secret."+storage_account_name+".dfs.core.windows.net", client_secret)
path = "abfss://"+container_name+"@"+storage_account_name+".dfs.core.windows.net/"+file
df = spark.read.format("csv").option("header","true").load(path)
df.show()
parquetTablePath = "oci://" + oci_bucket + "@" + oci_namespace +"/azure/spark-ParquetTable"
df.write.mode("overwrite").parquet(parquetTablePath)
load_from_azure()
ステップ4: OCIデータ・フローの構成:
OCIコンソールまたはAPIを使用して、OCI Data Flowアプリケーションを作成します。OCIコンソール内またはOCI Data Scienceノートブック内から、OCIコード・エディタを使用して前述のコードをテストすることもできます。依存アプリケーションjarファイル、入力データ・ソース(Azure Data Lake)、出力データ・シンク(OCIオブジェクト・ストレージ)など、必要な構成パラメータを指定します。
上記のPySparkは、Microsoft Azureデータ・レイクおよびHadoop JARファイル(特にこれらのバージョン)に依存しています。これをpackages.txtファイルに追加します。;
https://repo1.maven.org/maven2/org/apache/hadoop/hadoop-azure/3.3.1/hadoop-azure-3.3.1.jar https://repo1.maven.org/maven2/org/apache/hadoop/hadoop-azure-datalake/3.3.1/hadoop-azure-datalake-3.3.1.jar https://repo1.maven.org/maven2/org/codehaus/jackson/jackson-mapper-asl/1.9.9/jackson-mapper-asl-1.9.9.jar
PySparkは、OCI Vaultからシークレットを取得するためにOCI python SDKにも依存します。これを使用するには、OCI SDKを含むpythonのrequirements.txtファイルも必要です。;
oci
ここに示す手順に従って、archive.zipファイルを構築し、これをOCIオブジェクト・ストレージにアップロードします(サード・パーティの依存関係を持つzipを構築する方法については、ここで説明する手順を参照)。必ず、実行と同じpythonバージョンを使用してください(そうしないと、「ModuleNotFoundError: No module named ‘oci’」のようなエラーが発生します)。
これで、OCIコンソール内でOCI Data Flowアプリケーションを作成する準備が整いました。名前を定義しました。前述のSparkのバージョンは3.2.1 (Python 3.8を使用)で、このデモ用の計算用のシェイプです。;
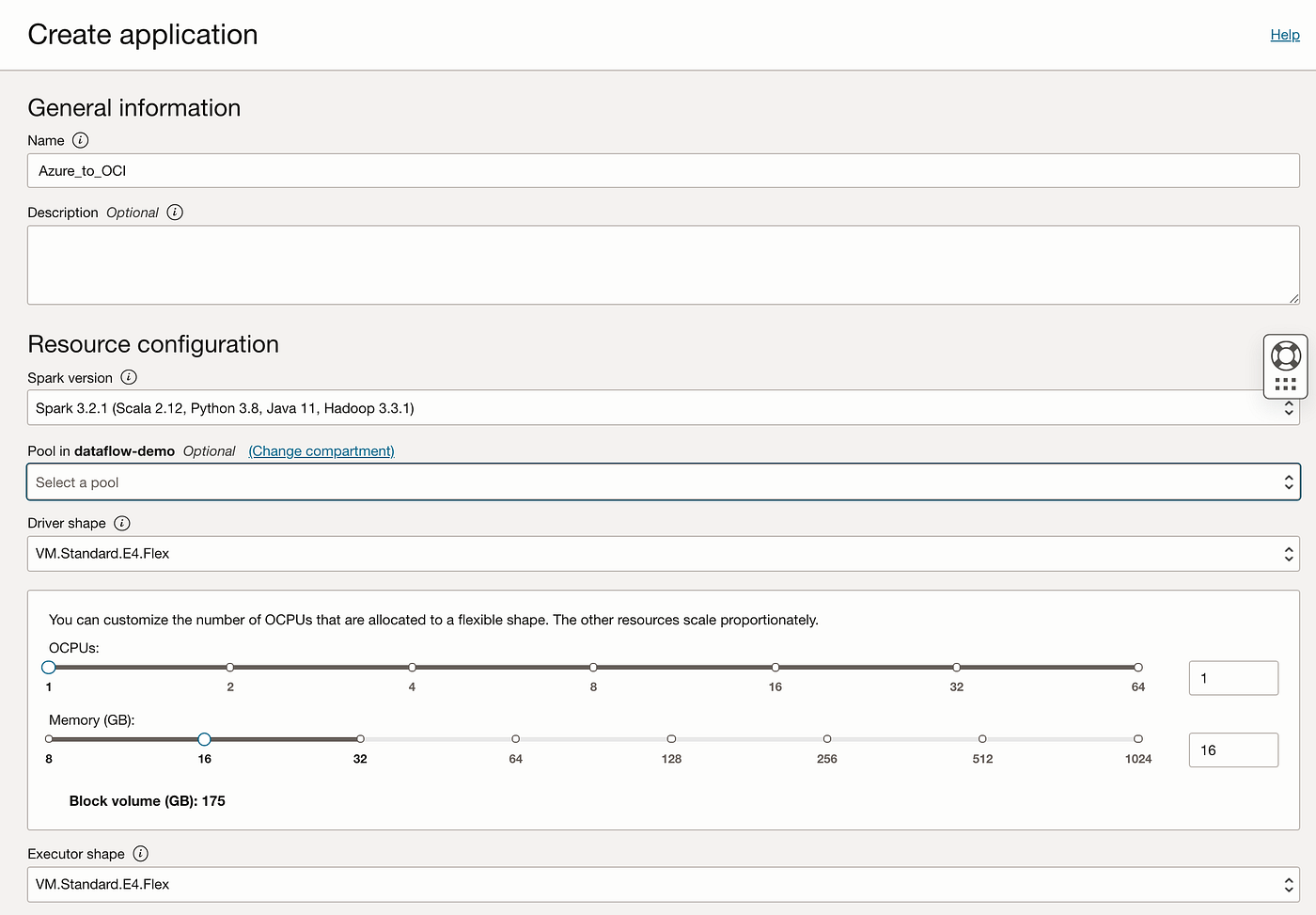
次に、Pysparkが存在する場所、バケットとオブジェクト名(azire_to_oci.py)、およびAzureのhadoop JARとデータ・レイクJARを含むarchive.zipの場所を定義します。
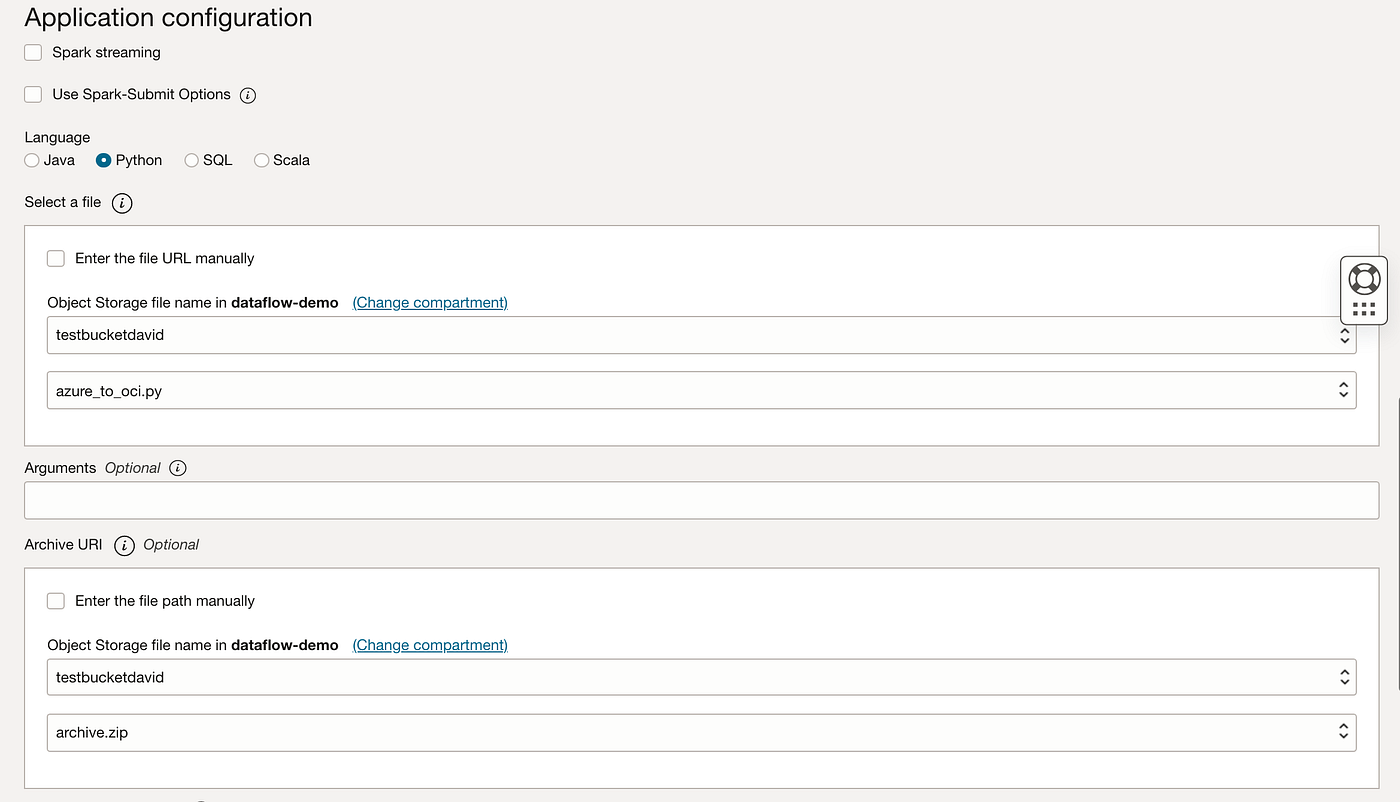
ステップ5: OCI Data Flowジョブを起動してモニター:
その後、アプリケーション実行パネルでアプリケーションおよびモニターを実行できます。;

アプリケーションが受け入れられるフェーズから実行および成功までのフェーズに進んでいることがわかります。

OCI Data Flowジョブを発行し、Sparkアプリケーションの実行をトリガーします。OCI Data Flowは、データの処理に必要なコンピュート・インスタンスなどの必要なリソースを自動的にプロビジョニングおよび管理します。
提供されているモニタリング・ツールおよびロギング・ツールを使用して、OCI Data Flowジョブの進行状況およびステータスをモニターします。ジョブが正常に完了したら、OCIオブジェクト・ストレージ内のコピーされたデータを検証して、転送の整合性を確保します。
これは簡単で、Azure Data Lakeとの間で読み書きできるようになりました。
まとめ:
マルチクラウド・アーキテクチャを構築することで、組織はさまざまなクラウド・プラットフォーム独自の強みを活用できます。このブログ投稿では、OCI Data Flowを使用してAzure Data LakeからOracleのOCIオブジェクト・ストレージにデータをコピーするプロセスについて考察しました。サーバーレス・コンピューティングと管理対象データ処理サービスの力を活用することで、企業はクラウド間でデータをシームレスに移動できるため、各クラウド・プロバイダのクラス最高の機能を使用できます。この柔軟性と俊敏性は、進化する現代の要求を満たす上で重要な役割を果たします。
詳細は、マルチクラウド・データ・レイク統合アーキテクチャの実装方法に関するこのOCIリファレンス・アーキテクチャをご覧ください。
お気に召しましたか? OCI Data Flowのアーキテクチャを確認し、OCI Data Flowでできることを確認してください。;
