※これはFirst Principles: Optimizing PostgreSQL for the cloudの翻訳です
Oracleでは、OCI Exadata Database Service、OCI MySQL Database Service、最近 First Principles シリーズで取り上げたクラウドスケールのサービスである MySQL Heatwave Database サービスなど、ワールドクラスのデータベースシステムとサービスを構築しています。 PostgreSQL は人気のあるオープンソースのデータベースであり、私たちの目標は、OCI の顧客がクラウドのワークロードを実行するためのデータベースを選択できるようにすることです。 最近発表された OCI Database for PostgreSQL では、Oracle のデータベース技術の専門知識を活用して、クラウドスケールのワールドクラスの OCI Database with PostgreSQLを構築しました。 このブログ投稿では、Oracle がどのようにして PostgreSQL をクラウドデータベースのサービスに適応させたかをわかりやすく説明します。
PostgreSQL は、ACIDプロパティとも呼ばれる原子性、一貫性、分離性、耐久性を提供する人気のあるデータベース ソフトウェアです。 Oracle Cloud Infrastructure (OCI) では、優れたクラウド・データベース体験を実現するものについて独自の意見を持っています。 顧客はデータベースのインスタンスをオンデマンドで追加・削除でき、コンピューティングとストレージを互いに独立して拡張できる必要があり、データ損失のリスクなしにクラス最高のプライスパフォーマンスを提供するように設計されている必要があります。 これらは、クラウドベースのデータベースのサービスの基本前提です。 OCI PostgreSQL サービスに必要な主要な要素は次のとおりです。
- 目標復旧時点 (RPO) ゼロとデータ損失ゼロ: インフラストラクチャやシステムに障害が発生した場合でも、顧客はデータベースに保存されているデータを失うことはありません。
- 一貫した高いパフォーマンス: データベースのパフォーマンスは、レプリケーションなどのバックエンドシステムのタスクの影響を受けません。
- 水平読み取りスケーリング: 書き込みパフォーマンスに影響を与えることなく、読み取り容量を簡単にスケールアップ・スケールダウンできます。
- プライスパフォーマンス: より低コストでより高速にワークロードを実行できます。
- 完全な自動化: ソフトウェアのパッチ適用、ヘルスモニタリング、データベースのフェイルオーバー、バックアップ、ストレージの拡張などのタスクに関して運用上のオーバーヘッドを節約できます。
バニラPostgreSQL
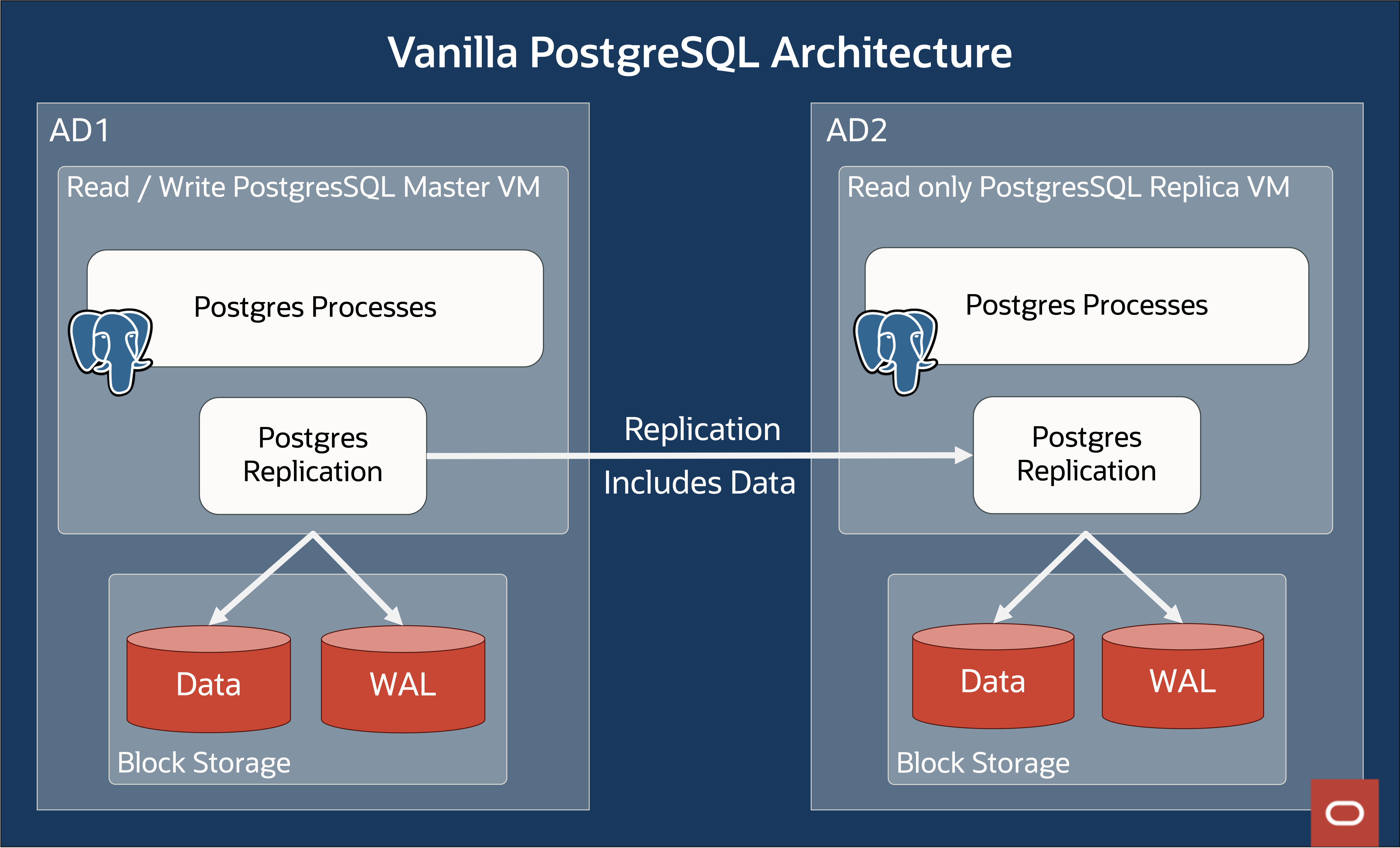
図1:ユーザー管理のPostgreSQLアーキテクチャ
以降、オープンソースの PostgreSQL を「バニラPostgreSQL」と呼びます。 バニラ PostgreSQL は強力で人気のあるデータベースですが、ユーザーが直面するいくつかの課題を次に示します。
- プライマリ・フェイルオーバー中のデータ損失 – non-Zero RPO: 図 1 に示すように、通常、可用性ドメイン(AD)全体でデータベース・インスタンスをレプリケートします。 このレプリケーションは、AD1 のプライマリ・データベースから AD2 の「レプリカ」に非同期的に実行されます。 レプリカ・データベースはプライマリ・データベースよりも遅れる可能性があります。 プライマリに障害が発生し、レプリカが新しいプライマリに昇格すると、遅延によりデータが失われる可能性があります。 データ損失の量は、プロモートされたレプリカが古いプライマリからどれだけ遅れていたかによって決まります。 バニラ PostgreSQL におけるこの問題の解決策は、同期レプリケーション機能ですが、パフォーマンスのオーバーヘッドが大きいため、あまり一般的ではありません。
- 手動での昇格の複雑さと管理性: 高可用性を実現するために、異なる可用性ドメインにレプリカを設定できますが、スタンバイ・レプリカをプライマリに昇格させるのは手動で複雑なプロセスです。 データ損失を最小限に抑えるために、昇格する新しい候補を慎重に選択する必要があります。同様に、古いプライマリをクラスタに再度追加するには、より多くの手動での手順が必要です。 たとえば、古いプライマリには、ローカルでコミットされた過剰なトランザクションが存在する可能性があり、クラスタに再参加する前に最初に、pg_rewind などのツールを使用してパージする必要があります。
- 高価で時間のかかるリードレプリカの作成: バニラ PostgreSQL では、新しいレプリカを作成するには、プライマリ上のデータのスナップショットを取得し、プライマリに追いつく必要があります。 テラバイト単位の大きなデータベースの場合、これは高コストで時間のかかる操作です。 アプリケーションからの読み取り要求のバーストを処理できるようにするには、データベースのリソースをオーバープロビジョニングする必要があります。 各レプリカにはデータベースの完全なコピーが必要なため、複数のレプリカを実行するとストレージのコストが高額になる可能性があります。
OCI Database with PostgreSQL はこれらの課題を解決しました。
OCI Database with PostgreSQL – ハイレベルのアーキテクチャ
次に、OCI Database with PostgreSQLのアップグレードされたアーキテクチャが上記の課題をどのように解決し、OCI での PostgreSQL の実行と管理を非常に簡単にするかを見ていきます。 OCI Database with PostgreSQL では、レプリケーションと耐久性の問題を新しいDatabase Optimized Storage (DbOS) レイヤーに押し込みます。このレイヤーは、高スケール、高可用性、高パフォーマンスのデータベース・サービスを実現するために専用に構築されました。 DbOS は、3 つの可用性ドメイン(AD)リージョン内の複数の可用性ドメイン間でデータブロックがレプリケートされ、また耐久性の高いネットワーク接続ストレージを提供されます。単一 ADのリージョンでは、データは複数のフォールトドメイン(FD)間でレプリケートされます。 クラスタ内のすべての PostgreSQLノードは、同じネットワーク接続ストレージにアクセスします。 各スタンバイレプリカは、データベースの独自のコピーを維持する必要がなくなりました。 プライマリ・インスタンスは共有ストレージに書き込みますが、スタンバイレプリカのインスタンスは同じ共有ストレージから読み取り、ユーザークエリに対応します。
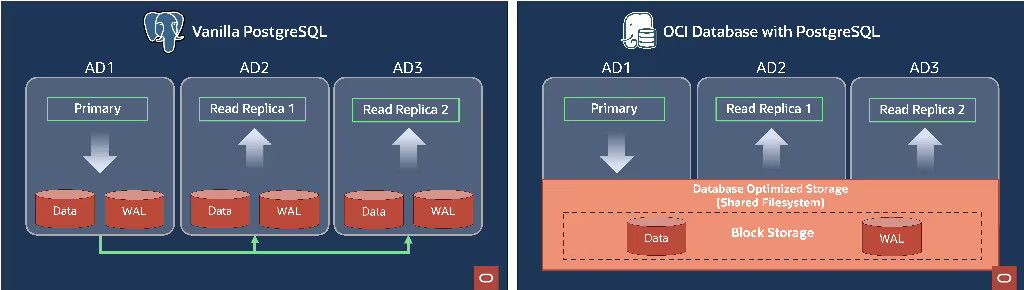
図2:バニラPostgreSQL vs OCI Database with PostgreSQL
OCI Database with PostgreSQL で使用されるこの新しい共有ストレージ・アーキテクチャは、安全性、柔軟性、効率性、パフォーマンスの面で多くの利点を提供します。OCI Database with PostgreSQLは、全く異なるストレージ・アーキテクチャを基盤としていますが、通常の PostgreSQL と完全な互換性があります。 そのため、既存の PostgreSQL ワークロードをOCI Database with PostgreSQLにLift & Shiftしたり、簡単に元に戻すことができます。 DbOS は、組み込み済みのレプリケーションなどの高性能 OCI Block Storage 機能を活用する共有ファイル システムです。
データベース最適化ストレージ (DbOS) の利点
新たに組み込まれたDbOS レイヤーが PostgreSQL ユーザーにとって非常に強力な利点となる理由を詳しく説明しましょう:
- 耐久性 (zero – RPO): DbOS は、マルチ可用性ドメイン・リージョン内の複数の可用性ドメイン間でデータをレプリケートし、可用性ドメイン全体の損失にも耐えることができます。 DbOS は、Quorumベースのレプリケーションを使用して、バックグラウンドでデータブロックを複製します。 プライマリノードに障害が発生した場合、DB はDbOS を使用するレプリケートされた別の DBノードにフェイルオーバーでき、この新しく昇格されたプライマリ PostgreSQLインスタンスはデータを損失することなく引き継ぐことができます。 古いプライマリで以前にコミットされたすべてのトランザクションは、新しいプライマリに存在します。 DbOS レイヤーがレプリケーションを実行するため、耐久性を確保するためだけに複数のレプリカインスタンスを実行する必要はありません。 たとえば、レプリカを使用せずに単一ノードの OCI Database with PostgreSQLのインスタンスで実行しても、耐久性を犠牲にすることはできません。 この単一ノード設定でも RPO がゼロであることが保証されます。
- 高可用性 (99.99%): OCI Database with PostgreSQL を使用すると、プライマリをクラスタ内の別のレプリカに数分で自動的にフェイルオーバーできます。 目標復旧時間は数分しかかからないため、プライマリ・フェイルオーバーは迅速であり、アプリケーションに対してほぼ透過的です。フェイルオーバーを透過的に有効にするために、プライマリ・エンドポイントは、新しいプライマリに自動的に移動されるフローティング IP アドレスとして設定されます。 アプリケーションは構成を変更することなく、フェイルオーバー後に新しいプライマリへのデータベース接続を自動的に再確立します。 通常の PostgreSQL とは異なり、プライマリ・フェールオーバーの開始中にレプリケーションの遅延やデータ損失を心配する必要はありません。 データ損失を最小限に抑えるために特定のレプリカを手動で選択する必要はありません。 クラスタ内のすべてのインスタンスは同じストレージを共有するため、フェイルオーバー時に新しいプライマリではデータ損失ゼロが保証されます。
- 弾力性: データベース・ストレージはすべてのノードで共有されるため、ユーザーのクエリ・ワークロードの需要を満たすために、レプリカを迅速に作成・削除できます。 通常の PostgreSQL とは異なり、新しいスタンバイ PostgreSQL インスタンスを起動するために、プライマリでデータのスナップショットを取得し、それをレプリカノードにコピーする必要はありません。 そのため、OCI Database with PostgreSQLでコンピューティング・インスタンスを起動するのと同じくらい早くスタンバイレプリカを作成できます。
- リードレプリカの水平スケーリング: レプリカノードはOCI Database with PostgreSQL内でデータベースストレージを共有するため、データベース・クラスタ内のレプリカの数に関係なく、データベースのコピーを 1 つだけ維持する必要があります。 その結果、OCI Database with PostgreSQL は、クラウドで通常の PostgreSQL を実行する場合と比較して、ストレージコストを大幅に節約できます。 さらに、OCI の PostgreSQL サービスは、コストを最小限に抑えるための自動スケーリングを備えたデータに対する従量課金制の価格モデルを提供します。
- 低いレプリカラグ: レプリケーションラグは、標準的な PostgreSQL リードレプリカ設定の大きな課題です。 レプリカはプライマリによって行われたすべての変更を再生して永続化する必要があるため、特にネットワークを分割する場合に遅れが発生する傾向があります。 共有ストレージを使用すると、レプリカの作業が大幅に減ります。 キャッシュ内のページに変更を適用するだけでよく、これらの変更を永続化する必要はありません。 このアーキテクチャでは、レプリケーションの遅延は通常ミリ秒単位であるため、読み取りクエリをほぼリアルタイムで実行・完了できます。
- 効率的なレプリケーション: OCI Database with PostgreSQLは、ストレージ層でレプリケーションを実行します。 したがって、プライマリ・インスタンスは、ログ先行書き込み (WAL) レコードをすべてのレプリカに物理的に送信する必要はありません。 代わりに、新しい変更をレプリカに通知し、個々のレプリカが共有ストレージから最新の WAL レコードを直接読み取ります。 これにより、プライマリの負荷が最小限に抑えられ、より多くのレプリカに効果的に拡張できます。
私たちの実験では、OCI Database with PostgreSQLの AD 全体の組み込みレプリケーションは、通常の PostgreSQL の同期レプリケーションの 2 倍以上高速でした。
DbFS: シングルライター ・マルチリーダー ・ファイルシステム
Linux 上のバニラ PostgreSQL は、カーネルによってサポートされる標準ファイルシステム (通常は ext4 または xfs) を使用します。 これらのファイルシステムは、クラスタ内のすべてのノードが同じストレージ・ファイルシステムを共有する OCI Database with PostgreSQLなどの分散セットアップ向けに設計されていません。 図 3 に示すように、OCI Database with PostgreSQLで使用されるファイルシステム実装の重要な側面をいくつか確認してみましょう。
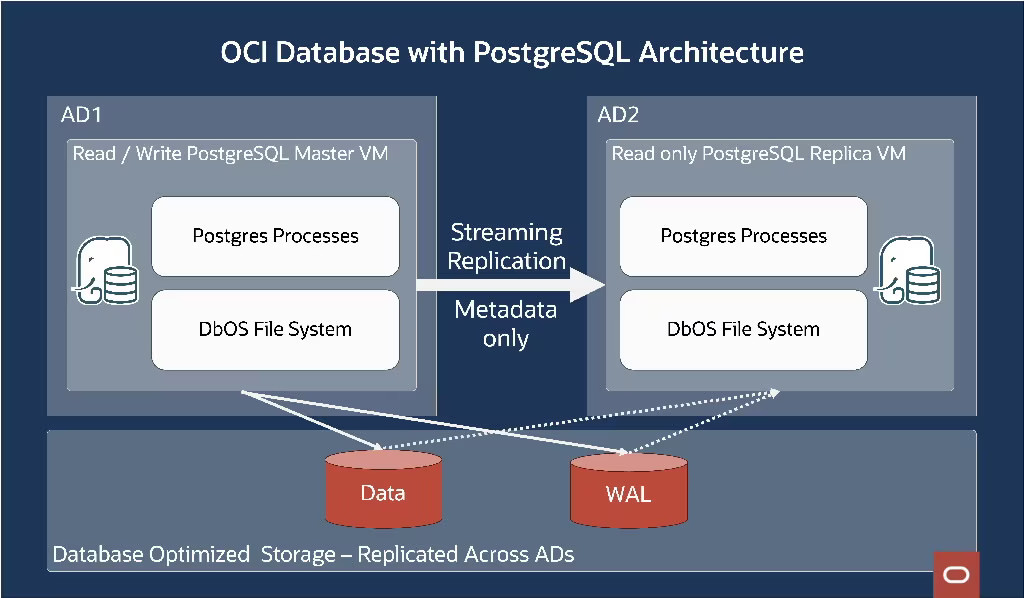
図3:OCI Database with PostgreSQL
- シングルライター・マルチリーダー: DbOS 共有ストレージ上で OCI PostgreSQL with Databaseを実行するために、複数のノードがファイルシステムに同時にアクセスできるカスタム・ユーザーモード DbOS ファイルシステム (DbFS) を構築しました。 具体的には、プライマリ・データベースと複数のリードレプリカ・データベースをサポートするために、シングルライター・マルチリーダーのアクセスモデルをサポートします。
- メタデータベースのレプリケーション: プライマリノードは読み取り/書き込みモードで DbFS をマウントし、リードレプリカノードは読み取り専用モードで DbFS をマウントします。 プライマリノードによってファイルシステムに加えられた変更は、レプリカノードに表示されるようになります。 データはストレージ層に保存され、ファイル システムがメタデータを管理します。 ストレージが共有されているため、プライマリからのデータレプリケーションは、メタデータのみをレプリケートすることによって実現されます。 ファイルの作成やファイルへのエクステントの割り当てなど、ファイルシステムのメタデータに対するすべての変更は、DbFS にジャーナル記録されます。ジャーナル更新はレプリカノードに送信されます。レプリカノードはジャーナルエントリを再生して、メモリ内のメタデータを最新の状態に保ちます。標準的な PostgreSQL が WAL 更新を通じて物理レプリケーションを行う方法と似ています。
- LSN 対応ストレージ: DbFS でのデータとメタデータの変更は両方とも、データベース・ログシーケンス番号 (LSN) でタグ付けされます。ブロックを不透明なデータのように扱う従来のファイル システムとは異なり、DbFS は個々のデータベースブロックの LSN を追跡します。 同じブロックの複数のバージョンを異なる LSN に保存します。 これにより、PostgreSQL は特定の LSN で DbFS からブロックを読み取り、「一貫した読み取り」を実現できるようになります。 ファイルの作成や削除などのメタデータ操作にも、対応するデータベース LSN がタグ付けされます。 ストレージはすべてのデータベース・インスタンス間で共有されるため、DbFS はプライマリによるファイルの削除を処理する必要があります。 プライマリでファイルが削除されても、遅れている一部のレプリカノードがそれらのファイルにアクセスする可能性があるため、そのファイルをストレージからすぐに削除することはできません。 DbFS はそのようなファイルを廃棄しますが、レプリカからは引き続きアクセスできます。 レプリカの LSN が先に進むと、これらの用済みのファイルはバックグラウンドで完全に削除されます。
- 従量制のストレージ モデル: DbFS はオンライン サイズ変更をサポートしているため、PostgreSQL が使用するストレージ スペースに応じて基盤となるストレージをスケールアップ・スケールダウンできます。 オンラインでのサイズ変更は純粋なメタデータのみの操作であるため、迅速に行うことができます。 データ ストレージ容量が減少すると、ストレージも自動的にスケールダウンされます。
共有ストレージからの「一貫した読み取り」の実現

図4:バニラPostgreSQLのレプリケーション
レプリカが読み取りクエリを満たすには、そのレプリカの現在の ReplayLSN の時点で一貫したページのバージョンを読み取ることができなければなりません。 これは、分割やマージなどの構造変更が同時に行われる可能性がある B ツリーなどのインデックス構造を走破する場合に重要です。標準的なPostgreSQLでは、LSN はログシーケンス番号であり、ReplayLSN はレプリケーション・プロセスの一部として実行される WAL 再生アクティビティ中の LSN です。標準的な PostgreSQLでは、各レプリカにそれぞれのストレージがあります。つまり、各レプリカは読み取りの一貫性を独立して維持できます。 図 4 は、バニラ PostgreSQL がプライマリ・データベースとレプリカ・データベースのデータを個別に保存していることを示しています。 プライマリには LSN 100 でデータが保持され、LSN 110 で最新データが書き込まれています。レプリカは LSN 90 で後続しています。ブロック 0 の読み取りリクエストがレプリカに送信されると、レプリカは LSN 90 で最新データを読み取ります。
ここで、これと同じ状況が、データベース対応の共有ストレージ層を使用する DbFS によってどのように処理されるかを見てみましょう。
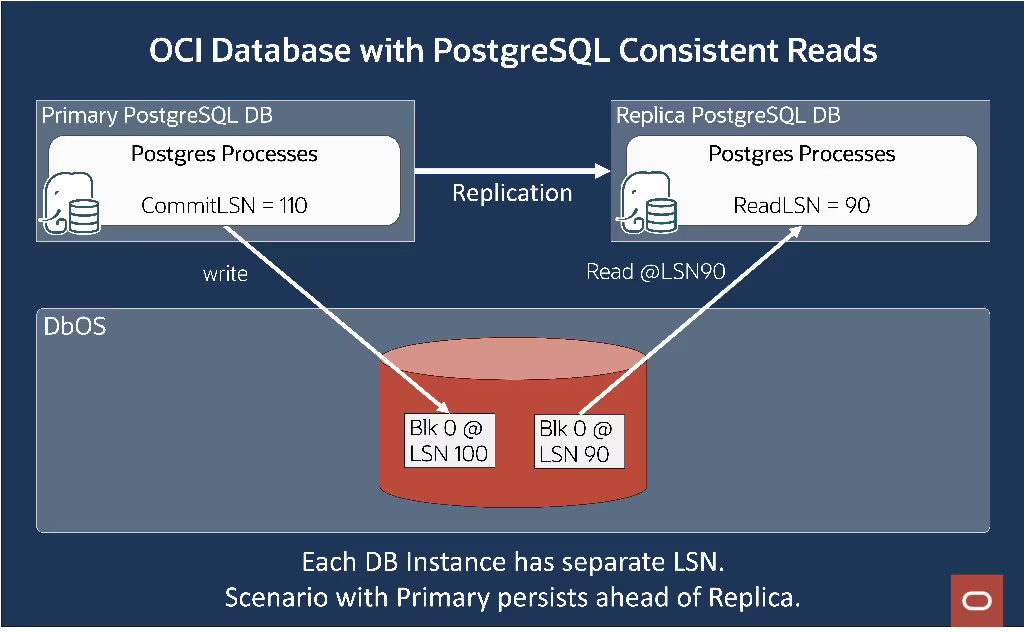
図5:プライマリがレプリカの前のシナリオ
レプリカが特定の LSN でページを読み取れるようにするために、DbFS はさまざまな LSN でページの複数のバージョンを保持します。 プライマリがチェックポイントまたはキャッシュの削除の一部としてページをフラッシュするとき、レプリカがまだそれを必要とする場合、DbFS は以前のコピーを上書きしません。 ログ構造ファイル システムに似たスキームでは、ブロックは新しいオフセットに書き込まれ、ブロックの複数のバージョンがリード レプリカで利用可能になります。 すべてのレプリカが LSN を超えてブロックが不要になったと DbFS が判断すると、古いバージョンは最終的に破棄されます。
図 5 では、プライマリは最初に LSN 90 でブロック 0 を永続化し、続いて LSN 100 で永続化しました。レプリカはまだ LSN 90 にあるため、プライマリは LSN 100 を別の場所に書き込み、LSN 90 のブロック 0 を上書きしません。 プライマリとレプリカに別々のバージョンのブロック 0 を保存すると、各レプリカの読み取り一貫性を確保できます。
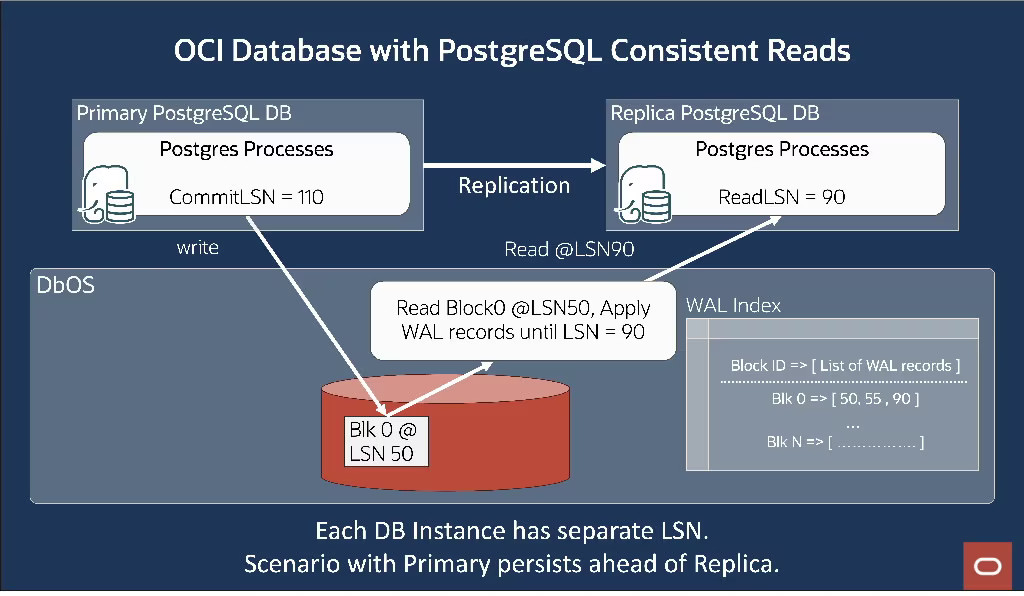
図 6: OCI Database with PostgreSQL – プライマリの最新データが永続化されていないシナリオ
プライマリがレプリカの ReplayLSN の時点でページを永続化していない場合、共有ディスクからページの古いバージョンを読み取り、このページに該当する WAL レコードを即時に再生して、レプリカの現在の ReplayLSN の時点でこのページを最新の状態にします。この WAL 再生を効率化するために、各レプリカはすべての WAL レコードのメモリ内インデックスを維持します。このインデックスはページ番号によってインデックス付けされ、最後のチェックポイント以降に維持されます。
図 6 では、プライマリは LSN 50 でブロック 0 を永続化していますが、ブロック 0 のメモリ内データは LSN 110 にあります。レプリカは、LSN 90 がメモリ内状態になるまで正常に再生されています。 その結果、レプリカは LSN 90 の DbOS に対してブロック 0 の読み取り要求を行います。DbOS には現在、LSN 50 にデータが永続化されています。DbOS は LSN 90 まで WAL レコードを適用し、LSN 90 のデータをレプリカに返します。 WAL インデックスを使用すると、プライマリがデータをストレージに永続化していない場合でも、DbOS は一貫したデータをレプリカに正常に返すことができます。
プライマリ・フェイルオーバー
高可用性を実現するために、OCI Database with PostgreSQLは異常なプライマリ・インスタンスを自動的に検出し、既存のリードレプリカにフェイルオーバーするか、リードレプリカがない場合は新しいデータベース・インスタンスを起動します。 フェイルオーバーのプロセスでは、異常なプライマリの共有ストレージへの新しい変更を停止するだけでなく、共有ストレージへの実行中の I/O リクエストがすべてキャンセルされることも保証する必要があります。 ネットワークの分割を伴う一部の障害シナリオでは、異常なプライマリに外部からアクセスできない場合がありますが、それでも共有ストレージを変更できる可能性があります。 これらの複雑なケースに対処するために、DbFS はブロック層予約 (NVMe 予約または SCSI-3 永続予約) を使用して古いプライマリを囲い込み、常に単一のプライマリが存在するようにします。 永続予約または NVMe 予約を使用すると、予約を保持しているノードは誰でも共有ストレージに書き込むことができます。 フェールオーバー中に、新しいプライマリが予約を取得し、古いプライマリを先制します。 これが完了すると、ストレージ サブシステムは古いプライマリからのすべての要求を拒否します。
さらなるストレージの最適化
共有ストレージの最適化に加えて、OCI Database with PostgreSQLでは、パフォーマンスをさらに向上させるために次の最適化が実装されました。
atomic write : DbOS は、「破損した書き込み」の排除など、既知のデータベースのパフォーマンスリスクに対する最適化を実装します。 通常、ほとんどのデータベースは、基盤となるストレージの「atomic writeユニット」サイズ(通常は 512B または 4KB)と一致しないページ サイズ(PostgreSQLだと8 KB)をデータベースが使用する場合に発生する「破損書き込み」に対する何らかの保護を必要とします。例えば、最後のチェックポイント以降のページへの最初の変更である場合、PostgreSQL は最初に 8KB ページ全体を WAL に書き込み、次にそのページをディスクにフラッシュします。 ページ書き込みが壊れた場合、PostgreSQL は以前に WAL に書き込んだページ全体を使用するようにフォールバックし、害はありません。 しかし、この保護には代償が伴います。WAL の肥大化を引き起こし、計画外のフェールオーバー時の回復時間を最小限に抑えるために必要なチェックポイントが頻繁に行われるため、問題はさらに悪化します。DbOS の PostgreSQL ページに対するアトミック書き込みサポートを実装しました。 ストレージ層が既存のページを上書きすることはありません。 代わりに、ログ構造化技術を使用して常にディスク上の新しい場所にページを書き込み、論理ファイルのオフセットからディスクの場所までのマッピング層を維持します。 古いバージョンのページは定期的にガベージコレクションされます。 これにより、二重書き込みが回避されます。
ページキャッシュの最適化: OCI Database with PostgreSQLは、汎用の Linux カーネル・ページキャッシュに依存するバニラ PostgreSQL とは異なり、専用のキャッシュレイヤーを使用します。 OCI のページキャッシュ実装には、次のような多くの最適化が行われています。
- PostgreSQL ワークロードに合わせたカスタム・プリフェッチ ロジック
- PostgreSQL 共有バッファとページ キャッシュでのページの二重キャッシュを回避
- データページをプリフェッチすることでPostgreSQLのリカバリを高速化
ストレージレベルのバックアップ: 通常の Postgresでは、データベースのバックアップを維持するために、WAL がオブジェクトストレージにコピーされ、ファイルシステムの定期的なスナップショットが取得されます。 このプロセスでは、プライマリノード上のネットワークと CPU の両方が使用されます。 OCI Database with PostgreSQL はバックアップをストレージ層に委任し、バックアップのためのネットワークと CPU のオーバーヘッドを排除します。
まとめ
OCI Database with PostgreSQL サービスは、先に詳しく説明したように、コスト、パフォーマンス、スケール、可用性、耐久性の点で大きな利点を提供します。 これらの利点のほとんどを実現するための鍵は、クラウドスケールでより効果的に動作するように PostgreSQL を最適化する目的で構築された DbOS と DbFS に基づいています。
重要なポイント
OCI Database with PostgreSQL は、すべてのデータベース・ノードが同じ基礎となる DbOS を共有する、専用の共有ストレージアーキテクチャを使用します。
DbOS は、プライマリ・フェールオーバー (zero-RPOフェールオーバー) 中にデータを損失することなく、リージョン全体にデータを自動的にレプリケートします。
OCI Database with PostgreSQL は、読み取りワークロードを水平方向にスケーリングし、クラスタ内のすべてのレプリカにわたって一貫した高パフォーマンスの読み取りを可能にします。
共有ストレージは、データのコピーを複数保存する必要がなく、データ サイズが減少するとストレージが自動的に縮小されるため、顧客に大幅なコスト削減をもたらします。
Oracle Cloud Infrastructure (OCI) Engineeringは、エンタープライズ顧客向けの最も要求の厳しいワークロードを処理するため、クラウド・プラットフォームの設計について異なる考え方をする必要がありました。 この「第一原則」シリーズの一環として、こうしたエンジニアリングの詳細をさらに詳しく説明ています。このシリーズは、Pradeep Vincent とその他の Oracle の経験豊富なエンジニアが主催しています。
詳細については、次のリソースを参照してください:
