Modern cloud applications are expected to remain available even during infrastructure interruptions, replication failovers, maintenance events, and transient network failures. In distributed database environments, it requires applications to treat transient failures as a normal part of production operations.
This blog discusses practical API reliability designs for applications using MySQL HeatWave High Availability and Read Replicas, including retry strategies, active session handling, and consistency considerations.
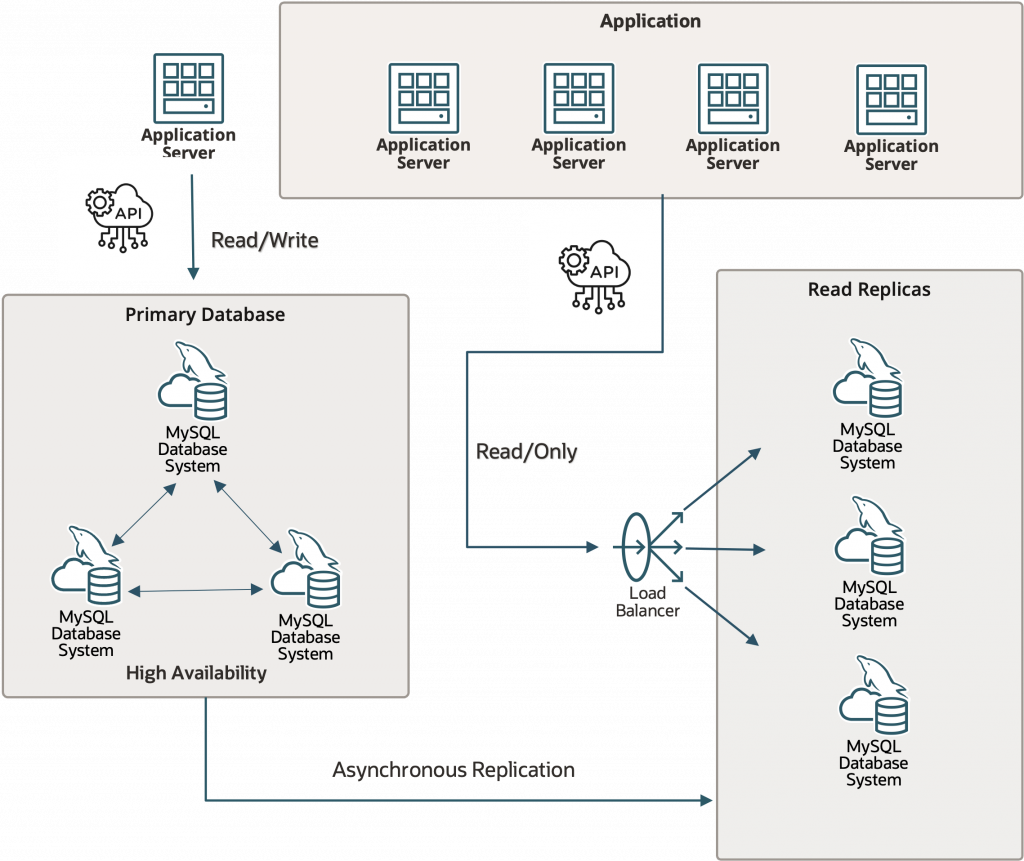
MySQL HeatWave High Availability & Read Replica Architecture
MySQL HeatWave provides fully-managed High Availability and Read Replicas to improve fault tolerance, minimize maintenance impact, and scale read-heavy workloads. Applications connect to the primary database via a read/write endpoint in a High Availability (HA) database system. Meanwhile, applications can connect through a read-only load balancer endpoint that distributes read requests across available Read Replicas.
Why Retry logic matters for APIs?
This architecture improves availability and scalability, but it also changes how applications must think about database connectivity and failure handling.
A common misconception is that a failed database transaction always indicates a database failure. In reality, these failures are often transient and recoverable through retries.
Retry logic matters for APIs because transient failures are unavoidable in distributed systems. Even healthy backend services can occasionally experience the following scenarios:
- Database connections may reset and idle sessions may expire
- Active sessions may disconnect unexpectedly
- HA database may need to perform automatic failover or manual switchover
- Read Replicas may be restarted or taken offline for maintenance
- Read Replicas may temporarily lag behind the primary database
- Temporary network disruptions may interrupt active database sessions and in-flight requests
Without retries, these temporary issues are immediately exposed to users as failed API requests, resulting in reduced availability and poor user experience.
A simple example without retry:
Client Request
↓
Temporary network interruption
↓
Request failsWith controlled retry handling:
Client Request
↓
Temporary network interruption
↓
Automatic retry
↓
Request succeedsWhat are the Retry best practices?
Retry best practices help applications recover from temporary failures while preventing additional instability during outages.
Here are some best practices:
- Retry only transient failures such as connection resets, temporary network interruptions, or replica temporarily unavailable
- Use exponential backoff to progressively increase wait times between retries
- Add randomized jitter to prevent synchronized retry spikes across clients
- Limit retry attempts to avoid excessive request amplification
- Prevent retry storms that can worsen outages during backend instability
Example 1. Retry Only Transient Failures
Applications should retry transient infrastructure failures:
try:
result = execute_query()
except ConnectionResetError:
retry()common transient MySQL errors can often be resolved successfully through an immediate retry or after a short backoff interval
| Error Code | Symbol | What it means | What to do |
1213 | ER_LOCK_DEADLOCK | Deadlock found when trying to get lock | Retry the entire transaction |
1205 | ER_LOCK_WAIT_TIMEOUT | Lock wait timeout exceeded | Retry the statement by default; retry the whole transaction if innodb_rollback_on_timeout is enabled. |
but should not retry application-level errors such as invalid SQL syntax or constraint violations:
ERROR 1064 (42000): SQL syntax errorExample 2. Use Exponential Backoff
Common resiliency pattern is exponential backoff. Instead of retrying immediately:
Retry 1 -> immediately
Retry 2 -> immediately
Retry 3 -> immediatelyapplications gradually increase retry intervals:
Retry 1 -> wait 100ms
Retry 2 -> wait 200ms
Retry 3 -> wait 400msThis reduces pressure on overloaded systems and improves recovery behavior.
Example 3. Add Randomized Jitter
Add randomized jitter further improves stability by preventing large numbers of clients from retrying simultaneously:
delay = base_delay * (2 ** attempt)
delay += random.uniform(0, 100)
sleep(delay)Without jitter, thousands of clients may reconnect at exactly the same interval after a failure event.
What are the recommended production practices to prevent Retry storms?
Retries improve resiliency by allowing applications to recover automatically from short-lived infrastructure instability without requiring user intervention.
However, retry policies should be carefully controlled. Excessive, immediate, or unbounded retries can amplify failures during service degradation or outages, increasing pressure on already constrained backend systems and extending recovery time.
In production environments, retries should increase availability while minimizing additional system load and avoiding the masking of underlying reliability issues.
Therefore, production-grade services should combine retries with the following recommendations:
| Recommendation | Benefit |
|---|---|
| Retry transient read failures | Improved availability |
| Keep retries bounded | Prevent overload |
| Use exponential backoff | Reduce contention |
| Avoid session-dependent state | Improve reconnect safety |
| Keep transactions short | Reduce interruption exposure |
| Observability and monitoring | Improve consistency awareness |
| Use connection pooling | Reduce connection overhead |
| Implement circuit breakers | Prevent cascading failures |
Summary
A practical retry strategy helps APIs remain available and fault tolerant while protecting backend systems from excessive load during failure scenarios.
In modern cloud-native architectures, retry logic is not simply an optimization feature – it is a core reliability requirement for building resilient APIs and distributed applications.
