※ 本記事は、Andy Rivenesによる”23c Deep Dive – In-Memory Vector Join Enhancements“を翻訳したものです。
2023年12月22日
インメモリー・ディープ・ベクトル化フレームワークは、Oracle Database 21cで最初に導入されました。新しいフレームワークを利用する最初の機能は、インメモリー・ベクトル化結合でした。Oracle Database 23cでは、インメモリー・ディープ・ベクトル化が拡張され、次の追加の結合タイプがサポートされるようになりました:
• マルチレベル・ハッシュ結合
• 複数結合キー
• 準結合
• 外部結合
• 集計別全グループ
この機能拡張により、単一命令、複数データ(SIMD)ベクトル命令を利用して、パフォーマンスを向上できます。私は、SSBスキーマとともに続く例としてOracle Database 23c Freeを使用しました。
さらに詳しく。結合グループと同様に、インメモリー・ディープ・ベクトル化は、SQLモニターによって取得される実行時決定です。インメモリー・ディープ・ベクトル化の使用は、ハッシュ結合操作の双眼鏡をクリックすることで、SQLモニターのアクティブ・レポートに表示できます。次に例を示します:
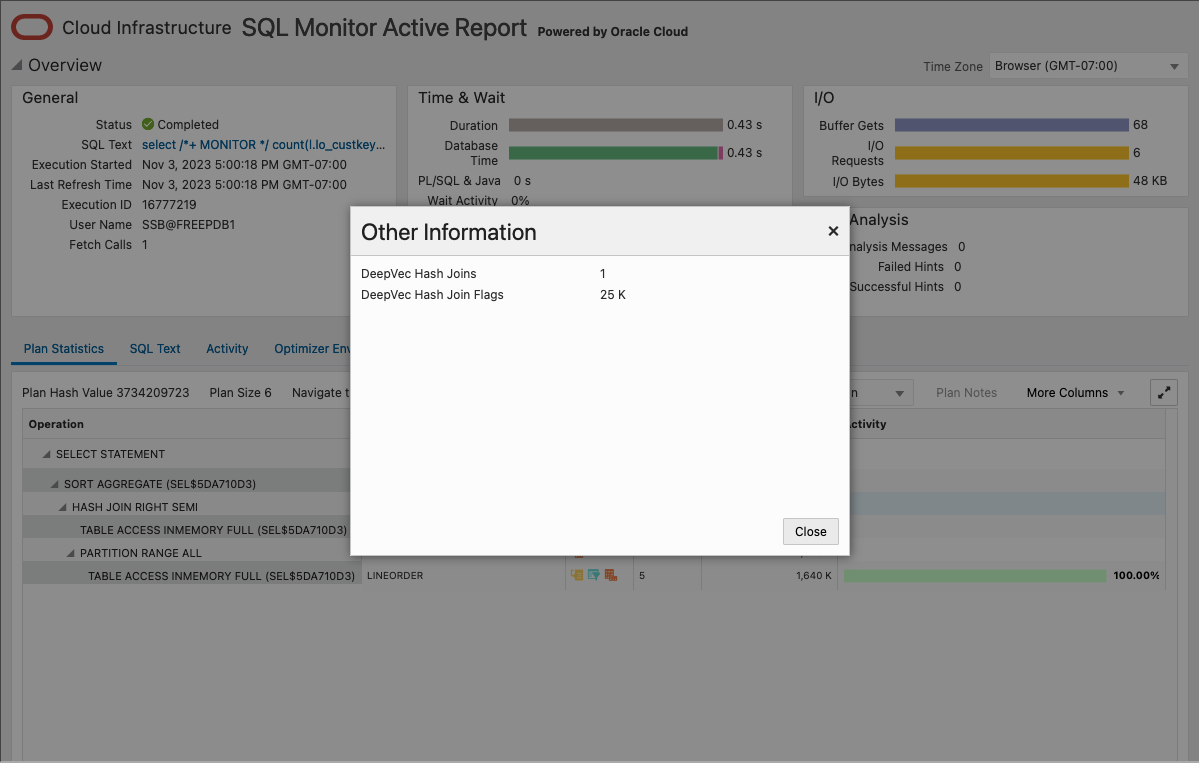
最初の統計「DeepVecハッシュ結合」が1に設定されていることに注意してください。これは、ディープ・ベクトル結合が実行されたことを意味します。SQLを使用して同じ情報を表示する2番目の方法があります。次のSQL文は、基礎となるSQLモニター表の同じ情報を表示します:
set echo off
set trimspool on
set trim on
set pages 0
set linesize 1000
set long 1000000
set longchunksize 1000000
PROMPT Deep Vectorization Usage: ;
PROMPT ------------------------- ;
PROMPT ;
SELECT
' ' || deepvec.rowsource_id || ' - ' row_source_id,
CASE
WHEN deepvec.deepvec_hj IS NOT NULL
THEN
'deep vector hash joins used: ' || deepvec.deepvec_hj ||
', deep vector hash join flags: ' || deepvec.deepvec_hj_flags
ELSE
'deep vector HJ was NOT leveraged'
END deep_vector_hash_join_usage_info
FROM
(SELECT EXTRACT(DBMS_SQL_MONITOR.REPORT_SQL_MONITOR_XML,
q'#//operation[@name='HASH JOIN' and @parent_id]#') xmldata
FROM DUAL) hj_operation_data,
XMLTABLE('/operation'
PASSING hj_operation_data.xmldata
COLUMNS
"ROWSOURCE_ID" VARCHAR2(5) PATH '@id',
"DEEPVEC_HJ" VARCHAR2(5) PATH 'rwsstats/stat[@id="11"]',
"DEEPVEC_HJ_FLAGS" VARCHAR2(5) PATH 'rwsstats/stat[@id="12"]') deepvec;
これは、次の形式で表示されます:
Deep Vectorization Usage: ------------------------- 2 - deep vector hash joins used: 1, deep vector hash join flags: 24576
次に、インメモリー・ディープ・ベクトル化を利用するようになった準結合の例を示します:
select /*+ MONITOR */ count(l.lo_custkey) from lineorder l where l.lo_partkey IN (select p.p_partkey from part p) and l.lo_quantity <= 3;
上の問合せの結果、23c Freeデータベースで次の実行計画が発生しました:
-------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes |TempSpc| Cost (%CPU)| Time | Pstart| Pstop |
-------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | | 5113 (100)| | | |
| 1 | SORT AGGREGATE | | 1 | 18 | | | | | |
|* 2 | HASH JOIN RIGHT SEMI | | 1640K| 28M| 12M| 5113 (8)| 00:00:01 | | |
| 3 | TABLE ACCESS INMEMORY FULL | PART | 800K| 3906K| | 73 (3)| 00:00:01 | | |
| 4 | PARTITION RANGE ALL | | 1640K| 20M| | 2448 (15)| 00:00:01 | 1 | 3 |
|* 5 | TABLE ACCESS INMEMORY FULL| LINEORDER | 1640K| 20M| | 2448 (15)| 00:00:01 | 1 | 3 |
-------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("L"."LO_PARTKEY"="P"."P_PARTKEY")
5 - inmemory("L"."LO_QUANTITY"<=3)
filter("L"."LO_QUANTITY"<=3)
25 rows selected.
SQL>
SQL> set echo off
Deep Vectorization Usage:
-------------------------
2 - deep vector hash joins used: 1, deep vector hash join flags: 24576
操作2「Deep Vectorization Usage」セクションで、HASH JOIN RIGHT SEMIがディープ・ベクトル・ハッシュ結合を使用して識別されたことに注意してください。
前述したように、ディープ・ベクトル結合がより高いパフォーマンスを達成する主な方法の1つは、単一命令、複数データ(SIMD)ベクトル処理を活用できることです。この違いは、インメモリー・ベクトル化を無効にして有効化した状態で、実行中の統計を比較するとわかります。残念ながら、21c以降では、IM SIMD統計はシステム・レベルでのみ使用できます。この問題については、21cのインメモリー・ベクトル結合で行ったAsk TOM Office Hoursセッションで話しました。ここからそのビデオを見ることができます。回避策は、変更したバージョンのTom Kyteの古いrunstatsユーティリティを使用して、セッション・レベルの統計ではなくシステム・レベルの統計を比較することでした。古いrunstatsユーティリティおよび変更されたrun_sysstatsユーティリティは、Githubサイトのここで確認できます。
注意事項です。システム・レベルの統計は、すべてのデータベース・セッションにわたって集計されます。この実験では、23c Freeデータベースを基本的に自分の仮想マシンで単一のユーザー・システムとして実行していました。複数のユーザーがインメモリー問合せを実行している場合、このアプローチはうまく機能しません。
次に、前の問合せの2つの実行からの出力を示します。1つ目はインメモリー・ディープ・ベクトル化が無効(つまり、inmemory_deep_vectorization = false)で、次にインメモリー・ディープ・ベクトル化が有効(つまり、inmemory_deep_vectorization = true)です:
Name Run1 Run2 Diff STAT...CPU used by this session 5 41 36 STAT...IM scan rows projected 2,440,148 51 -2,440,097 STAT...IM simd KV add calls 0 795 795 STAT...IM simd KV add rows 0 800,000 800,000 STAT...IM simd KV probe calls 0 51 51 STAT...IM simd KV probe chain_buckets 0 7,437 7,437 STAT...IM simd KV probe keys 0 1,640,148 1,640,148 STAT...IM simd KV probe rows 0 1,640,148 1,640,148 STAT...IM simd KV probe serial_buckets 0 420 420 STAT...IM simd decode symbol calls 3,126 2 -3,124 STAT...IM simd decode unpack calls 0 2 2 STAT...IM simd decode unpack selective calls 0 2 2 STAT...IM simd hash calls 0 53 53 STAT...IM simd hash rows 0 2,440,148 2,440,148 STAT...physical reads 28 13 -15 STAT...session logical reads 214,127 214,005 -122 STAT...session pga memory -524,288 0 524,288
文がインメモリー・ディープ・ベクトル化を有効にして実行されたRun2列でのSIMDの使用には、大きな違いがあることに注意してください。
本当に大事な改良が行われました。マルチレベル結合をサポートする機能です。どうしてこれがそれほど重要な強化なのでしょうか? これにより、行ソースまたは以前の結合の結果と表の間の結合を操作できるためです。したがって、マルチレベル結合になります。
次の問合せを使用して、マルチレベル結合を表示します:
select /*+ MONITOR NO_VECTOR_TRANSFORM */ d_year, c_nation, s_region, lo_shipmode , sum(lo_extendedprice) from part p, customer c, lineorder l, supplier s, date_dim d where s.s_suppkey = l.lo_suppkey and l.lo_custkey = c.c_custkey and l.lo_partkey = p.p_partkey and l.lo_orderdate = d.d_datekey group by d_year, c_nation, s_region, lo_shipmode;
この問合せでは、次の実行計画が生成され、「ディープ・ベクトル化の使用方法」の項から、実行計画の各ハッシュ結合によってディープ・ベクトル結合が実行されたことがわかります。
----------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes |TempSpc| Cost (%CPU)| Time | Pstart| Pstop |
----------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | | 145K(100)| | | |
| 1 | HASH GROUP BY | | 2166 | 203K| | 145K (2)| 00:00:06 | | |
|* 2 | HASH JOIN | | 27M| 2485M| | 145K (1)| 00:00:06 | | |
| 3 | PART JOIN FILTER CREATE | :BF0000 | 2556 | 30672 | | 1 (0)| 00:00:01 | | |
| 4 | TABLE ACCESS INMEMORY FULL | DATE_DIM | 2556 | 30672 | | 1 (0)| 00:00:01 | | |
|* 5 | HASH JOIN | | 27M| 2175M| | 145K (1)| 00:00:06 | | |
| 6 | TABLE ACCESS INMEMORY FULL | SUPPLIER | 20000 | 351K| | 3 (0)| 00:00:01 | | |
|* 7 | HASH JOIN | | 27M| 1719M| 9672K| 144K (1)| 00:00:06 | | |
| 8 | TABLE ACCESS INMEMORY FULL | CUSTOMER | 300K| 6152K| | 33 (7)| 00:00:01 | | |
|* 9 | HASH JOIN | | 27M| 1172M| 12M| 70700 (2)| 00:00:03 | | |
| 10 | TABLE ACCESS INMEMORY FULL | PART | 800K| 3906K| | 73 (3)| 00:00:01 | | |
| 11 | PARTITION RANGE JOIN-FILTER| | 27M| 1042M| | 2701 (23)| 00:00:01 |:BF0000|:BF0000|
| 12 | TABLE ACCESS INMEMORY FULL| LINEORDER | 27M| 1042M| | 2701 (23)| 00:00:01 |:BF0000|:BF0000|
----------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("L"."LO_ORDERDATE"="D"."D_DATEKEY")
5 - access("S"."S_SUPPKEY"="L"."LO_SUPPKEY")
7 - access("L"."LO_CUSTKEY"="C"."C_CUSTKEY")
9 - access("L"."LO_PARTKEY"="P"."P_PARTKEY")
37 rows selected.
SQL>
SQL> set echo off
Deep Vectorization Usage:
-------------------------
2 - deep vector hash joins used: 1, deep vector hash join flags:
5 - deep vector hash joins used: 1, deep vector hash join flags: 8192
7 - deep vector hash joins used: 1, deep vector hash join flags: 8192
9 - deep vector hash joins used: 1, deep vector hash join flags: 24576
これは非常にエキサイティングな強化です。ブルーム・フィルタは不要であり、この問合せのベクトル変換を無効にして、マルチレベル結合がどのように機能するかを示しました。ディープ・ベクトル結合はベクトル変換を直接サポートしませんが、同じ計画内の他のハッシュ結合はディープ・ベクトル結合を利用できます。もう一つ注意すべき点があります。マルチレベルのディープ ベクトル結合では、左ディープ、右ディープ、および一部のタイプのブッシュ結合がサポートされます。
ディープ・ベクトル結合も改善する他の2つのデータベース・インメモリー機能があります。結合グループおよびインメモリー動的スキャン(IMDS)です。結合グループは、同じ表または異なる表の列のディクショナリ値を同期することで役立ち、結合グループ内の列の結合が高速になります。IMDSは、IMCUレベルでスキャンをパラレル化するため、スキャンの改善を提供します。結合グループは、明示的に定義するか、23cの自動インメモリー(AIM)で定義する必要があります。CPU容量が超過し、CPU数が24を超えるシステムでは、リソース・マネージャによってIMDSが自動的に有効化されます。前述の例では、これらの機能はいずれも使用されていませんが、大規模なデータベースに対して大幅なパフォーマンス向上を提供できます。
