この記事はLudovico Caldaraによる”To mirror, or not to mirror, that’s the question“の日本語翻訳記事です。
※この記事は2021年に公開されたものです。最新の情報と異なる可能性があります。
2024年8月5日
「データロ損失をゼロにし、ダウンタイムを最小限に抑えてデータベースを保護するにはどうしたらよいでしょうか?」しばしばこのような質問をいただくことがあります。
データベースの規模が大きくなればなるほど、ソリューションはより創造的になり、その創造性には複雑さとトレードオフが伴います。
しかし、適切なディザスタ・リカバリを行う方法は一つしかありません。それは少なくとも1つの他の物理的サイトにデータをレプリケートすることです。
データをAからBに移動させる方法と言っても、それらにははいくつか種類があり、そこが面白くなるところです。
ソフトウェアをもっと単純な例に例えると、ネジで視覚化することができるます。壁にネジを打ち込むのに、ハンマーは使わないでしょう?ネジにダメージを与えるか、壁にダメージを与えるか、どちらかですが、どちらの方法をとっても最終的にはうまくいかないでしょう。この特殊な作業にはハンマーよりもドライバーの方がはるかに適していることは明確です。
同じ原則がソフトウェアにも当てはまります。つまり、ジョブに対して適切なツールを利用しましょうということです。
ここでは、Oracle Databaseの適切な保護に焦点を当てましょう。
この記事では、ストレージ・レプリケーションに焦点を当て、Oracle Databaseでこのテクニックを使用した場合に何が起こるか、または起こりうるかを説明します。
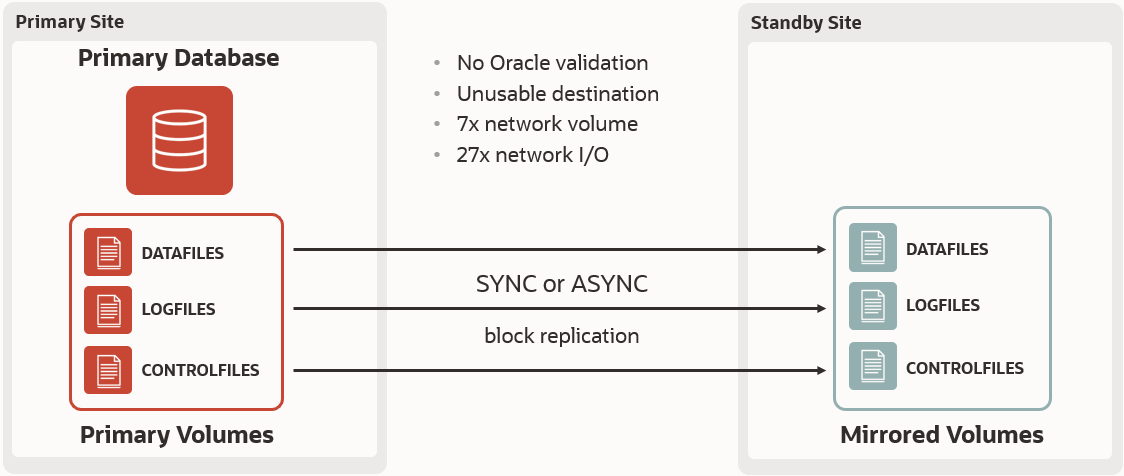
ストレージ・レプリケーションのテクニックの中を見てみると、「ソース側の書き込みは、ターゲット側でも反映されなければならない」という初歩的な原則が使われていることがわかります。これは揺るぎない単純な原理だと思うでしょうが、実はそうでもありません。
たった一度の書き込みでデータベースが壊れてしまったら?ストレージ・レプリケーションのメカニズムでは、ブロック内で何が起こっているのか分からないまま、喜んで遠隔地にデータを送信してしまいます。したがって、その時点で両方のサイトで同じ破損が発生し、スタンバイサイトを失うことになります。最近、これに関してよく行われる議論としては、書き込みがシステムからアレイAに1回、アレイBに1回と2回発行されるため、最新のシステムではエラーが起こりにくいというものです。しかし、書き込み処理が論理的にデータベースを壊していたらどうしましょう?両方のサイトが再び使えなくなり、手遅れになるまで論理的に壊れている状態に気づかないことがよくあります。
ストレージ・レプリケーションはブロックの破損を検出することはできませんが、データベースを保護するのに役立ちますよね?
しかし、実際はそうではありません。例えば、誤ってファイルを削除してしまったらどうなるでしょうか?その削除操作はそのままスタンバイにレプリケートされ、ファイルはリモートサイトでも失われてしまうので、同じ悲惨な状況に陥ります。これはスタンバイ・データベースで可能なユースケースを拡大しても、状況は良くなりません。
レプリケーションが実行されている間、読み取り専用の分析クエリーやレポートをリモートサイトにオフロードしたい場合はどうすればよいでしょうか。
ミラーコピーはこのような用途には使えません。つまり、ワークロードをオフロードする手法を失うだけでなく、オフロードすることで得られるスタンバイ環境の継続的な運用検証も失うことになります。
ストレージ・レプリケーションはデータを忠実にコピーすることができますが、その反面あらゆる種類の破損を忠実にコピーしてしまい、ミラーサイトを最悪のタイミングで使い物にならなくする可能性があります。
これは今でも続いており、最近(2021年)、私はヨーロッパに200以上の実店舗を持ち、約3万人の従業員を抱える大手小売企業の会議に参加するよう依頼されました。彼らは災害復旧計画で深刻な問題に直面しており、私はこのような状況においていつでも喜んで手を貸し、ガイダンスを提供します。話を聞くと、正しく構成・調整されたストレージ・レプリケーション・システムが問題に直面していることがわかりました。彼らの状況を説明すると、すべてのシステムが仮想化されており、Oracle Databaseがマシン内にあるこれらのボックスで稼動していました。しかし、ある時点でプライマリ・ストレージ・アレイがコールドシャットダウンし、そのすべてのVMがそこで稼働していることに気づいたとき、これは深刻な問題になりました。さらに悪いことにすべての書き込みがターゲット・システム上で完了しておらず、環境の約75%が完全に使用できない状態になってしまっていました。
特に、バックアップから完全な非本番環境をリストアし、本番システムから新しいクローンを作成する必要があったため、問題はさらにエスカレートしました。幸運なことに、本番環境の書き込みは時間内に完了し、別のサイト側で再びオープンすることができましたが、これには全復旧には10日以上かかっりました。
もし本番システムにも影響が及んでいたらどうなっていたか、想像してみてください。
これは最近の事例であり、正しく調整され構成されたシステムから起こった問題です。あらゆる善意ある予防措置にもかかわらず、このようなストレージ複製災害が、現代のディザスタリカバリ構成で起こり得るのです。しかし、これは頻繁に起こることなのでしょうか?いや、この規模の災害と同様、めったに起こらないが、それでも実際に起こります。
ネジの話を覚えていますか?Oracle Databaseを保護するためのより優れたツールがります。それはOracle Data Guardです。
重要なMAAテクノロジーの1つであるOracle Data Guardは、シンプルな原理で動作します。それは、REDOと呼ばれるデータベース・トランザクションによって行われたすべての変更を使用することです。
Data Guardは「REDOを転送し、REDOを適用する」という最も単純な原則を使用します。REDOには、Oracle Databaseがデータベース・トランザクションをリカバリするために必要なすべての情報が含まれています。プライマリ・データベースと呼ばれる本番データベースは、1 つ以上の独立したレプリカ(スタンバイ データベースと呼ばれる)にREDOを送信します。Oracle Data Guardのスタンバイ・データベースは、プライマリ・データベースとの同期を維持するために、REDOを検証して適用し、継続的な復旧状態にあります。この検証を実現できるのはOracle Data Guardだけです。ブロックに何が必要かを知っているのはデータベースだけです。Oracle Data Guardは、スタンバイ・データベースに書き込まれたデータが正しいことを保証することができます。
また、Oracle Data Guardは、ネットワークやスタンバイの停止によって一時的にプライマリデータベースから切り離されたスタンバイ・データベースを自動的に再同期することもできます。
![]()
ストレージ・レプリケーションは、データファイルやログファイルを含め、 データベース内で変更されたすべてのブロックをミラー化します。書き込みを多用するアプリケーションでは、 ストレージミラー化のオーバーヘッドにより多くのネットワーク帯域幅が必要になり、データベースのパフォーマンスに悪影響を与えかねません。
逆に、Oracle Data Guardが使用するREDO転送はI/Oレイヤーをバイパスし、転送量をスタンバイ・サイト上で修正を適用するために必要なものたけに厳密に絞ることができます。
さらに、Oracle Data Guardのプリケーションは転送データ量を劇的に削減するうえ、転送の前後にブロックを検証してデータが論理的に正しいことを確認します。
Oracle Data Guardは、Oracle Enterprise Editionに追加費用なしでご利用いただけます。これにより、スタンバイ・データベースの作成と保守、ロールの移行(スイッチオーバー、手動または自動フェイルオーバー)の実行、スナップショット・スタンバイ・モードでのスタンバイの読み取り/書き込みテストが可能になります。
スタンバイ・データベースは、プライマリから到着したREDOを適用しながら、読み取り専用ワークロードを実行できます。このリモートサイトでの読み取り専用機能には、 Oracle Active Data Guardオプションが必要です。
Oracle Active Data Guard は、運用作業のオフロード、高速インクリメンタル バックアップの実行、ローリング アップグレードなどの追加機能を提供します。DMLリダイレクションは、これらの機能の完璧な例であり、読み取り専用のスタンバイ・データベースで作業しながら、時折DML操作を行うことができます。この機能については以前にブログで紹介しています。
結論として、Oracle Data Guard(またはActive Data Guard)は、Oracle Databaseに保存されたデータを完全に保護するのに適した唯一のツールです。こちらの資料で取り上げたようにで取り上げたように、そのアプローチはストレージレベルのレプリケーションよりも優れています。
