※ 本記事は、Karan Singhによる”Big Data service major release“を翻訳したものです。
2022年6月21日
Oracle Big Data Serviceには、お客様が求める複数の主要な機能を提供するメジャー・リリースがありました。Oracle Distribution of Hadoopを使用したBig Dataサービス・バージョン3.0.7(以降)では、次の新機能が提供されるようになりました。
自動スケーリング
Big Dataの自動スケーリングでは、自動スケーリング・ルールを作成して、CPU使用率メトリックを使用してクラスタを水平または垂直に自動スケーリングできます。自動スケーリングでは、必要なときに、より多くのリソースとパフォーマンスを自動的に取得し、必要のないときに消費量を自動的に削減してコストを最適化します。自動スケーリングは、標準シェイプとAMD Flexシェイプの両方で機能します。
垂直自動スケーリングでは、指定したルールに基づいてクラスタ内のノードのシェイプを変更できます。
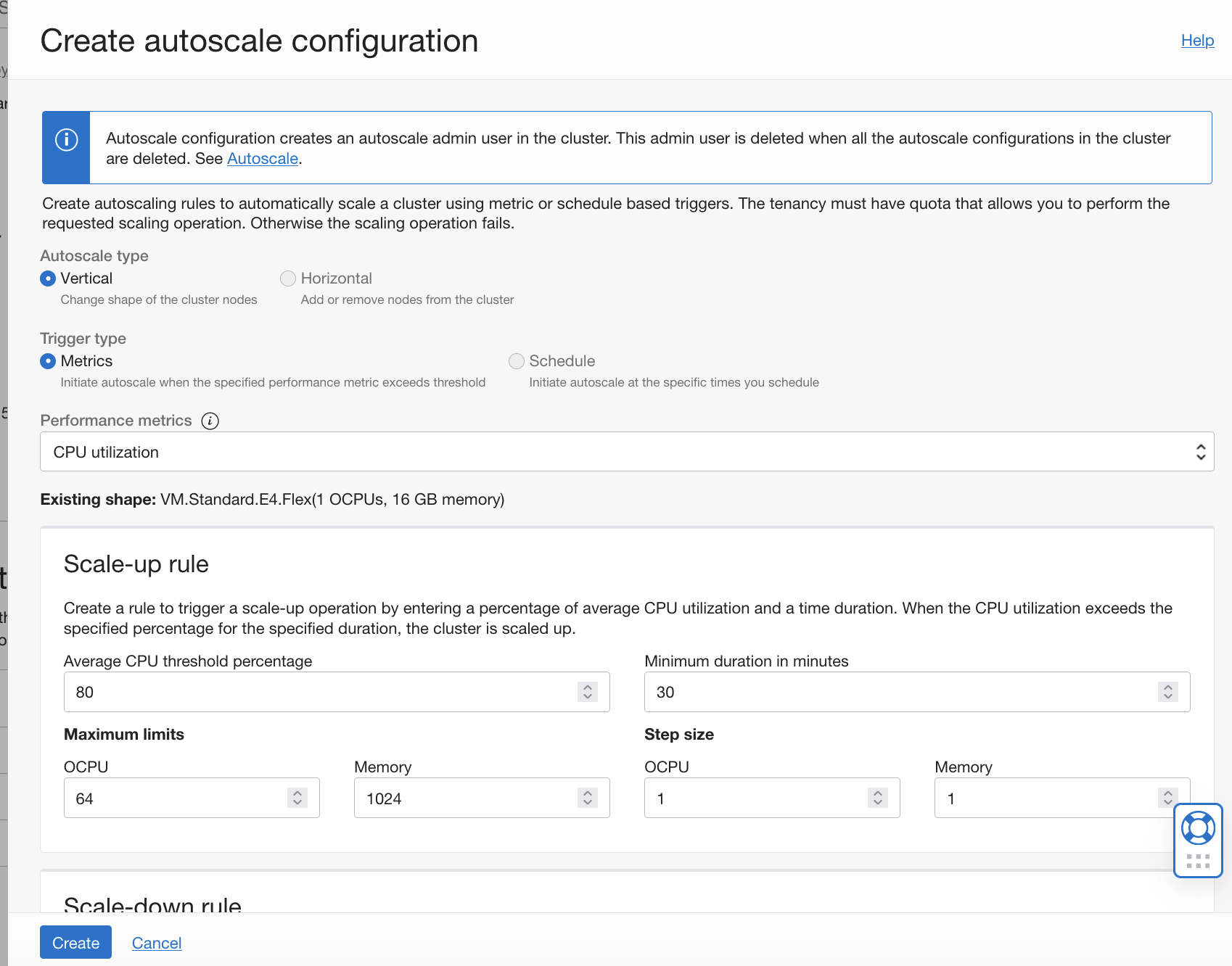
水平自動スケーリングでは、しきい値に達すると、構成されたルールに応じて、クラスタ内のワーカー・ノードが自動的に追加(スケール・アウト)または削除(スケール・イン)されます。
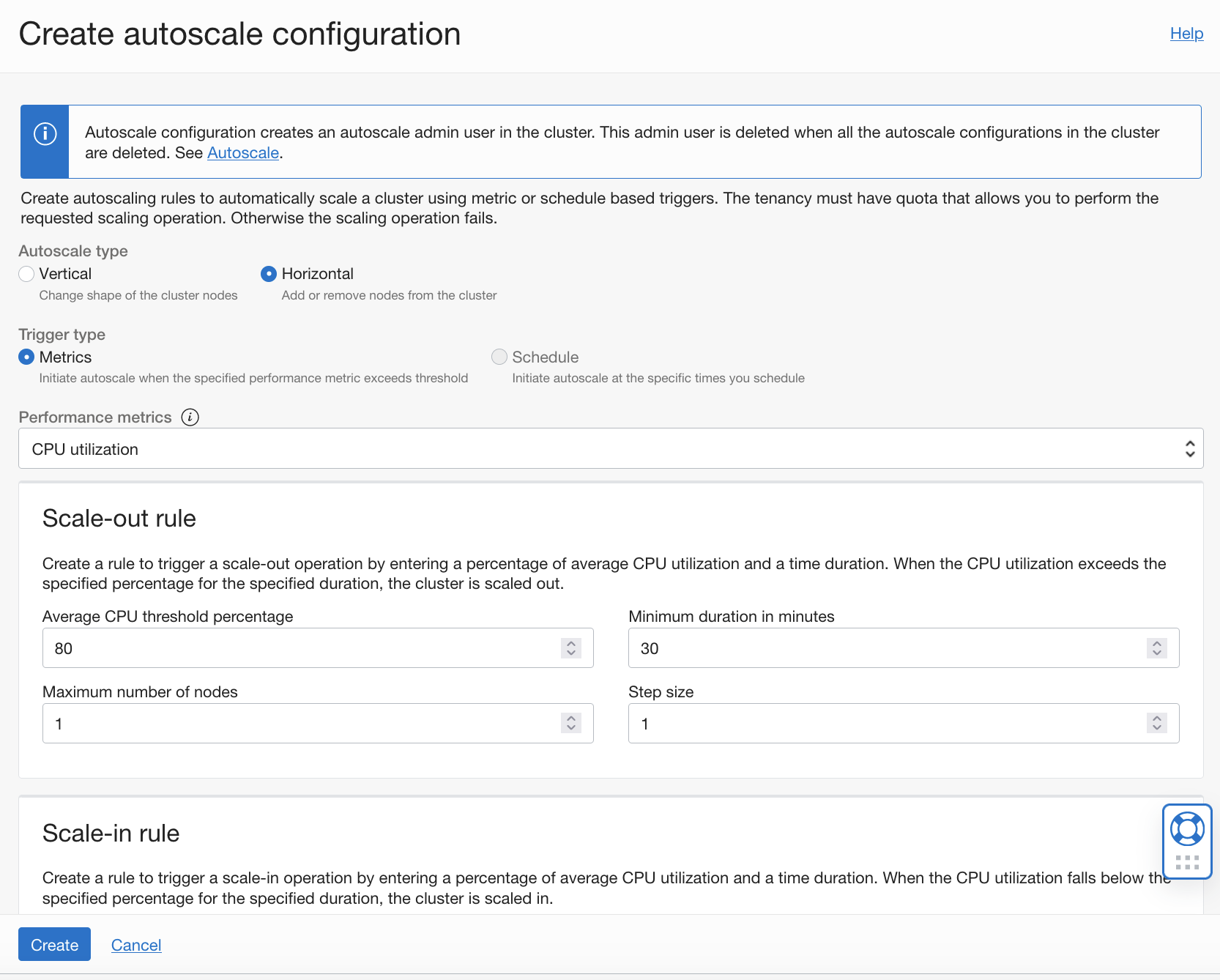
詳細は、「クラスタの自動スケーリング」を参照してください。
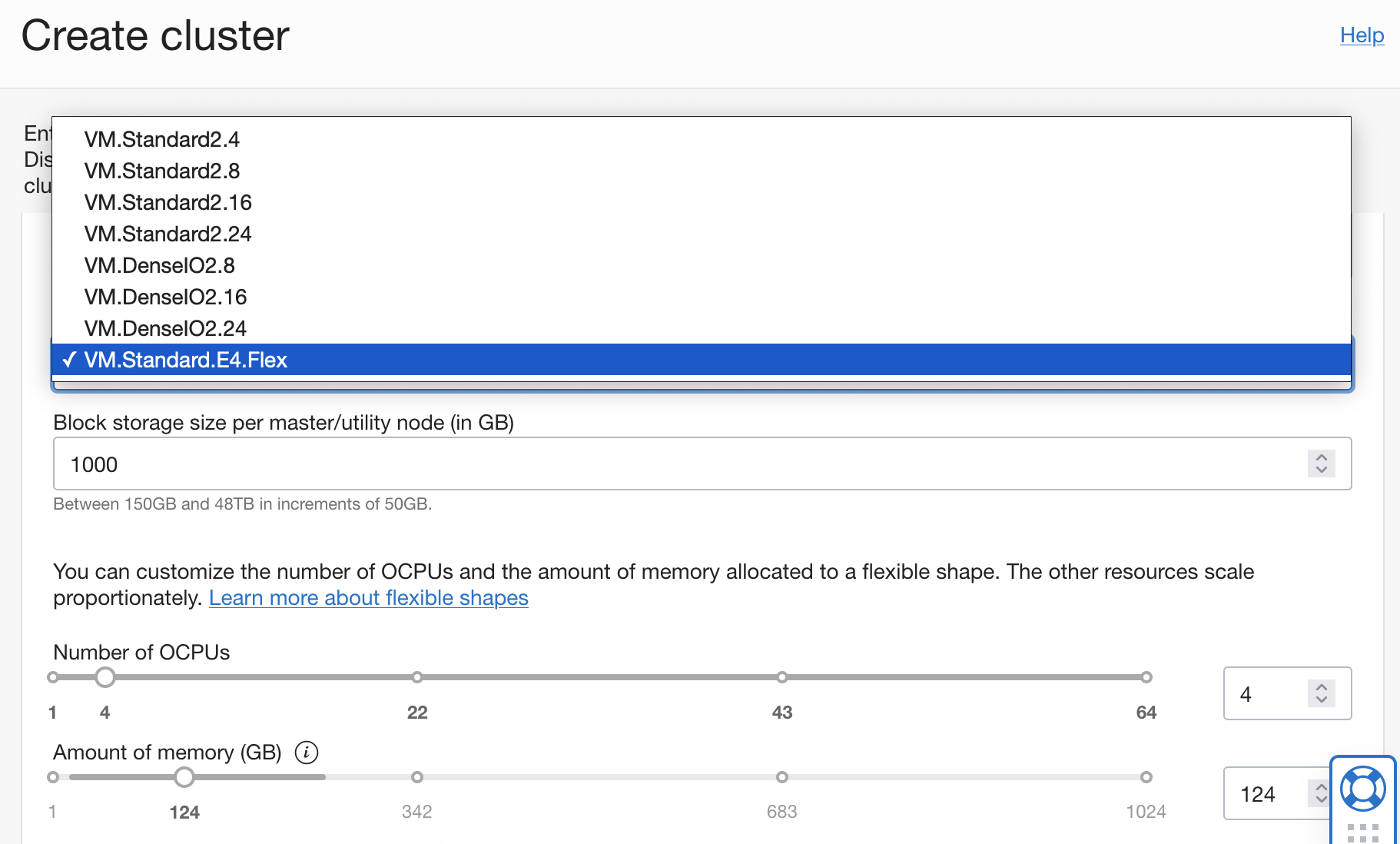
AMD Flexシェイプ
Big DataはVM.Standard.E4.Flex(AMD)シェイプをサポートするようになりました。このシェイプでBig Dataクラスタを作成する場合、ワークロードに一致するために必要なOCPUの数およびメモリーの量を選択します。これにより、パフォーマンスを最適化し、コストを最小限に抑えることができます。
Presto (Trino)
Trinoは、Big Data Hadoop Distributed File System(HDFS)とOracle Cloud Infrastructure(OCI)Object Storageの大きなデータ・セットを問い合せるために設計された分散SQL問合せエンジンです。PrestoはBig Dataクラスタで事前構成されており、Ambariで管理できます。
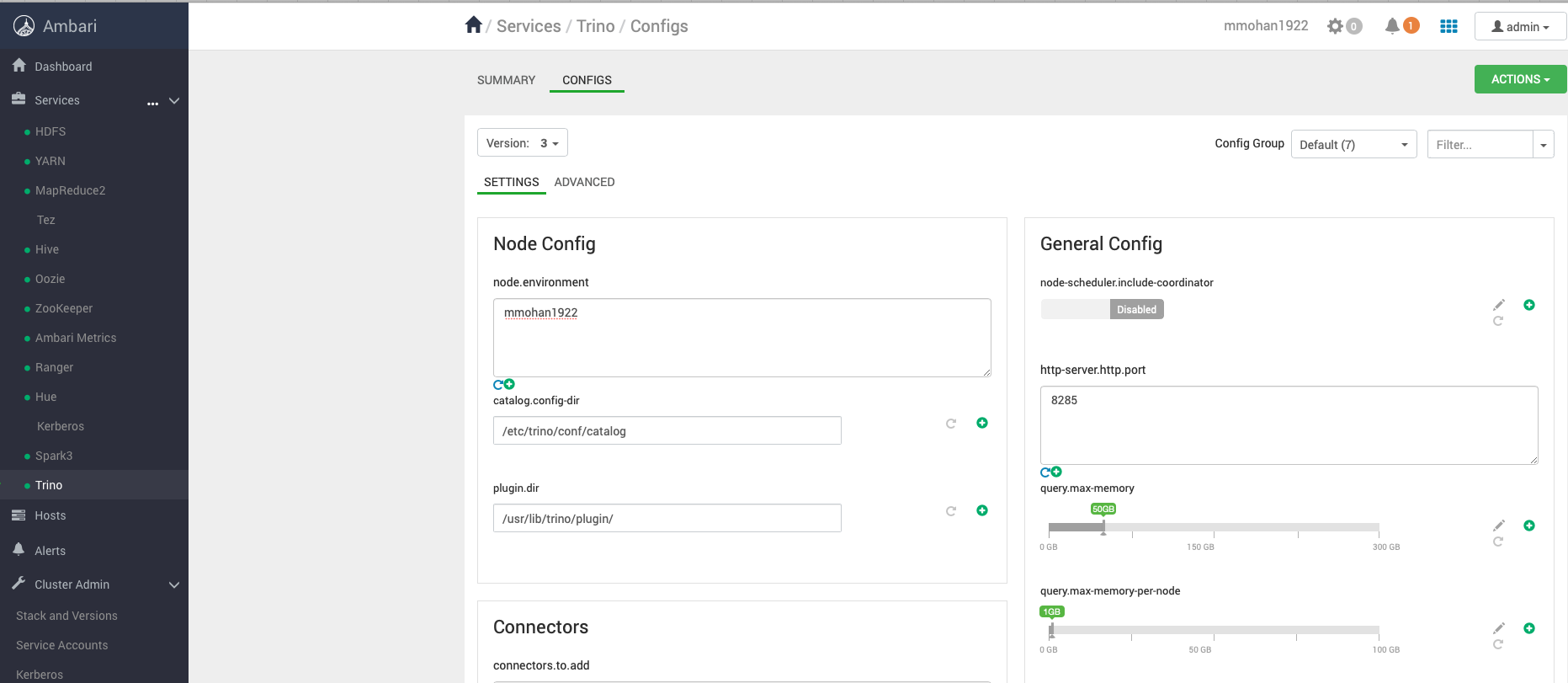
詳細は、「クラスタの管理」を参照してください。
JupyterHub
JupyterHubは一般的なオープン・ソース・プロジェクトで、複数のユーザーが一緒に管理される共有リソースに独自のJupyterノートブックを提供することで、連携できます。Big Dataは、JupyterHubで事前構成されています。
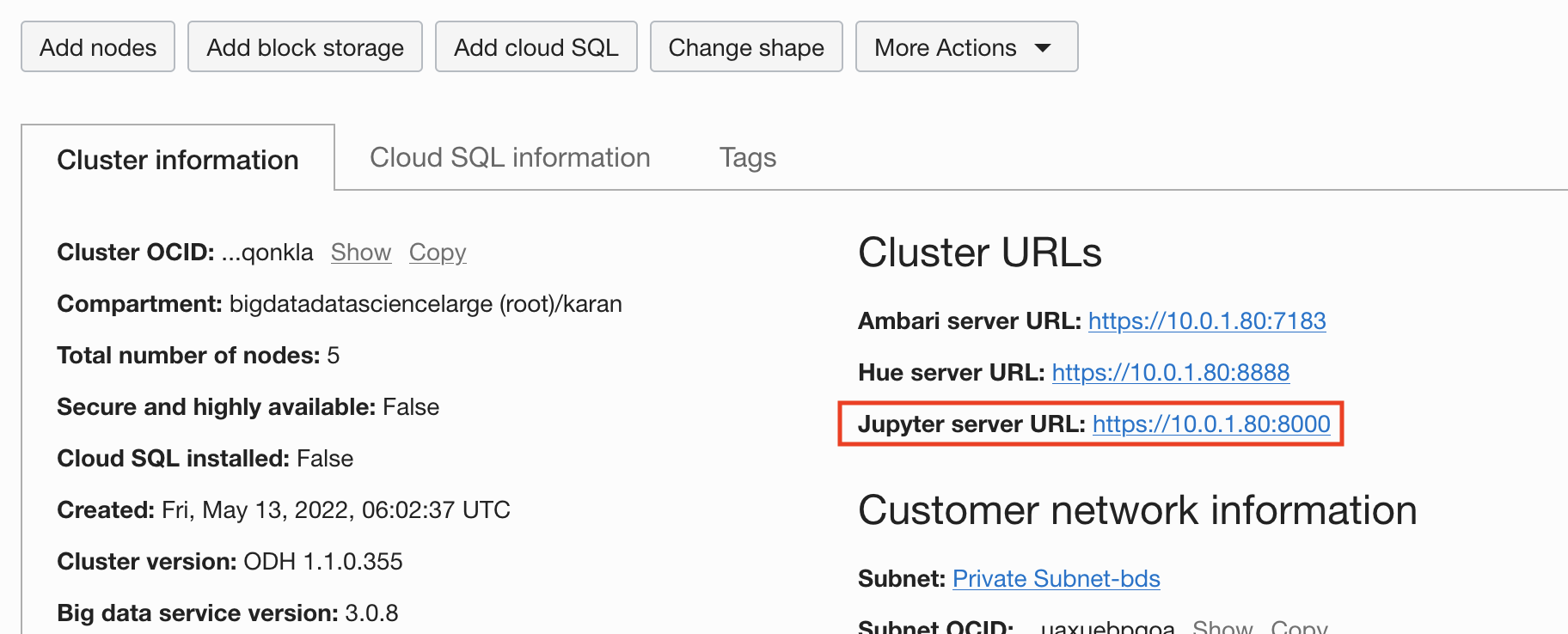
Oracle Cloud Consoleで提供されているURLからJupyterhubにアクセスし、ノートブック・サーバーをデプロイしてページを起動できます。
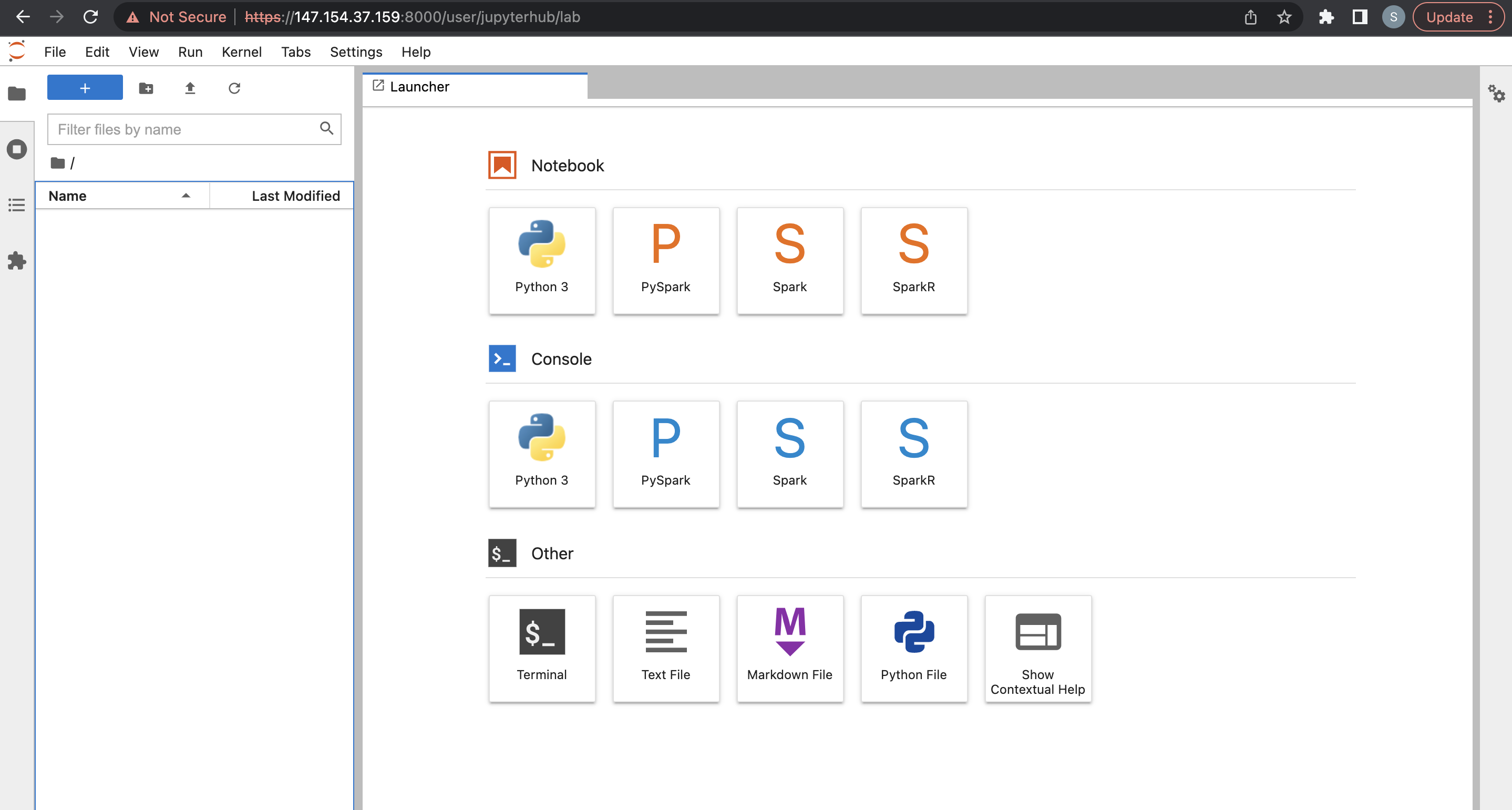
そこから、Python、PySpark、Spark、SparkRなど、デフォルトで使用可能な複数のカーネルの1つをデプロイできます。
詳細については、「Jupyterhubの使用」を参照してください。
ブートストラップ・スクリプト
ブートストラップ・スクリプトにより、Big Dataによる簡単な構成と自動化が可能になります。クラスタの作成後、クラスタのシェイプが変更されたとき、またはクラスタからノードを追加または削除するときに、すべてのクラスタ・ノードでブートストラップ・スクリプトを実行できます。このスクリプトを使用して、クラスタ内のカスタム・コンポーネントをインストール、構成および管理できます。
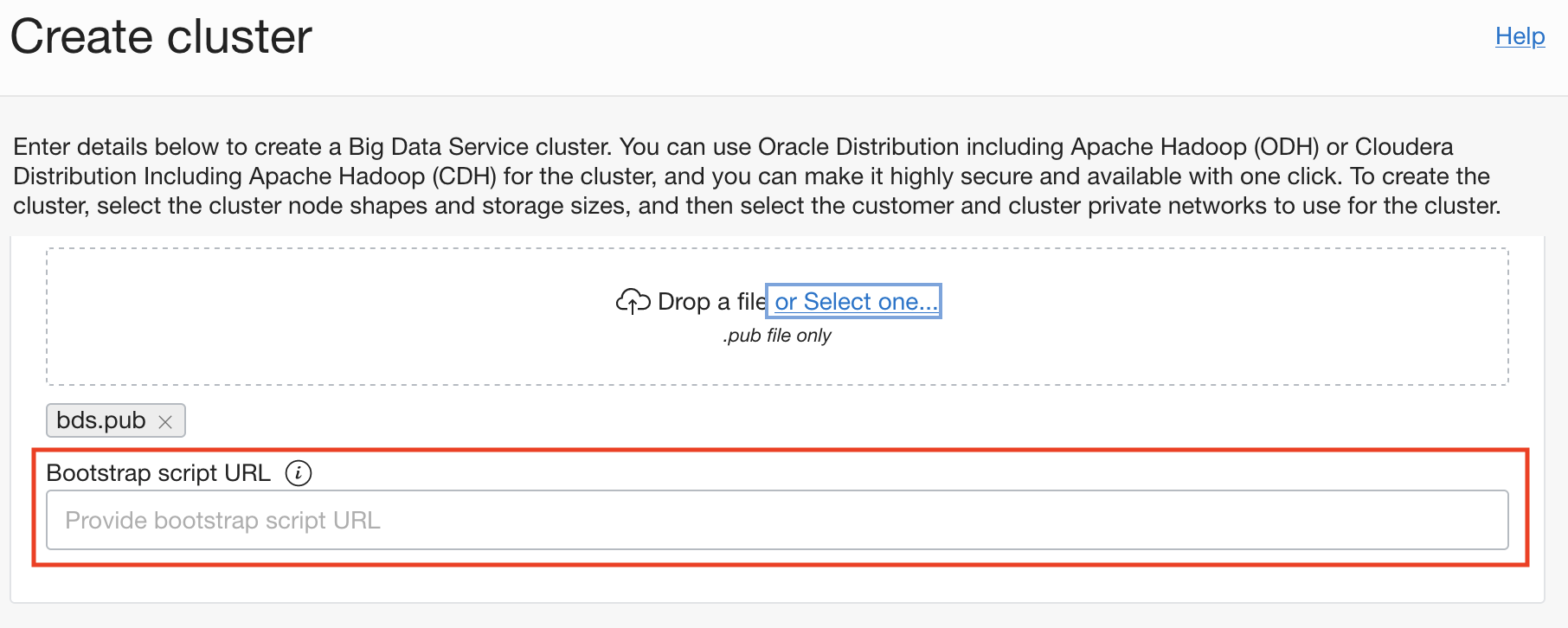
ブートストラップ・スクリプトは、クラスタの作成後に更新することもできます。
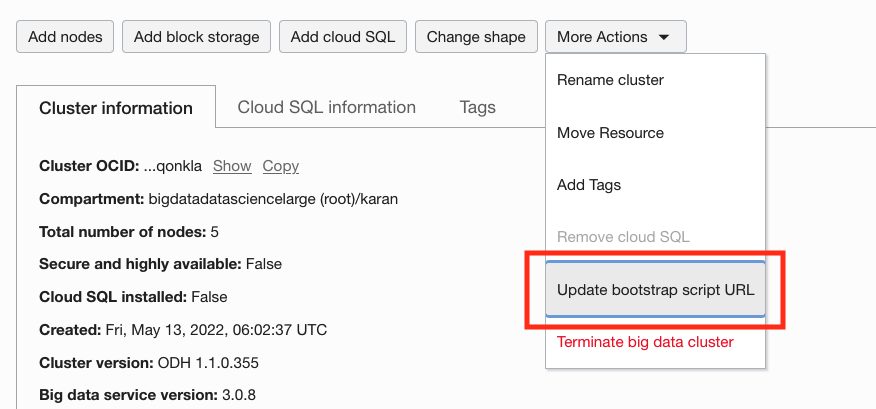
詳細は、「ブートストラップ・スクリプトURLの更新」を参照してください。
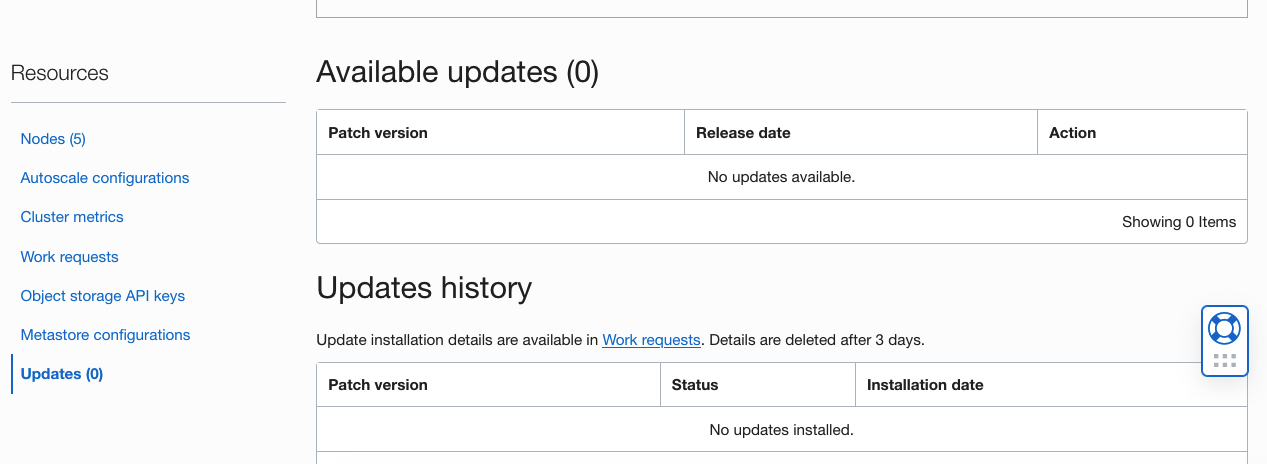
パッチ管理
Big Data Consoleページには、「リソース」列に新しい「更新」リンクがあります。このリンクをクリックして、クラスタで使用可能な更新およびインストールされた更新を表示します。このリンクを使用すると、Big Dataパッチを簡単に管理および適用し、以前に適用されたパッチの履歴を確認できます。
カスタムKerberosレルム名
Big Dataクラスタの作成時に、独自のカスタムKerberosレルム名を指定できるようになりました。
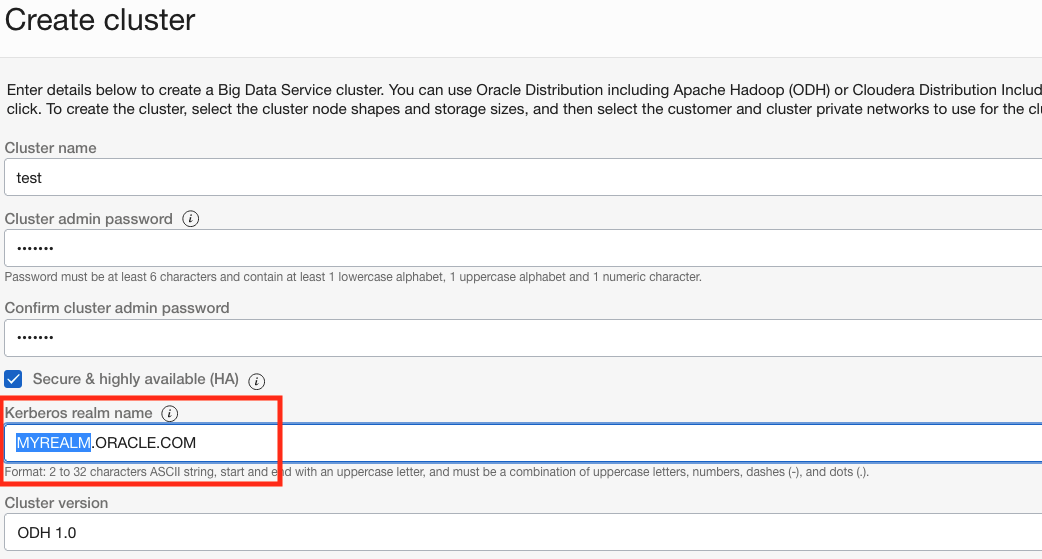
企業のお客様は、独自の信頼できるレルムを使用し、Big Dataを既存のKerberosとより簡単に統合できるようになりました。
詳細は、「クラスタの作成」を参照してください。
その他の機能
このリリースでは、次の機能の一般的な可用性が提供されます。
-
コンピュート専用ワーカー・ノードをクラスタに追加します。
-
クラスタからワーカー・ノードを削除します。
-
Hueはクラスタに事前構成されています。
-
Livyはクラスタに事前構成されています。
まとめ
このBig Dataリリースのすべての機能は、あらゆる規模の企業が、Big Dataの管理対象オープン・ソース・ソフトウェアのパワーをより簡単かつ効率的に使用して、データ・レイク、抽出、変換およびロード(ETL)、問合せ、処理および機械学習プラットフォームを構築するのに役立ちます。今後のブログでは、これらの新機能について詳しく説明します。
