※ 本記事は、Stephane Duprat, Ulrike Schwinnによる”Getting started with vectors in 23ai“を翻訳したものです。
2024年9月2日
Oracle 23aiでは、Oracle AI Vector SearchがOracle Databaseに追加されます。ベクトル機能をネイティブに追加および統合することで、Oracleのコンバージド・データベース戦略を完全に強化します。1つのシステムで、ビジネス・データに対するリレーショナル検索と組み合せることができます。Oracle AI Vector Searchは、人工知能(AI)ワークロード向けに設計されており、キーワードではなくセマンティクスに基づいてデータをクエリできます。そのため、特殊なベクトル・データベースを追加する必要がなくなり、複数のシステム間のデータ断片化の問題が解消されます。また、セキュリティ、可用性、パフォーマンス、パーティショニング、GoldenGate、RAC、Exadataなど、Oracle Databaseの他の機能と緊密に統合されています。Oracle Databaseに保持されているデータには、SQLを介して直接アクセスできます。中間形式に変換する必要はありません。さまざまなフォーマットでデータを組み合わせるのは簡単です。あとは参加するだけです。
AI vector検索機能から始める方法の概要を素早く理解するために、私の同僚のStephaneと私はこのチュートリアルで、機能を実証するための短くて簡単なシナリオを構築することがどれほど簡単かを示します。次のトピックについて説明します:
概要
一般に、新しいベクトル・データ型VECTORを使用して表を作成したり、INSERTを使用してベクトルを挿入したり、SQL Loaderを使用してベクトルをロードしたり、Data Pumpを使用してロードおよびアンロードしたり、ベクトル埋込みにベクトル索引を作成したりできます。ベクトル距離関数や、ベクトルを作成、変換および記述したり、データをチャンク化および埋め込むために、Oracle AI VECTOR Searchでベクトルで使用できるその他の多くのSQL関数および演算子など、新しいSQL関数が追加されています。
一般的なOracle AI Vector Searchのワークフローは、次のようになります …
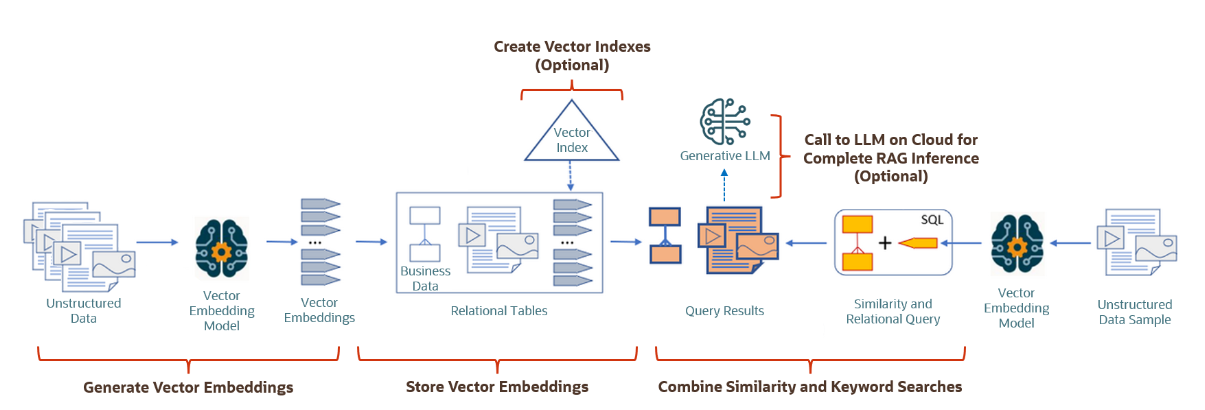
Image1: Oracle AI Vector Searchのユースケース・フローチャート(ソース: ドキュメント)
次のチュートリアルでは、次の3つの主なタスクを示します:
- ベクトル埋め込みモデルを使用したベクトル埋め込みの生成
- VECTORデータ型の列へのベクトル埋込みの格納
- SQLおよびORDSでの類似性検索の使用
チュートリアルを始める前に、いくつかの基本的な用語と概念の説明から始めましょう。
Oracle Database 23aiには、新しいVECTORデータ型があります。VECTORは、新しいOracle組込みデータ型です。このデータ型は、INT8 (8ビット整数)、FLOAT32 (32ビット浮動小数点数)またはFLOAT64 (64ビット浮動小数点数)のいずれかの形式で格納される一連の数値としてベクトルを表します。列をvectorデータ型として宣言し、オプションでディメンションの数とその格納形式を指定できます。
ベクトル埋込みは、単語、ドキュメント、オーディオ・トラック、イメージなどのコンテンツの背後にある意味を記述します。このベクトル表現は、人間が認識するオブジェクトの意味的な類似性を、数学的ベクトル空間の近接性に変換します。埋込みモデルを使用すると、非構造化データをベクトル埋込みに変換して、ビジネス・データに対するセマンティック問合せに使用できます。
データのタイプに応じて、様々な事前トレーニング済オープン・ソース・モデルを使用してベクトル埋込みを作成できます。事前トレーニング済オープンソースの埋込みモデルまたは独自の埋込みモデルを使用して、Oracle Databaseの外部でベクトル埋込みを生成できますが、これらのモデルがOpen Neural Network Exchange (ONNX)標準と互換性がある場合に、それらのモデルをOracle Databaseに直接インポートすることもできます。Oracle Databaseは、データベース内でONNXランタイムを直接実装します。これにより、SQLを使用してOracle Database内で直接ベクトル埋込みを生成できます。
データ・セット内のセマンティック類似性の検索は、ベクトル空間で最も近い近傍を検索することと同じです。特定のクエリベクトルに基づいて類似性検索を行うことは、ベクトル空間のクエリ・ベクトルにK-nearestのベクトルを取得することと同等です。基本的に、ベクトルの順序付けされたリストをランク付けして検索する必要があります。ここで、リストの最初の行は問合せベクトルに最も近いまたは最も類似したベクトルで、リストの2番目の行は問合せベクトルに2番目に近いベクトルです。類似性検索を行う場合、距離の相対的な順序は、実際の距離ではなく、本当に重要なものです。類似性検索では、問合せベクトルの値およびフェッチ・サイズに応じて、1つ以上のクラスタからデータが取得される傾向があります。ベクトル索引を使用した近似検索では、検索を特定のクラスタに制限できますが、完全検索ではすべてのクラスタにわたるベクトルが訪問されます。
ベクトル埋込みにベクトル索引を作成し、これらの索引を使用して巨大なベクトル空間で類似性検索を実行できます。クラスタリング、パーティショニング、ネイバー・グラフなどの手法を使用して、類似アイテムを表すベクトルをグループ化します。これにより、検索領域が大幅に削減されるため、検索プロセスが非常に効率的になります。これらのvectorはディスク上に構築され、それらのブロックは通常のバッファ・キャッシュにキャッシュされます。ベクトル検索では、次の2つのベクトル索引がサポートされています:
- 逆ファイル(IVF)フラット索引: ディスク上に構築されたNeighbor Partition Vector索引とそのブロックは、通常のバッファ・キャッシュにキャッシュされます。
- 階層型Navigable Small Worlds (HNSW)索引: In-Memory Neighbor Graph Vector索引は、完全にインメモリーで構築されています。SGAにVECTOR_MEMORY_SIZEを使用して新しいメモリー・プールを設定し、それを収容する必要があります。索引は、完全にインメモリーで構築されています。SGAにVECTOR_MEMORY_SIZEを使用して新しいメモリー・プールを設定し、それを収容する必要があります。
ベクトル索引の使用法は、この投稿のトピックではありませんが、後の投稿で説明します。
インストールと設定
AI vector検索を含むこれらの機能は、すべての23aiデータベース・エディション – クラウドまたは利用可能な23ai free版 で使用できます。23aiデータベース・リリースの利用状況の詳細は、現在のデータベース・リリースのリリース・スケジュール(ドキュメントID 742060.1)を参照してください。
Oracle Database 23ai Freeの場合は、「スタート・ガイド」ページから開始します。Oracle Container Registryからダウンロードするか、Linux 8または9用のRPMまたはWindows用のzipファイルをダウンロードします。クイック・インストール後、すぐに開始できます。
インストール後は、通常、いくつかの設定コマンドを実行します。最初のステップでは、データベースに表領域(TBS_VECTOR)とスキーマ(VECTOR_USER)を作成します:
-- connect as user sys to FREEPDB1 create bigfile tablespace TBS_VECTOR datafile size 256M autoextend on maxsize 2G; create user vector_user identified by "Oracle_4U" default tablespace TBS_VECTOR temporary tablespace TEMP quota unlimited on TBS_VECTOR; GRANT create mining model TO vector_user; -- Grant the 23ai new DB_DEVELOPER_ROLE to the user grant DB_DEVELOPER_ROLE to vector_user; exit
次のステップでは、データ・セットを取得します。次のデモでは、200.000新聞の見出しで構成された公開データ・セットdataset_200K.txtを使用します。このデータ・セットはここでダウンロードできます。
次のステップでは、このファイルの上に外部表を作成します:
-- connect as user sys to FREEPDB1 CREATE OR REPLACE DIRECTORY dm_dump as '/home/oracle'; GRANT READ, WRITE ON DIRECTORY dm_dump TO vector_user; exit
作成したデータベース・ディレクトリに対応するパスにデータ・セットをコピーし、外部表を作成します:
sqlplus vector_user/Oracle_4U@FREEPDB1
CREATE TABLE if not exists CCNEWS_TMP (sentence VARCHAR2(4000))
ORGANIZATION EXTERNAL (TYPE ORACLE_LOADER DEFAULT DIRECTORY dm_dump
ACCESS PARAMETERS
(RECORDS DELIMITED BY 0x'0A'
READSIZE 100000000
FIELDS (sentence CHAR(4000)))
LOCATION (dm_dump:'dataset_200K.txt'))
PARALLEL
REJECT LIMIT UNLIMITED;
-- Check that the external table is correct
select count(*) from CCNEWS_TMP;
COUNT(*)
----------
200000
-- Check the three first rows
select * from CCNEWS_TMP where rownum < 4;
SENTENCE
--------------------------------------------------------------------------------
BOGOTA, Colombia - A U.S.-made helicopter on an anti-drugs mission crashed in
the Colombian jungle on Thursday, killing all 20 Colombian soldiers aboard, the
army said.
UNIONTOWN, Pa. - A police officer used a Taser to subdue a python that had wrapp
ed itself around a man's arm and would not let go.
French soccer star Zidane apologized for head-butting an Italian opponent during
the World Cup final, saying Wednesday that he was provoked by insults about his
mother and sister.
exit
次のステップを実行する準備が整いました。
基本ステップ
次のステップでは、外部表としてマップしたデータ・セットのベクトル埋込みを計算します。そのためには、外部表の各行にベクトル埋込みを生成するベクトル埋込みモデルが必要です。
最初は、ベクトル埋め込みモデルをデータベースにロードします。新しい23ai DBMS_VECTORパッケージを使用して、ONNXモデルをデータベース内にロードできます。
ONNX(Open Neural Network Exchangeの略)は、ディープ・ラーニング・モデルを表すように設計されたオープンソースの形式です。これは、異なるディープ・ラーニング・フレームワーク間の相互運用性を提供し、あるフレームワークでトレーニングされたモデルを、広範な変換や再トレーニングを必要とせずに別のフレームワークで使用できるようにすることを目的としています。
この例のONNXファイルは、Oracle OML4Pyユーティリティによってall-MiniLM-L6-v2文トランスフォーマ・モデルから生成され、ここでダウンロードできます。all-MiniLM-L6-v2.ONNXファイルをDM_DUMPディレクトリに対応するパスにコピーします。
次に、データベースのVECTOR_USERスキーマに接続し、ディープ・ラーニング埋込みモデルをデータベースにロードします。
DBMS_VECTORの使用方法の詳細は、ドキュメントを参照してください。
sqlplus vector_user/Oracle_4U@FREEPDB1
EXECUTE DBMS_VECTOR.LOAD_ONNX_MODEL('DM_DUMP','all-MiniLM-L6-v2.onnx','doc_model')
PL/SQL procedure successfully completed.
exit
次のディクショナリ・ビューを問い合せて、モデルが正しくロードされたことを確認できます:
sqlplus vector_user/Oracle_4U@FREEPDB1 col model_name format a12 col mining_function format a12 col algorithm format a12 col attribute_name format a20 col data_type format a20 col vector_info format a30 col attribute_type format a20 set lines 120 SELECT model_name, mining_function, algorithm, algorithm_type, model_size FROM user_mining_models WHERE model_name = 'DOC_MODEL' ORDER BY model_name; MODEL_NAME MINING_FUNCT ALGORITHM ALGORITHM_ MODEL_SIZE ------------ ------------ ------------ ---------- ---------- DOC_MODEL EMBEDDING ONNX NATIVE 90621438 SELECT model_name, attribute_name, attribute_type, data_type, vector_info FROM user_mining_model_attributes WHERE model_name = 'DOC_MODEL' ORDER BY attribute_name; MODEL_NAME ATTRIBUTE_NAME ATTRIBUTE_TY DATA_TYPE VECTOR_INFO ------------ -------------------- ------------ ------------------ ----------------------- DOC_MODEL DATA TEXT VARCHAR2 DOC_MODEL ORA$ONNXTARGET VECTOR VECTOR VECTOR(384,FLOAT32) exit
埋め込みモデルがデータベースにロードされたので、データベースに直接埋め込みを計算できます:
VECTOR_USERスキーマに接続し、データ型がVECTORの列vecを持つ表を作成します:
sqlplus vector_user/Oracle_4U@FREEPDB1
create table if not exists CCNEWS (
id number(10) not null,
info VARCHAR2(4000),
vec VECTOR
);
-- Use the doc_model previously loaded to calculate the vector embeddings:
insert into CCNEWS (id, info, vec)
select rownum,
sentence,
TO_VECTOR(VECTOR_EMBEDDING(doc_model USING sentence as data))
from CCNEWS_TMP;
200000 rows created.
commmit;
Commit complete.
exit
異なるデータ型に対して1つのベクトル埋込みを生成する場合は、VECTOR_EMBEDDING関数を使用します。この例では、VECTOR_EMBEDDING関数は、「sentence」列に含まれるデータの埋込みを計算します。この埋込みは、TO_VECTOR関数によってベクトルに変換されます。詳細は、ドキュメントを参照してください。
注意:
環境リソース(1つのocpu、dockerの実行など)に応じて、このINSERT文が終了するまで最大40分かかります。環境によっては、文の実行時間を短縮するためにパラレル化の使用を検討する場合があります。
この時点で、ID、テキスト列およびベクトルを含む行を含むCCNEWS表をロードしました。
これで、ベクトル検索問合せを実行する準備ができました。
類似性検索問合せ
次のステップでは、ベクトルを使用してセマンティック検索を実行します。
より正確には、ベクトル間の距離を、これらのベクトルで表されるデータ間の類似度を示すために使用します。
言い換えると、二つのテキストが与えられ、ベクトルが小さいほど、ベクトル間の距離が小さくなるほど、テキストはより類似しています。
2つのvectors間の距離を計算するには、VECTOR_DISTANCE関数を使用します。関数VECTOR_DISTANCEの詳細は、ここにあります。
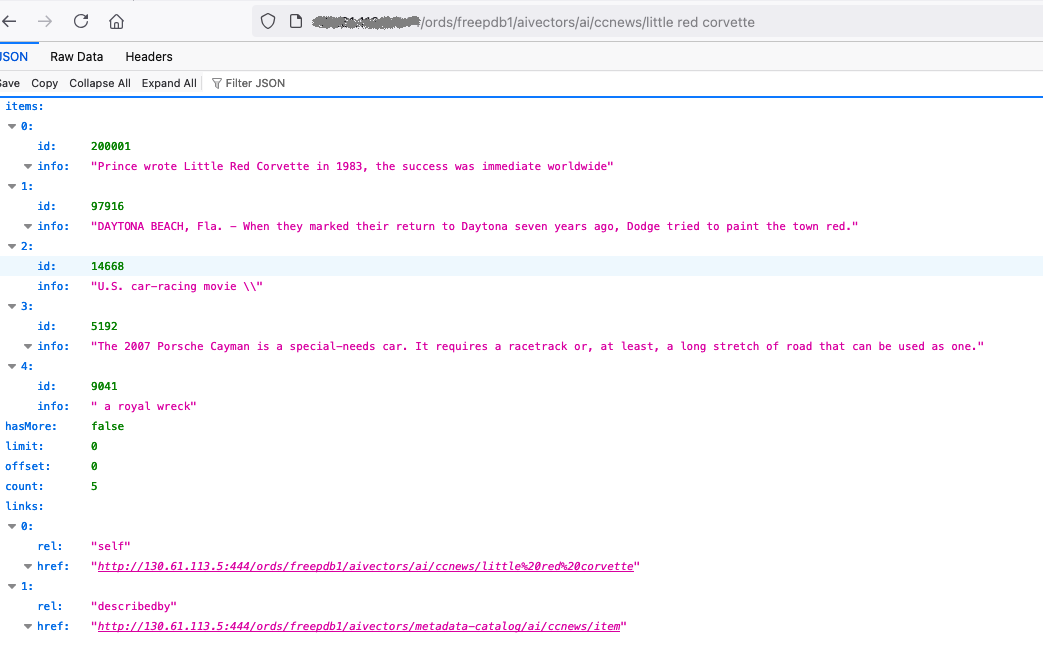
次の例では、「little red corvette」という文に関連する見出しを探しています:
set timing on col info format a90 set lines 120 select id, info from CCNEWS order by vector_distance(vec, TO_VECTOR(VECTOR_EMBEDDING(doc_model USING 'little red corvette' as data)), COSINE) fetch approx first 5 rows only; ---------- ------------------------------------------------------------------------------------------ 97916 DAYTONA BEACH, Fla. - When they marked their return to Daytona seven years ago, Dodge trie d to paint the town red. 14668 U.S. car-racing movie \ 5192 The 2007 Porsche Cayman is a special-needs car. It requires a racetrack or, at least, a lo ng stretch of road that can be used as one. 9041 a royal wreck 11981 From the Tokyo auto show another member of the German automaker's 'new small family' line of concept cars debuts. Elapsed: 00:00:00.44 exit
「little red corvette」を表すベクトルへのベクトル距離が小さい5行を取得しました。
VECTOR_DISTANCE関数で使用される”COSINE”パラメータ: 2つのベクトル間で計算できる距離のタイプがいくつかあります。1つはCOSINE、もう1つはEUCLIDEAN距離、2倍のEUCLIDEANなどに基づいています。経験則として、埋め込みモデルの構築に使用したものと同じタイプの距離(この場合はCOSINE)を使用する必要があります。
前の問合せの実行計画を簡単に確認できます:
set autotrace traceonly explain select id, info from CCNEWS order by vector_distance(vec, TO_VECTOR(VECTOR_EMBEDDING(doc_model USING 'little red corvette' as data)), COSINE) fetch approx first 5 rows only; Execution Plan ---------------------------------------------------------- Plan hash value: 2370891095 ----------------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes |TempSpc| Cost (%CPU)| Time | ----------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 5 | 10075 | | 106K (1)| 00:00:05 | |* 1 | COUNT STOPKEY | | | | | | | | 2 | VIEW | | 235K| 452M| | 106K (1)| 00:00:05 | |* 3 | SORT ORDER BY STOPKEY | | 235K| 454M| 460M| 106K (1)| 00:00:05 | | 4 | TABLE ACCESS STORAGE FULL| CCNEWS | 235K| 454M| | 14073 (1)| 00:00:01 | ----------------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 1 - filter(ROWNUM<=5) 3 - filter(ROWNUM<=5) Note ----- - dynamic statistics used: dynamic sampling (level=2) - automatic DOP: Computed Degree of Parallelism is 1 because of no expensive parallel operation exit
表に対して全表スキャンが実行されたため、200.000行ごとにVECTOR_DISTANCEが実行されました。ただし、問合せは0.44秒で実行されました。これは優れたパフォーマンスです。
必要に応じて、ベクトル索引を作成することでパフォーマンスを高速化できます。ベクトル索引はベクトル検索を高速化し、正確な検索索引または近似検索索引のいずれかです。正確な検索により、大量のコンピュート・リソースのコストで100%の精度が得られます。ベクトル索引とも呼ばれる近似検索索引は、パフォーマンスの取引精度です。ベクトルは類似度に基づいてグループ化または結合され、類似度は相互の相対距離によって決まります。
ベクトル検索では、2つのvector索引がサポートされています。これらのベクトルはディスク上に構築され、それらのブロックは通常のバッファ・キャッシュにキャッシュされます
- 逆ファイル(IVF)フラット・インデックス: ディスク上に構築されたNeighbor Partition Vector索引とそのブロックは、通常のバッファ・キャッシュにキャッシュされます。
- 階層型Navigable Small Worlds (HNSW)索引: In-Memory Neighbor Graph Vector索引は、完全にインメモリーで構築されています。SGAにVECTOR_MEMORY_SIZEを使用して新しいメモリー・プールを設定し、それを収容する必要があります。
ベクトル索引については、今後の投稿で説明します。
ORDSの使用
ベクトルは、RAC、Data Guard、True Cacheなど、すべてのデータベース機能と統合されています。
ベクトル検索はORDSでAPIを使用して実行できるため、RESTエンドポイントを介してセマンティック検索を実行できます。
次のステップでは、REST対応ベクトル検索を設定します。
まず、VECTOR_USERスキーマに追加の権限を付与します:
-- connect as sys to pdb FREEPDB1
grant SODA_APP to VECTOR_USER;
BEGIN
ords_admin.enable_schema (
p_enabled => TRUE,
p_schema => 'VECTOR_USER',
p_url_mapping_type => 'BASE_PATH',
p_url_mapping_pattern => 'aivectors',
p_auto_rest_auth => TRUE -- this flag says, don't expose my REST APIs
);
COMMIT;
END;
/
exit
ここで、VECTOR_USERスキーマを使用して、ベクトル検索をサポートするRESTサービスを定義します:
sqlplus vector_user/Oracle_4U@FREEPDB1
BEGIN
ORDS.define_service(
p_module_name => 'vectorsearch',
p_base_path => 'ai/',
p_pattern => 'ccnews/:mysentence',
p_method => 'GET',
p_source_type => ORDS.source_type_collection_feed,
p_source => 'SELECT id,info from CCNEWS order by vector_distance(vec, TO_VECTOR(VECTOR_EMBEDDING(doc_model USING :mysentence as data)), EUCLIDEAN) fetch approx first 5 rows only',
p_items_per_page => 0);
COMMIT;
END;
/
exit
「mysentence」をバインド変数としてサービスを作成したことを確認します。ブラウザで次のURLを使用し、ベクトル検索を実行できるようになりました:
http://<hostname>/ords/freepdb1/aivectors/ai/ccnews/little%20red%20corvette
これは、以前使用したSQL問合せと同じ結果を返します。
まとめ
Oracle Database 23aiでは、生成Al埋込みモデルを格納するベクトルのサポート、Al Vector Similarity Search、および強力な新しいAIインデックスなど、強力な新しいベクトル・データベース機能スイートが導入されています。このチュートリアルでは、埋込みモデルをデータベースにロードし、PL/SQLパッケージを使用してベクトル埋込みを作成し、vectorデータ型列に格納し、ベクトル検索を実行する方法を学習しました。最後に、ORDSフレームワークを使用して、RESTエンドポイントを介して検索を実行しました。23aiでそれを使うのがどれほど簡単か、アイデアを得るために自分で試してみてください。
参考文献
- Oracle AI Vector Search User’s Guide
- Oracle AI Vector Search
- What Is a Vector Database?
- PL/SQLパッケージおよびタイプ・リファレンス: DBMS_VECTOR
- SQL言語リファレンス: Function VECTOR_DISTANCE
- SQL言語リファレンス: Function VECTOR_EMBEDDING
- Oracle AI Vector Search FAQ
- Oracle LiveLab: AI Vector Search – Complete RAG Application using PL/SQL in Oracle Database 23ai
- Github Folder AI Vector Search
