※本ページは、”All About Exadata Disk Scrubbing“の翻訳です
この投稿では、Exadata – Automatic Hard Disk Scrub and Repair機能(自動ハード・ディスク・スクラブおよび修復)の根本的かつ一般的に誤解されている機能について説明します。確かに、格好よく聞こえますが、サイレントなデータ破損が検出されて修復される、Exadataで重要な Maximum Availability Architecture (MAA)機能です。
最初から始めましょう。
Oracle Databaseは、どのプラットフォームで実行していても、最終的に何らかの形式の永続ストレージにデータを書き込みます。通常、これはハードディスク・ドライブ(HDD)またはフラッシュ・デバイスである可能性があります。Exadataでは、大容量(HC)ストレージ・サーバー(X10M世代には12本 x 22 TBのHDDが付属)と、4本 x 30.72 TBのフラッシュ・ドライブを搭載したExtreme Flash (EF)ストレージ・サーバー)の2つのストレージ・サーバーを提供しています。フラッシュ・ドライブはスクラブする必要がないため、大容量ストレージのみにフォーカスして、データは適切な回転ディスクに保持されます。データベース・ブロックがHDDに書き込まれると、複数の4kセクター(最新のHDDの場合です、以前は512バイトのセクターがありました)にまたがって保存されます、私たちの関心事項は、これらのディスク上のセクターについてです。
時間の経過とともに、HDDの使用期間は長くなり、データへのアクセス頻度はますます少なくなります。明らかに、これはデータそのものとその目的によって異なりますが、現時点ではこれで十分です。データへのアクセス頻度が低くなると、Oracle Databaseでは、ブロック(および暗黙的にディスク・セクター)を検査して、ブロックがまだ有効であり、時間の経過とともにコラプション(破損)が発生していないかどうかをチェックする機会が少なくなります。
コラプション(破損)によって何を意味するかを定義することの意味を考えてみましょう。データ破損は複数の形式で発生しますが、論理的な破損および物理的な破損という基本的なカテゴリに分類できます。
「論理的な破損」とは、データが意図されているコンテキストで論理的に有効でないようにデータが変更されるときです。たとえば、表の値リスト表を更新し、すべての国を「オーストラリア」とするように変更したようなケースは、データベースは論理的に破損していることになります。データは技術的には有効です、この場合、単なるテキストとしてですが、、、データのコンテキスト(中身)は現実世界では意味を持ちません。このような「論理的な破損」を修正するには、フラッシュバック・テーブル、フラッシュバック・トランザクション、さらにはフラッシュバック・データベースなどのデータベース機能を使用して、データを以前の状態に戻すことになります。
「物理的な破損」はより深刻な問題です。これは、データベースの外で発生し、データにアクセスするまで破損が検出されません。基本的に、これは通常「ビット腐敗(bit rot)」と呼ばれ、時間の経過とともにすべてのドライブに影響を与える可能性があります。Exadataで出荷されるドライブには、エンタープライズ・グレードのディスクに搭載されている一般的なエラー修正コード(ECC)およびS.M.A.R.T機能が搭載されています。ただし、これらの機能と同様に、Oracle Databaseでは認識されません。
Automatic Hard Disk Scrub and Repair(自動ハードディスクスクラブと修復)を入力してください!Automatic Hard Disk Scrub and Repair(ハードディスクの自動スクラブと修復)- スクラブを開始し- ディスク上のセクターに物理的なエラーがないかをプロアクティブに検査し、そうすることで、HDD ECCなどの可能性がある問題を検出可能になります。スクラビングは、データベースのパフォーマンスに影響を与えないように、ディスクがアイドル状態(ビジー状態が25%未満)になったときに開始するExadataの自動プロセスであり、デフォルトで隔週でスケジュールが設定されます。
セクターが破損していることがスクラブによって検出された場合、ストレージ・サーバーは別のストレージ・サーバー上のミラーの1つからセクターを修復するようASMにリクエストします。これは、複数のミラーが不可欠であるもう1つの理由です。1つのミラーが破損している場合は、少なくとも1つのコピーが使用可能であり、障害のあるミラーを修復に使用できます。OracleのMaximum Availability Architectureの推奨事項では、トリプル・ミラーリングを使用するHigh Redundancyを採用しています。不正なセクター(破損)がディスク上で検出されるとします。その場合、不良セクターがディスクに増える可能性が高く、すべての破損が修復されるまで、Exadataはそのディスクでのスクラブ実施頻度を適応的に自動的に増やします。
ExadataでのスクラブがASMによって実行されるスクラブと異なる場合、スクラブ(エラーのチェック)されるセクターがExadataストレージ・サーバーを離れることはなく、不要なネットワーク・トラフィックが排除され、データベース・サーバーのCPU消費が回避されます。
スクラブは、データベースが最近読み取っていないセクターをターゲットとします。使用頻度が低いデータは、ある日の午前2時に問題になるのではなく、破損が早期に発見され、迅速に修復されるようにチェックする必要があります。
バックアップとミラーは、ここで特に言及する価値があります。あなたは考えているかもしれません、私は定期的にデータベースをバックアップします- それはすべてのセクターが定期的にチェックされていることを意味しますか?これは妥当な考えですが、おそらくブロック・チェンジ・トラッキングおよびRMAN未使用ブロック圧縮(RMAN Unused Block Compression)も使用しています。これにより、前回のバックアップ以降に変更されていないブロックはスキップされ、空のブロックは完全にスキップされます。読み取りは、通常、セカンダリコピーや3番目のコピーではなく、データのプライマリコピーで発生するため、すべてのディスクのスクラブが行われなかった場合に、これらのミラーに不正なセクターが表示される可能性があります。
スクラブが実行中かどうかはどのように確認できるのでしょうか? 自動ワークロード・リポジトリ(AWR)レポート、Exadata Metrics およびReal-Time Insightは、スクラブ・アクティビティに対する優れた可視性を提供します。たとえば、AWRでは、次のデータがExadataセクションにあります。
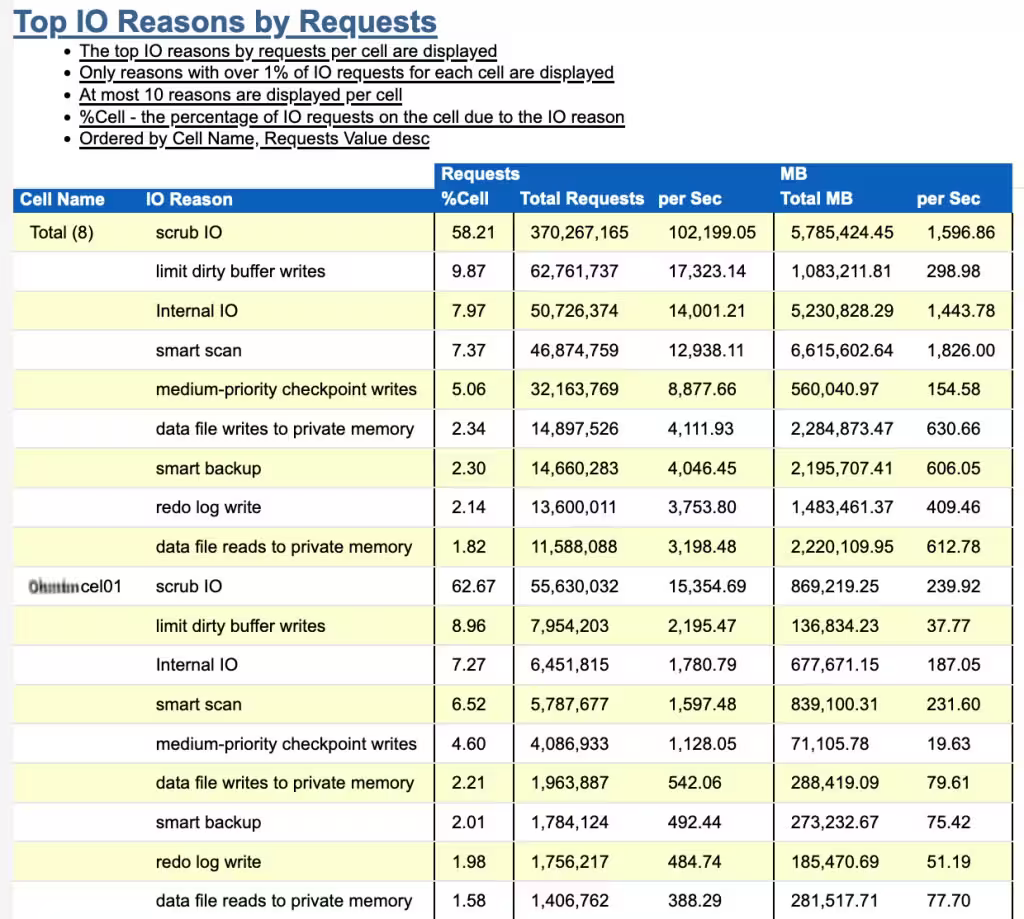
この例からわかるように、このシステムでは、この期間中に「Scrub I/O」としてかなりの量のI/Oが報告されています。ストレージ・サーバーがアイドル状態の時に実施されていて、これは良いことです。実際のデータベースI/Oが増加すると、Exadataは自動的にバックオフされ、スクラブが停止します。
ストレージ・サーバーにて、cellcliコマンドを使用して、list metriccurrent (name = ‘CD_IO_BY_R_SCRUB_SEC’) コマンドを実行できます。次の例では、12台のHDD CD_00 – CD_11において、約115 MB/s の速度でセクターをスクラブしていることがわかります。
CellCLI> list metriccurrent where name = 'CD_IO_BY_R_SCRUB_SEC' and metricObjectName like 'CD.*'
CD_IO_BY_R_SCRUB_SEC CD_00_exadbm01celadm01 115 MB/sec
CD_IO_BY_R_SCRUB_SEC CD_01_exadbm01celadm01 118 MB/sec
CD_IO_BY_R_SCRUB_SEC CD_02_exadbm01celadm01 117 MB/sec
CD_IO_BY_R_SCRUB_SEC CD_03_exadbm01celadm01 113 MB/sec
CD_IO_BY_R_SCRUB_SEC CD_04_exadbm01celadm01 114 MB/sec
CD_IO_BY_R_SCRUB_SEC CD_05_exadbm01celadm01 119 MB/sec
CD_IO_BY_R_SCRUB_SEC CD_06_exadbm01celadm01 112 MB/sec
CD_IO_BY_R_SCRUB_SEC CD_07_exadbm01celadm01 120 MB/sec
CD_IO_BY_R_SCRUB_SEC CD_08_exadbm01celadm01 116 MB/sec
CD_IO_BY_R_SCRUB_SEC CD_09_exadbm01celadm01 115 MB/sec
CD_IO_BY_R_SCRUB_SEC CD_10_exadbm01celadm01 116 MB/sec
CD_IO_BY_R_SCRUB_SEC CD_11_exadbm01celadm01 113 MB/sec
上記のStorage Server はアイドル状態の Storage Server を表します。実際のデータベースからの負荷がかかっていた場合、右側の値は 0 MB/s に低下します。
Real-Time Insight が設定されている場合(詳細はこのリンクおよびこのリンクを参照)、CD_IO_BY_R_SCRUB_SECメトリックを選択したダッシュボードに送信するようにストレージ・サーバーを構成して、すべてのExadataセルにわたるスクラブを視覚的に表示できます。
たとえば、次のようなグラフが表示されます。この例では、赤色の領域にあるセル・ディスク(IOPs – CD)の高I/Oリクエストはすべてスクラブに起因します。このサーバーでのデータベース・ワークロードの増加(緑色領域から開始)により、スクラブのI/Oが削減され、最終的に停止され、データベースI/Oが影響を受けないようになりました。
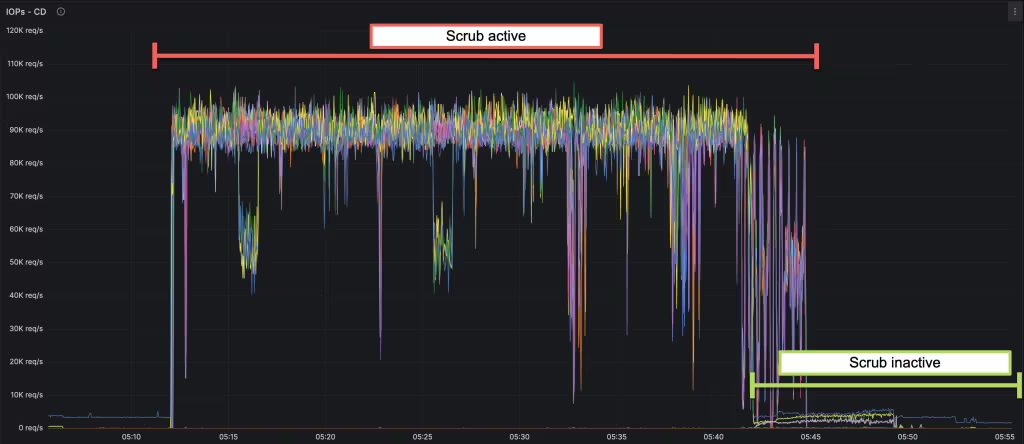
スクラブI/Oが表示されるようになったので、最近数回発生した混乱を引き起こした事象について説明します。
「Exadata OS I/O Statistics – Top Cells」セクションを見ると、次のことがわかります。すぐに目に付くのは、底の赤いハイライトされた部分です。表の上部のノートを読む前に、何かが間違っていることがわかりますか?
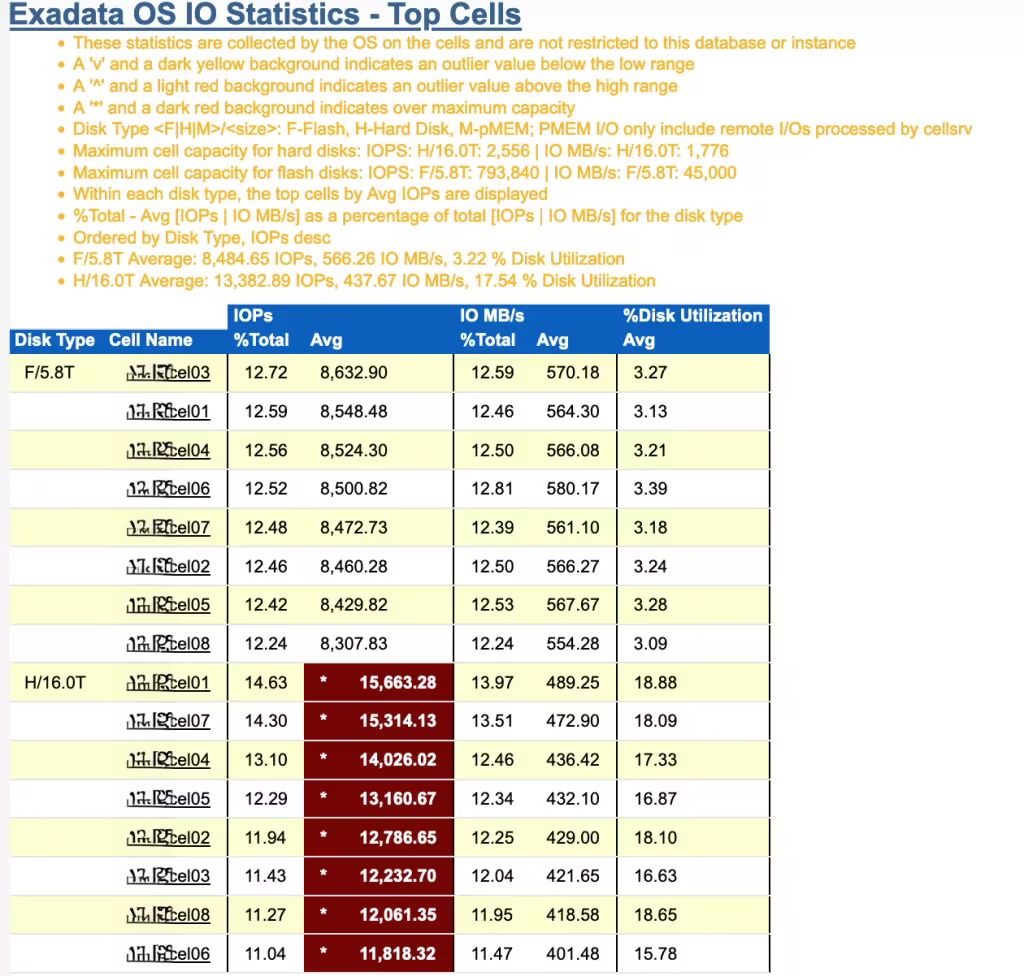
うん、うん、うん。説明させてください。
まず、すべてのストレージ・サーバーのビジー率が25%未満であることに注意してください。スクラブを開始するのに十分なアイドル状態なことが分かります。
次に、残りのノートを読んでみましょう。
「’Maximum cell capacity for hard disks: IOPS: H/16.0T: 2,556 | IO MB/s: H/16.0T: 1,776‘.」(訳注:上から6行目)
という行を確認します。ここで特に重要なのは、各「セル」(ストレージサーバー)が使用できる IOPSの数です。この例では、システムは大容量(ディスク)ストレージ・サーバーとExtreme Flash(フラッシュ)ストレージ・サーバーの両方を備えたX9Mで、それぞれに異なる特性があります(ノートを参照)。数学を少し実行する場合、赤いデータ・ポイントのそれぞれのIOPS値が、ストレージ・サーバーの実際の最大IOPS値(訳注:2,556 IOPS)の約3~6倍であることが分かります。明らかなことは、ストレージ・サーバーは、物理的に使用できる以上のI/Oは実行できません。
どのような理由によってこのような状態が発生しているのでしょうか。大容量ストレージ・サーバーのハード・ディスク・ドライブは、小さなキャッシュを含むディスク・コントローラに接続します。前述のスニペットでAWRが報告しているのは、ディスク・コントローラ・キャッシュによって処理されるIOPSの数であり、ディスク自体によって処理される物理IOPSの数ではありません。
しかし、多くの人々はこれを見て、スクラブを無効にすることが問題に対する万能であると考えます。スクラブ I/Oの実行を停止すると、問題は解消します。それは筋が通っているように聞こえます。そのような決定はプラセボであり、現実的には、長期的には有害である可能性があります。
上記から「いいえ」と「はい」両方の答えが返ってくることが分かります。
いいえ- スクラブがアクティブであることは、データベースおよびシステムの状態がヘルシーであるためであり、AWRレポートからScrubが実行中であることをが分かります。
はい- 正しくありませんが、AWRでIOPSをレポートする方法です。つまり、一部のバージョンでは、ディスク自体ではなくディスク・コントローラ・キャッシュから実行されたIOを公開することで、AWRがIOPSを過大にレポートします。
良いニュースは、この動作が修正され、DB 19.16以降のデータベース・リリース更新に含まれていることです。前述のシステム(DBRU 19.14を利用)のような以前のリリースでは、スクラブがアクティブなときにAWRに同様の出力が表示される場合は、SRを発行し、問題を確認し、必要なステップを実行して解決していました。
最後に、Automatic Hard Disk Scrub and Repair(自動ハード・ディスク・スクラブおよび修復)は、ExadataのMaximum Availability Architectureの重要な機能です。データ破損が問題になる前に検出および修復されるため、決して無効にしないでください。スクラブは自動的に実行がスロットルされるため、実際のデータベース・ワークロードには影響しません。ストレージ・サーバー内でその作業の大部分が実行されるため(ASMは破損の修復にのみ関与します)、非常に効率的です。
上記のデータとスクリーンショットを提供し、ブログをレビューし、一緒に仕事をする喜びを分かち合えた、Maximum Availability Architectureチームの素晴らしいJony Safiに感謝します。また、Shaun Levey氏による追加の技術レビューにも感謝します。
