The Oracle HeatWave MySQL service offers users the flexibility to modify DB system shapes and configuration, enabling them to adapt to changing workloads and enhance performance.
In this blog post we’ll share insights into the latest changes related to DB system shape and configuration changes, mostly focusing on the high availability and read replicas support.
Why Change DB System Shape and Configuration?
Scaling up the capacity of your DB system is the most common reason for updating its shape. Larger shapes provide more computing power, increased memory and can unlock optional functionalities like support for read replicas and HeatWave clusters. Oracle HeatWave MySQL service provides a list of the supported shapes, each with its own characteristics and limitations, in this page.
DB systems configurations are shape-specific. Distinct default configurations are optimized for different shapes, with memory and CPU options tuned with predefined values. Hence, changing the shape of your DB system also requires updating its configuration in the same request.
Maximizing DB System Availability
Enabling high availaibility (HA) in your DB systems can reduce significantly the recovery time objective (RTO) for the READ/WRITE enpoint, not only in failure cases but also during maintenance or shape and configuration updates.
By relying on high availability, you also minimize the risk of impact in the READ/WRITE endpoint during maintenance or shape and configuration updates. This is possible by orchestrating changes on the HA group members in a rolling manner (the same approach as the one described in maintenance of a HA DB system):
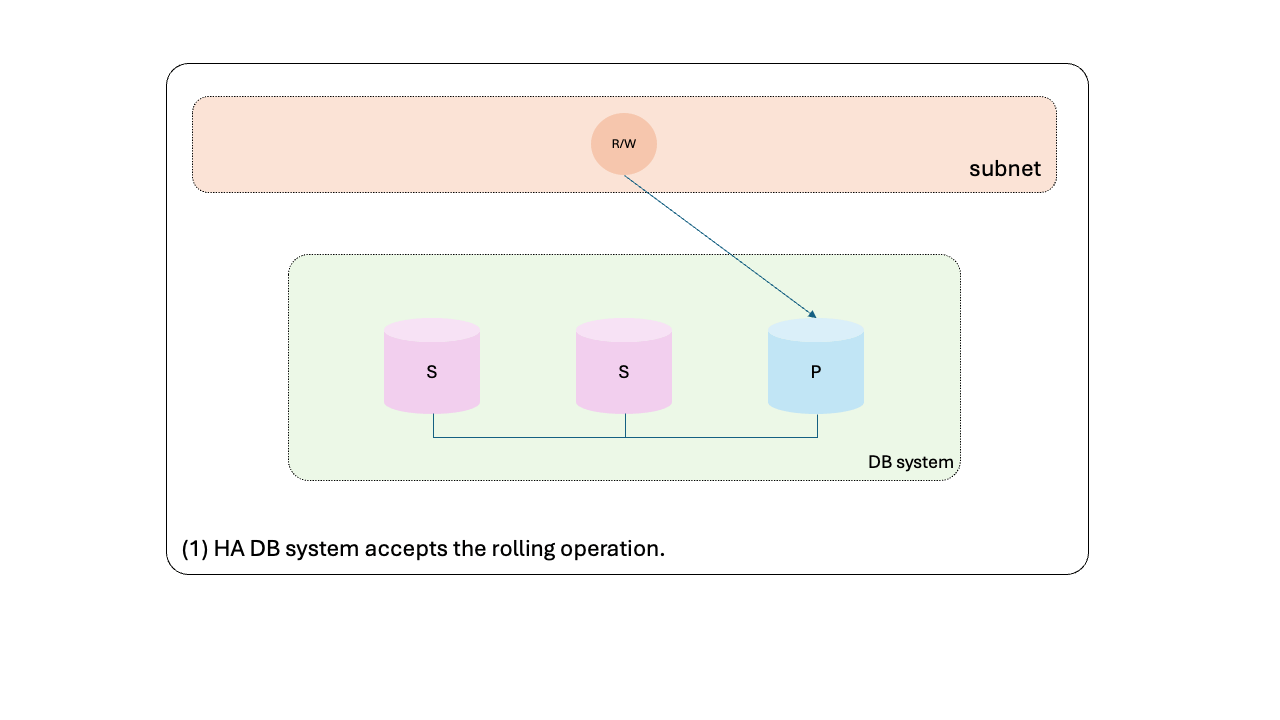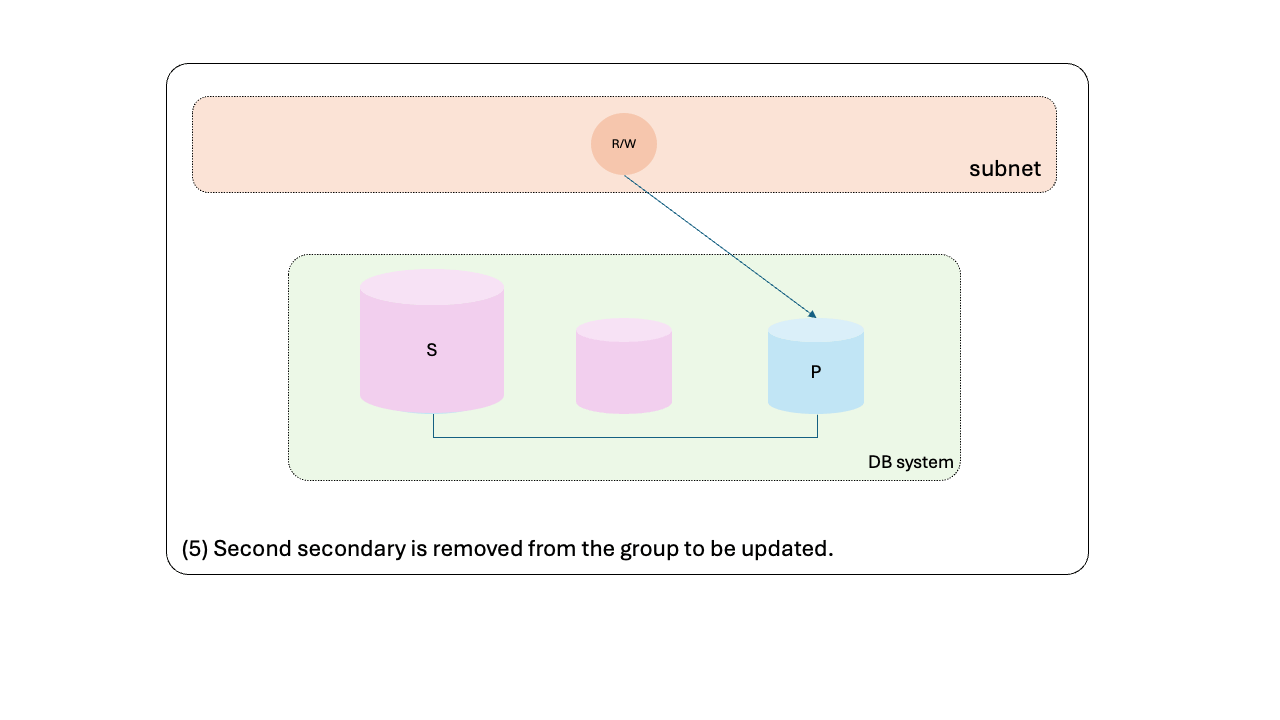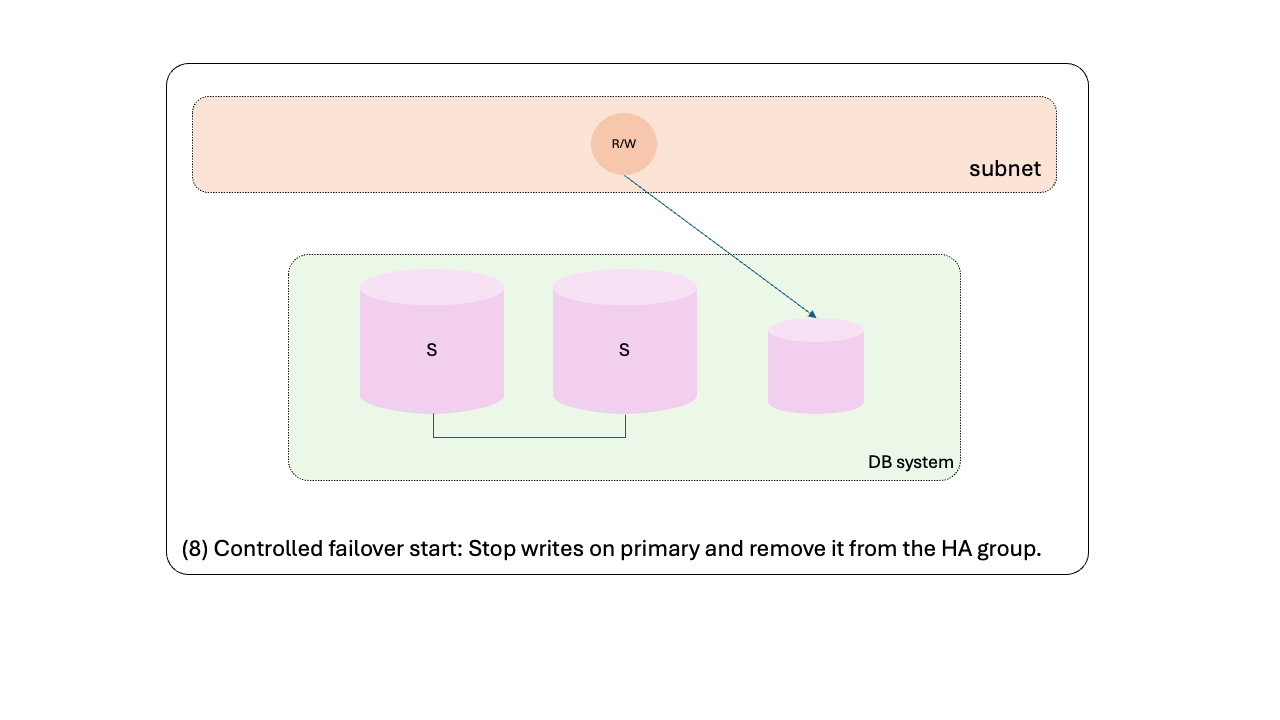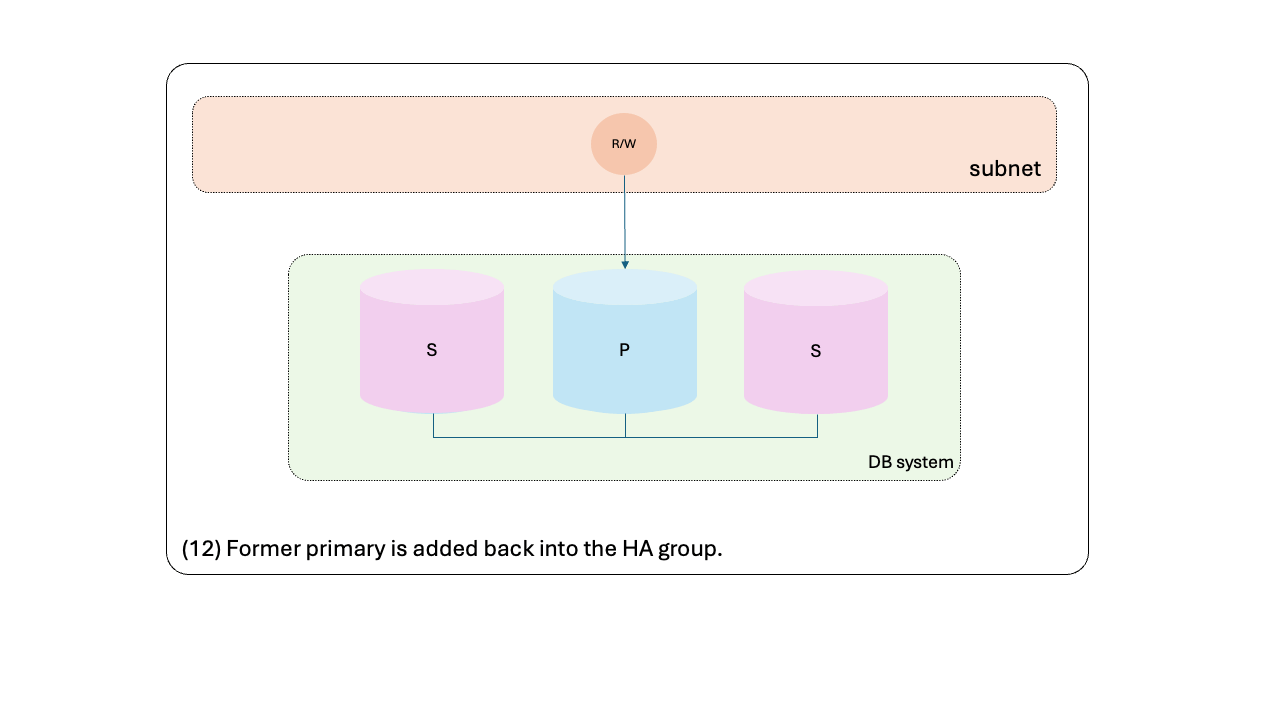
- HA DB system accepts the rolling operation.
- First secondary is removed from the group to be updated.
- First secondary is updated.
- First secondary is added back into the HA group.
- Second secondary is removed from the group to be updated.
- Second secondary is updated.
- Second secondary is added back into the HA group.
- Controlled failover start: Stop writes on primary and remove it from the HA group.
- Controlled failover: New primary is elected.
- Controlled failover finish: R/W endpoint is rewired to the new primary.
- Former primary is updated.
- Former primary is added back into the HA group.
It is possible to group the above mentioned steps regarding their impact in the READ/WRITE endpoint as:
- Perform the operation in the secondaries first, one by one (steps 1 to 7):
- The primary is kept untouched until all secondaries are successfully updated;
- Each updated secondary rejoin the group after the operation.
- Perform what we refer to as the “controlled failover” (steps 8 to 10):
- Once only the primary group member remains to be operated, the orchestration framework fences the primary and remove it from the HA group in order to trigger a new primary election;
- One of the recently operated secondaries takes over the primary role in the HA group and, within seconds, the DB system READ/WRITE endpoint is rewired to the new primary.
- The observed downtime in the READ/WRITE endpoint in this case happens from when the former primary is fenced up to the rewiring of the READ/WRITE endpoint to the new primary.
- Perform the operation in the former primary (steps 11 and 12):
- It will rejoin the HA group as a secondary.
No switchback to the former primary is performed on purpose to avoid yet another downtime during the operation. If needed, the user can perform a manual switchover at his best convenience.
Note: Any request to update an HA DB system configuration, even for changing dynamic variables only, will utilize the rolling framework with a “controlled failover” to ensure minimal disruption.
Maximizing Read Availability
Read replicas are an essential component for scaling out reads and avoiding downtime for read-only workloads.
When updating the shape and configuration of your DB system, the new rolling framework orchestrates changes to read replicas in a rolling manner too, one by one. This process ensures that there is negligible downtime on the read replica load balancer endpoint. Read replicas are updated before changing any of the HA group members for high availability DB systems (or the instance serving the READ/WRITE endpoint for standalone DB systems).
For DB systems with multiple read replicas, the load balancer endpoint will always have available read replicas to serve read requests during the update process. Here’s an overview of the orchestration process:
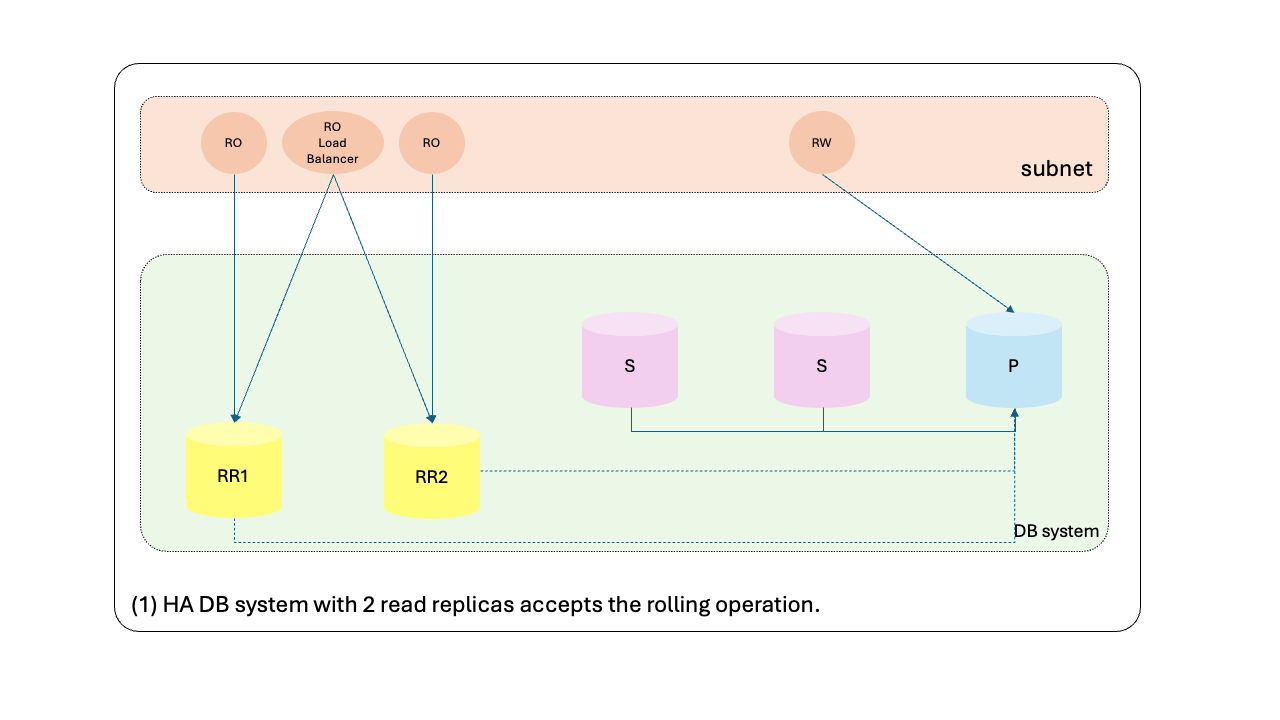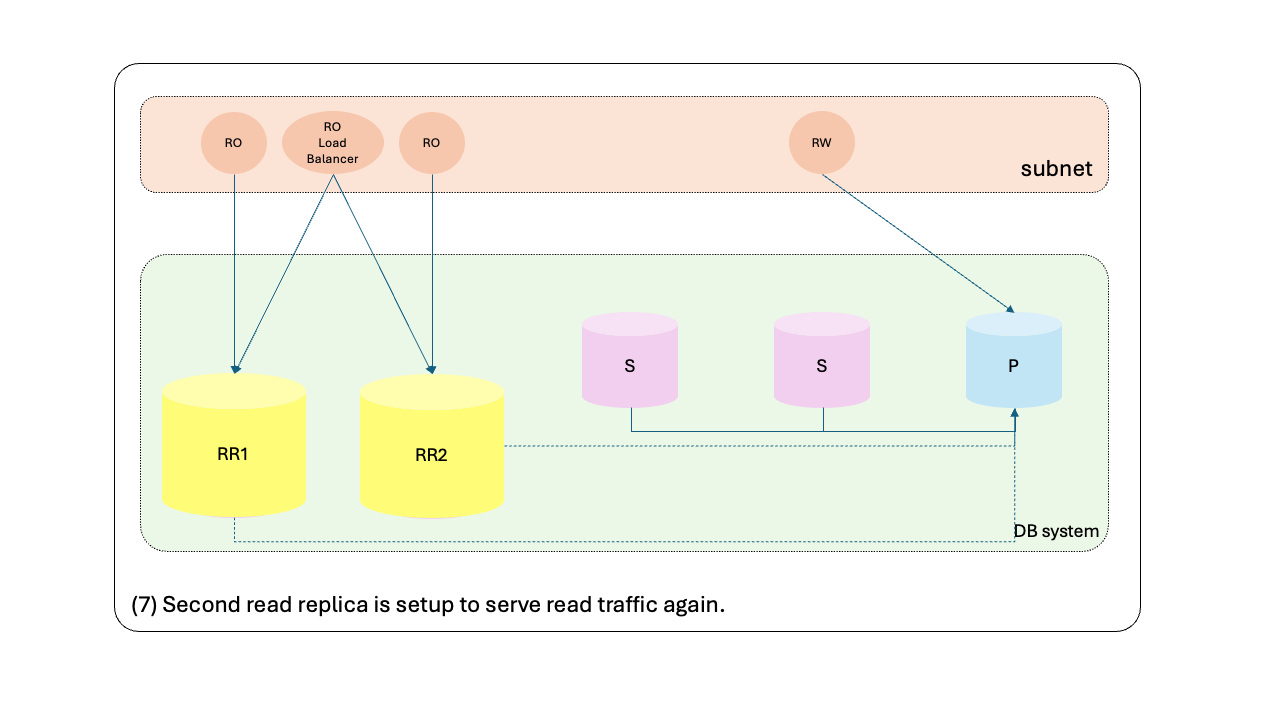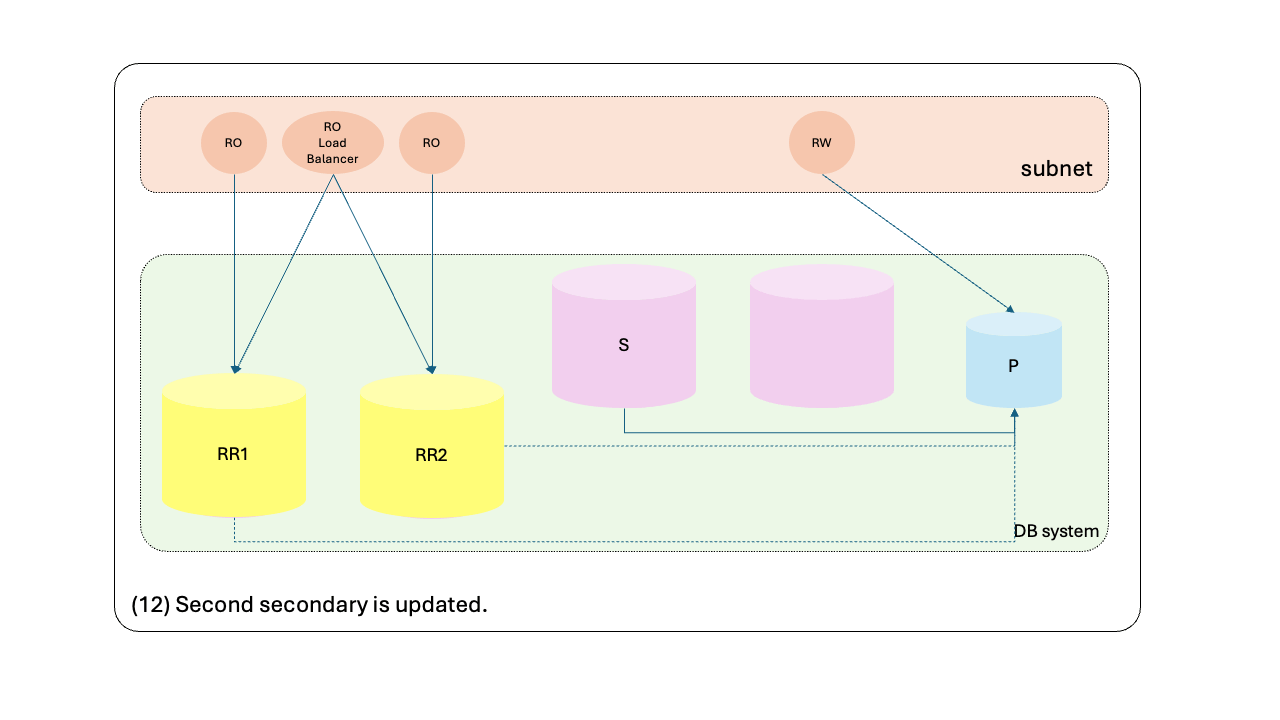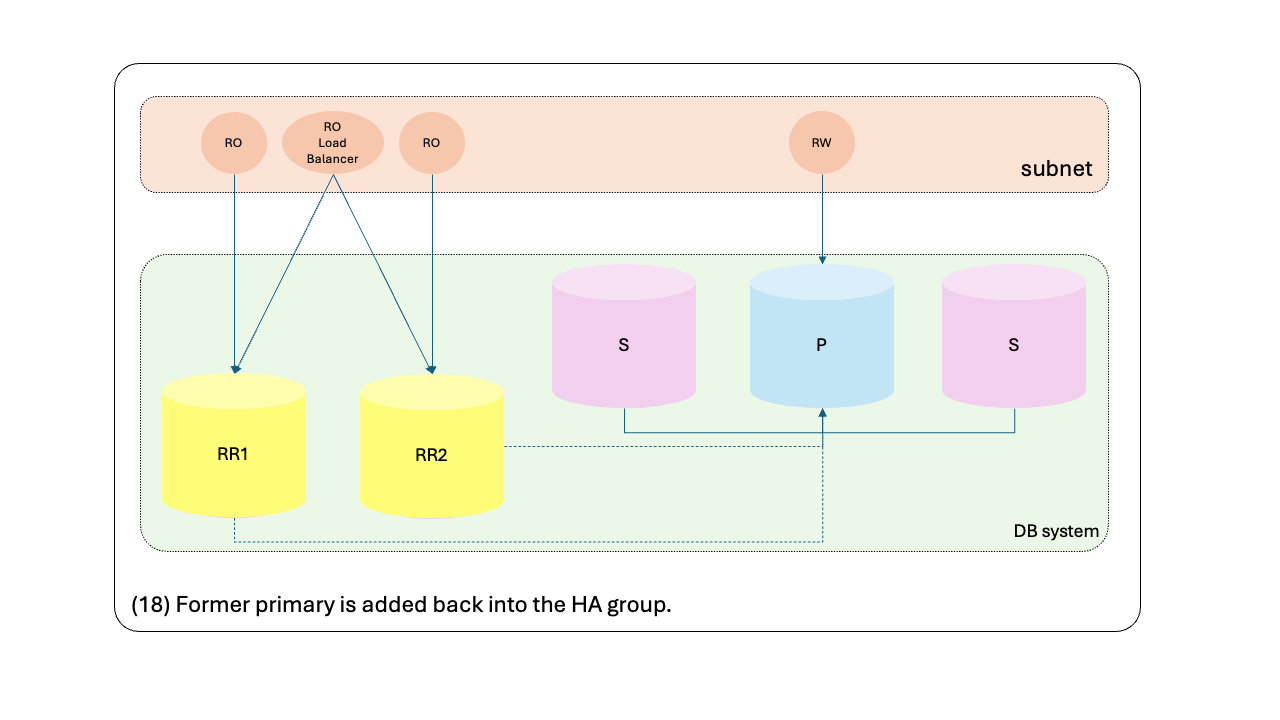
- HA DB system with 2 read replicas accepts the rolling operation.
- First read replica is prepared to be updated.
- First read replica is updated.
- First read replica is setup to serve read traffic again.
- Second read replica is prepared to be updated.
- Second read replica is updated.
- Second read replica is setup to serve read traffic again.
After updating the read replicas, there should be a sequence like step 2 to 12 from the HA DB system update described previously (related to the HA group members updates).
This means there is negligible downtime on the read replica load balancer endpoint! Also, the READ/WRITE endpoint is not expected to have any downtime while the orchestration is updating the read replicas.
Note: Read replicas can be updated to have their own unique shape and configuration. Only the read replicas that don’t override the DB system shape and configuration will be updated automatically by a request to update the DB system shape and configuration.
Resilient Operations
During a rolling operation, if any failures are detected, the orchestration framework will halt the process to prevent extended downtime. This proactive measure ensures we maintain system integrity.
For HA DB systems, our design ensures that if one of the secondaries encounters an issue, there is no observable downtime from the application perspective. Even if a failure occurs while updating the former primary, the downtime remains consistent with a successful update, minimizing any potential impact.
Upon failure, the DB system lifecycle details may indicate inconsistencies in properties like shape name, configuration OCID, or MySQL version:
Please verify the properties and update the DB system, or contact support.
When inconsistencies are caused by a failed update request that updated some of the HA group members, a retry operation with the same target properties values will only affect the members that need to be updated. This ensures that already updated HA group members are not altered again.
Alternatively, you can perform a rollback by initiating a new update request with the current DB system property values. Similar to the retry, only the HA group members requiring the update will be operated.
You can also request a new update with target values that are not the current nor the ones on previous failed attempts. In this case, all HA group members are expected to be operated.
While the system is designed to remain operational despite inconsistencies, it is not recommended to operate with these discrepancies for prolonged periods. Always verify the properties and take the necessary steps to update the DB system or reach out to support for guidance.
Automatic HeatWave Cluster Recovery
The rolling DB system shape and configuration operations will automatically recover any HeatWave cluster on high availability DB systems, just like what happens during maintenance or after unexpected primary failures.
Summary
Updating DB Systems with minimum downtime is crucial for resource optimization and adapting to changing workloads within cloud services.
To ensure a smooth transition, it’s important to sidestep common mistakes and adhere to best practices. Thoroughly testing new configurations, applying detailed planning, understanding application requirements and focusing on continuous availability are essential to maintain uninterrupted services for end-users.
By harnessing this new capability and following the guidelines outlined above, you can confidently adjust DB systems shapes and configurations with minimal downtime.
To explore the capabilities of HeatWave MySQL, visit oracle.com/heatwave/free and create one for free.
To learn more about HeatWave MySQL, visit oracle.com/mysql.
