この記事はSuraj RameshによるOCI Full Stack DR: Advanced Control and Smarter Recovery Operationsの日本語翻訳版記事です。
2026年1月22日
このシリーズの第1部では、OCI Full Stack DRの機能強化についてご紹介しました(米国政府クラウド対応、Oracle Integration Cloudのネイティブ保護、Object Storageスクリプト機能の向上など)。今回は、リカバリー手順をより正確にコントロールし、災害対策時の運用インテリジェンスを強化する最新の機能をご紹介します。
これらの機能拡張は、多くの組織が直面する課題に対応しています。自動でDRプランを生成できるのは便利ですが、アプリケーションごとに固有の依存関係や運用要件を持っています。今回のリリースでは、復旧ワークフローをカスタマイズし、必要なタイミングで重要な情報を可視化できるツールが提供されています。
1. 依存関係のマッピング:プログループや手順の順序変更
OCI Full Stack DRでは、プログループの順序変更や、各グループ間で個々の手順を移動させることによって、リカバリ・シーケンスを自由にカスタマイズできるようになりました。
なぜ重要なのか
例えば、DR計画を作成してドリル(テスト)を実施した結果、リカバリの手順が自社アプリケーションの特有の依存関係に合っていないと気づく場合があります。あるいは、アプリケーションレベルの特定の手順をまとめて実行したい、実行順を業務システムの要件に合わせて調整したい、といったニーズも出てきます。
OCI Full Stack DRの自動依存関係解析はOCIリソースに最適化されたリカバリ手順を提供しますが、アプリケーション・スタックごとに必要な業務要件は異なります。例えば、特定の初期化シーケンスや監視・ミドルウェア・サービスをまとめて実行する必要があるかもしれません。カスタマイズできないと、次のような課題に直面します:
- 柔軟性のないリカバリ手順: 自動生成された計画を自社の業務ロジックに合わせて調整できない。
- 回避策の必要: 実行順序の特別なニーズに合わせて複雑なカスタムスクリプトを作成しなければならない。
- リカバリ時のリスク増: 技術的には復旧が成功しても、サービスの起動順が間違っていると業務的には失敗となる。
- RTO(復旧時間)の延長: DR実施時に手動で調整する必要が生じる。
計画内のグループや手順を自由に並べ替えられることで、自社のビジネスロジックに沿ったリカバリ・ワークフローが実現でき、自動生成計画のメリットも失われません。これは、正確なリカバリー手順がRTOや復旧の成否に直結する高度な多層(マルチティア)アプリケーションでは特に不可欠な機能です。
Full Stack DRにおける依存関係の扱い
Full Stack DRは、プライマリおよび待機DR保護グループ内のOCIリソース間の関係や依存性を自動的に特定し、リカバリー時の正しい手順の順序を判断します。この解析結果をもとに、DRドリル計画、フェイルオーバー計画、スイッチオーバー計画を迅速に生成し、リソースの依存関係ごとに手順をグループ化した組み込みの計画グループとしてまとめます。これにより、各コンポーネントが必要とする前提となるサービスやデータソース、インフラが正しい順序で復旧されるよう保証されます。
組み込みグループに加えて、Full Stack DRではカスタム・スクリプトやOCI関数などもユーザー定義の計画グループとして組み込むことができます。DR計画内では、計画グループ内の手順は並列実行され、計画グループ同士は設定された順序で実行されます。
新機能:リカバリ手順のカスタマイズ
標準の作業順序は、OCIのインフラおよびプラットフォームリソースを復旧するために最適化されたシーケンスになっています。今回のアップデートで、これらのグループ化をカスタマイズし、自社のビジネスシステム要件に合わせた、より細かい依存関係を作成できるようになりました。計画グループの順序を変更したり、組み込みの計画グループから個々の手順を新しいユーザー定義グループへ再編成したり、既存グループ間で手順を移動することも可能です。
計画グループの順序を変更する方法
組み込みグループとユーザー定義グループの両方で、実行順序を調整できます。ただし、Prechecks(事前チェック)の組み込みグループは必ず最初に固定されており、移動できません。Oracleでは、組み込みグループは最適な実行順になっているため、基本的にはユーザー定義グループの並び替えのみを推奨しています。どうしても組み込みグループの順序を変更する場合は、依存関係が正しい順に並んでいるか必ず確認してください。順序が正しくないと、計画の実行が失敗することがあります。
例:
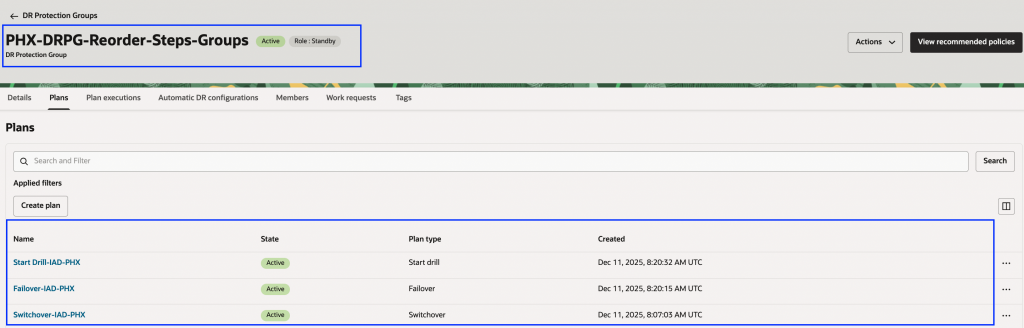
この手順説明では、スイッチオーバー計画を選択し、Autonomous Database – Switchover と Database – Switchover 計画グループの順序を変更します。
- 待機DR保護グループにアクセスし、「計画」をクリックして、修正したいDR計画を選択します。
2.「計画グループ」をクリックして、順番に並んだリストを表示します。
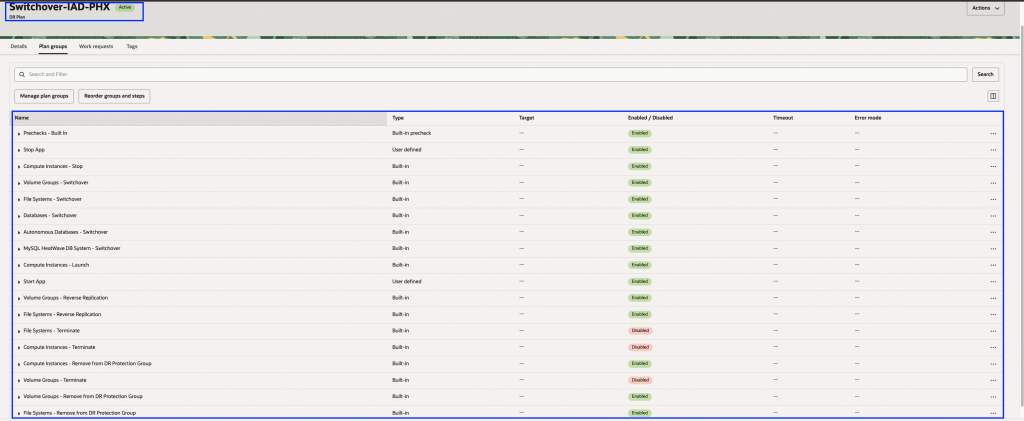
3.「グループと手順の並び替え」をクリックします。
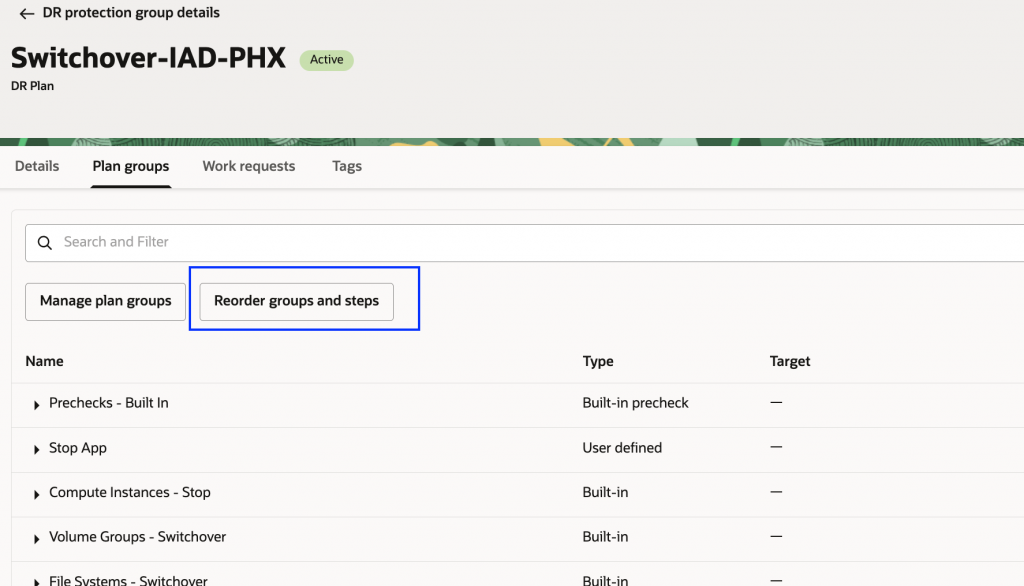
4. 変更したい計画グループを見つけて、三点リーダーのアクションメニューをクリックします。この例では、Autonomous Database – Switchover 計画グループを Database – Switchover 計画グループの前に移動します。グループの位置を変更するには、「上へ移動」または「下へ移動」を選択します。
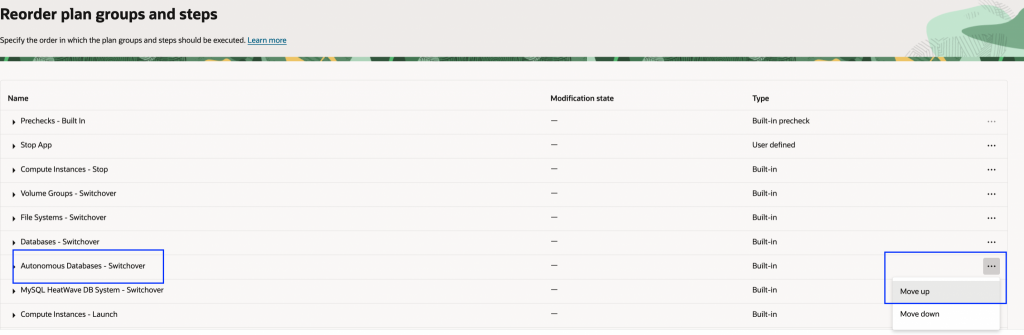
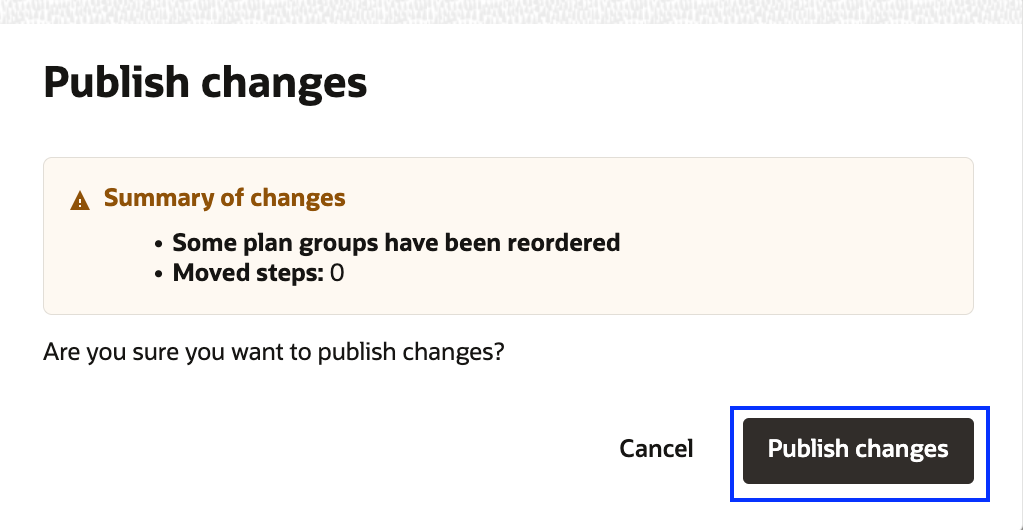
5.「更新」をクリックし、変更内容のサマリーを確認して公開します。
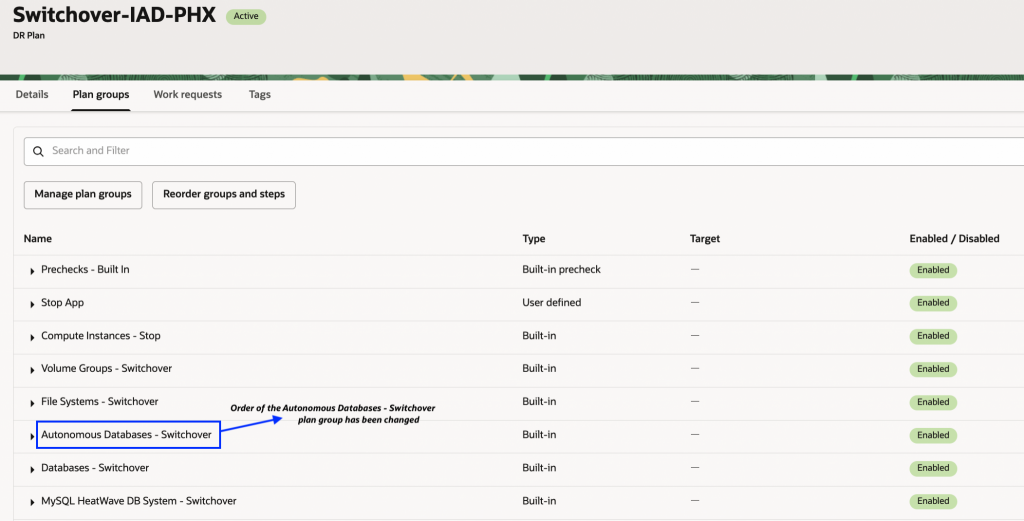
6. 更新された計画グループの順序を確認します。
計画グループ間で手順を移動する方法
1つまたは複数の組み込み計画グループから、他の組み込みグループやユーザー定義グループに計画手順をまとめることができます。
例:
この手順では、Start Drill計画を選び、すべてのデータベース手順(Autonomous DatabaseとMySQL HeatWave)を「Database – Group」というユーザー定義の計画グループにまとめて移動します。
- 待機DR保護グループに移動し、「Start Drill計画」を選択します。
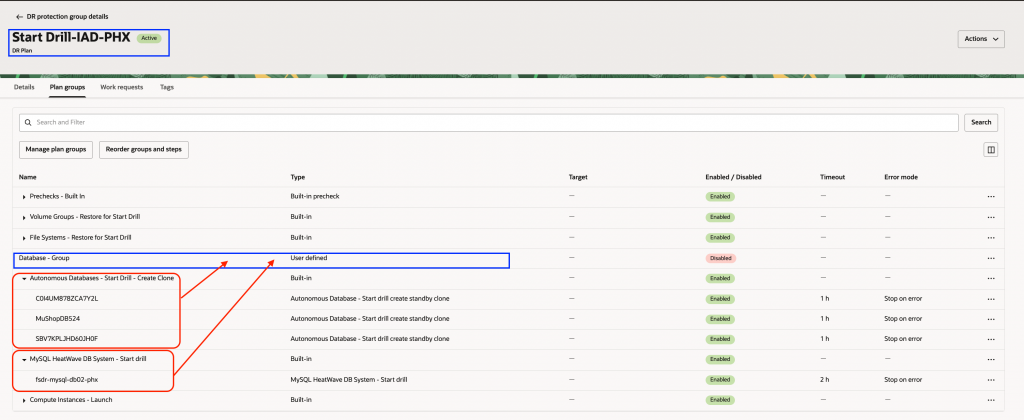
2.「計画グループ」をクリックし、「グループと手順の並び替え」を選択します。ここでは、既存のユーザー定義計画グループ「Database Group」を利用し、「Autonomous Databases – Start Drill – Create Clone」と「MySQL HeatWave DB System – Start drill」両方の手順を「Database – Group」に移動します。
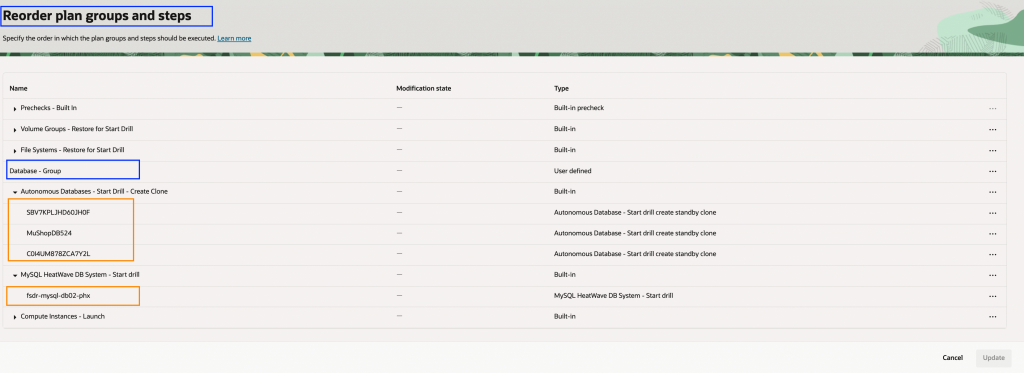
3. 移動したい手順が含まれている計画グループを展開し、三点リーダーのアクションメニューをクリックして「手順をグループに移動」を選択します。
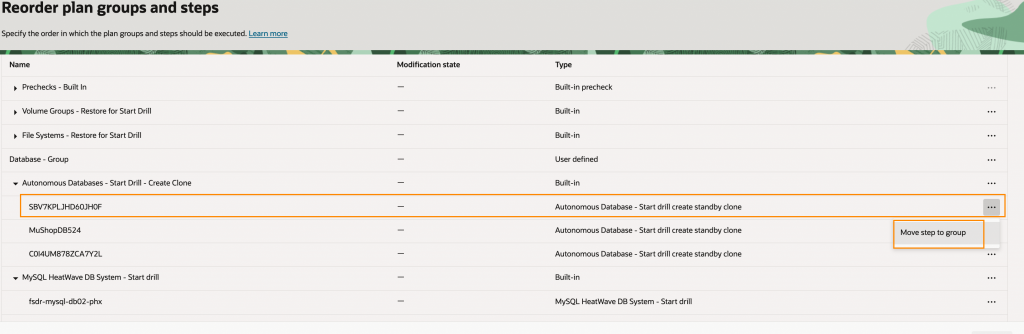
4. 移動先の計画グループを選択し、「更新」をクリックします。
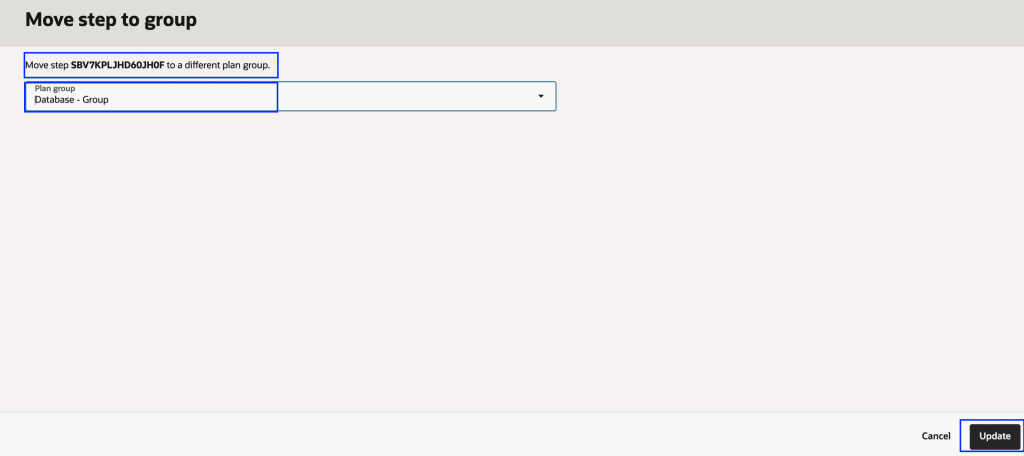
5. 他の手順についても同様に繰り返します。すべての手順を移動し終えると、各手順に「移動済み」と表示されます。
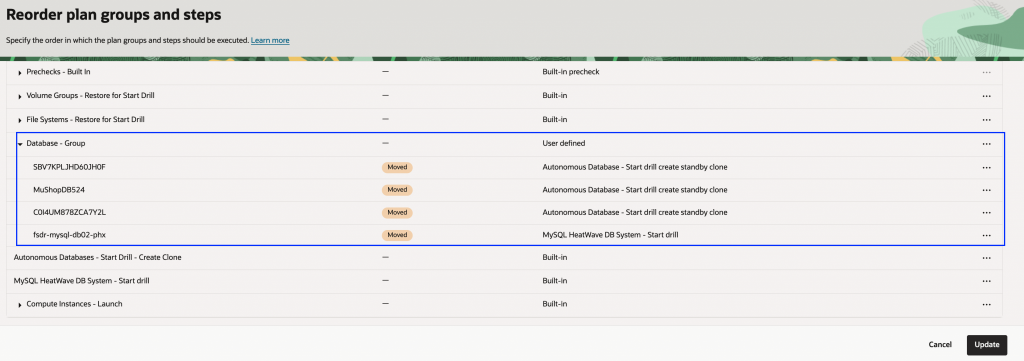
6. 確認後、「更新」をクリックして変更を公開します。
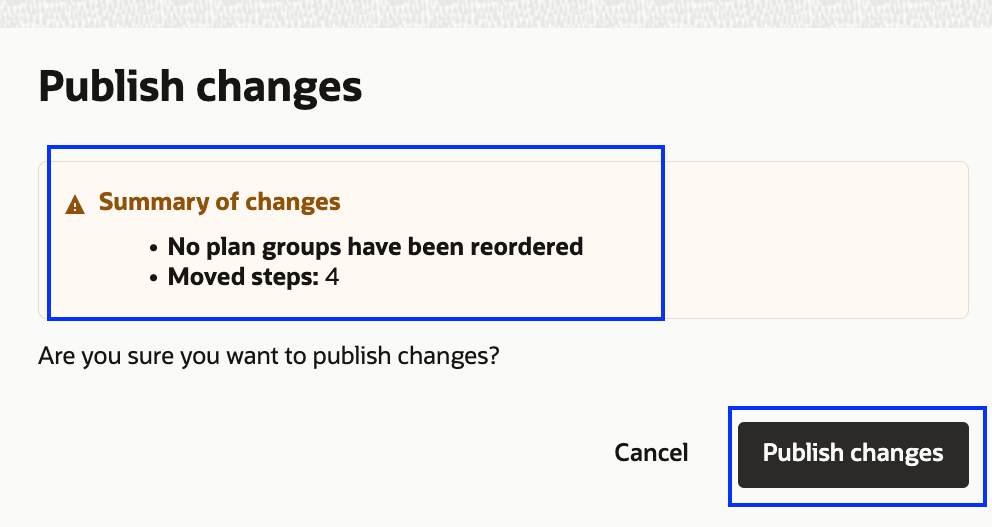
7. まとめられた計画グループを確認します。「Autonomous Databases – Start Drill – Create Clone」と「MySQL HeatWave DB System – Start drill」のすべての手順が「Database – Group」に移動されています。
重要な注意点
計画グループや手順を再編成する際は、正しい復旧の依存関係を維持する責任があります。ある手順が別の手順に依存している場合は、同じ計画グループに配置しないでください。同じグループ内の手順は並列実行されるため、同時に開始すると失敗の原因になります。前提となる手順は、必ず前の計画グループに配置しましょう。
詳細については、「グループとステップの順序変更」に関するドキュメントをご参照ください。
2. Kubernetesワークロード向けのOKEリソース修飾子
OCI Full Stack DRは、Oracle Kubernetes Engine(OKE)リソース用の修飾子(リソースモディファイア)をサポートするようになり、DRオペレーション中のKubernetesリソース構成をきめ細かくコントロールできるようになりました。
なぜ重要なのか
DR環境は、通常の本番環境とは異なる構成が求められることが多くあります。例えば、コスト最適化のためにレプリカ数を減らしたり、リソース制限を調整したり、監視用の環境固有ラベルを付与したり、ネットワーク設定を変更したりする必要があります。この機能がなければ、以下のような課題が発生します:
- 個別マニフェストの管理:DR専用のKubernetesマニフェストを別途作成・管理しなければならず、設定のずれ(コンフィグドリフト)や管理負担が増加。
- 手動での復旧時調整:復旧時に設定を手動で修正する必要があり、復旧時間(RTO)が延びたり、ヒューマンエラーのリスクが増加。
- 一律の復旧設定:本番と同じ構成でDRを実施すると、余分なコストが発生したり、リソースの割当が不適切になる場合がある。
- 複雑なスクリプト作成:自動化のためにカスタムスクリプトを書く必要があり、運用が複雑化し故障点も増加。
リソース修飾子を使えば、DR専用の構成を一度定義すれば、それを自動的かつ一貫して適用できるため、マニュアル作業やコンフィグドリフトを防ぎつつ、コンテナ化されたワークロードが必要な設定で確実に復旧できます。
リソース修飾子の仕組み
リソース修飾子を使うことで、Kubernetesリソースの構成(ラベルやアノテーション、レプリカ数、リソース制限など)を、復旧時に自動的にパッチ適用できるようになります。これにより、DR専用のマニフェストを別途作成する必要がありません。
修正ルールはConfigMap内に定義し、対象リソースと変更内容を標準のJSON Patch操作(add、remove、replace、test)で指定します。この機能は、OKEクラスタをDR保護グループに追加する際、「高度なオプション」から利用できます。
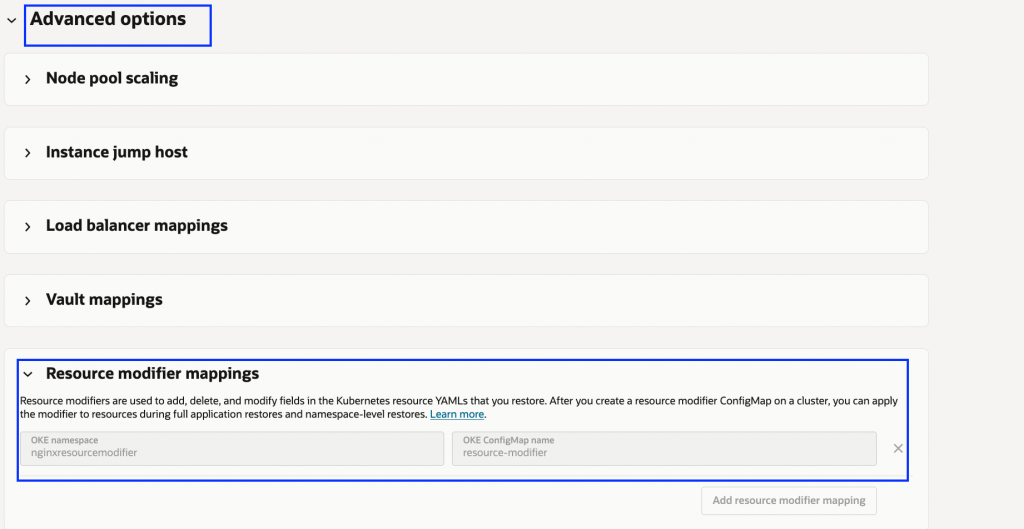
利用例
たとえば、本番環境で特定のラベルが設定されたnginxのデプロイメントがあるとします。DR時には、環境固有のラベルを追加したり、既存の値を変更したり、本番専用ラベルを削除したりする必要があるかもしれません。パッチルールを記載したリソース修飾子用のConfigMapを作成し、Full Stack DRのOKEメンバーの高度なプロパティに設定すれば、スイッチオーバーやフェイルオーバー時にこれらの修正が自動的に適用されます。
詳しくは、「ディザスタ・リカバリ保護グループへのOKEクラスタの追加」ドキュメントをご参照ください。
3. 可視性の向上:DR計画実行グループの手順サマリー
OCI Full Stack DRでは、DR計画の実行時に、すべての手順をまとめて確認できるサマリービューが提供されるようになりました。
なぜ重要なのか
多数の手順で構成されるディザスタリカバリ計画を管理するのは、特に本番復旧時などの緊急事態において負担が大きくなりがちです。従来はリカバリーワークフローの全体像を把握するために画面を何度も切り替える必要があり、以下のような課題がありました。
- 認知的負荷の増大:画面切り替えが頻発し、意思決定力が低下
- トラブルシューティングの遅れ:失敗や警告が発生した手順の特定が困難
- 振り返り作業の難しさ:レビューのためのナビゲーションが煩雑
- 一目で状況が把握しづらい:全体状況を瞬時に確認できない
サマリービューを使うことで、認知負荷が軽減され、迅速かつ的確な意思決定が可能になります。
DR計画実行サマリー
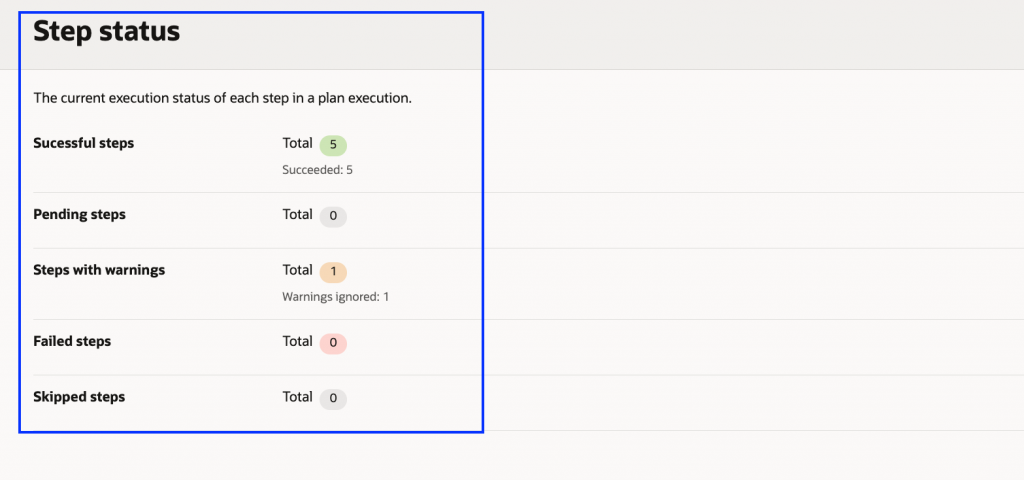
新しいサマリービューでは、以下のことが可能です:
- 状態を素早く把握:成功、保留、警告、失敗、スキップされた手順などを一目で確認できます
3. 可視性の向上:DR計画実行グループの手順サマリー
OCI Full Stack DRでは、DR計画の実行時に、すべての手順をまとめて確認できるサマリービューが提供されるようになりました。
なぜ重要なのか
多数の手順で構成されるディザスタリカバリ計画を管理するのは、特に本番復旧時などの緊急事態において負担が大きくなりがちです。従来はリカバリーワークフローの全体像を把握するために画面を何度も切り替える必要があり、以下のような課題がありました。
- 認知的負荷の増大:画面切り替えが頻発し、意思決定力が低下
- トラブルシューティングの遅れ:失敗や警告が発生した手順の特定が困難
- 振り返り作業の難しさ:レビューのためのナビゲーションが煩雑
- 一目で状況が把握しづらい:全体状況を瞬時に確認できない
サマリービューを使うことで、認知負荷が軽減され、迅速かつ的確な意思決定が可能になります。
DR計画実行サマリー
新しいサマリービューでは、以下のことが可能です:
- 状態を素早く把握:成功、保留、警告、失敗、スキップされた手順などを一目で確認できます
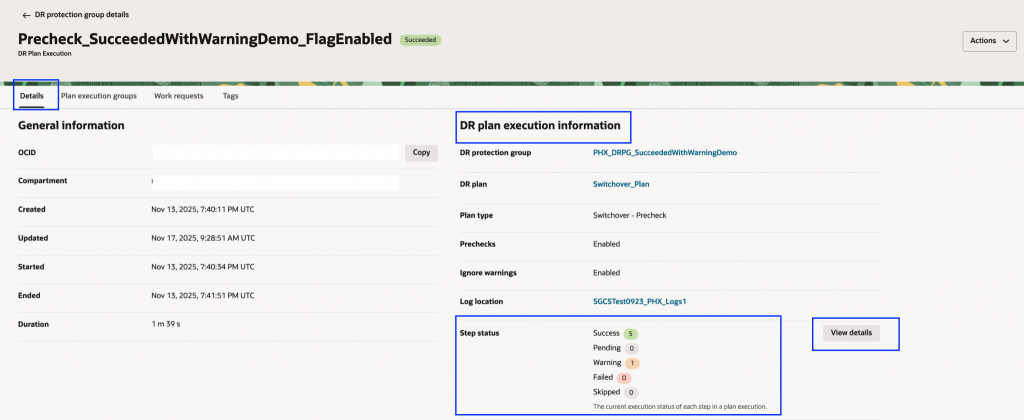
2. レビューやトラブルシューティングの簡素化:特に緊急時でも、計画の確認や問題対応を効率的に行うことができます。
詳しくは、「ディザスタ・リカバリ計画実行のモニター」ドキュメントをご参照ください。
4. DR計画実行:「警告付きで成功」の新しいステータス
OCI Full Stack DRでは、DR計画の実行結果に「警告付きで成功」(Succeeded with Warnings)という新しいステータスが追加されました。これにより、重大ではない問題が発生した場合でも、計画自体は正常に完了したことを示せるようになりました。
なぜ重要なのか
ディザスタリカバリ運用では、完全な失敗ではないものの、完全な成功とも言えない状況がよく発生します。従来は「成功」か「失敗」かの二択しかなく、次のような課題がありました。
- 誤った失敗判定:本来の目的は達成できているのに、軽微な問題により復旧処理が停止する
- RTO(復旧時間)の増加:重大でない問題の調査・対応により処理が遅れる
- 不要な手作業:チームが警告対応の要否を判断しなければならない
- 経過の記録不足:警告が出たが全体として復旧できた状況を残せない
「警告付きで成功」ステータスは、例えば次のような実際によくある状況を反映できます:
- 下流のサービスがエラーではなく警告を返す場合
- 手順が部分的にしか実行されないが、主要な目標は達成されている場合
- レガシー対応や互換性の都合から、リソースがデフォルトオプションで復旧する場合
- 軽度の設定不一致があるが、復旧自体には影響がない場合
この柔軟性により、軽微な問題で復旧処理が止まることを防ぎ、より高いレジリエンスと効率的なDR運用を実現します。
重要: 現時点でこの機能強化は事前チェック(Pre-check)実行時のみ利用可能です。
例:古いComputeインスタンスの起動オプションへの対応
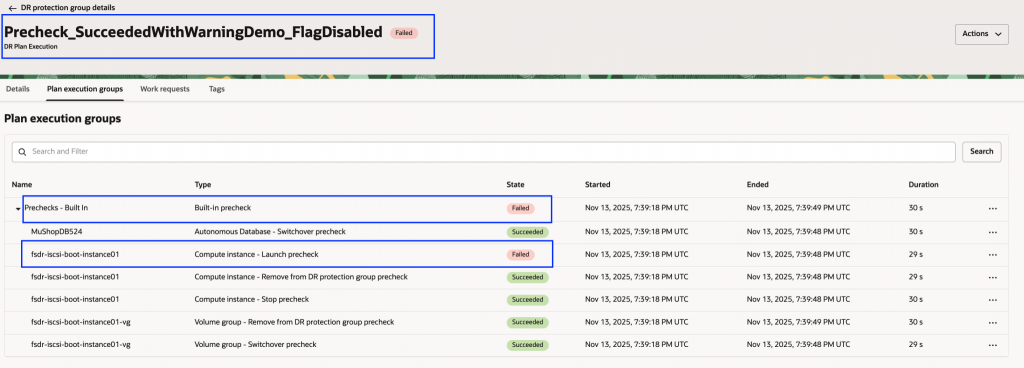
たとえば、現在はサポートされていない起動オプションで作成したComputeインスタンスがある場合を考えます。これまでは、事前チェックが失敗し、リカバリー自体が停止していました。今後は次のような対応が可能です。
- デフォルト動作(警告を無視 = false):
事前チェックは未サポートの属性について明確なエラーメッセージを表示し、2つの対処方法を案内します。
a. ‘警告を無視する’ オプションを有効にして再実行する
b. 事前チェック手順を無効にする
どちらの方法でも、待機インスタンスはデフォルト設定で起動できます。
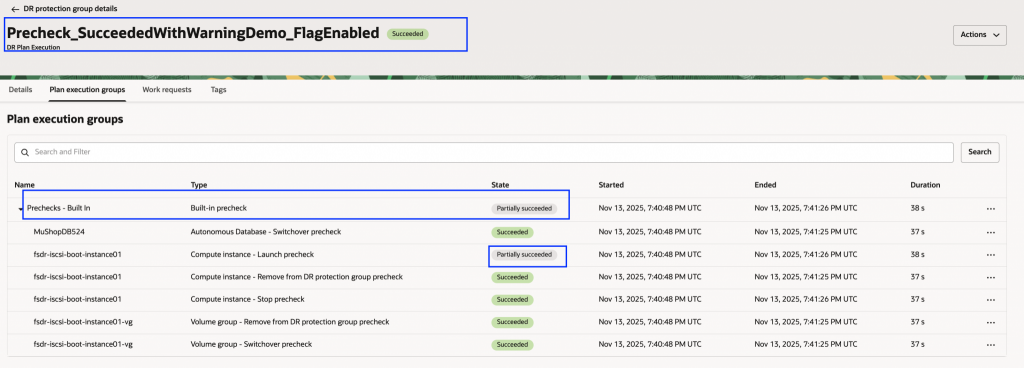
2. 警告を無視する = true の場合:
事前チェックは警告付きで成功となり、未サポートの属性がログに記録されます。そのうえで、待機インスタンスは自動的にデフォルト設定で起動されます。
「警告付きで成功」というステータスを導入することで、OCI Full Stack DRは運用面での柔軟性を高めています。これにより、重大ではない問題を認識・対応しつつ、全体の復旧目標を損なうことなく、より効果的にDRプロセスを管理できるようになります。
詳しくは、「ディザスタ・リカバリ計画実行の事前チェック」ドキュメントをご参照ください。
まとめ
これらの機能強化により、各組織は自社の運用要件に合ったディザスタリカバリ戦略を柔軟に設計できるようになりました。より高い制御性、自動化、可視性を提供することで、OCI Full Stack DRは迅速で信頼性の高い復旧プロセスを実現し、ダウンタイムを最小限に抑え、事業継続性を確保します。
また、第1部でご紹介した政府クラウド対応、Oracle Integrationのネイティブ保護、自動化機能の強化とあわせて、今回のリリースでは、重要な場面での制御性や可視性の向上、手動作業の削減も実現しています。
さらに詳しく知りたい方へ
OCI Full Stack Disaster Recoveryをまだご覧になったことがない場合は、ぜひOracle Cloud Infrastructureのアカウント担当者にデモの実施をお申し付けください。ドキュメント、価格情報、導入事例、動画、チュートリアル、ハンズオンラボなどの詳細は、Full Stack Disaster Recoveryの公式ページをご覧ください。
追加リソース:
