Introduction
Vision Language Models (VLMs) are crucial for bridging the gap between visual and textual data by combining image and language understanding. Some important VLMs’ use cases are:
- Image Captioning
- Visual Question Answering (VQA)
- Document Information Extraction (Pdf scans)
- Image classification/sentiment analysis
VLMs are considered an improvement over traditional Optical Character Recognition (OCR) systems by incorporating contextual awareness beyond pixel-level recognition.
Heatwave GenAI already provides industry-first in-database LLMs, an automated in-database vector store, scale-out vector processing, and the ability to have contextual conversations in natural language informed by unstructured content [1]. This pipeline eliminates the need for data movement, ETL duplication and specialized AL infrastructure. Adding support for VLMs further improves this pipeline by enabling developers, analysts, and novice users to use visual and textual data in a single place.
Use-case scenarios
Use-case1: Image Captioning
Image captioning generates a brief natural language description of what is happening in an image.
Query image:

Image captioning example:
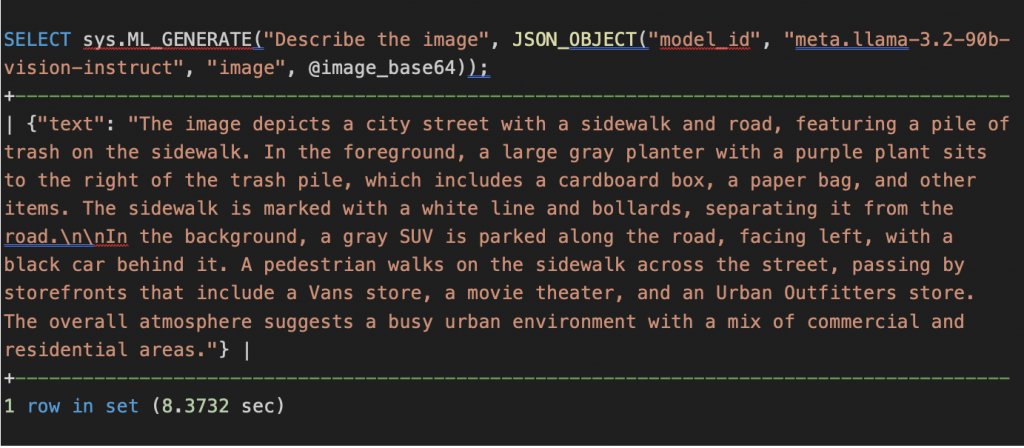
Use-case2: Visual Question Answering (VQA)
VQA answers a user’s question about an image like “Is there any trash in the image?” in simple language.
Query image:

Visual Question Answering example:
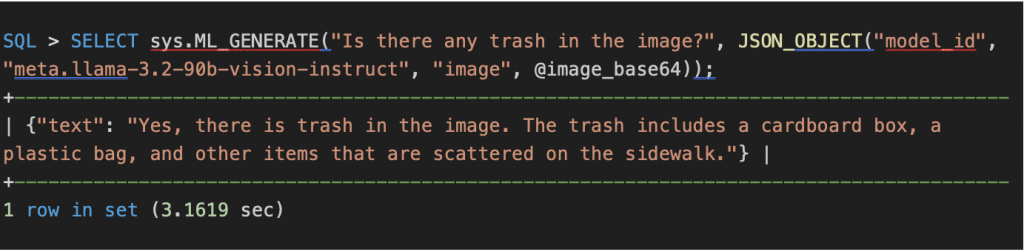
Use-case3: Document Information Extraction
A VLM processes documents and extracts structured details into a clean, structured format.
Query image:

Document Information Extraction example:
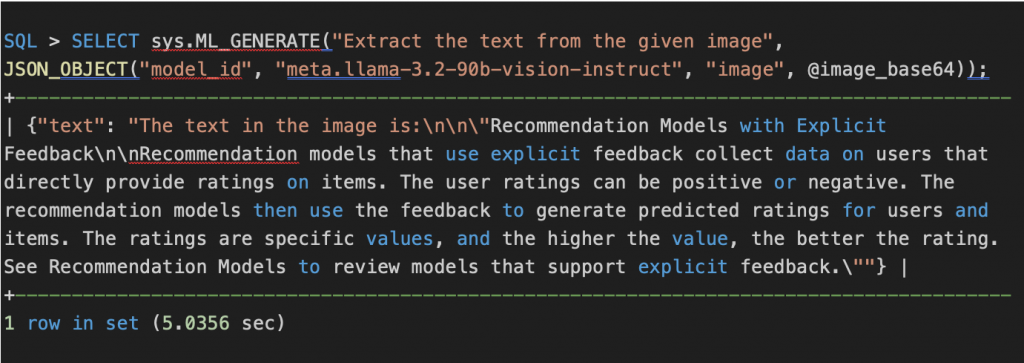
ML_GENERATE_TABLE can be used to process multiple images in parallel using the Heatwave distributed cluster.
Next steps
In future, we plan to add support for:
- In-Heatwave VLMs
- VLMs that reside within the Heatwave service and run on CPUs.
- Multimodal retrieval which addresses the following use cases:
- User wants to find images matching a particular search string.
- User wants to find text content matching a particular image.
- User wants to find images matching a particular image.
- Multimodal RAG
- User wants to generate a text response to a multimodal query.
- Image generation
- Generate an image corresponding to a given string.
Conclusion
Vision Language Models (VLMs) are considered a breakthrough in Generative AI space that enable advanced multimodal capabilities such as image captioning, visual question answering (VQA), and document information extraction by combining image and language understanding. When you bring these abilities directly into Heatwave GenAI as a unified pipeline, everything happens inside the database where your data already lives which eliminates the need for data movement, ETL duplication and specialized AL infrastructure [2].
Learn More
To explore additional resources and deepen your understanding of MySQL HeatWave and VLMs, visit the following links:
- MySQL Heatwave
- MySQL Heatwave GenAI
- Heatwave Gen AI Supported Models and Languages
- ML_GENERATE documentation
- ML_GENERATE_TABLE documentation

