※ 本記事は、Gabrielle Prichardによる”A Practical Guide to Using Sequences in Oracle Analytics“を翻訳したものです。
2024年1月17日
シーケンスについて
Oracle Analyticsのシーケンスは、データ・フロー、データセットおよびその他のシーケンスを論理的に編成および実行するための強力なツールとして機能します。シーケンスは、これらの項目を設定されたスケジュールまたは特定の順序で実行する必要がある場合や、パラレル実行を利用してパフォーマンスを最適化する場合に特に役立ちます。この記事では、フィットネス関連のユース・ケースを通じて、シーケンスの技術的な利点を検討します。
フィットネスのユース・ケース
ウェアラブル・デバイスから、新しいレコードを毎週Oracle Autonomous Data Warehouse (ADW)テーブルに入力するデータ・ストリーミングがあるとします。目標は、このデータを変換およびクレンジングし、ワークブックでビジュアル化するためのキュレートされたデータセットを作成することです。また、ワークアウト中の消費カロリーを予測する機械学習モデルをトレーニングし、定期的に再トレーニングすることです。ステップの概要を次に示します。:
- データの準備と変換: データ・フローを使用して、ウェアラブル・デバイスの生データをクレンジングし、ビジュアライゼーションや機械学習のトレーニングおよびテストに使用するデータセットを作成します。
- コードなしの機械学習モデルのトレーニング: データ・フロー内のノーコード機械学習機能を使用して、カロリー消費量を予測するモデルを作成します。
- モデルのパフォーマンス評価: モデルがテスト・データセットでどのように動作するかを確認し、結果をワークブックで可視化します。
- 外部データセットを組み込む: キャッシュされた天候関連データセットをワークブックで使用するためにリロードし、外気温および一般的なランニング条件に基づく平均ランペースなどの傾向を分析します。
次のハイレベル・アーキテクチャ図は、ウェアラブル・デバイス・データを使用して前述のリストの要件に対応するソリューションを示しています。このソリューションには複数のアーティファクトが含まれており、様々なジョブの実行が必要です。
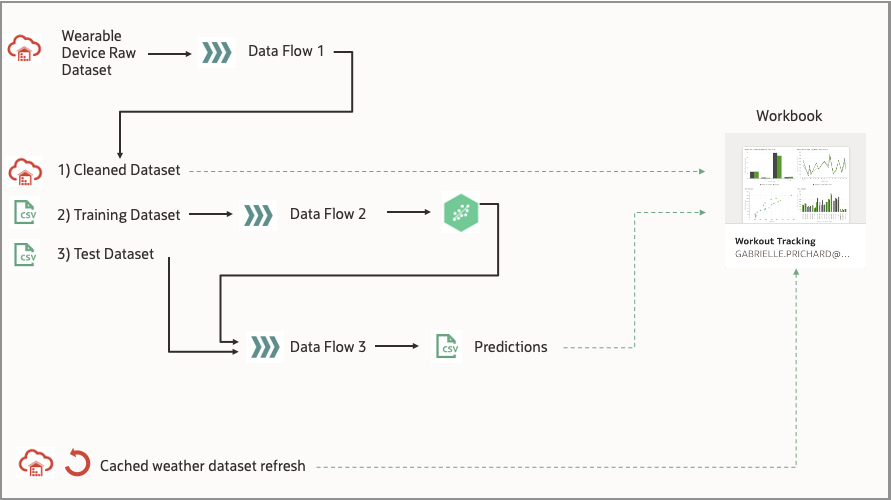
このプロセスを簡素化および自動化するために、これらのプロセスを、設定されたスケジュールで実行されるシーケンスにグループ化できます。シーケンスに依存することで、アーティファクトごとに個別のスケジュールを構成する必要がなくなります。シーケンスはスケジューリングと実行を簡素化するだけでなく、他のユーザーとの共有をより迅速にします。ユーザーは、簡単にシーケンスを共有でき、数回クリックするだけでコンテンツおよび関連するアーティファクトを自動的に共有できます。
効率的なワークフローの構築
次のセクションでは、ウェアラブル・デバイス・データ・ソリューションを構築する方法について説明します。このソリューションは、データが最新であることを確認するために、個人のOracle Analytics Cloud (OAC)環境でスケジュールされたシーケンスで実行されます。
ステップ1: データの準備と変換
ウェアラブル・デバイス・データをクレンジングするデータ・フローを作成し、ワークブックでのビジュアライゼーションの作成に使用するキュレートされたデータセットを作成します。このデータ・フローでは、機械学習の目的でトレーニングおよびテストのデータセットも作成します。次のスクリーンショットは、適用された様々な変換ステップと、生成された3つの出力データセットを示しています。
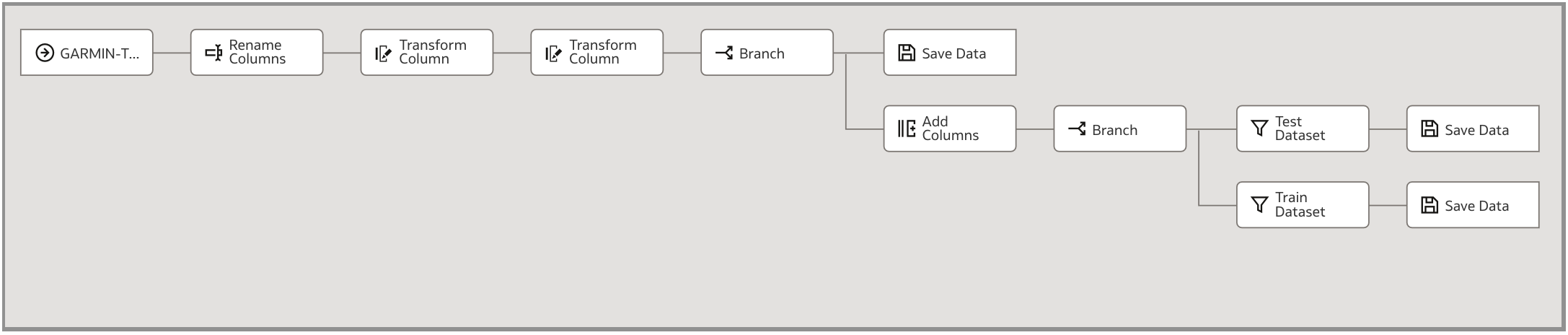
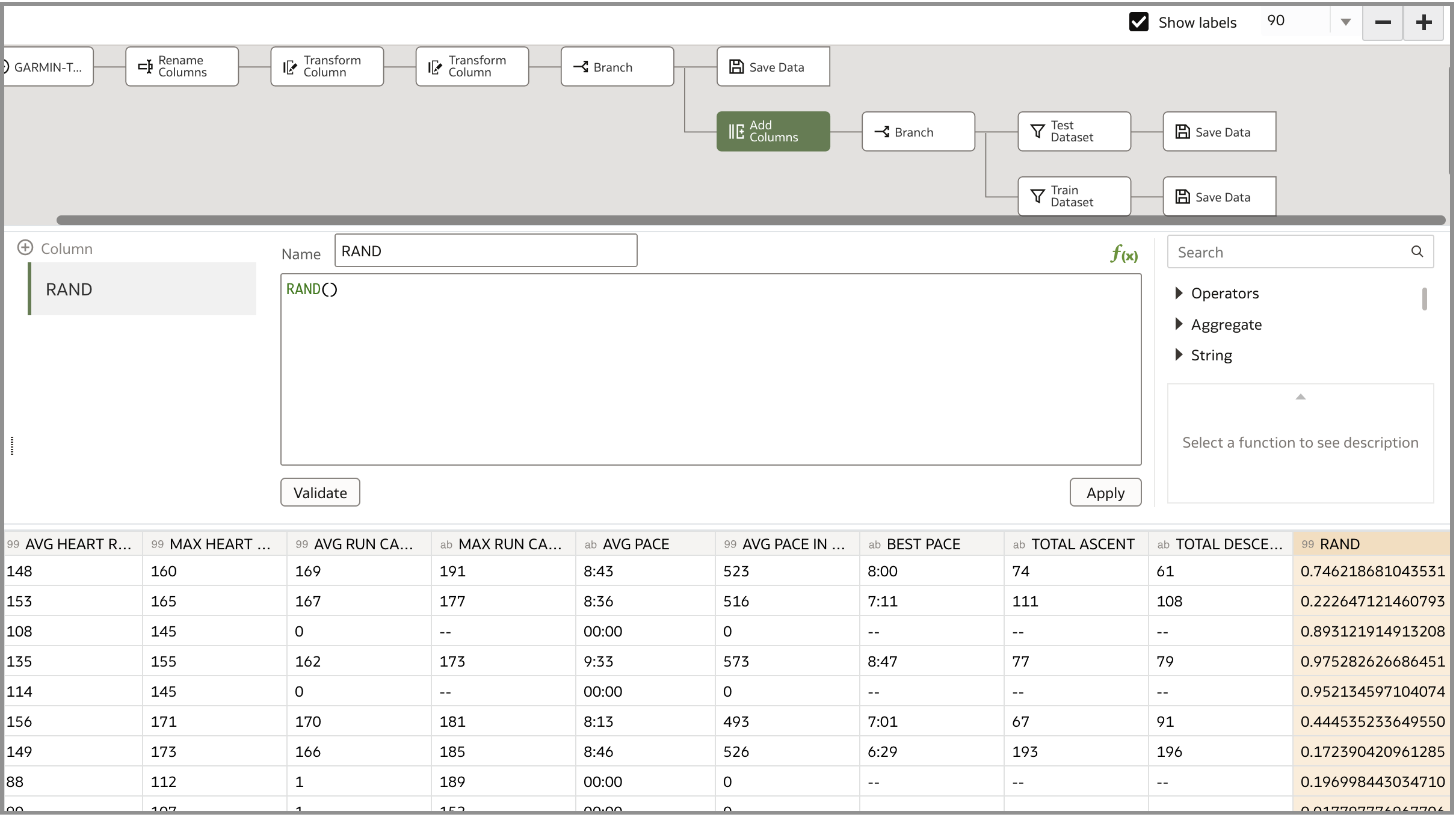
このデータ・フローを使用して、機械学習用のテストおよびトレーニング・データセットを作成しました。データをクレンジングした後、ブランチ・ステップを使用してブランチを作成し、RAND()関数を使用して「列の追加」ステップを使用しました。この関数は、0から1までの疑似乱数を持つ列を作成します。別のブランチを作成して、2つの異なるテスト・データセットとトレーニング・データセットを作成しました。テスト・データセットを作成するには、「フィルタ」ステップを使用して、新しく追加した列が0.7を超えた行を選択的に取得します。トレーニング・データセットを作成するには、「フィルタ」ステップを使用して、新しい列の値が0.7以下の行を取得します。このプロセスにより、トレーニングとテストのデータをランダムに選択できるようになりました。
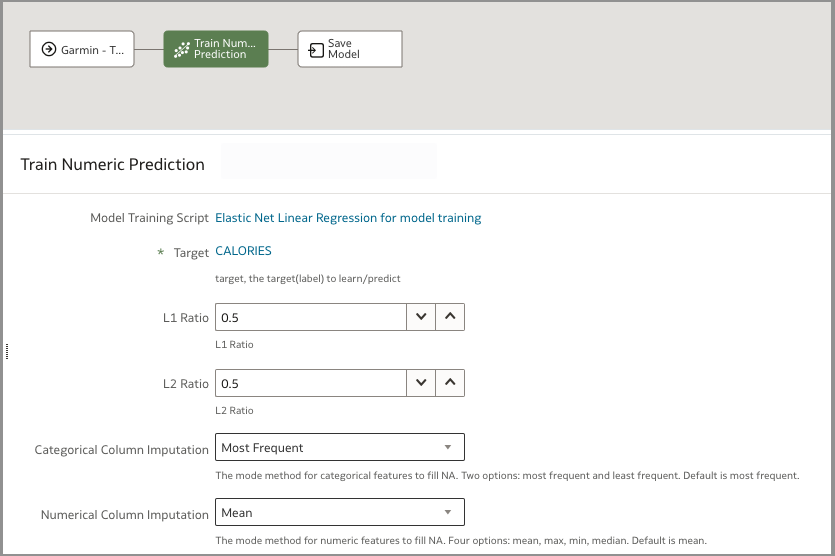
ステップ2: コードなし機械学習モデル・トレーニング
ソリューションに関連する2番目のデータ・フローでは、上記のデータ・フローで作成されたトレーニング・データセットを使用して、各ワークアウトで消費されるカロリーの数を予測する数値予測モデルが生成します。つまり、データ・フロー1の出力がデータ・フロー2の入力として使用されます。
ステップ3: モデル・パフォーマンス評価
3番目と最後のデータ・フローでは、上記で生成された機械学習モデルを最初のデータ・フローで生成されたテスト・データセットに適用します。目的は、機械学習モデルが消費カロリーをどの程度予測するかを検証することです。
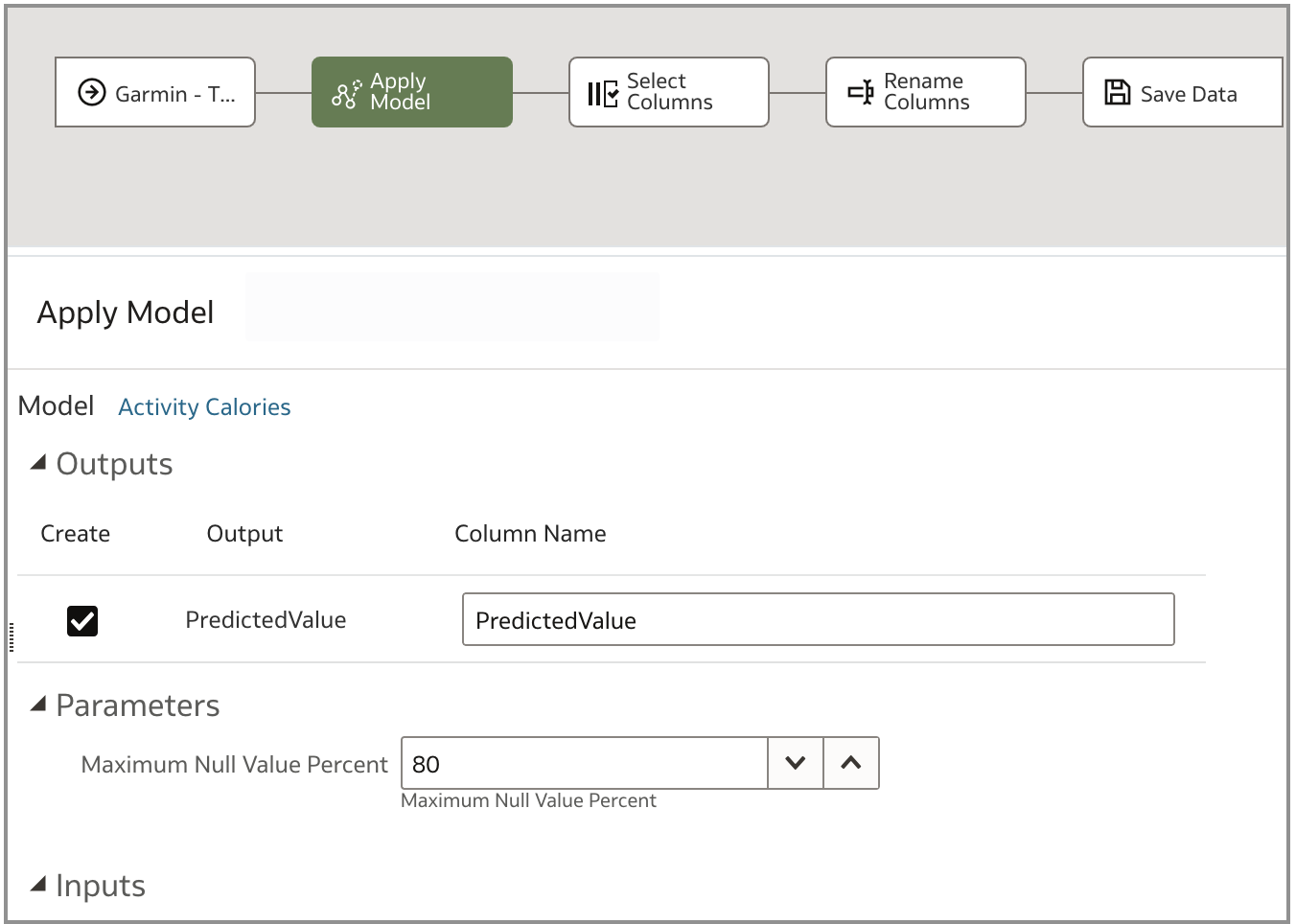
ステップ4: 外部データセットおよびグループ・アイテムのシーケンスへの組込み
上記のデータ・フローには多数の依存関係があることは明らかです(例えば、データ・フロー1はデータ・フロー2および3によって使用されるアーティファクトを生成するため、最初に実行する必要があることを意味します)。このステップでは、これらのデータ・フローをシーケンスに追加し、最新の気象情報を取得するためにリフレッシュが必要なキャッシュされた気象データセットも追加します。次のスクリーンショットは、これら3つの項目を順番に示しています。次のスクリーンショットでは、シーケンス・アイテムが順番にリストされておらず、ページ上部の「Ordered」トグルが選択されていないことに注意してください。このトグルの選択を解除すると、パフォーマンスを最適化するために、可能なかぎり多くのタスクが並行して実行されます。アーティファクトの依存関係を考慮して、アイテムの実行順序を決定します。「Ordered」トグルがチェックされている場合、アイテムを配置する順序が重要になります。アイテムは配置された順序で実行されます。
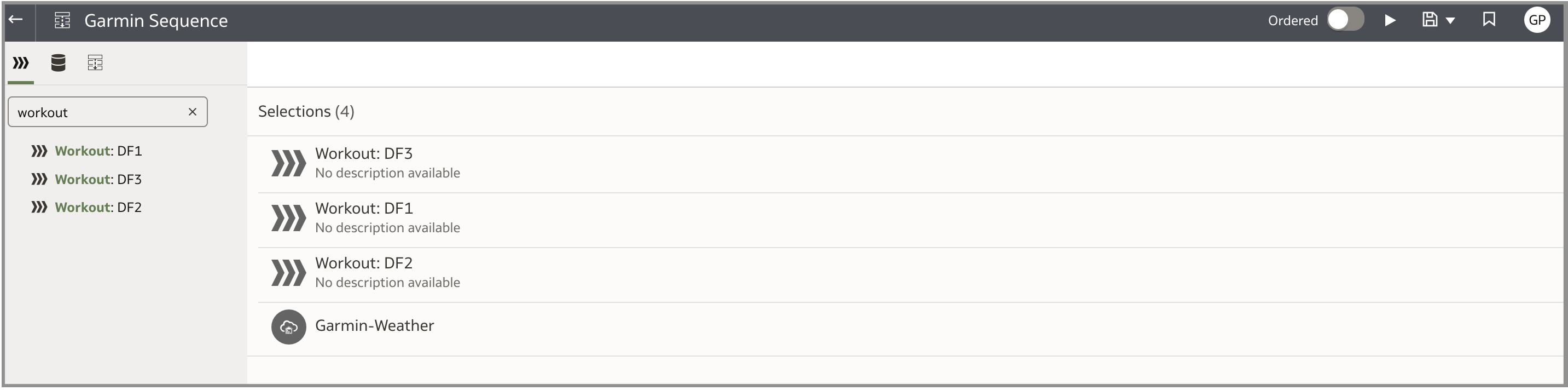
前述のとおり、このシーケンスはスケジュール通りに実行されます。
結果の視覚化
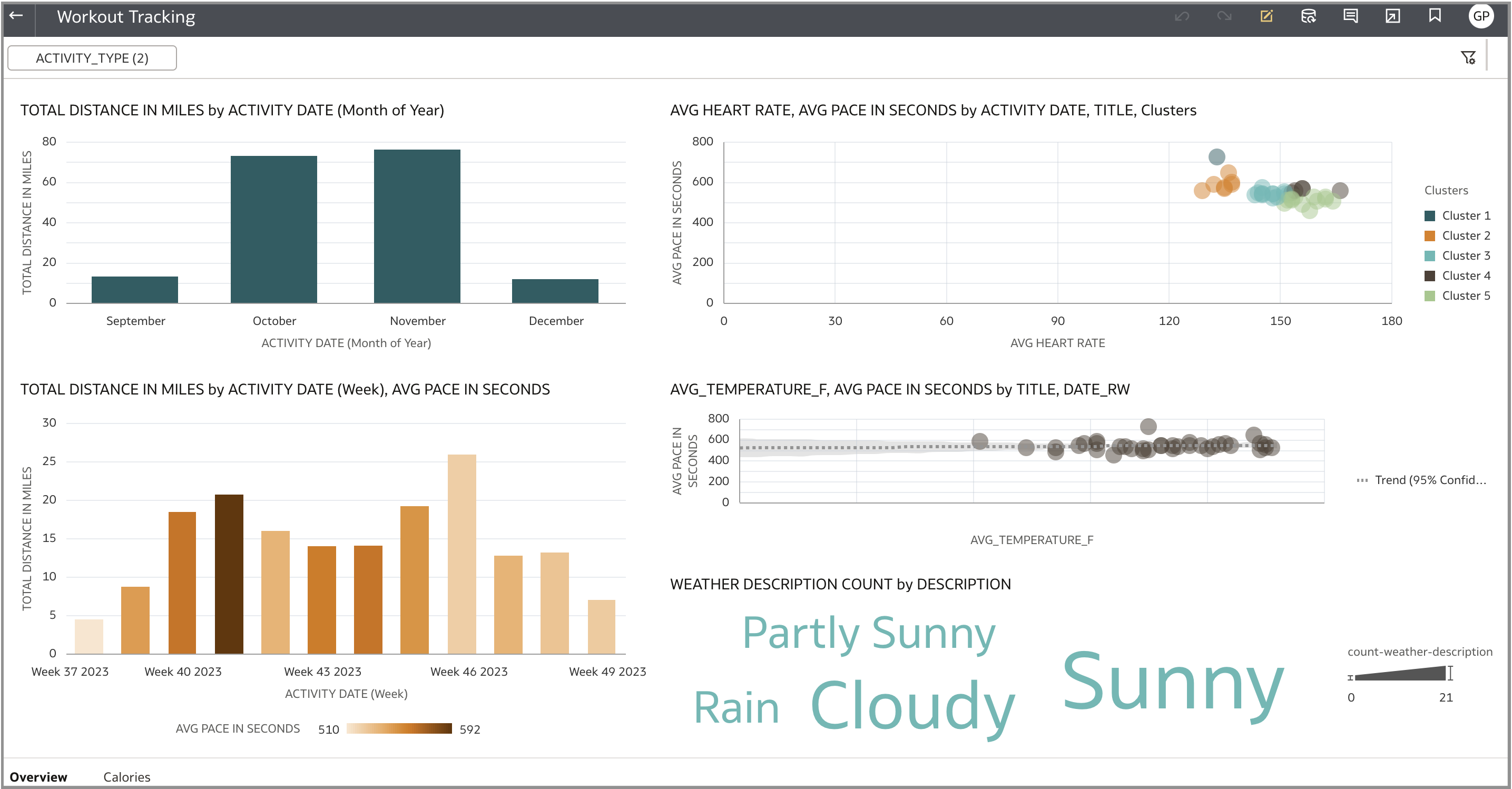
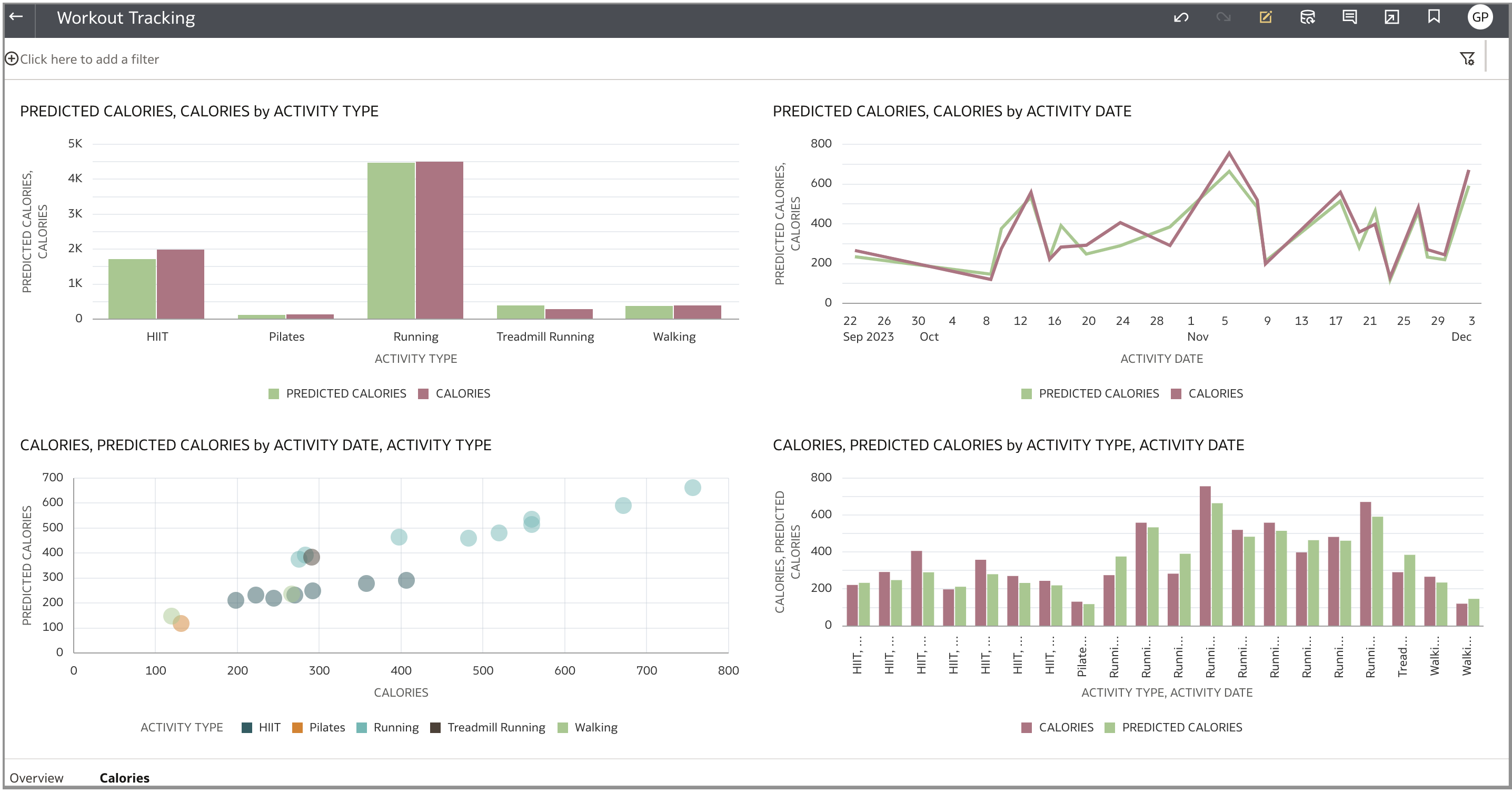
次のスクリーンショットは、このソリューションの一部として作成されたビジュアライゼーションを示しています。シーケンスはスケジュールで実行されているため、データは常に最新です。最初のキャンバスには、最も一般的なワークアウト・タイプ、トレーニング全体でランニング・ペースがどのように変化したか、および外気温に基づいてペースがどのように変化するかを示すビジュアライゼーションが含まれています。
次のキャンバスには、機械学習モデルの予測から生成されたチャートが含まれています。これらのビジュアライゼーションから、モデルが特定のワークアウトの消費カロリーを予測するのに適していることがわかります。このビジュアライゼーションは、様々なワークアウト・タイプおよび特定のアクティビティに対する総消費カロリーと予測消費カロリーを示しています。
行動喚起
この記事からインスピレーションを引き出し、データフローとシーケンスの力を活用して分析ワークフローを合理化することをお勧めします。シーケンスを活用することで、データ処理を最適化し、自動化を強化し、価値実現までの時間を短縮できます。シーケンスの詳細は、このリソースを参照してください。
