In the rapidly evolving Gen AI landscape, effective monitoring of your inference applications plays a crucial role to ensure their performance, reliability and scalability.
OCI Application Performance Monitoring provides a dedicated framework to monitor Gen AI Inference applications. It enables tracking of response times, error detection, and model accuracy. In addition, it safeguards against issues like data drift or inefficiencies. This helps ensure compliance with regulations, strengthens security, and optimizes resource usage to enhance cost efficiency.
Check out a 5-minute video demonstrating the feature:
OCI Application Performance Monitoring: LLM Observability
Key Features and Benefits
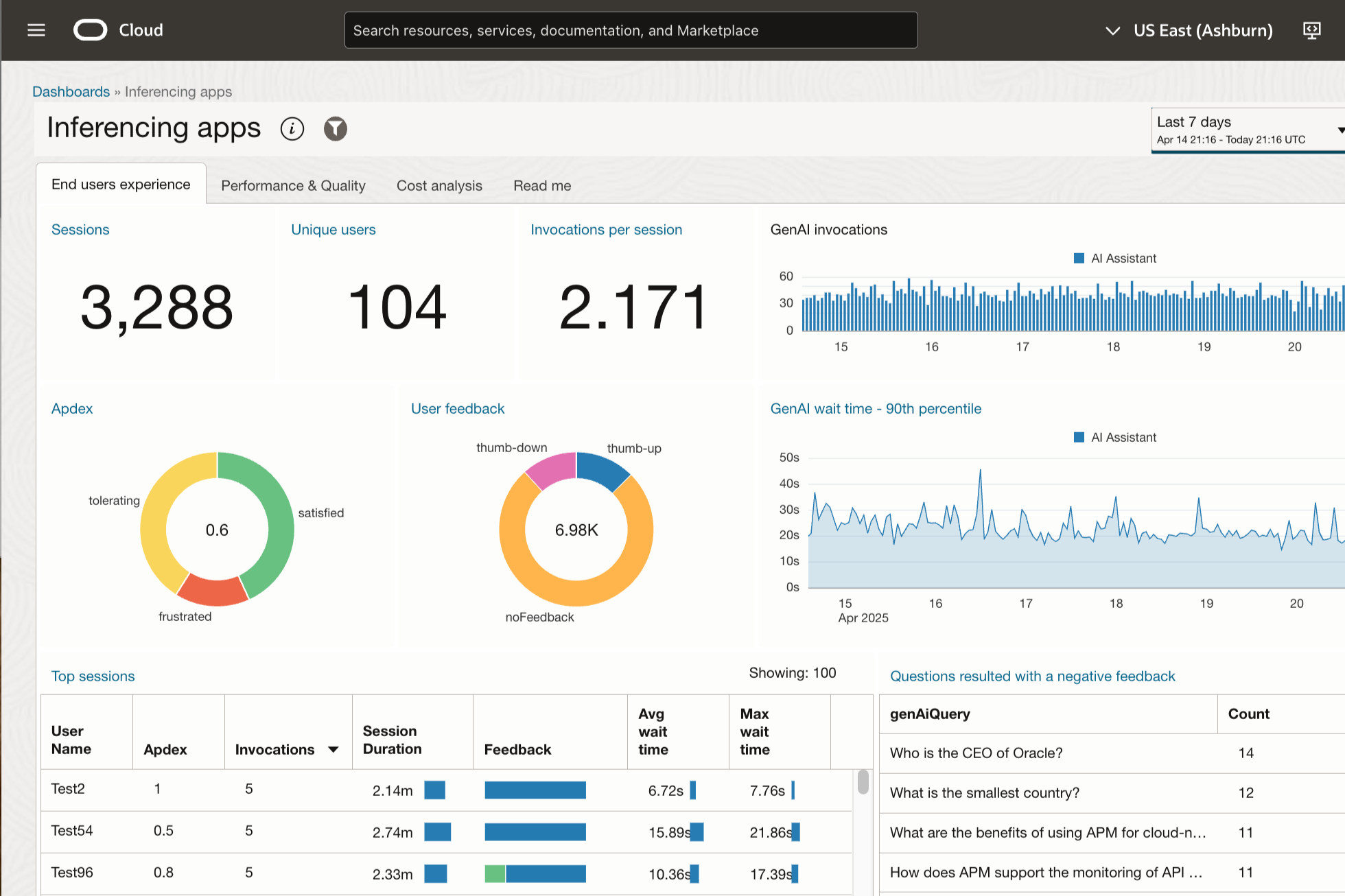
Monitoring and diagnostics on inferencing applications
The feature offers powerful monitoring and deep diagnostics capabilities for your inferencing applications by tracing every invocation across Large Language Model (LLM) chats, vector databases searches, embeddings and other services or tools. Utilizing vast application data captured, it helps you identifying bottlenecks and optimizing overall application performance. It also enables in-depth diagnostics through line-level instrumentation and payload capture.
End user monitoring
User sessions are tracked to examine how effective your inferencing applications are, such as their impact on conversion rates. It measures response time from the end-users’ perspective, including network and browser latency. The feature also offers synthetic monitoring to measure the availability, also watches for drifted behavior over time ensuring the consistency on answers generated by the applications.
LLM service invocation tracking
Token count and associated costs are captured for both inputs and outputs. It also records user feedback, such as thumb up or thumb down, and visualized in dashboards for analysis. Weak responses, like “I do not know” or “not in provided data” are also monitored, which you can narrow down to the trace details. The platform has flexible configuration that supports any framework, models or programming language.
Analytics
Out-of-the-box dashboards provide analytical insights to users by correlating cost and performance metrics, and user feedback. They help drill down into invocation details, including prompt length, token counts, user queries, and GenAI responses. Strong query language enables deeper analysis for various use cases, and elastic dashboards address new evaluation goals as AI trends evolve and paradigms change.
Integrating OCI Application Performance Monitoring into your Gen AI inferencing application is a powerful strategy to elevate its user experience and overall performance. By leveraging real-time monitoring, error analysis, model accuracy assessments, and resource optimization, you can create a robust and reliable Gen AI system. This approach not only ensures user satisfaction but also allows your application to evolve and thrive in the dynamic Gen AI landscape.
With OCI APM, you gain the observability needed to make informed decisions, quickly address issues, and ultimately deliver a cutting-edge Gen AI user experience. Start implementing these monitoring practices to stay ahead of the competition and meet the ever-growing demands of your Gen AI application users.
To start with, obtain comprehensive set of resources, including detailed instructions from GitHub: https://github.com/oracle-quickstart/oci-observability-and-management/tree/master/examples/genai-inference-app-monitoring
Resources:
- OCI Application Performance Monitoring: LLM Observability
- Oracle Cloud Observability and Management Platform
- Oracle Application Monitoring YouTube channel
- Application Performance Monitoring Technical Content
- APM Blogs space
