HeatWave MySQL Cluster
HeatWave is a massively parallel, high performance, in-memory query accelerator that accelerates MySQL performance by orders of magnitude for analytics workloads, mixed workloads, and machine learning. HeatWave can be accessed through Oracle Cloud Infrastructure (OCI), Amazon Web Services (AWS), and Oracle Database Service for Azure (ODSA).
HeatWave consists of a MySQL DB System and HeatWave nodes. Analytics queries that meet certain prerequisites are automatically offloaded from the MySQL DB System to the HeatWave Cluster for accelerated processing. With a HeatWave Cluster, you can run online transaction processing (OLTP), online analytical processing (OLAP), and mixed workloads from the same MySQL database without requiring extract, transfer, and load (ETL), and without modifying your applications. For more information about the analytical capabilities of HeatWave, see Chapter 2, HeatWave MySQL.
The MySQL DB System includes a HeatWave plugin that is responsible for cluster management, query scheduling, and returning query results to the MySQL DB System. The HeatWave nodes store data in memory and process analytics and machine learning queries. Each HeatWave node hosts an instance of the HeatWave query processing engine (RAPID). (Source: HeatWave Overview)
Size Of Your HeatWave Cluster
To check the size of your HeatWave Cluster (assuming you have already created your HeatWave instance and created the cluster), from the OCI web console page, click the top-left (hamburger) menu, go down and click Databases and under the HeatWave MySQL header, click DB Systems. You should see something like this:

Then, select the HeatWave instance from the list. To see the cluster details of the HeatWave instance, on the right side of the DB systems page, under HeatWave cluster, click “Details”:
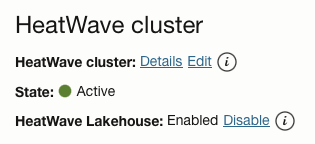
You should then see the details of your HeatWave cluster:
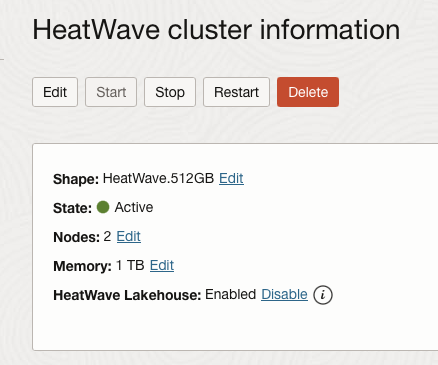
In this cluster, we have two nodes with 512GB of memory in each one.
HeatWave Performance Schema Tables
The HeatWave Performance Schema tables provide information about HeatWave nodes, and about tables and columns that are currently loaded in HeatWave.
Information about HeatWave nodes is available only when rapid_bootstrap mode is ON. Information about tables and columns is available only after tables are loaded in the HeatWave Cluster. See Section 2.2, “Loading Data to HeatWave MySQL”.
Here is a list of the HeatWave performance schema tables: rpd_column_id, rpd_columns, rpd_exec_stats, rpd_ml_stats, rpd_nodes, rpd_preload_stats, rpd_query_stats, rpd_table_id and rpd_tables. For this post, we will be looking at the rpd_nodes table.
Available HeatWave Cluster Memory
The rpd_nodes table provides information about the HeatWave nodes, and details about each column is on the rpd_nodes manual page. The rpd_nodes table provides information such as memory memory usage, so we can use that to determine the amount of available memory.
Here are the rpd_nodes table columns:
desc performance_schema.rpd_nodes; +----------------------+-----------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +----------------------+-----------------+------+-----+---------+-------+ | ID | int unsigned | NO | | NULL | | | CORES | int unsigned | YES | | NULL | | | MEMORY_USAGE | bigint unsigned | YES | | NULL | | | MEMORY_TOTAL | bigint unsigned | YES | | NULL | | | BASEREL_MEMORY_USAGE | bigint unsigned | YES | | NULL | | | STATUS | varchar(64) | YES | | NULL | | | IP | varchar(64) | YES | | NULL | | | PORT | int unsigned | YES | | NULL | | | CLUSTER_EVENT_NUM | bigint unsigned | YES | | NULL | | | NUM_OBJSTORE_GETS | bigint unsigned | YES | | NULL | | | NUM_OBJSTORE_PUTS | bigint unsigned | YES | | NULL | | | NUM_OBJSTORE_DELETES | bigint unsigned | YES | | NULL | | | ML_STATUS | varchar(64) | YES | | NULL | | +----------------------+-----------------+------+-----+---------+-------+ 13 rows in set (0.0017 sec)
As I mentioned earlier, I have two HeatWave nodes with 512GB of memory each. I have already loaded some data into HeatWave, and I have logged into the instance using MySQL Shell. I can use this SQL statement to give me an idea of how much memory space is available.
SELECT
ID,
MEMORY_USAGE,
MEMORY_TOTAL,
CASE
WHEN memory_total = 0 THEN 0
ELSE (MEMORY_USAGE / MEMORY_TOTAL * 100)
END AS memory_percentage
FROM rpd_nodes order by ID;
The statement does check to make sure that the memory usage is not zero, so you don’t get a “division by zero” error. When I run the command, I get this output:
+----+-------+--------------+--------------+-------------------+ | ID | CORES | MEMORY_USAGE | MEMORY_TOTAL | memory_percentage | +----+-------+--------------+--------------+-------------------+ | 0 | 32 | 6283108979 | 515396075520 | 1.2191 | | 1 | 32 | 6282877887 | 515396075520 | 1.2190 | +----+-------+--------------+--------------+-------------------+
You can see the two cluster nodes as ID’s 0 and 1. Each node has 32 cores, and 515396075520 bytes of memory – or 480 gigabytes. You aren’t able to use all 512GB of memory as some memory is used by the cluster itself. But, HeatWave compresses the data as it is loaded, so your are able to store more than 512GB’s in each node. Data compression does add a tiny amount of overhead, but you can turn off compression if desired. My memory usage is low, and the percentage used is about 1.22% for each node.
Note:
The rpd_nodes table is read-only.
The rpd_nodes table may not show the current status for a new node or newly configured node immediately. The rpd_nodes table is updated after the node has successfully joined the cluster.
If additional nodes fail while node recovery is in progress, the newly failed nodes are not detected and their status is not updated in the performance_schema.rpd_nodes table until after the current recovery operation finishes and the nodes that failed previously have rejoined the cluster.
