※ 本記事は、Ulrike Schwinnによる”Hybrid Vector Index – a combination of AI Vector Search with Text Search“を翻訳したものです。
2025年3月4日
Oracle 23aiでは、人工知能(AI)ワークロード向けに設計されたOracle AI Vector Searchが追加され、キーワードではなくセマンティクスに基づいてデータをクエリできるようになりました。Oracle AI Vector Searchの最大の利点の1つは、1つのシステム内で、非構造化データに対するセマンティック検索を、ビジネス・データに対するリレーショナル検索と組み合せることができることです。
ユース・ケースがユーザーの検索語またはキーワードとも一致する必要がある場合、どうすればよいでしょうか? ここで、Oracle Textテクノロジの出番です。Oracle Textとは何でしょうか?
Oracle Textは、Oracleの統合された全文検索テクノロジであり、すべてのエディションのOracle Databaseの一部です。Oracle Textでは、標準SQLを使用して、Oracleデータベースに格納されているテキストおよびドキュメントの索引付け、検索および分析を行います。通常、プレーン・テキストはVARCHAR2列およびCLOB列に格納されます。ただし、BLOB列に格納されているWordやPDFファイルなどのバイナリ・ドキュメントに索引付けすることもできます。データベースに格納されている外部ファイルへのポインタのみを使用して、ファイル・システム、Webまたはクラウド・ストレージで外部に保持されているファイルに索引付けすることもできます。
次に簡単な例を示します。
create table customers ( cust_id number, cust_name varchar2(80), create_date date );
データを追加します。
insert into customers VALUES (1, 'The Acme Manufacturing Company, Inc.', SYSDATE); insert into customers VALUES (2, 'Coyote Trap Construction GMBH', SYSDATE);
「create search index」構文を使用してテキスト索引を作成できるようになりました。Oracle Databaseでは、21c以降ならば、次のように簡単です:
CREATE SEARCH INDEX cust_text_index on customers (cust_name);
21c以前の場合は:
create index cust_text_index on customers (cust_name) INDEXTYPE IS ctxsys.context
PARAMETERS ('SYNC (ON COMMIT)');
CONTAINS問合せ演算子を使用して、この表の行を検索できるようになりました。CONTAINSは、一致がない場合は0を戻し、一致がある場合は0より大きい値を戻す関数です。検索する列名とテキスト問合せを取り、CONTAINSを他の演算子と簡単に組み合せます:
select cust_id, cust_name from customers where CONTAINS ( cust_name, 'construction' ) > 0 and create_date > '01-JAN-23';
Oracle Textについてさらに学習する場合は、Oracle Textのドキュメント、Oracle Databaseの『A New User’s Guide to Oracle Text』のペーパーを参照するか、ここでコンパイルされたリンクのリストを確認してください。
現段階で、両方のテクノロジーを統合できたらどうでしょうか? リリース23.6では、Oracleは、新しいクラスのベクトル索引であるハイブリッド・ベクトル索引を導入して、この要件に対処しました。これにより、ユーザーは、全文検索とセマンティック・ベクトル検索を1つの索引で組み合せて、ドキュメントの索引付けおよび問合せを簡単に行うことができます。ハイブリッド・ベクトル索引は、ユーザーがテキスト問合せ、ベクトル類似性問合せ、またはこれらの両方のアプローチを利用するハイブリッド問合せを実行できる統合問合せAPIを提供します。これにより、ユーザーは簡単に検索エクスペリエンスをカスタマイズし、検索結果を拡張できます。
ハイブリッド・ベクトル索引機能を示すために、ここではこのチュートリアルをまとめました。「23aiでベクトルを使い始める」に掲載されている表とモデルを使用しました。これにより、最新の23aiリリースで試すことができます。
次のトピックについて説明します:
基本
一般に、新しいベクトル・データ型VECTORを使用した表の作成、INSERTを使用したベクトルの挿入、SQL Loaderを使用したベクトルのロードまたはData Pumpを使用したロードとアンロード、またはベクトル埋込みでのベクトル索引の作成を行うことができます。ベクトル距離関数や、ベクトルを作成、変換および記述したり、データをチャンク化および埋め込むためにOracle AI Vector Searchのベクトルで使用できるその他の多くのSQL関数および演算子など、新しいSQL関数が追加されています。
Oracle AI Vector Searchの一般的なワークフローの概要については、インタラクティブなOracle AI Vector Searchテクニカル・アーキテクチャをご覧ください。
通常の表の列に索引を作成する方法と同様に、ベクトル埋込みにベクトル索引を作成できます。これは、巨大なベクトル空間で類似性検索を実行する場合に便利です。クラスタリング、パーティショニング、ネイバー・グラフなどの手法を使用して、類似アイテムを表すベクトルをグループ化します。これにより、検索領域が大幅に削減されるため、検索プロセスが非常に効率的になります。これらのベクトルはディスク上に構築され、それらのブロックはバッファ・キャッシュにキャッシュされます。
Oracle AI Vector Searchでは、近似近傍検索に基づいて、次のカテゴリのベクトル索引付け方法がサポートされています:
- Hierarchical Navigable Small World (HNSW)は、サポートされるインメモリー近傍グラフ・ベクトル索引の唯一のタイプです。HNSWグラフは、ベクトル近似検索の非常に効率的な索引です。HNSWグラフは、階層化された階層組織とともに、スモール・ワールド・ネットワークの原理を使用して構造化されます。
- Inverted File Flat (IVF)索引は、サポートされている唯一のタイプの近傍パーティション・ベクトル索引です。Inverted File Flat索引(IVF Flat索引または単純IVF)は、高い検索品質と妥当な速度のバランスをとることができるパーティションベースの索引です。ディスク上に構築され、そのブロックは通常のバッファ・キャッシュにキャッシュされます。
- さらに、非構造化データにハイブリッド・ベクトル索引(Oracle Text索引とベクトル索引の組合せ)を作成できるようになりました。
詳細は、『AI Vector Search ユーザーズ・ガイド』を参照してください。
ハイブリッド・ベクトル索引の作成
類似性検索とハイブリッド検索のどちらを使用するかに応じて、ベクトル索引またはハイブリッド・ベクトル索引を作成できます。ベクトル索引の作成を可能にするには、ベクトル・プールと呼ばれるSGAに格納されている新しいメモリー領域を有効にする必要があります。ベクトル・プールは、Hierarchical Navigable Small World (HNSW)索引および関連するすべてのメタデータを格納するためにSGAに割り当てられるメモリーです。また、IVF索引を使用した実表に対するDML操作に加えて、Inverted File Flat (IVF)索引の作成も高速化するために使用されます。
ベクトル・プールのサイズを設定するには、VECTOR_MEMORY_SIZE初期化パラメータを使用します。このパラメータは、CDBおよびPDBレベルで動的に変更できます。
私の環境では、次のようになります:
SQL> sho parameter vector_memory_size NAME TYPE VALUE ------------------------------------ --------------------------------- ---------------- vector_memory_size big integer 1G
V$VECTOR_MEMORY_POOLを問い合せてベクトル・プールを監視します。
SQL> select * from V$VECTOR_MEMORY_POOL; POOL ALLOC_BYTES USED_BYTES POPULATE_STATUS CON_ID ------------------ ----------- ---------- --------------- ---------- 1MB POOL 671088640 382730240 DONE 3 64KB POOL 335544320 3997696 DONE 3 IM POOL METADATA 124151396 16777216 DONE 3
注意: HNSW索引の格納に必要なメモリー・サイズを大まかに決定するには、次の式を使用します。1.3 * ベクトル数 * ディメンション数 * ベクトル・ディメンション・タイプのサイズ(たとえば、FLOAT32はBINARY_FLOATと同等で、サイズは4バイトです)。
この件の詳細は、『AI Vector Search User’s Guide』の「ベクトル・プールのサイズ設定」の章を参照してください。
ハイブリッド・ベクトル索引を作成する前に、前回の投稿「23aiでベクトルを使い始める」で使用した環境を見直しましょう。
connect vector_user/password@pdb1
-- the table CCNEWS we used
SQL> desc ccnews
Name Null? Type
----------------------------------------- -------- ----------------------------
ID NOT NULL NUMBER(10)
INFO VARCHAR2(4000)
VEC VECTOR(*, *)
-- 200.000 newspaper headlines in the table
SQL> select count(*) from ccnews;
COUNT(*)
----------
200000
-- the vector embedding model we used
col model_name format a12
col mining_function format a12
col algorithm format a12
col attribute_name format a20
col data_type format a20
col vector_info format a30
col attribute_type format a20
set lines 120
SQL> select model_name, mining_function, algorithm,
algorithm_type, model_size
from user_mining_models
where model_name = 'DOC_MODEL'
order by model_name;
MODEL_NAME MINING_FUNCT ALGORITHM ALGORITHM_TYPE MODEL_SIZE
------------ ------------ ------------ ------------------------------ ----------
DOC_MODEL EMBEDDING ONNX NATIVE 90621438
-- our first query is looking for headlines related to the term "newspaper"
SQL> select id, info
from ccnews
order by vector_distance(vec, TO_VECTOR(VECTOR_EMBEDDING(doc_model USING 'newspaper' as data)), COSINE)
fetch approx first 5 rows only;
ID INFO
---------- ----------------------------------------------------------------------------
153556 : British newspaper
190160 Blogs and the Web may hurt or change newspapers.
185646 Editor and Publisher - NEW YORK For years, editorial page editors at newspapers across the
country have battled \
70536 on journalist: report
2020 The paper that has chronicled business from Lower Manhattan for 119 years plans to start a
sports page and move to the News Corporationâs Midtown offices.
次に、最初のハイブリッド・ベクトル索引である専用のドメイン索引を作成します。この例では、索引を作成する表名と列名、埋込みを生成するためのデータベース内ONNX埋込みモデルなど、最小限の情報が使用されます。
INFOは索引付けされる列で、DOC_MODELは使用されるモデルです。
SQL> CREATE HYBRID VECTOR INDEX my_hybrid_idx on ccnews(info) PARAMETERS ('model doc_model') parallel 8;
Index created.
Elapsed: 00:12:27.35
その他のすべての索引付けパラメータは、テキスト処理、チャンク化または埋込み戦略の専門家でなくても、ドキュメントの索引付けを容易にするために事前定義されています。必要に応じて、索引のベクトル索引部分のベクトル検索プリファレンス、索引のテキスト索引部分のテキスト検索プリファレンス、結合索引に対するDML操作の索引メンテナンス・プリファレンスを使用して、事前定義済パラメータを変更できます。たとえば、データストア・プリファレンスを使用して、ソース・ファイルが格納されるローカルまたはリモートの場所を指定できます。考えられるすべての設定の詳細は、ドキュメントを参照してください。
索引の作成には、通常高いCPU消費が必要であり、時間がかかることに注意してください。ただし、ベクトル索引はパラレルで作成でき、並列度はCPUコアでスケーリングできます。したがって、環境と並列性は作成時間に影響します。
私の場合は、Exadataマシンでのテストでは、次の結果を得ました:
200K行の場合:
- 並列度 8: 12分27秒
- 並列度 16: 7分42秒
- 並列度 32: 03分13秒
- 並列度 64: 02分51秒
- 02分52秒 並列度 96 2 G –CPU 100%
400K行の場合:
- 並列度 16: 13分58秒
- 並列度 32: 05分34秒
コマンドが実行されると、バックグラウンドで何が行われるのでしょうか? この例では、Inverted File Flat (IVF)ベクトルとOracle Text索引が作成されます。パラメータVECTOR_IDXTYPEにHSNWを使用すると、Hierarchical Navigable Small World (HNSW)索引が作成されます。次に例を示します。
CREATE HYBRID VECTOR INDEX my_hybrid_idx_hnsw on ccnews_1(info) PARAMETERS ('model doc_model vector_idxtype HNSW') parallel 8;
ドメイン索引のステータス(ここではINDEXED)およびその他の情報をチェックするには、CTX_USER_INDEXESなどの通常のOracle Textデータ・ディクショナリ・ビューを問い合せます。
SQL> select idx_name, idx_table, idx_status, idx_docid_count, idx_maintenance_type, idx_model_name, idx_vector_type from ctx_user_indexes; IDX_NAME IDX_TABLE IDX_STATUS IDX_DOCID_COUNT -------------------- ------------------------- --------------- --------------- IDX_MAINTENANCE_TY IDX_MODEL_NAME IDX_VECTOR_TYPE ------------------ -------------------- -------------------- MY_HYBRID_IDX_HNSW CCNEWS_1 INDEXED 200000 AUTO DOC_MODEL HNSW MY_HYBRID_IDX CCNEWS INDEXED 200000 AUTO DOC_MODEL
新しいデータ・ディクショナリ・ビューV$VECTOR_INDEXは、ベクトル索引に関する診断情報を提供します。ベクトル索引ビューおよびハイブリッド・ベクトル索引ビューの詳細は、ドキュメントも参照してください。この例では、索引名、索引編成、HNSW索引の場合にこのベクトル索引に割り当てられるメモリーの合計量、このベクトル索引が問合せによって使用された回数、ターゲット問合せの精度が指定されていない場合にこのベクトル索引で近似検索を実行する場合に達成する精度などの情報がリストされています。
SQL> select index_name, index_organization, allocated_bytes/1024/1024 MB, distance_type, index_dimensions, index_dim_type, default_accuracy, index_used_count from v$vector_index; INDEX_NAME INDEX_ORGANIZATION MB ------------------------------ ------------------------- ---------- DISTANCE_TYPE INDEX_DIMENSIONS INDEX_DIM_TYPE DEFAULT_ACCURACY -------------------- ---------------- -------------------- ---------------- INDEX_USED_COUNT ---------------- DR$MY_HYBRID_IDX$VI NEIGHBOR PARTITIONS 0 COSINE 384 FLOAT32 95 9 DR$MY_HYBRID_IDX_HNSW$VI INMEMORY NEIGHBOR GRAPH 359.5 COSINE 384 FLOAT32 95
索引付けパイプラインにについてのアイデアを得るためのドキュメントからのアーキテクチャ図を次に示します。
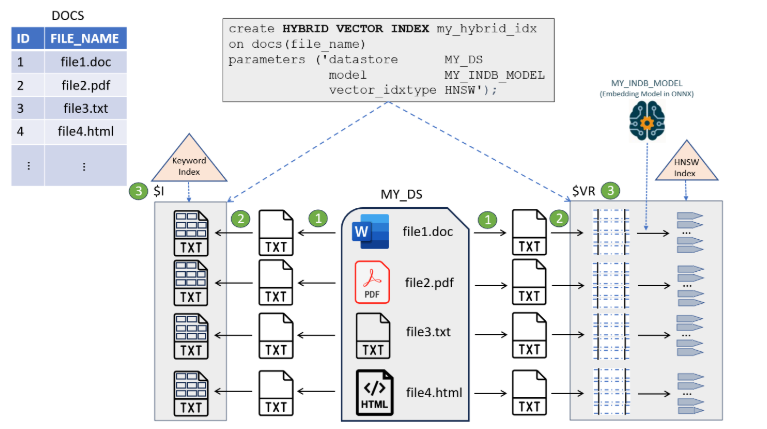
ドキュメント表DOCSには、MY_DSデータストアと呼ばれる場所に格納されているIDおよび対応するドキュメント名またはファイル名が含まれます。
索引付けパイプラインは、MY_DSデータストアからのドキュメントの読取りから始まり、一連の処理ステージを通じてドキュメントを渡します:
- フィルタ(PDF、Word、Excelなどのバイナリ・ドキュメントのプレーン・テキストへの変換)
- トークン化(キーワード検索のデータのトークン化)とベクトル化(ベクトル検索のチャンク化/埋込み生成)
- 索引作成エンジン(セカンダリ表の作成)
問合せ
2つの単純な問合せから始めましょう。最初の例では「newspaper」という用語を使用しました。ここでは、英国の新聞の、Times、Sunなどの特定のキーワードに問合せを絞り込みます。問合せ機能を提供するために、DBMS_HYBRID_VECTORという新しいパッケージ・インタフェースが導入されました。これには、SEARCHというJSONベースの問合せAPIが含まれており、ハイブリッド・ベクトル索引に対して問合せを実行できます。
DBMS_HYBRID_VECTOR.SEARCH PL/SQLファンクションを使用すると、テキスト問合せ、ベクトル類似性問合せ、またはハイブリッド・ベクトル索引に対するハイブリッド問合せを実行できます。可能なすべての設定の詳細なリストと説明を取得するには、ドキュメントを参照してください。
DBMS_HYBRID_VECTOR.SEARCH (json(
'{ "hybrid_index_name": "<hybrid_vector_index_name>",
"search_text" : "<query string for keyword-and-semantic search>",
"search_scorer" : "RRF | RSF", -- the method to evaluate the combined "fusion" search scores from both keyword and semantic search results
"search_fusion" : "INTERSECT | UNION | TEXT_ONLY | VECTOR_ONLY | MINUS_TEXT | MINUS_VECTOR",
"vector": { … } -- vector search parameters
"text": { … } -- text search parameters
"return": { … } -- return parameters }'))
最初の例では、チャンク・モードで”newspaper”という用語に対して純粋なセマンティック検索を使用し、チャンク・レベルの結果を取得するためにベクトルのみの検索を実行します。チャンク・モードでは、チャンクが同じドキュメントからのものか異なるドキュメントからのものかに関係なく、識別される最適なチャンクのリストに対応する実表からのチャンク識別子および関連付けられたドキュメントIDのリストが検索の結果になります。これらのチャンク・テキストからのコンテンツは、LLMが応答を定式化するための入力として使用できます。
JSON_SERALIZEを使用して、JSON出力をテキスト表現で表します。
set long 10000 pagesize 1000
select json_serialize(
dbms_hybrid_vector.search(
json(
'{ "hybrid_index_name" : "my_hybrid_idx",
"vector":
{
"search_text" : "newspaper", -- search text
"search_mode" : "CHUNK" -- chunk-level results
},
"return":
{
"values" : [ "score", "vector_score", "chunk_text" ],
"topN" : 5
}
}' )) pretty) output;
OUTPUT
--------------------------------------------------------------------------------
[
{
"score" : 83.4,
"vector_score" : 83.4,
"chunk_text" : ": British newspaper"
},
{
"score" : 71.55,
"vector_score" : 71.55,
"chunk_text" : "Blogs and the Web may hurt or change newspapers."
},
{
"score" : 71.54,
"vector_score" : 71.54,
"chunk_text" : "Editor and Publisher - NEW YORK For years, editorial page ed
itors at newspapers across the country have battled \\"
},
{
"score" : 70.65,
"vector_score" : 70.65,
"chunk_text" : "on journalist: report"
},
{
"score" : 70.62,
"vector_score" : 70.62,
"chunk_text" : "The paper that has chronicled business from Lower Manhattan
for 119 years plans to start a sports page and move to the News Corporation
Midtown offices."
} ]
この場合、キーワード・スコアがないため、最終スコア(スコア)はベクトル・スコアと同じです。システムは、すべてのベクトルに対して類似性検索を実行し、最大で上位k個のベクトルを抽出します。値kは内部的に計算されます。それぞれにベクトル・スコアが与えられます。これらのkベクトル(最大)は、ドキュメントID別にグループ化され、識別された各ドキュメントについて、そのドキュメントで見つかった各関連ベクトルのセマンティック・スコアは、その特定のドキュメントに対するこれらのスコアの最大(デフォルト関数)を計算するために使用されます。最大スコアが最も高い上位5つのドキュメント(最大)が返されます。
次の例では、キーワード・スコアとセマンティック・スコアを組み合せたハイブリッド検索を使用します。ハイブリッド検索では、すぐに利用できるスコアリング手法またはカスタムのスコアリング手法を使用して、全文問合せとベクトルベースの類似性問合せを組み合せてドキュメントを検索できます。SEARCH_FUSIONパラメータのデフォルトはINTERSECTです。したがって、テキスト検索結果とベクトル検索結果の両方に共通する行のみが返されます。
set long 10000 pagesize 1000
select json_serialize(
dbms_hybrid_vector.search(
json(
'{ "hybrid_index_name": "my_hybrid_idx",
"vector":
{
"search_text" : "newspaper",
"search_mode" : "CHUNK"
},
"text":
{
"contains" : "British newspaper or Times or Sun"
},
"return":
{ "values" : [ "score", "text_score", ""vector_score", "chunk_text" ],
"topN" : 5
}
}' )) pretty) output;
OUTPUT
--------------------------------------------------------------------------------
[
{
"score" : 89.24,
"text_score" : 10,
"vector_score" : 97.16,
"chunk_text" : ": British newspaper"
},
{
"score" : 69.09,
"text_score" : 19,
"vector_score" : 74.1,
"chunk_text" : "The Times of London has published its final edition as a bro
adsheet newspaper. Today, it relaunches as a tabloid. The Times is the second Br
itish newspaper to move to a smaller, more commuter-friendly format in a bid to
reverse slumping sales."
},
{
"score" : 67.39,
"text_score" : 10,
"vector_score" : 73.13,
"chunk_text" : "Beginning Monday all editions of the venerable Times of Lond
on will be printed in tabloid format, just as the Sun and other not-quite-so-ven
erable newspapers."
},
{
"score" : 65.14,
"text_score" : 10,
"vector_score" : 70.65,
"chunk_text" : "News International, the publisher of the Sun, Times and News
of the World newspapers, is to relocate its print works from Wapping to Enfield
in north London."
},
{
"score" : 64.69,
"text_score" : 19,
"vector_score" : 69.26,
"chunk_text" : "After more than two centuries as a broadsheet newspaper, The
Times of London has gone strictly tabloid. On Monday, The Times moved to a tota
lly compact format after almost a year of dual publication."
}
]
類似性検索では、VECTOR_DISTANCE値の概念を使用してチャンクのランク付けを行います。一方、従来のOracle Text検索では、キーワード・スコアの概念(CONTAINSスコアとも呼ばれる)が使用されます。これは、Saltonの式からの逆頻度アルゴリズムに基づいて、ワード問合せで返されたドキュメントの関連性スコアを計算します(Wikipediaを参照)。逆頻度スコアリングでは、ドキュメント・セットで頻繁に発生する用語がノイズ用語であると想定されるため、これらの用語のスコアは低くなります。通常、ドキュメントが高スコアになるには、ドキュメント内で問合せ用語が頻繁に発生する必要がありますが、ドキュメント・セット全体ではあまり発生しません。
2つのメトリックは非常に異なっており、一方のメトリックを直接使用して他方のメトリックと比較することはできません。したがって、類似性検索距離は、セマンティック・スコアと呼ばれるCONTAINSスコアに相当する距離に変換または正規化されるため、その値の範囲は100 (最良)から0 (最悪)になります。これにより、キーワード・スコアとセマンティック・スコアは、ハイブリッド検索の実行時に比較できます。
検索が完了したら、結果をマージしてスコアリングする必要があります。SEARCH_FUSION操作では、Reciprocal Rank Fusion (RRF)やRelative Score Fusion (RSF)などのSEARCH_SCORERアルゴリズムが機能します(「ハイブリッド検索の理解」の章の図8-2「ドキュメント・モードでのキーワードおよびセマンティック検索のスコアリング」および図8-4「チャンク・モードでのキーワードおよびセマンティック検索のスコアリング」を参照)。最後に、定義されたtopNドキュメント識別子が最大で返されます。
その他の例については、「ハイブリッド・ベクトル索引のエンドツーエンドの問合せの例」の章の例などのドキュメントを参照してください。
まとめ
ハイブリッド・ベクトル索引の使用を検討すべき場合と理由は何でしょうか?
純粋な検索を使用すると、単にキーワードに一致するのみでなく、単語やフレーズの意味やコンテキストに焦点を当てます。ベクトル検索では、問合せ語間のセマンティック関係が考慮されるため、よりコンテキスト関連の結果が含まれる場合があります。特に、正確なフレーズがコンテンツに存在しない場合は、より広いトピックに関する結果を含めることができます。
一方、テキスト検索を使用した純粋なキーワード検索では、テキスト索引でトークン化された用語と単語またはフレーズの正確なキーワードまたは表現を照合することに重点を置いているため、問合せ語を具体的に含む結果が返される場合があります。したがって、キーワード検索のみでは、特に正確な用語がコンテンツに存在しない場合、問合せの単語の背後にある意味的な意味を見落とす可能性があるため、適切でない場合があります。ハイブリッド検索では、同じデータに対してキーワード検索とベクトル検索を実行し、2つの検索結果を1つの結果セットに結合することで、このような問合せの両方のコンポーネントに対処できます。このようにして、テキスト索引とベクトル索引の両方の長所を利用して、最も関連性の高い結果を取得できます。これにより、より正確でパーソナライズされた情報が提供されます。ハイブリッド・ベクトル索引は、DMLを使用してテキストおよびベクトルを維持できる単一のドメイン索引です。キーワード検索とベクトル検索の両方がすべてのドキュメントに対して実行され、2つの検索結果が結合およびスコアリングされて、統一された結果セットが返されます。
その他の資料
- 23aiでベクトルを使い始める (ブログ投稿)
- Oracle AI Vector Search ユーザーズ・ガイド
- Oracle AI Vector Search
- Oracle AI Vector Searchテクニカル・アーキテクチャ (interactive diagram)
- ベクトル・データベースとは?
- AI Vector Search ユーザーズ・ガイド: SEARCH
- Oracle AI Vector Search FAQ
- Github Folder AI Vector Search
