この記事はSanket Jain、Mark Hornick、Abhishek Singh、Amit Mehrotra、Sandeep Khotによる”Unlocking Data Insights with the Oracle AI Database Agent in Gemini Enterprise: Part 2“の日本語翻訳版記事です。
はじめに
Part 1 では、カスタムの自然言語 SQL 変換スタックを構築することなく、Gemini Enterprise をライブの Oracle データに接続する最短の方法を紹介しました。この記事は、その基盤をさらに拡張したい開発者向けです。
ここでは、Oracle AI Database Agent が引き続き、ガバナンスの効いた Oracle データプレーンおよび SQL 実行エンジンとして機能します。その上で、Cloud Run 上で動作するカスタム ADK オーケストレーターが、並列データ収集、Web 情報による補強、チャート生成、ドキュメント配信といった合成処理を追加します。
この違いは重要です。Part 1 の Oracle AI Database Agent を置き換えるわけではありません。また、AI を機能させるためだけに Oracle データを別のミドルウェア層へコピーするわけでもありません。Oracle エージェントを、より広範なワークフローの中の専門エージェントの1つとして利用します。これにより、独自のデータ連携基盤を構築・保守することなく、信頼性が高く、ガバナンスの効いた形で、モデルに記録システムへのアクセスを提供できます。
この記事を読み終えるころには、A2A によって複数のエージェントがタスクを分解し、並列に実行し、単一エージェント内では構築が難しい結果を統合できることを示す、Cloud Run 上のデプロイ可能なリファレンスアーキテクチャを理解できます。
対象読者
- ADK を使ってエージェント型アプリケーションを構築する Google Cloud 開発者
- より広範なワークフローの中で、Oracle AI Database Agent をガバナンスの効いた Oracle データアクセスコンポーネントとして使いたい開発者
- 本番システム向けの統合パターンとして A2A を評価しているエンジニア
構築するもの
Oracle Sales Intelligence Hub は、5つの専門エージェントをオーケストレーションすることで、Oracle の売上データに関する複雑なビジネス質問に回答できる開発者向けリファレンスアプリケーションです。
Part 1 の Oracle AI Database Agent が Oracle データアクセスを担当し、その他のエージェントが外部コンテキスト、可視化、統合、配信を追加します。
- oracle_analyst
A2A リモートエージェントを介して Oracle AI Database、ここでは Sales History スキーマに問い合わせます。 - web_analyst
Gemini の Web 検索グラウンディングを使って、外部市場コンテキストを検索します。 - charts_agent
売上の棒グラフと地理マップを PNG 画像として生成します。 - synthesis_agent
すべての入力を統合し、構造化されたエグゼクティブブリーフィングを作成します。 - docs_writer_agent
完成したブリーフィングを Cloud Storage にアップロードし、署名付き URL を返します。
たとえばユーザーが「英国市場について、2025年度第3四半期のブリーフィングを作成して」と1つの質問を入力すると、チャート、市場コンテキスト、共有可能なリンクを含むブリーフィング文書を、1つの Gemini Enterprise チャット応答の中で受け取れます。
エージェントのトポロジー
エージェントは SequentialAgent パイプラインとして構成され、データ収集段階では ParallelAgent が使われます。
root_agent (LlmAgent is the entry point)
└── briefing_pipeline (SequentialAgent)
├── data_gathering_team (ParallelAgent)
│ ├── oracle_analyst this refers to Oracle Database AI
Agent[RemoteA2aAgent]
│ └── web_analyst for Gemini web search grounding
├── charts_agent for bar chart png
├── synthesis_agent to combine Oracle + web + charts
└── docs_writer_agent to store in Cloud StorageParallelAgent は oracle_analyst と web_analyst を同時に実行します。これはマルチエージェントの重要な価値の1つです。どちらかのエージェントがもう一方を待つ必要がないため、逐次実行と比べて全体のレイテンシをおおよそ半分にできます。
前提条件
このブログの Part 1 で準備したもの
- Oracle エージェント URL: Oracle NL2SQL A2A エージェントのベース URL
- Oracle トークン URL: データベースの OAuth トークンエンドポイント
- Oracle クライアント ID とクライアントシークレット: OAuth 登録ステップで取得したもの
- Select AI プロファイル: Sales History(SH)スキーマを使って構成済みのもの
GCP 側のセットアップ要件
- 次の API が有効化された GCP プロジェクト
- Vertex AI API
- Cloud Run API
- Cloud Build API
- Secret Manager API
- Cloud Storage API
- Maps Static API
- 次のロールを持つサービスアカウント
- Vertex AI User
- Secret Manager Secret Accessor
- Storage Object Admin
- Logs Writer
- Service Account Token Creator
- Cloud Storage バケット
署名付き URL 配信用にはマルチリージョンを推奨します。 - Google Maps API キー
Maps Static API に制限してください。 - 認証済みの gcloud CLI
プロジェクト構成
oracle-sales-hub/
├── orchestrator/
│ ├── demo_sales_hub/ ADK agent package
│ │ ├── __init__.py
│ │ └── agent.py all agent definitions
│ ├── oracle_auth.py Oracle OAuth client factory
│ ├── gcs_tool.py Cloud Storage upload
│ ├── charts_tool.py Bar chart + Maps API map
│ ├── main.py ADK FastAPI entry point
│ ├── requirements.txt
│ └── Dockerfile
└── infra/
└── deploy.sh Cloud Run deployment script認証に関する補足: Part 1 では、ユーザー向けのマネージドフローを説明しました。このフローでは、クエリは各ユーザーの Oracle Database ID で実行されます。一方、このリファレンスアーキテクチャでは、開発者が所有するオーケストレーターを Cloud Run 上に導入し、そのオーケストレーターと Oracle リモートエージェントの間でサービス間認証を使用します。
Step 1: Oracle OAuth 認証
Oracle Database AI Agent は、OAuth 2.0 の password grant、つまりリソースオーナーパスワード認証情報を使用します。このグラントにより、オーケストレーターはデータベースのユーザー名とパスワードを使ってトークンを取得できます。
oracle_auth.py モジュールでは、Bearer トークンを取得し、キャッシュし、有効期限の60秒前に更新する httpx.Auth クラスを実装します。これは ADK の RemoteA2aAgent に、a2a_client_factory パラメーターを通じて接続されます。
# oracle_auth.py (key excerpt)
class OracleOAuthAuth(httpx.Auth):
def __init__(self, token_url, client_id, client_secret, username,
password):
self.token_url = token_url
self.client_id = client_id
self.client_secret = client_secret
self.username = username
self.password = password
def _get_token(self) -> str:
resp = client.post(self.token_url, data={
"grant_type": "password",
"username": self.username,
"password": self.password,
"client_id": self.client_id,
"client_secret": self.client_secret,
})
return resp.json()["access_token"]
def auth_flow(self, request):
request.headers["Authorization"] = f"Bearer {self._get_token()}"
yield request
def get_oracle_client_factory(token_url, client_id, client_secret,
username, password):
auth = OracleOAuthAuth(token_url, client_id, client_secret, username,
password)
async_client = httpx.AsyncClient(
timeout=httpx.Timeout(timeout=60.0),
auth=auth,
headers={"Content-Type": "application/json"},
)
return
ClientFactory(ClientConfig(httpx_client=async_client))このパターンは、Google 以外の OAuth を必要とする任意の A2A リモートエージェントに再利用できます。他のサードパーティ A2A エージェントを統合する場合も、自分のトークンエンドポイントとグラントタイプに合わせて、同じ httpx.Auth サブクラスのパターンを実装します。
Step 2: Oracle NL2SQL A2A エージェントに接続する
Oracle Database AI Agent は、Oracle 固有の実装に基づくパスで A2A エンドポイントを公開します。Oracle では次の形式を使用します。
ORACLE_AGENT_URL/agents/{agent-name}ここでは URL ではなく、事前に構築した AgentCard オブジェクトを RemoteA2aAgent に直接渡します。これにより、HTTP による取得を完全にバイパスできます。
from a2a.types import AgentCard, AgentSkill,
AgentCapabilities
def _make_oracle_remote_agent(name: str) -> RemoteA2aAgent:
agent_card = AgentCard(
name="Oracle AI Database Agent",
description="Queries Oracle Autonomous AI Database using natural
language.",
url=ORACLE_AGENT_URL + AGENT_CARD_PATH,
version="1.0.0",
default_input_modes=["text/plain"],
default_output_modes=["text/plain"],
capabilities=AgentCapabilities(streaming=False),
skills=[AgentSkill(
id="nl2sql",
name="NL2SQL Query",
description="Converts natural language to SQL and queries
Oracle.",
tags=["oracle", "sql", "database"],
examples=["Show revenue by channel for Q3 FY2025"],
)],
)
return RemoteA2aAgent(
name=name,
description="Queries Oracle Autonomous AI Database using natural
language.",
a2a_client_factory=get_oracle_client_factory(
token_url=ORACLE_TOKEN_URL,
client_id=ORACLE_CLIENT_ID,
client_secret=ORACLE_CLIENT_SECRET,
username=ORACLE_USERNAME,
password=ORACLE_PASSWORD,
),
agent_card=agent_card, # pre-built object, no HTTP fetch
use_legacy=True,
)重要なのは、NL2SQL と Oracle クエリ実行は引き続き Oracle 側で行われるという点です。Cloud Run 上のオーケストレーターは、自然言語を自分で SQL に変換しません。A2A を通じて、Oracle データの取得を Oracle AI Database Agent に委任します。
Step 3: Oracle と Web 検索を並列実行する
ADK の ParallelAgent は、すべてのサブエージェントを同時に実行し、その出力を共有会話コンテキストに収集します。data_gathering_team は、Oracle クエリと Web 検索を同時に実行します。
data_gathering_team = ParallelAgent(
name="data_gathering_team",
sub_agents=[oracle_analyst, web_analyst],
)各サブエージェントは、自分の出力の先頭に明確なヘッダーを付けます。これにより、後続の統合エージェントが各データソースを確実に見つけられるようになります。
Step 4: 視覚的なチャートを生成する
Gemini Enterprise は、エージェントカードで image/png を出力モードとして宣言している場合、チャット内に PNG 画像をインライン表示できます。charts_tool.py モジュールは、2種類の画像を生成します。
棒グラフ
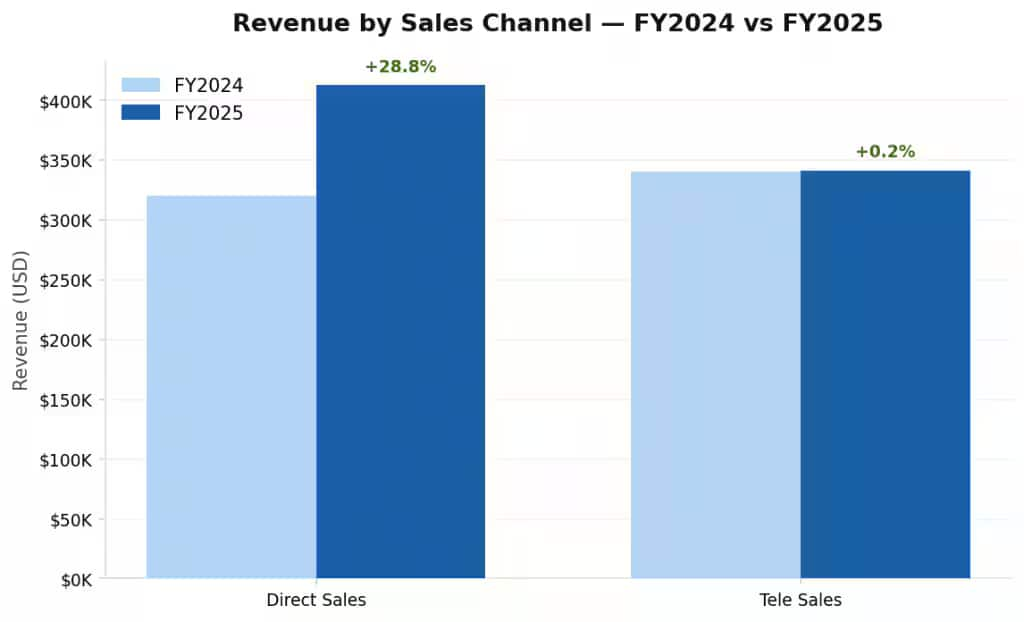
Matplotlib で生成します。Direct Sales、Tele Sales などの販売チャネルごとに、FY2024 と FY2025 の棒を横並びで表示し、前年比の割合も示します。
# charts_tool.py (bar chart excerpt)
bars_2024 = ax.bar(x - bar_width/2, fy2024_vals, bar_width,
label="FY2024", color="#B5D4F4")
bars_2025 = ax.bar(x + bar_width/2, fy2025_vals, bar_width,
label="FY2025", color="#185FA5")
# YoY % label above each FY2025 bar
for i, (v24, v25) in enumerate(zip(fy2024_vals, fy2025_vals)):
yoy = ((v25 - v24) / v24) * 100
color = "#3B6D11" if yoy >= 0 else "#A32D2D"
ax.text(x[i] + bar_width/2, v25, f"+{yoy:.1f}%",
ha="center", color=color, fontweight="bold")地理分布を示す売上マップ
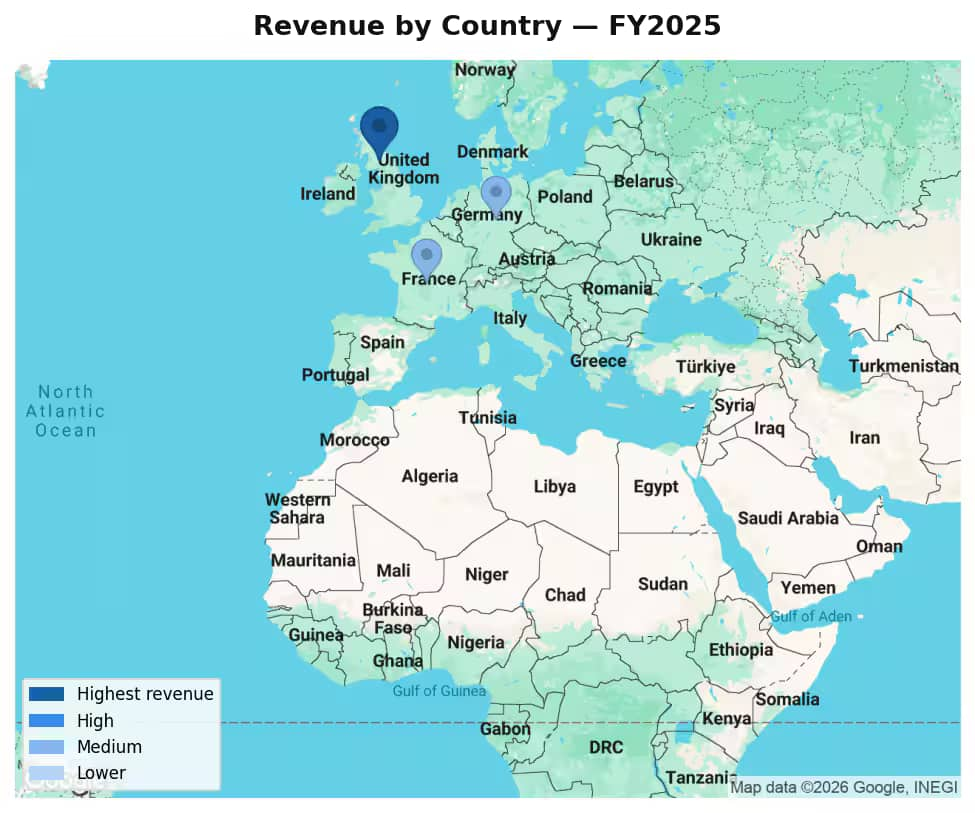
Google Maps Static API を使って生成します。国ごとの中心座標に円形マーカーを重ね、売上規模に応じてマーカーの大きさと色を変えます。Oracle の結果に含まれる国に基づいて、地図の中心とズームは自動的に調整されます。
# charts_tool.py (map excerpt)
params = {
"size": "800x500",
"scale": "2", # retina quality
"maptype": "roadmap",
"center": f"{center_lat},{center_lon}",
"zoom": str(zoom),
"key": MAPS_API_KEY,
}
# Add a circle marker per country, colored by revenue intensity
for country, revenue in mapped.items():
lat, lon = COUNTRY_COORDS[country]
markers.append(f"color:{color}|size:{size}|{lat},{lon}")両方の画像は Cloud Storage にアップロードされ、署名付き URL として返されます。charts_agent は data_gathering_team の完了後に実行されるため、売上数値の解析に必要な Oracle データへアクセスできます。URL は Gemini Enterprise のチャット応答内にクリック可能なリンクとして表示され、ユーザーは新しいタブでフル解像度のチャートを開けます。
Step 5: ブリーフィングを統合する
統合エージェントは、共有会話コンテキストを通じて、上流の3つの入力を受け取ります。そして、それらを組み合わせて構造化された Markdown のブリーフィングを作成します。
出力されるブリーフィングは、売上実績、地理分布、市場コンテキスト、推奨事項などのセクションを持つ固定構造に従います。
Step 6: Cloud Storage 経由でブリーフィングを配信する
docs_writer_agent は upload_briefing_to_gcs() を呼び出し、ブリーフィングを HTML ページに変換して Cloud Storage バケットにアップロードします。簡略化のため、この例ではファイルを公開読み取り可能なストレージに配置します。
Gemini Enterprise チャットでの最終応答には、Markdown 形式の構造化ブリーフィング本文、棒グラフと売上マップへの画像リンク、Cloud Storage 上の完全な HTML レポートへのクリック可能な URL が含まれます。
Step 7: エージェントカードで画像出力を宣言する
Gemini Enterprise が、このエージェントが画像コンテンツを返せることを認識できるように、エージェントカード JSON で image/png をサポートされる出力モードとして宣言します。
実際には、Gemini Enterprise は A2A 応答内でバイナリ Blob 添付として送信された画像を表示します。GCS URL として参照されるだけの画像は、インライン表示ではなくクリック可能なリンクとして表示されます。このデモでは、チャートは新しいタブで開くクリック可能リンクとして表示され、完全な HTML ブリーフィングレポートにはチャートがインラインで埋め込まれます。
Gemini Enterprise に貼り付けるエージェントカード JSON には、次のフィールドを含める必要があります。
{
"protocolVersion": "0.1",
"name": "Oracle Sales Intelligence Hub",
"description": "Answers business questions about Oracle sales
data...",
"url": "https://YOUR_CLOUD_RUN_URL",
"version": "1.0.0",
"defaultInputModes": ["text/plain"],
"defaultOutputModes": ["text/plain", "image/png"],
"capabilities": { "streaming": false },
"skills": [{
"id": "sales_briefing",
"name": "Sales Briefing",
"description": "Generates an executive sales briefing...",
"tags": ["sales", "oracle", "analytics", "briefing"],
"examples": ["Give me a Q3 FY2025 briefing for the UK market",
"demo"]
}]
}Step 8: to_a2a() でエージェントを提供する
ADK の get_fast_api_app() は、ADK 独自の API 形式でエージェントを提供します。Gemini Enterprise が期待する A2A JSON-RPC 標準ではありません。
適切な A2A 準拠エンドポイントを公開するには、ADK の to_a2a() 関数を使用します。セッションサービスとアーティファクトサービスを設定した Runner を渡します。
# main.py
import os
import uvicorn
from google.adk.a2a.utils.agent_to_a2a import to_a2a
from google.adk.artifacts import InMemoryArtifactService
from google.adk.runners import Runner
from google.adk.sessions import InMemorySessionService
from demo_sales_hub.agent import root_agent
port = int(os.environ.get("PORT", "8080"))
cloud_run_url = os.environ.get("CLOUD_RUN_URL", "")
host = cloud_run_url.replace("https://", "").replace("http://",
"").rstrip("/")
runner = Runner(
agent=root_agent,
app_name=root_agent.name,
session_service=InMemorySessionService(),
artifact_service=InMemoryArtifactService(),
)
app = to_a2a(
agent=root_agent,
host=host,
port=443,
protocol="https",
runner=runner,
)
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=port)Step 9: Cloud Run にデプロイする
デプロイスクリプトは、すべてのセットアップ手順を自動的に処理します。スクリプト冒頭のプレースホルダーを入力し、プロジェクトルートから実行します。
環境変数
| 変数 | 説明 |
|---|---|
| PROJECT_ID | GCP プロジェクト ID |
| REGION | Cloud Run リージョン。例: us-east4 |
| ORACLE_AGENT_URL | Oracle AI Database Agent のベース URL |
| ORACLE_TOKEN_URL | Oracle OAuth トークンエンドポイント |
| ORACLE_CLIENT_ID | Oracle 登録で取得した OAuth クライアント ID |
| ORACLE_CLIENT_SECRET | OAuth クライアントシークレット。Secret Manager に保存 |
| ORACLE_USERNAME | password grant 認証に使用する Oracle データベースユーザー名 |
| ORACLE_PASSWORD | Oracle データベースパスワード。Secret Manager に保存 |
| GCS_BUCKET_NAME | ブリーフィング出力用の Cloud Storage バケット |
| MAPS_API_KEY | Google Maps Static API キー。Secret Manager に保存 |
| CLOUD_RUN_URL | Cloud Run サービスの公開 URL。エージェントカード作成に使用 |
| SERVICE_ACCOUNT_EMAIL | GCS 署名付き URL 生成用のサービスアカウントメール |
| GOOGLE_GENAI_USE_VERTEXAI | Gemini API キーではなく Vertex AI を使う場合は true |
| GOOGLE_CLOUD_PROJECT | Vertex AI SDK に渡す GCP プロジェクト ID |
| GOOGLE_CLOUD_LOCATION | Gemini モデルの可用性を最も広くするため global を指定 |
| GEMINI_MODEL | gemini-2.5-flash を指定 |
デプロイを実行する
chmod +x infra/deploy.sh
./infra/deploy.shスクリプトは次の処理を実行します。
- アクティブな GCP プロジェクトを設定
- 必要なすべての GCP API を有効化
- Cloud Build サービスアカウントにデプロイ権限を付与
- Oracle クライアントシークレットや Maps API キーを Secret Manager に保存
- Cloud Build 経由で Docker イメージをビルドしてプッシュ
- Zero Trust 認証を使って Cloud Run サービスをデプロイ
- テスト用に現在のユーザーへ Cloud Run invoker アクセスを付与
Step 10: Gemini Enterprise に接続する
デプロイ後、Gemini Enterprise アプリ管理者は、Cloud Run オーケストレーターをカスタム A2A エージェントとして登録します。これは、Part 1 の Oracle AI Database Agent の上にある第2層と考えると分かりやすいです。Gemini Enterprise はオーケストレーターと通信し、オーケストレーターがさらに Oracle エージェントと通信します。
このアーキテクチャには、2つの別々の接続があります。Part 1 の Oracle OAuth 認証情報は、オーケストレーターが Oracle AI Database Agent を呼び出すときに使用します。一方、Gemini Enterprise から Cloud Run サービスへのアクセスは、カスタムエージェントエンドポイントをどのように公開するかに合わせる必要があります。このデモでは、Gemini Enterprise が呼び出せるようにサービスを到達可能にします。
手順は次のとおりです。
- Gemini Enterprise Admin Console を開きます。
Apps → Google Workspace → Gemini Enterprise に移動します。 - Agents に移動し、Add Agent から Custom agent via A2A を選択します。
- エージェントカード JSON を貼り付けます。
YOUR_CLOUD_RUN_URL を実際のサービス URL に置き換えます。url フィールドは Cloud Run サービスのベース URL を指している必要があります。 - OAuth 認証情報を入力します。
Gemini Enterprise は Client ID、Client Secret、Authorization URL、Token URL の入力を求めます。Part 1 と同じ Oracle OAuth 認証情報を使用します。 - アクセス権を付与します。
エージェントの Permissions パネルで、アクセスを許可するユーザー、グループ、または OU を追加します。 - Cloud Run を allUsers に公開します。
Gemini Enterprise がサービスに到達できる必要があります。次を実行します。
gcloud run services add-iam-policy-binding oracle-sales-hub \
--region=YOUR_REGION \
--member="allUsers" \
--role="roles/run.invoker"注意: この設定は再デプロイのたびにリセットされます。永続化するには、deploy.sh 内の gcloud run deploy コマンドに –allow-unauthenticated を追加します。
デモ出力
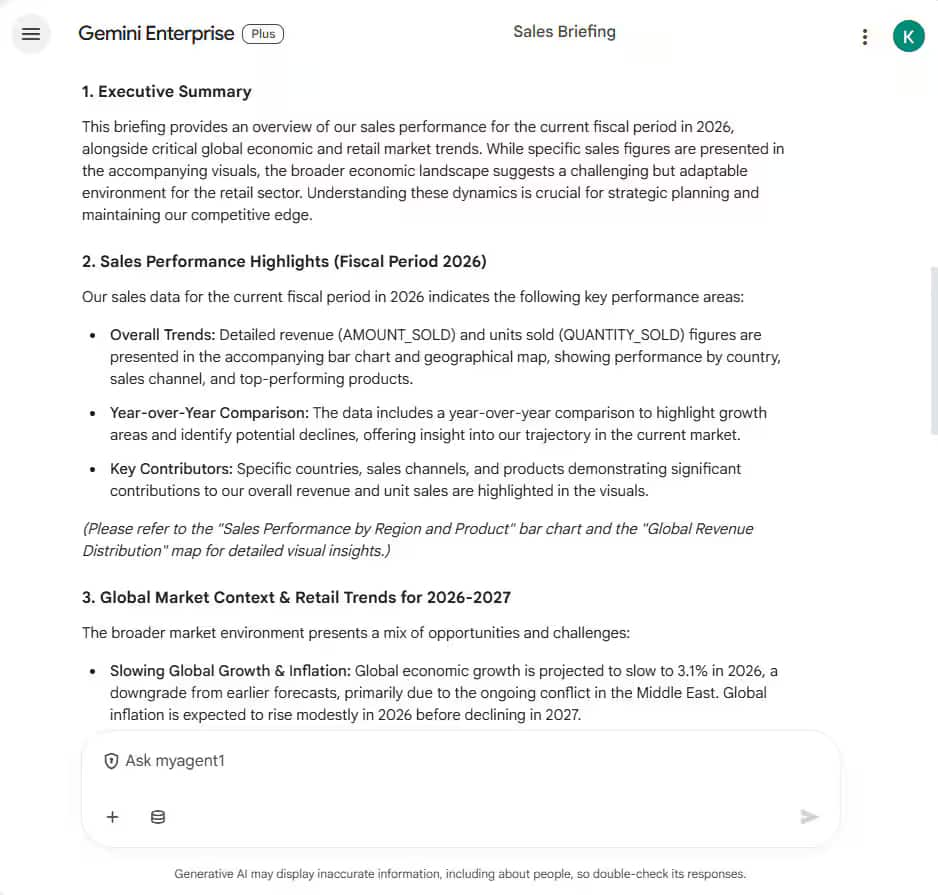
チャット
Gemini Enterprise のチャット内に、デモの応答が表示されます。
チャート
チャートは新しいタブで開きます。たとえば、2024年度と2025年度の販売チャネル別売上を比較する可視化チャートや、地図上に結果を表示する売上分布マップが生成されます。
トラブルシューティング
| 問題 | 対処方法 |
|---|---|
| Cloud Run でコンテナが起動しない | ログを確認します。gcloud logging read で resource.type=cloud_run_revision を指定してください。最も一般的な原因は、環境変数が不足していて import 時にクラッシュしていることです。 |
| ModuleNotFoundError: google.adk.a2a | A2A extras がインストールされていません。requirements.txt の google-adk>=0.4.0 を google-adk[a2a]>=0.4.0 に変更して再デプロイします。 |
| curl でエージェントカードが 404 を返す | ADK の get_fast_api_app() は A2A エンドポイントを公開しません。Step 8 のとおり、main.py で to_a2a() に切り替えます。 |
| Gemini Enterprise に対して Cloud Run が 403 を返す | Gemini Enterprise がサービスに到達できていません。gcloud run services add-iam-policy-binding oracle-sales-hub –member=allUsers –role=roles/run.invoker を実行します。 |
| Gemini モデルで 404、または publisher model not found が発生する | gemini-2.0-flash は新規プロジェクトでは利用できません。gemini-2.5-flash を使用し、deploy.sh で GOOGLE_CLOUD_LOCATION=global を設定します。 |
| 署名付き URL エラー: credentials just contain a token | Compute Engine の認証情報は URL に直接署名できません。SERVICE_ACCOUNT_EMAIL 環境変数を追加し、gcs_tool.py を access_token パラメーターを使用するよう更新し、サービスアカウントに roles/iam.serviceAccountTokenCreator を付与します。 |
| Oracle A2A が ADB-00015 Invalid credential を返す | client_id または client_secret が誤っている、または期限切れです。Oracle OAuth 登録の curl を再実行して、新しい認証情報を生成します。 |
| Gemini Enterprise OAuth error unauthorized | Gemini Enterprise は PKCE なしの authorization code flow を送信します。Oracle OAuth クライアントが PKCE ありで登録されている場合は、token_endpoint_auth_method: client_secret_post を使用して新しいクライアントを登録してください。 |
リンク
- Gemini EnterpriseにおけるOracle AIデータベースエージェントの活用(Part1)
- Google Agent Development Kit (ADK) documentation
- Agent2Agent (A2A) protocol specification
- Implementing Zero Trust A2A with ADK in Cloud Run
- Oracle Autonomous AI Database Select AI documentation
- Google Maps Static API documentation
- Cloud Run deployment documentation
