※ 本記事は、Joanne Leiによる”Accelerate distributed deep learning with OCI“を翻訳したものです。
2022年8月10日
ディープ・ラーニング・モデルは、より多くのデータおよび長期にわたってトレーニングされた数十億のパラメータによって大きくなっています。このような大規模なトレーニング・ワークロードを促進するために、お客様は数百ものGPUを必要とします。つまり、インフラは単一のコンピュート・インスタンスを超えてスケーリングされます。Oracle Cloud Infrastructure(OCI)コンピュート・インスタンスBM.GPU4.8には、8つのNvidia A100 Tensor Core GPUが付属しています。128 GPUを必要とするトレーニング・ジョブの場合、16のBM.GPU4.8インスタンスのクラスタに変換されます。
並列性とGPU間通信
トレーニング・モデルが単一のGPU以上に成長すると、モデルの並列化とデータ並列化が分散ディープ・ラーニングに一般的な手法となり、高スループットで低レイテンシのGPUとGPUの通信の必要性が高まります。通常、同じインスタンス内のGPUネットワークは問題ではありませんが、モデル・トレーニングがマルチノードへとスケール・アウトすると困難になります。1つのコンピュート・ノードのGPUは、別のコンピュート・ノード上の別のGPUと直接通信する必要があります。
リモート・ダイレクト・メモリー・アクセス(RDMA)を使用すると、あるコンピュータは、CPUを使用せずにネットワーク経由で別のコンピュータのメモリー・データにアクセスできます。RDMAでは、ネットワーク・アダプタはリモートGPUメモリーから直接読み書きできます。待機時間とCPUのオーバーヘッドを削減することで、パフォーマンスが大幅に向上します。
OCIクラスタ・ネットワーキングのスケーリング
RDMA over converged ethernet(RoCE)は、標準Ethernet経由でのRDMAパケットの転送をサポートするネットワークプロトコルです。RoCE上に構築されたOCIは、高スループットおよび低レイテンシRDMAサポートを備えた独自のGPUコンピュート・クラスタを開発しました。このソリューションは、Nvidia GPUインスタンス、Mellanox ConnectXネットワーク・アダプタおよび専用のスパインリーフ・ネットワーク・ファブリックで構成されています。各Mellanoxには、非ブロッキング・バックボーン・ファブリックを介してデータを送信する2つの100Gbpsポートがあり、各BM4.8インスタンスの行レート(185GB/秒以上)のほぼ集約帯域幅になります。

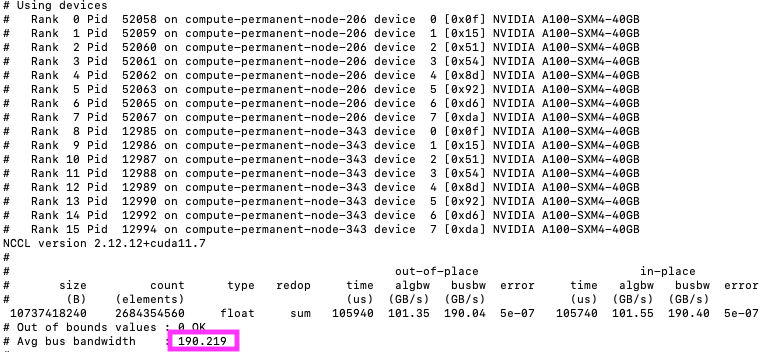
Nvidia Collective Communication Library(NCCL)は、ノード内のNvidia GPUおよびノード全体のMellanox Network用に最適化された multiGPUおよびマルチノードGPU通信プリミティブを提供します。NCCLにより、CUDAアプリケーションとディープ・ラーニング・フレームワークは、複雑なカスタム・コードを記述することなく、GPU間で並列性を実装できます。NCCLテストを実行して、NCCL操作のパフォーマンスと正確性をチェックできます。NCCLテストで取得されるメトリックの1つは、バス帯域幅であり、NCCLが最大限のハードウェア速度で実行されるようにします。次のイメージは、ラボ内の2つのノード(BM4.8)クラスタに対して1秒当たり190GBの結果を示しています。
まとめ
Nvidia NCCLソフトウェア・スタック、OCIクラスタ・ネットワーキング・ハードウェア・スタック、OCI Nvidia GPUインスタンス・ファミリーを組み合せると、基本的にクラウドに巨大GPUマシンを構築して、最も要求の厳しい学習トレーニング・ワークロードに対応するコンピューティング能力を提供できます。
詳細は、次のリソースを参照してください。
